u7k4rs6/MIRR
GitHub: u7k4rs6/MIRR
一个用于训练和评估智能体在部分可观测的微服务仿真环境中诊断故障根因并执行恢复操作的实验平台。
Stars: 0 | Forks: 0
# MIRR - 微服务事件响应与恢复
## 这是什么?
一个供智能体在压力下思考的演练场。
MIRR 是一个部分可观测的微服务环境,基于规则的经典智能体、LLM 智能体和 GRPO 训练模型在这里展开竞争,竞相诊断并恢复一个崩溃的分布式系统——在它级联演变为彻底崩溃之前。
五个微服务。一个隐藏故障。充满噪声的指标。以及一个迫使智能体在采取行动前明确提交其推理过程的诊断动作。
你可以在 Gradio 演示中实时观看整个过程,逐帧回放片段,或者训练你自己的模型,看着奖励曲线不断攀升。
## 链接
| 交付物 | 链接 |
|---|---|
| HF Space (实时演示) | 基于此仓库创建一个 Space,然后在此处粘贴你的 URL |
| 训练 Notebook (Colab) | 在 Colab 中打开 - 或从此克隆中上传 `train.ipynb` |
| 源码 / 更新 | [github.com/u7k4rs6/MIRR](https://github.com/u7k4rs6/MIRR) |
| 训练好的模型 | 训练后在 `train.ipynb` 中运行步骤 3。设置 `HF_TOKEN` + `HF_HUB_USERNAME`。默认:`YOUR_USERNAME/incident-response-grpo` |
| Episode 轨迹回放 (数据集) | `train.ipynb` 中的步骤 4。默认:`YOUR_USERNAME/incident-response-rollouts` |
**Hub 上传:**在 Colab(或本地的 `.env`)中设置 `HF_TOKEN` 和 `HF_HUB_USERNAME`,然后运行 `train.ipynb` 的步骤 3 和 4。在本地运行时请复制 `.env.example` 为 `.env`——它已被添加到 `.gitignore` 中。
## 训练曲线
## 设定
这是智能体在每个 episode 中面临的实际问题:
```
Five microservices. One is failing silently.
Metrics are noisy (±15%). Logs cost a step to read.
You don't know which service is broken - and neither do your metrics.
```
智能体的行动顺序如下:
1. **观察 (Observe)** - 收到带有固有噪声的降级健康指标
2. **调查 (Investigate)** - 调用 `check_logs()` 以缩小范围(消耗一个 step)
3. **诊断 (Diagnose)** - 在采取任何操作之前,明确指出根本原因
4. **修复 (Fix)** - 对正确的服务执行 `restart`、`rollback` 或 `scale_up`
5. **确认 (Confirm)** - 观察恢复情况逐渐传导,或者看着情况继续恶化
诊断步骤是整个博弈的核心。正是它将具备推理能力的智能体与靠运气的盲猜者区分开来。
## 为什么“诊断”动作能改变一切
以下是在奖励函数上进行暴力破解的样子:
```
Brute-force: tries all 5 services
→ -2.0 × 4 wrong fix attempts
→ +6.0 on the lucky final hit
= -2.0 total
```
而这才是真正经过推理的样子:
```
Reasoning agent: commits to the right diagnosis first
→ +8.0 correct diagnosis
→ +10.0 correct fix
→ +20.0 full recovery
= 38.0+
```
**一个设计决策就带来了 40 分的巨大差距。**将诊断与修复分开计分,意味着你无法用侥幸的操作来掩盖浅薄的推理。该环境会惩罚盲目自信的错误,并奖励结构化的思考。
## 故障模式
并非所有的故障都是一样的。共有三种模式,每种都有不同的陷阱:
| 模式 | 正确修复 | 陷阱 |
|---|---|---|
| `crashed` | `restart` | 简单直接。 |
| `memory_leak` | `restart` | 有效——但它会在 4 步之后复发。 |
| `overloaded` | `scale_up` | restart 毫无作用。只能看着智能体徒劳挣扎。 |
