siro-devops/k8s-incident-response
GitHub: siro-devops/k8s-incident-response
一套结合混沌工程、监控告警和应急手册的 Kubernetes 应急响应实践框架,用于验证集群自愈能力并标准化故障排查流程。
Stars: 0 | Forks: 0
# Kubernetes 应急响应工程
[]()
[]()
[]()
## 本项目展示了什么
此仓库证明了我能够**运维** Kubernetes,而不仅仅是部署它。它包含:
| 能力 | 实现方式 | 证据 |
|------------|----------------|----------|
| Chaos 注入 | LitmusChaos pod-delete 实验 | Pod 被杀掉,K8s 在 8 秒内自动恢复 |
| 告警 | 带有 runbook URL 的 Prometheus 规则 | 基于 Pod 重启率触发告警 |
| 合成监控 | k6 冒烟测试 + 负载测试 | 持续验证脚本 |
| 应急响应 | 3 个 runbook (CRD, markdown) | 可操作的故障排查步骤 |
## 快速开始 (Runbook 优先)
1. **Pod CrashLoopBackOff** → [Runbook](runbook/pod-crashloop.md)
2. **高网络延迟** → [Runbook](runbook/high-latency.md)
3. **节点 CPU 饱和** → [Runbook](runbook/node-cpu-saturation.md)
