Dvurechensky/Browser.Reverse.Engineering.Toolkit
GitHub: Dvurechensky/Browser.Reverse.Engineering.Toolkit
一套浏览器会话捕获、自动化爬取与离线重建工具包,用于深度解析现代Web应用的技术架构和运行时状态,生成结构化报告和工程产物。
Stars: 13 | Forks: 0
语言:
俄语
|
英语(当前)
浏览器逆向工程工具包
一个由三部分组成的工具包,用于浏览器会话捕获、自动化爬取以及现代 Web 应用程序的离线重建。
概述
本仓库不涉及绕过身份验证或攻击网站。它只处理浏览器会话中已有的内容:DOM、网络活动、运行时状态、存储、路由、遥测数据以及真实用户交互的痕迹。 这个 monorepo 围绕一个 pipeline 构建: ``` Capture -> Crawl -> Reconstruct -> Review -> Export ```示例页面
    - https://dvurechensky.github.io/Browser.Reverse.Engineering.Toolkit/项目
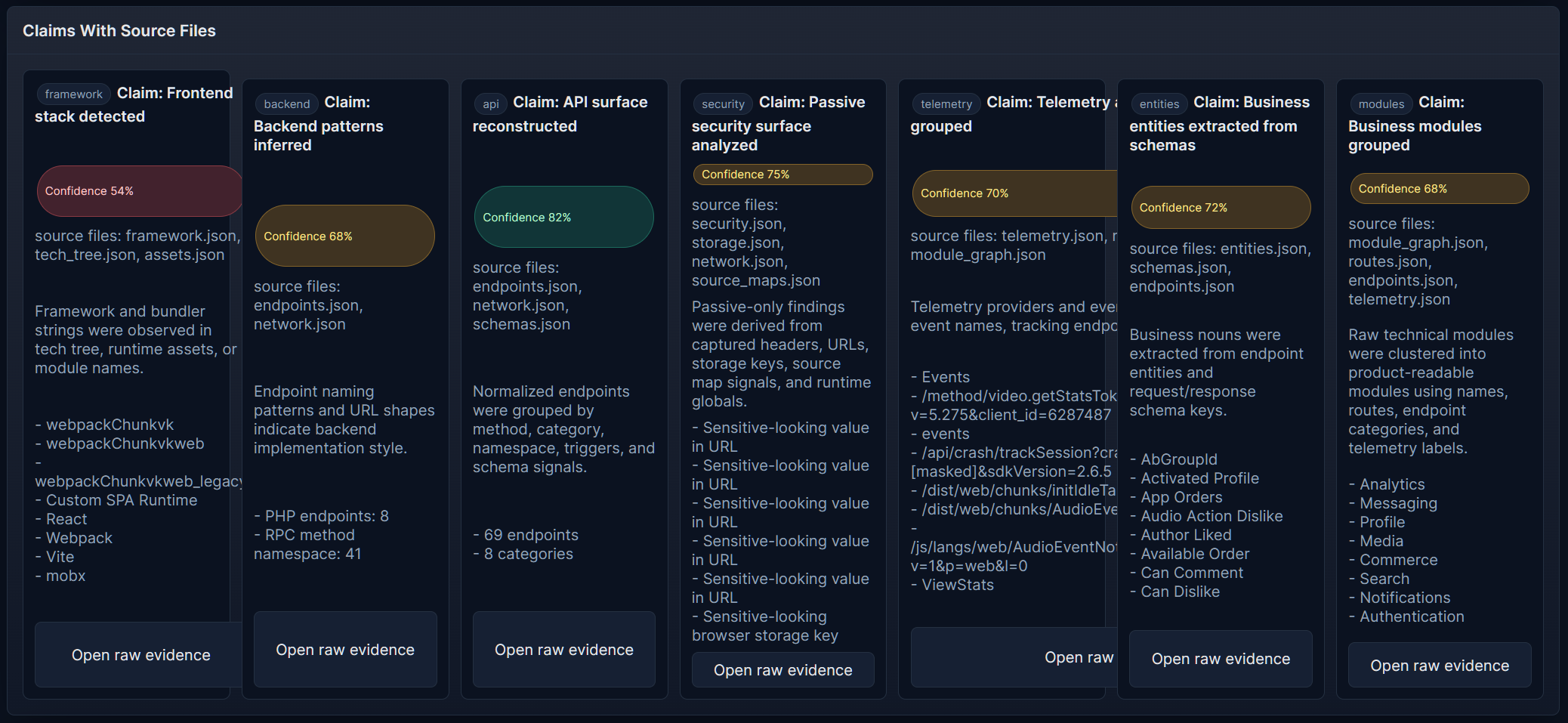
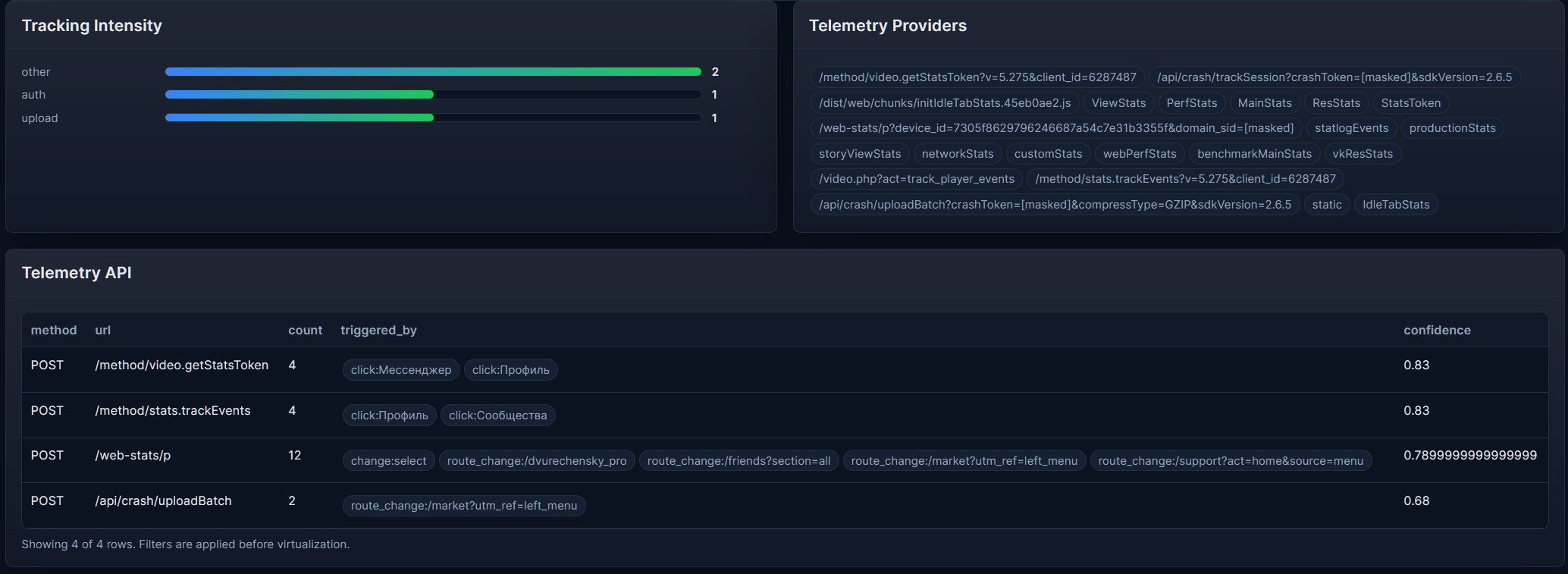
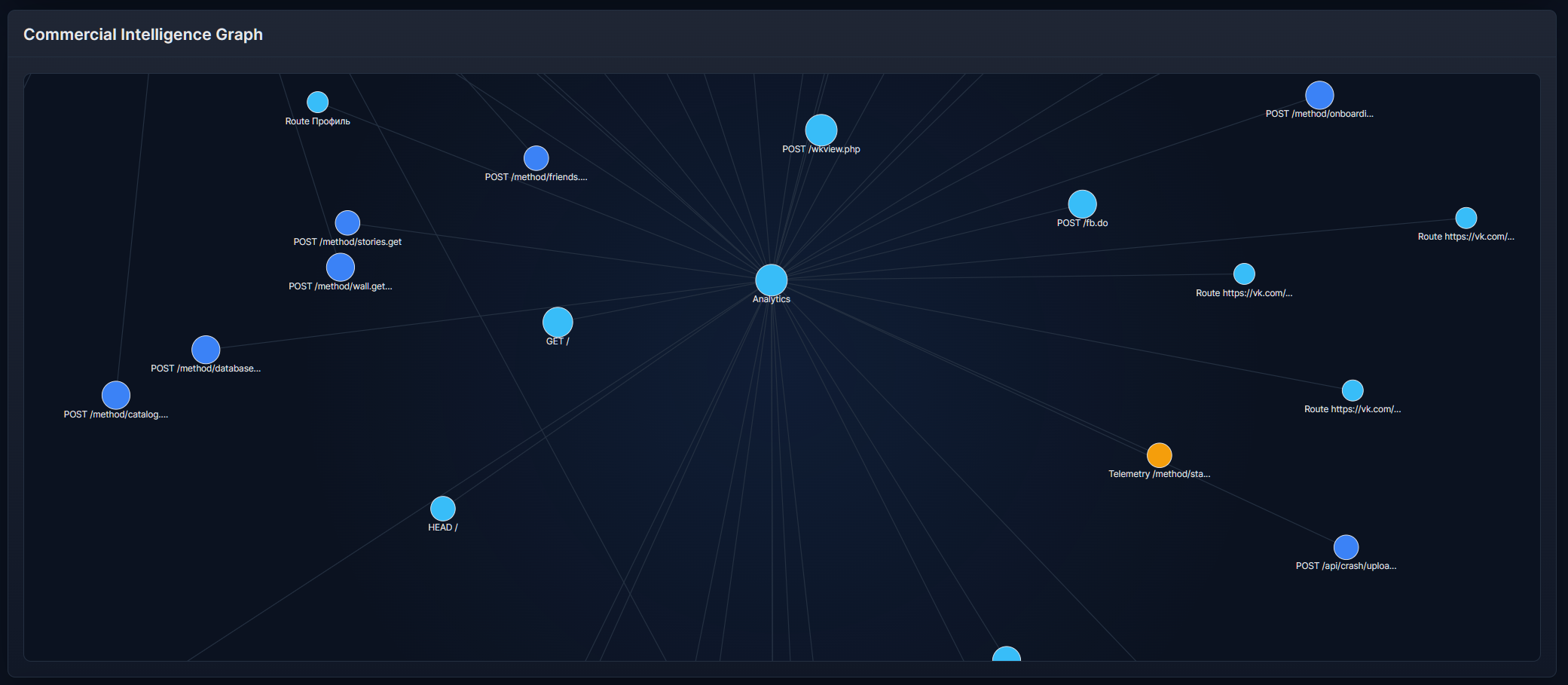
### SiteSnapshotter 通过 DevTools 或浏览器自动化注入到活动页面的浏览器端捕获引擎。 - 记录 DOM、CSS、资产、请求、响应、路由、存储、IndexedDB、Cache Storage 和 Service Worker 信号。 - 支持通过 `watch()` 进行会话记录。 - 生成用于下游分析的 JSON 捕获包。 文档: - [英文 README](./SiteSnapshotter/README.md) - [俄文 README](./SiteSnapshotter/README.ru.md) ### SiteCrawlerSnapshotter Playwright 编排层,用于针对目标站点运行一个连续的浏览器会话。 - 使用持久的 Chromium 配置文件。 - 支持 `auth none|manual|auto|profile`。 - 能够处理重定向和登录流程。 - 发现内部 URL 并记录最终的会话捕获。 文档: - [英文 README](./SiteCrawlerSnapshotter/README.md) - [俄文 README](./SiteCrawlerSnapshotter/README.ru.md) ### SiteReconstructor 离线分析和报告层,将捕获包转换为结构化报告和导出构件。 - 构建架构、API、场景、遥测、存储、实体和安全视图。 - 生成 HTML 报告、Postman 集合、OpenAPI 草稿、TypeScript SDK 草稿和 MockServers。 - 适用于手动捕获和爬虫会话。 文档: - [英文 README](./SiteReconstructor/README.md) - [俄文 README](./SiteReconstructor/README.ru.md)典型工作流
1. 使用 `SiteSnapshotter` 手动捕获浏览器会话,或使用 `SiteCrawlerSnapshotter` 自动捕获。 2. 将生成的捕获文件夹提供给 `SiteReconstructor`。 3. 审查生成的 HTML 门户和导出的构件。 4. 将结果用作工程情报、集成准备、迁移支持或技术尽职调查的输入。适用人群