| `bad_deploy` | `rollback` | restart 反而会雪上加霜。 |
`bad_deploy` 模式是打破简单启发式方法的关键。如果你的智能体的心智模型是“崩溃 = restart”,它就会重启一个糟糕的部署,从而进一步拉低健康分。这是有意为之的。
## 结果
| 智能体 | 成功率 | 诊断准确率 | 平均奖励 |
|---|---|---|---|
| 随机 | 10% | 5% | -8.2 |
| 启发式 (日志感知) | ~68% | ~99% | ~81 |
| 训练后的 LLM | 68% | 61% | 22.7 |
启发式智能体之所以具有近乎完美的诊断准确率,是因为它直接对日志进行模式匹配——它确切知道要寻找什么。训练后的 LLM 达到了同样的成功率,但其路径不同:诊断较为凌乱,但泛化能力更强。在实现相同成功率的情况下,诊断准确率(99% vs 61%)的差距向我们揭示了一个有趣的现象:LLM 能够在 episode 中途从错误的信念中自我纠正。
## 环境设计
```
openenv.yaml - Env metadata (id, thresholds, service list)
env/environment.py - Episodic API: reset / step / render
env/simulator.py - Hidden state, failure propagation, health logic
agent/ - Random, heuristic, and LLM agents
eval/evaluate.py - Evaluation loop + curve generation
train.ipynb - GRPO training notebook (Colab-ready)
app.py - Gradio live demo
training_curves/ - reward_curve.png, loss_curve.png
```
该环境兼容 OpenEnv 规范。`reset()` / `step()` / `render()` 均按规范实现。接入任何兼容的智能体即可运行。
## 设置
**本地运行:**
```
pip install -r requirements.txt
# Windows
set GROQ_API_KEY=your_key_here
set PYTHONPATH=%CD%
# Linux / macOS
export GROQ_API_KEY=your_key_here
export PYTHONPATH="$(pwd)"
python eval/evaluate.py
python app.py
```
**HF Space:**在 Space Secrets 中添加 `GROQ_API_KEY`。应用监听端口为 `PORT`(默认 `7860`)。
## 发布清单
- [ ] 公开 HF Space - 在隐身模式下进行冒烟测试
- [ ] 代码库根目录下包含 `openenv.yaml`
- [ ] `environment.py` 实现了 `reset()` / `step()` / `render()`
- [ ] 已提交 `training_curves/reward_curve.png` 和 `loss_curve.png`
- [ ] `train.ipynb` 可端到端运行;Colab 副本保持同步
- [ ] README 链接指向实际的在线 URL
## 我为什么构建这个
大多数 RL 环境要么过于干净(CartPole、Atari),要么过于不透明(你无法深入探究的生产级基础设施)。
MIRR 介于两者之间——足够复杂以至于暴力破解会失败,又足够结构化以至于你能切实衡量智能体的推理能力。我之所以引入 `diagnose()` 动作,是因为我想看看,强制要求一个明确的承诺步骤是否会改变智能体的行为方式。事实证明确实如此。
GRPO 训练钩子已内置。带上你自己的模型,接入轨迹回放格式,然后观察它是否学会了“三思而后行”。
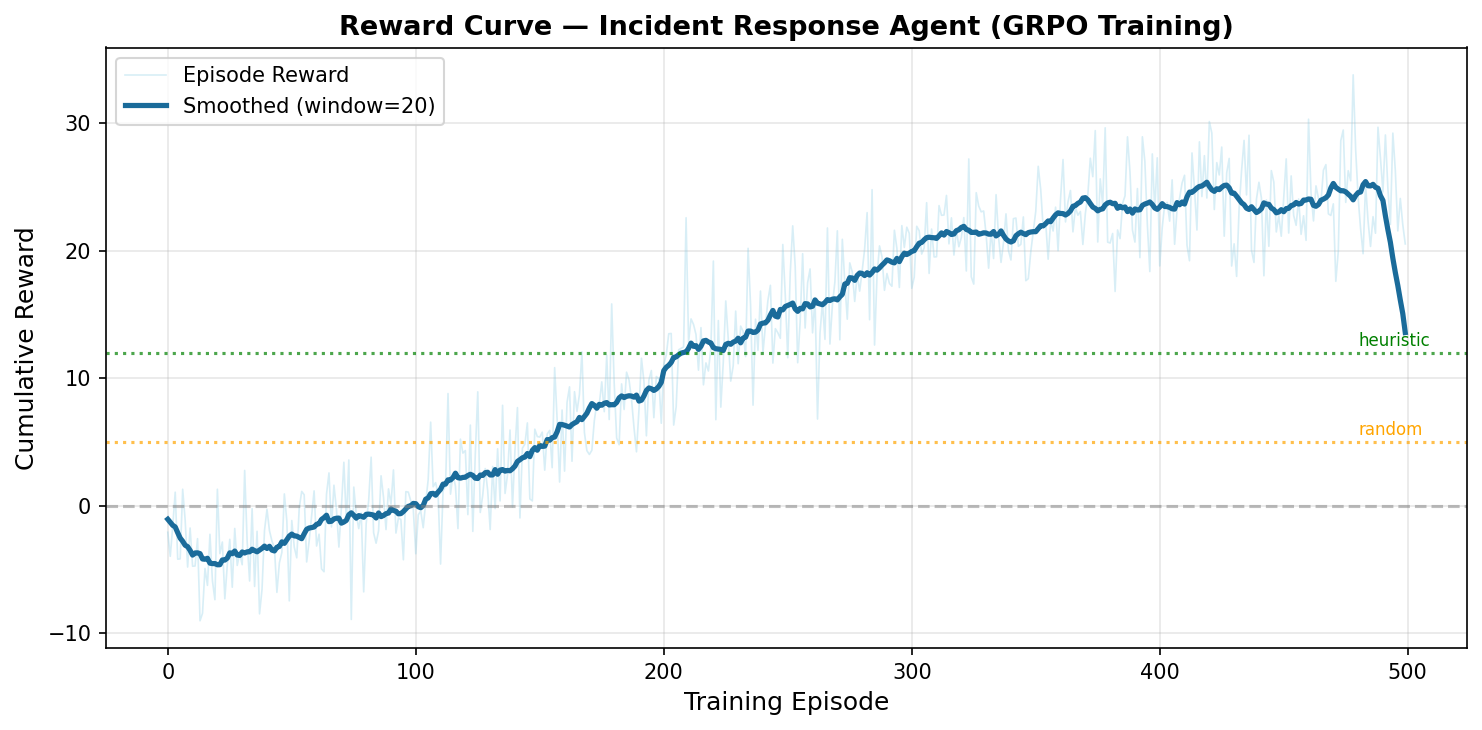 |
 |
| Reward Curve | Loss Curve |
由 Utkarsh Bahuguna 构建与nbsp;· 欢迎提交 PR · 如果它让你有所收获,请点个 Star
标签:AIOps, Gradio, GRPO, SRE, Sysdig, 事故响应, 交互式Demo, 偏差过滤, 分布式系统, 启发式算法, 响应大小分析, 大语言模型Agent, 强化学习, 故障恢复, 故障诊断, 智能体训练, 模拟环境, 系统弹性, 级联故障, 训练评估, 逆向工具, 部分可观测环境