shelf-project/shelf
GitHub: shelf-project/shelf
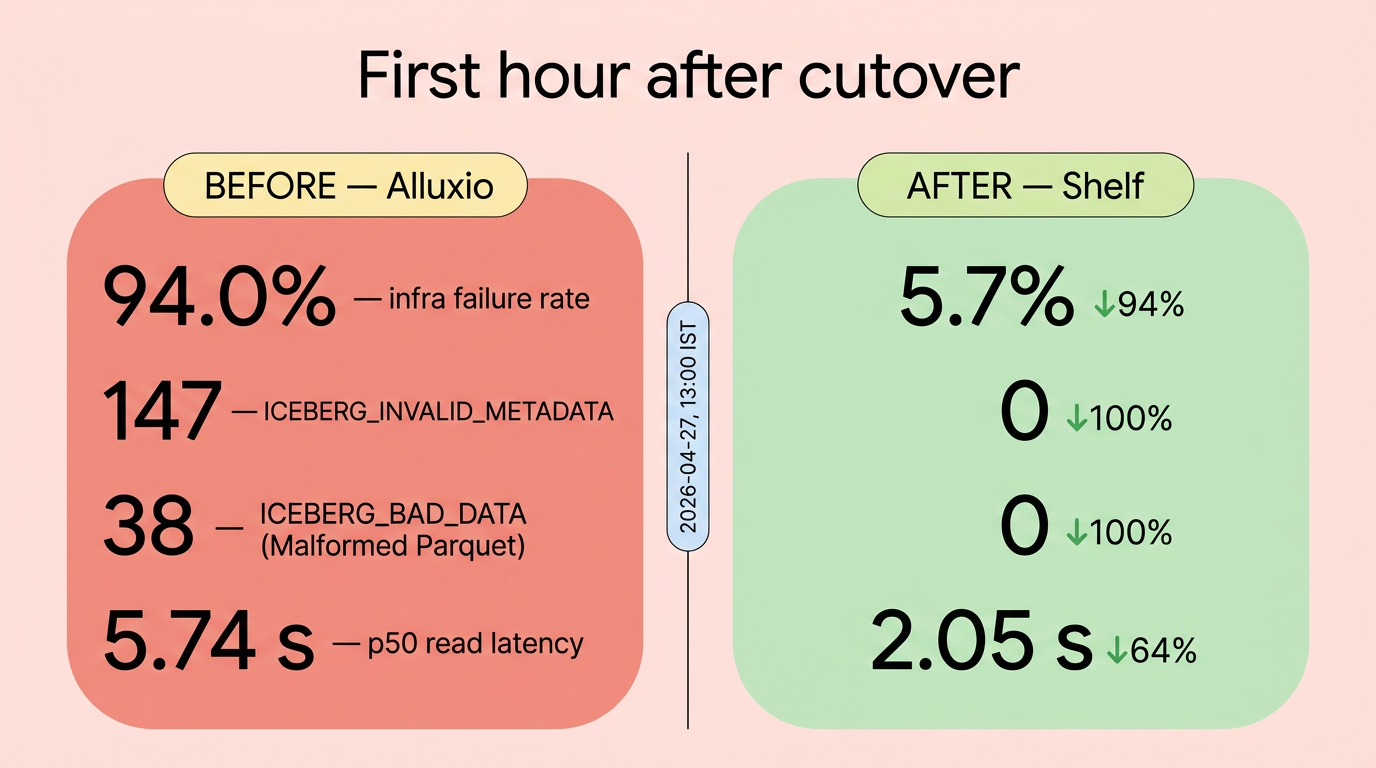
Shelf 是一个用 Rust 编写的、面向 Trino on Iceberg 的行组粒度读取缓存,通过伪装 S3 端点以零侵入方式将 p50 延迟减半、基础设施故障率降至接近零。
Stars: 4 | Forks: 0
# Shelf
. See [LICENSE](./LICENSE) and [NOTICE](./NOTICE) for details.