- 逆向工程师 - 集成团队 - 前端和平台工程师 - 注重安全的分析师 - 迁移和尽职调查团队仓库布局
``` SiteSnapshotter/ browser capture engine SiteCrawlerSnapshotter/ Playwright automation and session crawling SiteReconstructor/ offline report and export pipeline scripts/ auxiliary build and generation scripts docs/ internal notes and working materials ```当前定位
作为一个开源工程工具包,这个仓库已经非常有价值。它在会话捕获、浏览器状态分析、IndexedDB 情报以及技术构件重建方面具有真正的深度。 作为一个商业化的开箱即用平台,它目前还未达到要求。主要差距在于产品打磨、分类的可重复性,以及生成 SDK 和 mock server 等导出内容所需的信任度。 目前实际的理想定位是: - 强大的开源核心工具包 - 专家主导的付费分析 - 利基 B2B/内部平台的潜力许可证
本仓库基于 [MIT 许可证](./LICENSE) 分发。标签:CMS安全, DevTools, DNS枚举, DOM捕获, Homebrew安装, JavaScript, MITM代理, URL抓取, 前端安全, 前端逆向, 多模态安全, 数字取证, 数据可视化, 数据抓取, 数据泄露, 无头浏览器, 浏览器自动化, 浏览器逆向工程, 特征检测, 离线浏览, 离线重构, 站点快照, 网络会话抓取, 网络安全工具, 网络情报收集, 网络请求记录, 自动化爬虫, 自动化脚本, 自定义脚本