## Chaos 实验
### Pod 杀掉 (已执行)
- 目标部署:`target-app`
- Chaos 持续时间:30 秒
- 被杀掉的 Pod:`target-app-68b958dc98-5hsb2`
- 恢复时间:约 8 秒 (Kubernetes 重新调度)
```bash
# 实时观察自动恢复过程
kubectl get pods -l app=target-app -w
```
## Prometheus 告警
配置的告警带有链接到此仓库的 `runbook_url` 注解:
- `HighPodRestartRate` (>0.05 restarts/sec 持续 2m)
- `PodCrashLooping` (检测到 CrashLoopBackOff)
- `HighNetworkLatency` (p95 > 500ms)
## 合成监控
- `smoke-test.js` - 验证核心 endpoint (全天候运行)
- `load-test.js` - 在 Chaos 实验期间模拟流量
```bash
k6 run synthetic/smoke-test.js
```
## 截图
| # | 证据 | 截图 |
|---|----------|------------|
| 1 | Chaos 发生前正在运行的 Pod | 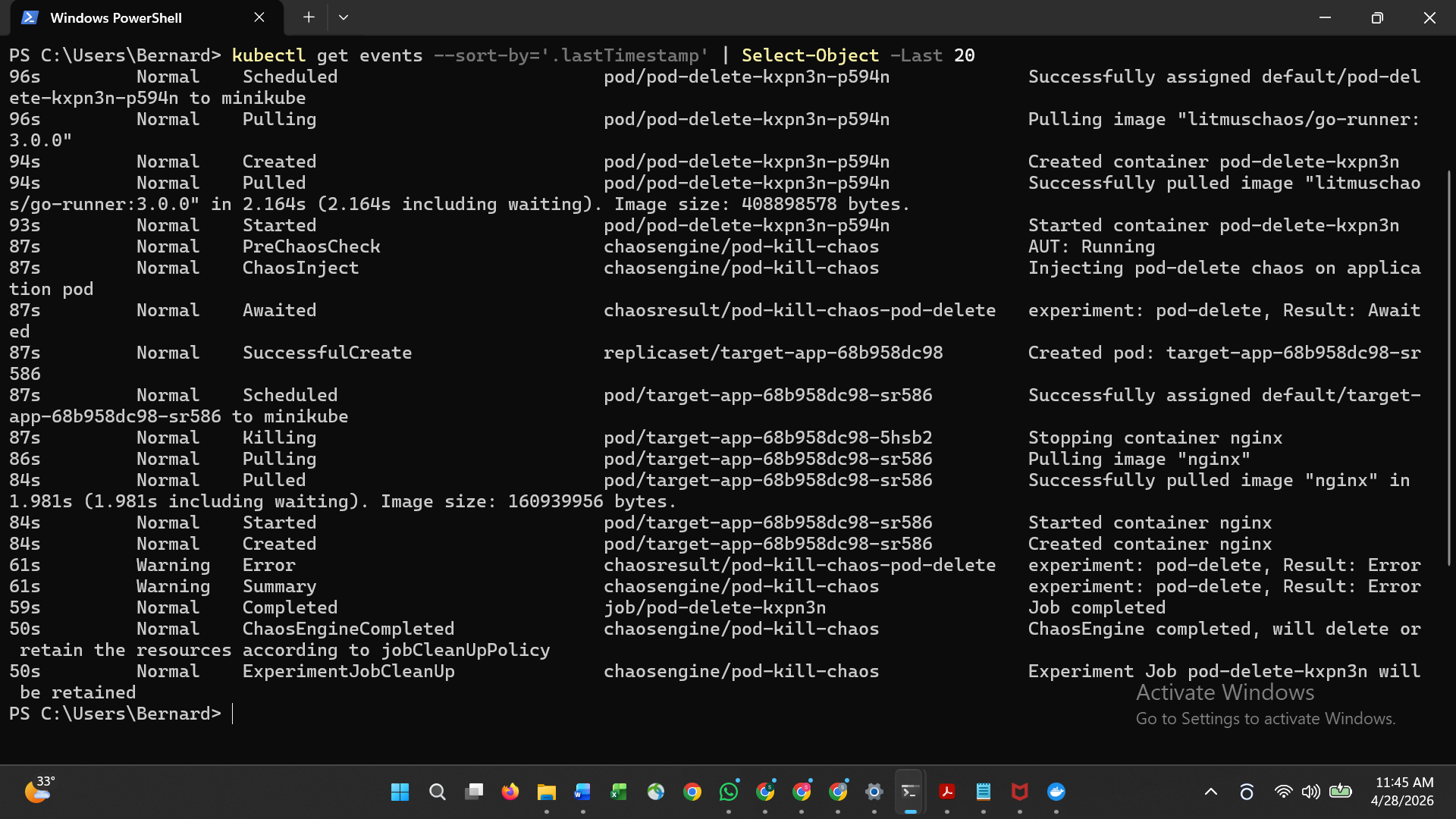 |
| 2 | Pod 杀掉自动恢复 | 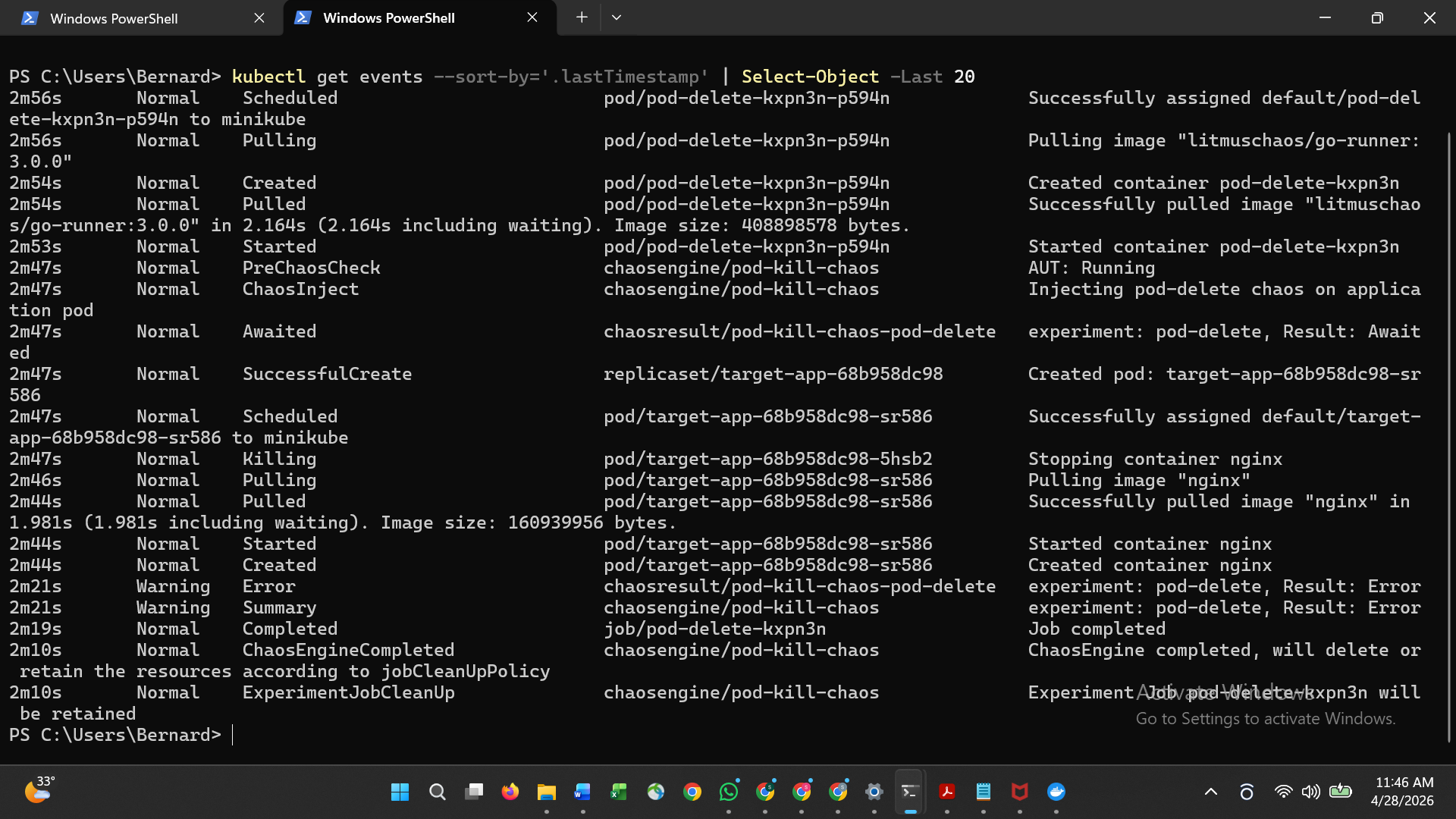 |