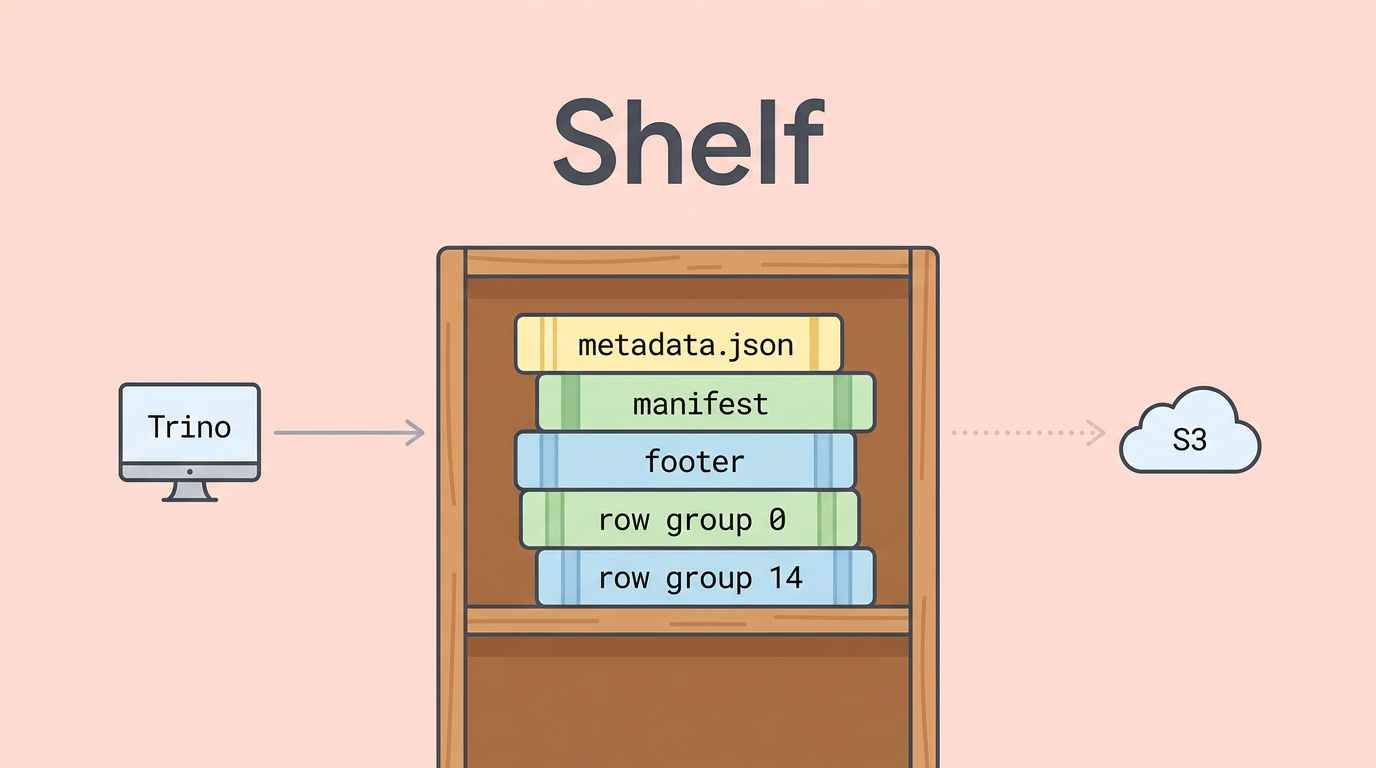
一个行组粒度、计划感知且原生支持 Iceberg 的 Trino 读取缓存。使用 Rust 编写,Apache 2.0 许可证,采用失败开放 (fail-open) 设计。



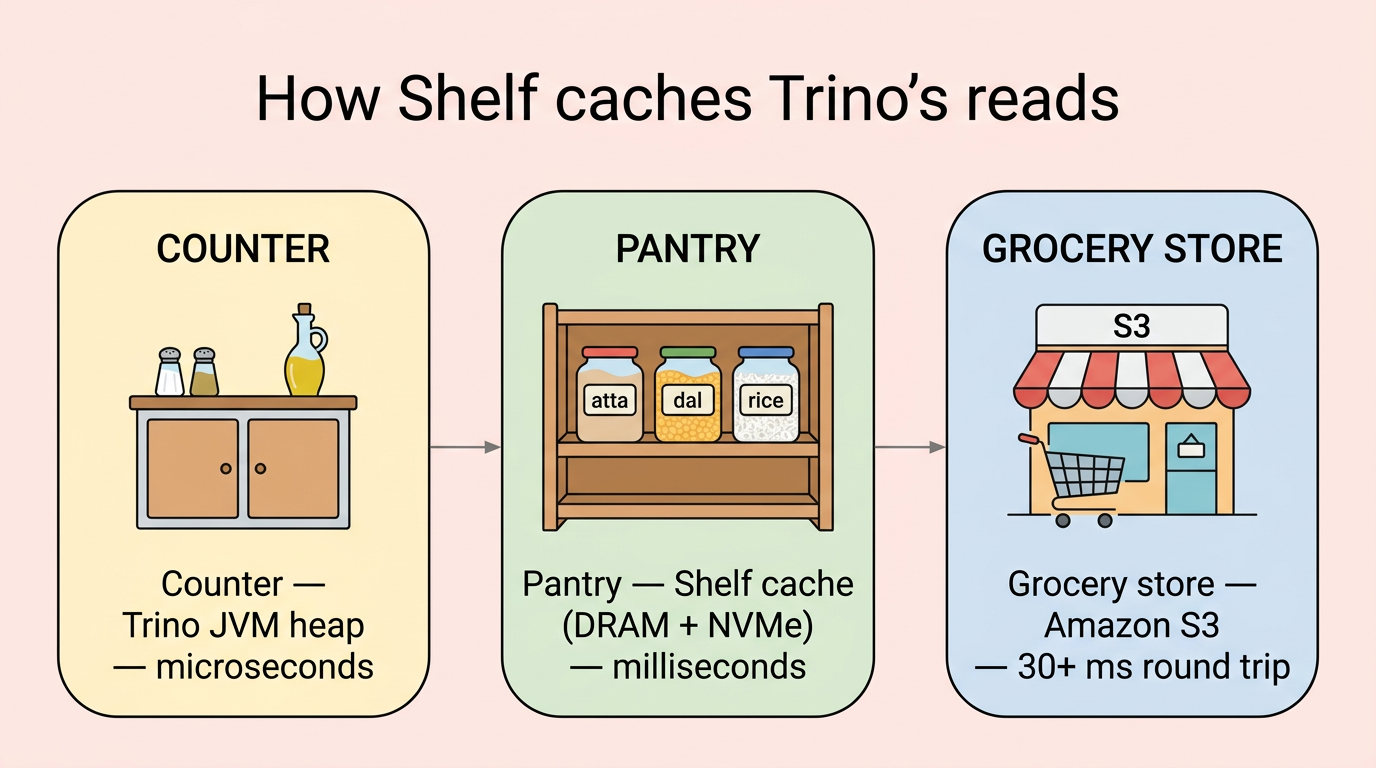
