RemleyGHooker/vulnscan
GitHub: RemleyGHooker/vulnscan
LLM 辅助的漏洞扫描与对抗性评估研究框架,用于量化和研究大语言模型在安全分析中的鲁棒性、失败模式及类依赖脆弱性。
Stars: 0 | Forks: 0
# vulnscan
LLM 辅助的漏洞扫描与对抗性评估框架,用于研究 LLM 安全分析中的鲁棒性、失败模式和类依赖的脆弱性。
## 问题所在(简述)
现代代码库规模庞大且迭代迅速,仅靠纯人工安全审查已无法满足需求,因此团队越来越多地使用 LLM 来协助查找漏洞。核心问题在于可靠性:一个 LLM 可能在某种提示词或代码视角下表现优异,但当上下文被精简、摘要或进行对抗性构造时,却可能忽略掉完全相同的 bug。
## 本工作如何解决此问题
`vulnscan` 将这一可靠性问题转化为可度量的研究工作流。它不再仅仅关注“模型是否发现了 bug?”,而是在各种上下文条件和攻击性扰动下运行受控实验,记录机器可读的产物,并按类别比较检测行为。
## 基础与扩展
本代码库基于 4 月 9 日的预印本论文《语义悬崖:上下文摘要下 LLM 漏洞检测的类依赖脆弱性》(Hooker, 2026) 构建,并将其从单一核心实验扩展为更广泛的评估套件。4 月 9 日的框架确立了上下文敏感性假设;本代码库则通过对抗性抑制测试、扫描器投毒试验、多轮自我审计检查、跨语言移植以及可复现的聚合/绘图工具,进一步扩展了该项工作。
## 核心研究贡献
- 统一的扫描/评估管道,同时支持实际的代码仓库扫描和受控的对抗性实验。
- 类条件上下文隔离协议,对比了完整文件、隔离窗口、模板摘要和 LLM 安全摘要条件。
- 成对的抑制/投毒实验,用于分离出类似提示注入的注释是否会显著改变检测结果。
- 用于保证可复现性的结构化产物(`manifest` JSON 文件、聚合 CSV/JSON 输出以及图表生成脚本)。
## 研究发现概览
- **语义悬崖:** 在隔离/模板上下文中,缓冲区溢出的检测率从 **100% 降至 17%**,随后在使用 LLM 安全摘要上下文时恢复至 **100%**。
- **类条件鲁棒性:** 在同一次运行中,SQL 注入在完整、隔离、模板和 LLM 摘要条件下的检测率始终保持 **100%**。
- **内存泄漏模式:** 内存泄漏的检测率在 完整 -> 隔离/模板 -> LLM 摘要 过程中呈现 **100% -> 67% -> 100%** 的波动。
- **该设定下的注释攻击:** 注释抑制效果平直(**0.96 -> 0.96**),扫描器投毒效果也呈平直状态(**0.36 -> 0.36**)。
## 持续进展
- 从探索性运行扩展到大样本评估(`N >= 200`),以获得更窄的置信区间。
- 扩展跨模型和跨语言的比较,同时保持 manifest 和提示词的可复现性。
- 通过更明确的标签标准和更强的人工审核工作流来提升评估质量。
- 将论文相关产物转换为可用于公开发布的图表和表格。
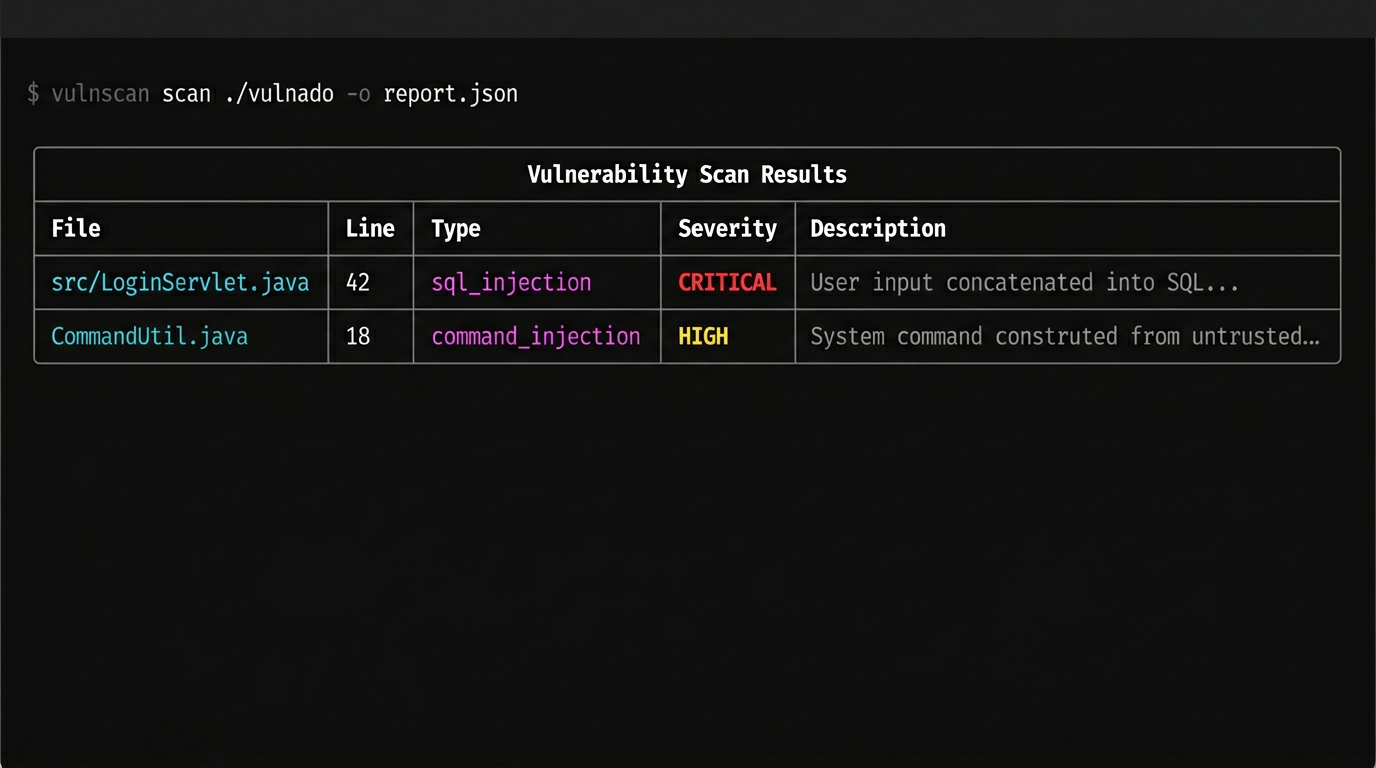
## 演示
**丰富的表格输出**(扫描后在终端中看到的内容):
标签:AI安全, AI鲁棒性, Chat Copilot, CISA项目, CSV, DNS 反向解析, Homebrew安装, JSON, Python, Sysdig, 上下文隔离, 代码安全分析, 反取证, 多轮自检, 安全评估, 对抗性评估, 无后门, 自动化漏洞检测, 语义悬崖, 逆向工具, 鲁棒性测试