| 3 | Chaos 事件日志 | 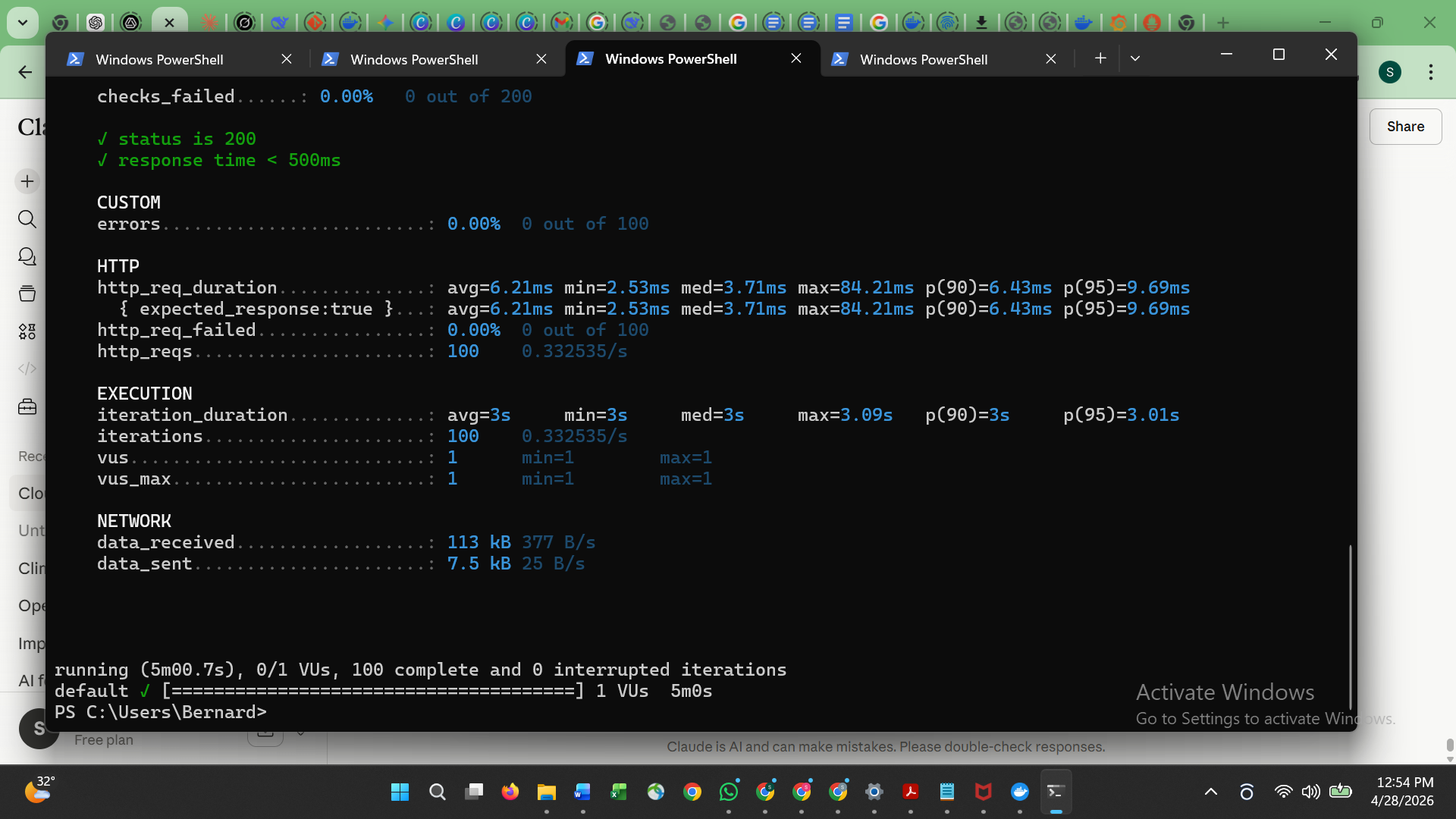 |
| 4 | Prometheus 告警触发中 | 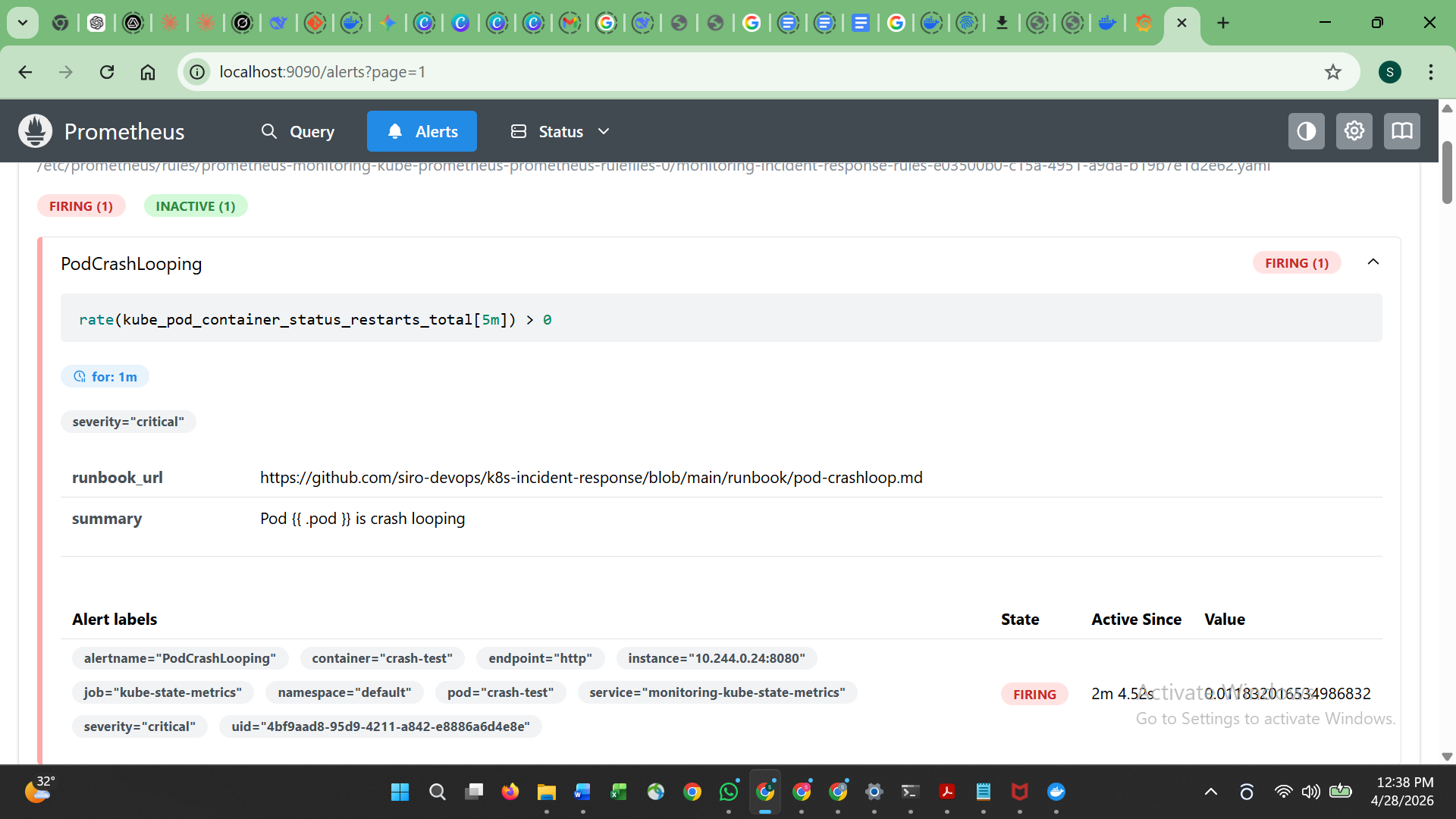 |
| 7 | k6 冒烟测试通过 | 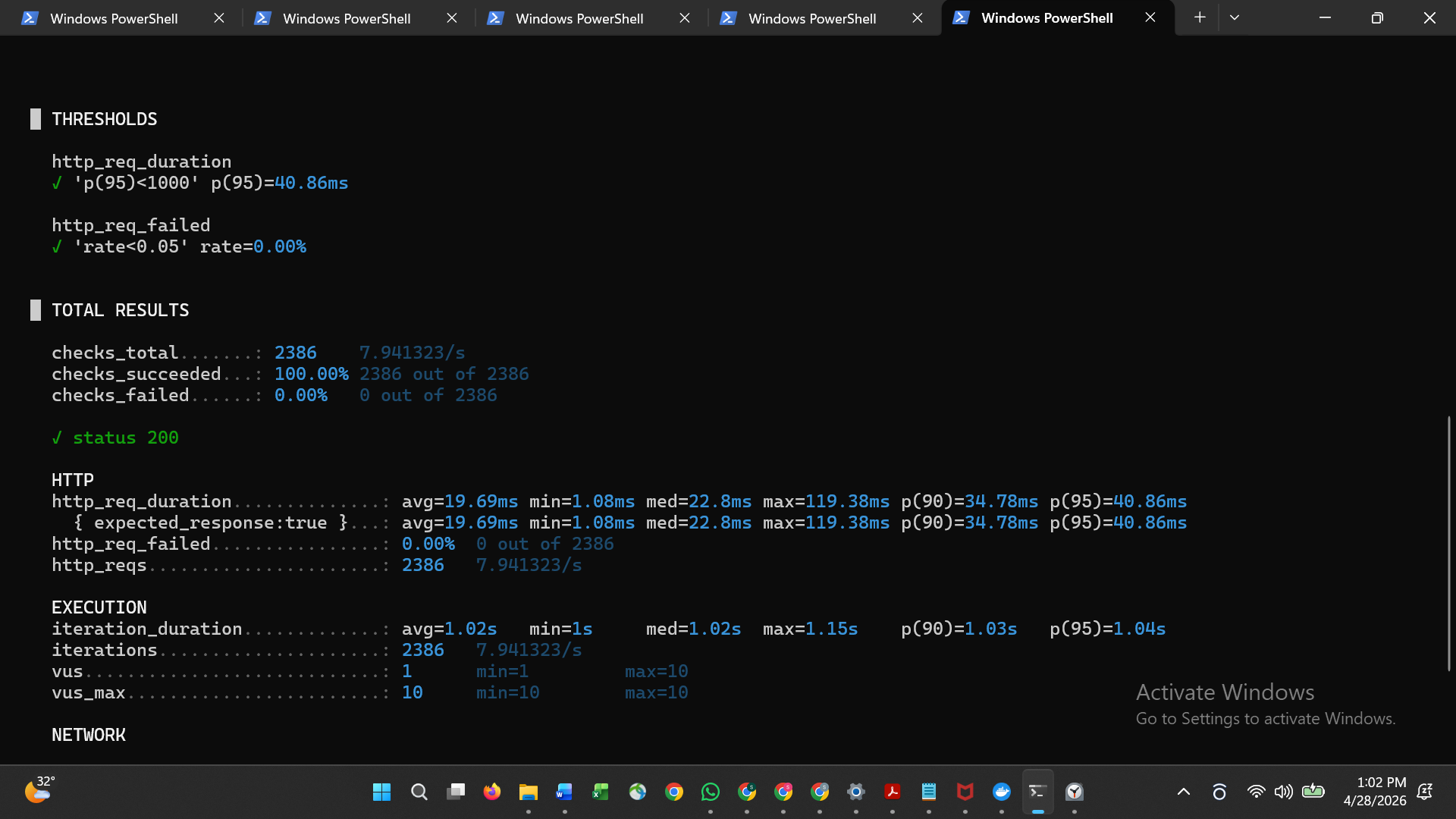 |
## 技术栈
- **Chaos**:LitmusChaos 3.0.0
- **监控**:Prometheus + Grafana
- **测试**:k6
- **编排**:Kubernetes (Minikube)
- **基础设施即代码**:Terraform (独立仓库)
## 联系方式
**GitHub:** [github.com/siro-devops](https://github.com/siro-devops)
**Upwork:** 可承接 DevOps 合同项目
*"没有 Chaos 的可观测性仅仅是猜测。"*
标签:API集成, ASM汇编, CISA项目, CPU饱和度, IT运维, k6, K8s运维, LitmusChaos, NIDS, Runbook, Socks5代理, SRE, 偏差过滤, 压力测试, 可观测性, 合成监控, 告警规则, 子域名突变, 容器化, 工程能力, 库, 应急响应, 性能测试, 故障排查, 数据处理, 混沌工程, 监控, 站点可靠性工程, 系统恢复, 网络延迟, 自动化运维, 自定义脚本, 自定义请求头, 自愈能力, 运维自动化