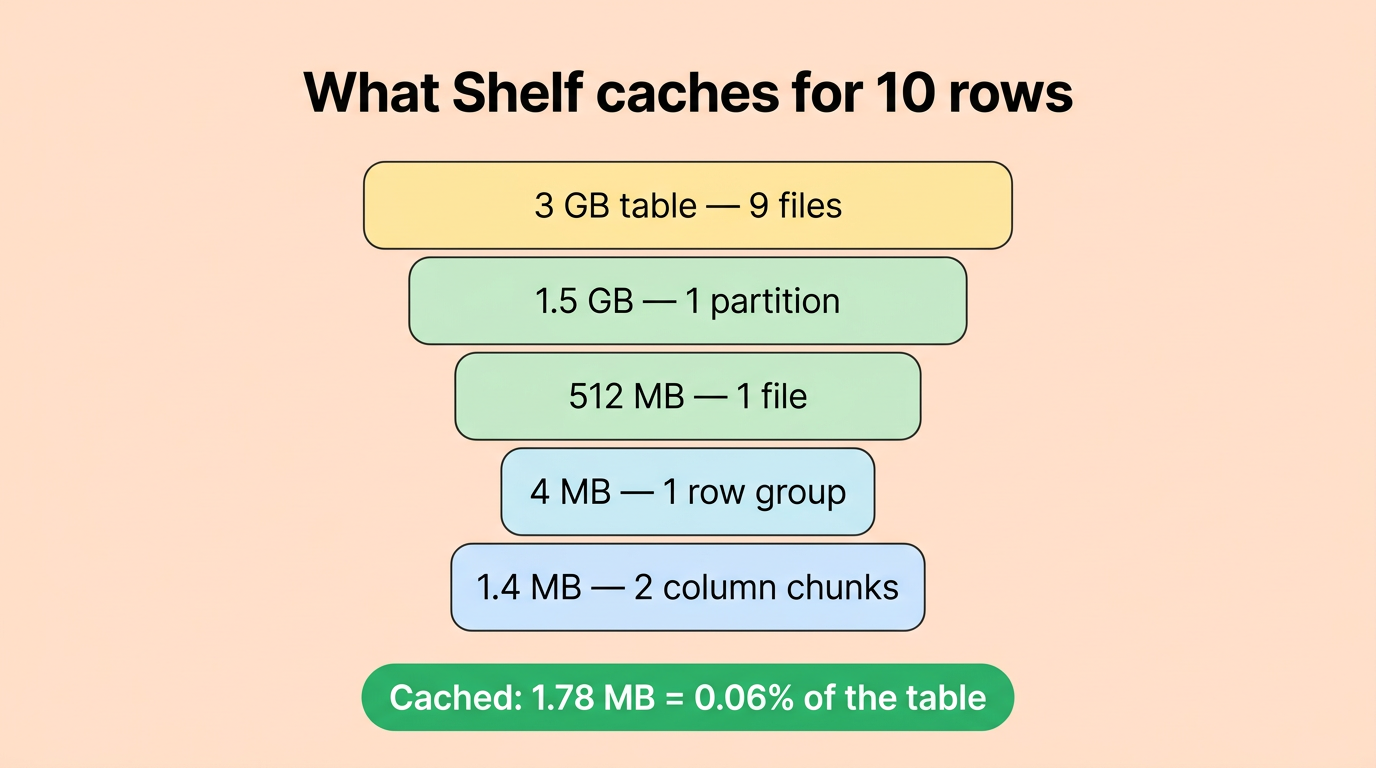
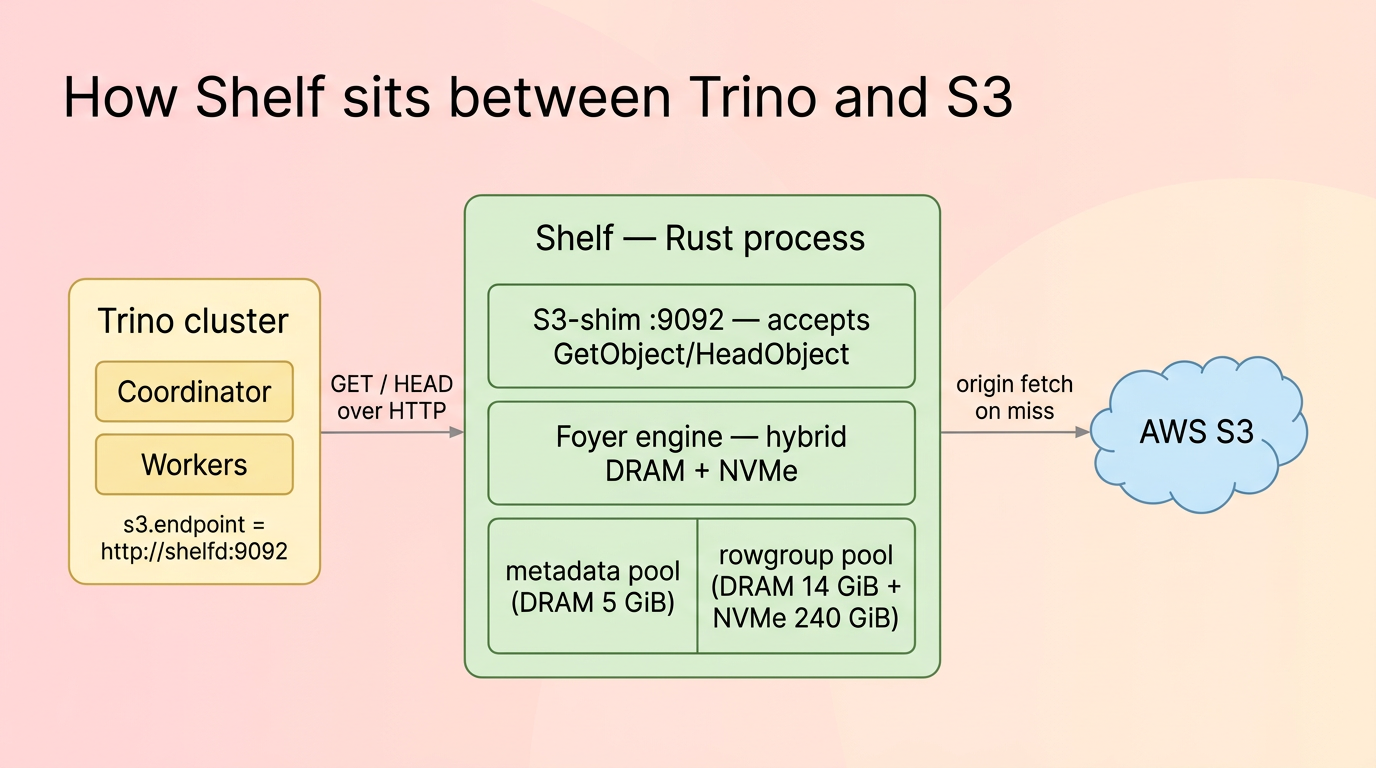

标签:Apache 2.0, DNS解析, DRAM, Fail-open, Gradle集成, HTTP工具, Iceberg, NVMe, Parquet, Rust, S3, S3兼容, Trino, 代理服务, 可视化界面, 基础设施, 大数据, 子域名突变, 对象存储, 延迟优化, 开源项目, 性能优化, 数据湖, 检测绕过, 目录扫描, 缓存, 网络安全审计, 网络流量审计, 行组级缓存, 读取加速, 通知系统