# FreeLLMAPI
**One OpenAI-compatible endpoint. Sixteen free LLM providers. ~1.7B tokens per month.**
Aggregate the free tiers from Google, Groq, Cerebras, NVIDIA, Mistral, OpenRouter, GitHub Models, Cohere, Cloudflare, HuggingFace, Z.ai (Zhipu), Ollama, Kilo, Pollinations, LLM7, OVH AI Endpoints, and OpenCode Zen — plus any custom OpenAI-compatible endpoint (llama.cpp, LM Studio, vLLM, local Ollama) — behind a single `/v1/chat/completions` endpoint. Keys are stored encrypted. A router picks the best available model for each request, falls over to the next provider when one is rate-limited, and tracks per-key usage so you stay under every free-tier cap.
[](https://github.com/tashfeenahmed/freellmapi/actions/workflows/ci.yml)
[](./LICENSE)
[](#contributing)
[](https://github.com/tashfeenahmed/freellmapi/pkgs/container/freellmapi)
**[freellmapi.co](https://freellmapi.co)** — browse the live model catalog
## Contents
- [Why this exists](#why-this-exists)
- [Supported providers](#supported-providers)
- [Features](#features)
- [Not yet supported](#not-yet-supported)
- [Quick start](#quick-start)
- [Docker](#docker)
- [Desktop app](#desktop-app)
- [Premium (live catalog)](#premium-live-catalog)
- [Using the API](#using-the-api)
- [Screenshots](#screenshots)
- [How it works](#how-it-works)
- [Context Handoff](#context-handoff)
- [Limitations](#limitations)
- [Contributing](#contributing)
- [Terms of Service review](#terms-of-service-review)
- [Disclaimer](#disclaimer)
## Why this exists
Every serious AI lab now offers a free tier — a few million tokens a month, a few thousand requests a day. On its own each tier is a toy. Stacked together, they add up to roughly **1.7 billion tokens per month** of working inference capacity, across 100+ models from small-and-fast to reasonably capable.
The problem is that stacking them by hand is painful: seventeen different SDKs, seventeen different rate limits, seventeen places a request can fail. FreeLLMAPI collapses that into one OpenAI-compatible endpoint. Point any OpenAI client library at your local server, and it routes transparently across whichever providers you've added keys for.
## Supported providers
Plus a **custom** provider — point at any OpenAI-compatible endpoint (llama.cpp, LM Studio, vLLM, a local Ollama, or a remote gateway) from the Keys page.
## Features
- **OpenAI-compatible** — `POST /v1/chat/completions` and `GET /v1/models` work with the official OpenAI SDKs and any OpenAI-compatible client (LangChain, LlamaIndex, Continue, Hermes, etc.). Just change `base_url`.
- **Responses API** — `POST /v1/responses` (the wire format current Codex CLI versions require) is implemented as a translating shim over the same router, with full streaming events and tool calls.
- **Streaming and non-streaming** — Server-Sent Events for `stream: true`, JSON response otherwise. Every provider adapter implements both.
- **Tool calling** — OpenAI-style `tools` / `tool_choice` requests are passed through, and assistant `tool_calls` + `tool` role follow-up messages round-trip across providers.
- **Embeddings** — `/v1/embeddings` with family-based routing: failover only ever happens between providers serving the *same* model (vectors from different models are incompatible), never across models. See [Embeddings](#embeddings).
- **Automatic fallover** — If the chosen provider returns a 429, 5xx, or times out, the router skips it, puts the key on a short cooldown, and retries on the next model in your fallback chain (up to 20 attempts).
- **Per-key rate tracking** — RPM, RPD, TPM, and TPD counters per `(platform, model, key)` so the router always picks a key that's under its caps.
- **Sticky sessions** — Multi-turn conversations keep talking to the same model for 30 minutes to avoid the hallucination spike that comes from mid-conversation model switches.
- **Encrypted key storage** — API keys are encrypted with AES-256-GCM before hitting SQLite; decryption happens in-memory just before a request.
- **Unified API key** — Clients authenticate to your proxy with a single `freellmapi-…` bearer token. You never expose upstream provider keys to your apps.
- **Dashboard login** — The admin UI and all `/api/*` routes are gated behind an email + password account (scrypt-hashed, session-token auth), set on first run. The `/v1` proxy keeps its own unified-key auth for apps.
- **Health checks** — Periodic probes mark keys as `healthy`, `rate_limited`, `invalid`, or `error` so the router skips dead ones automatically.
- **Admin dashboard** — React + Vite UI to manage keys, reorder the fallback chain, inspect analytics, and run prompts in a playground. Dark mode included.
- **Analytics** — Per-request logging with latency, token counts, success rate, and per-provider breakdowns.
- **Context handoff on model switch** — Optional. When a session falls over to a different model, injects one compact system message so the new model knows it is continuing an existing task. Disabled by default; enable with `FREELLMAPI_CONTEXT_HANDOFF=on_model_switch`. See [Context Handoff](#context-handoff).
- **Runs anywhere Node 20+ runs** — Windows, macOS, Linux servers, or a small ARM SBC (Raspberry Pi included). ~40 MB RSS at idle behind PM2 / systemd / whatever supervisor you prefer.
## Not yet supported
The scope is deliberately narrow. If a feature isn't on this list and isn't below, assume it isn't there yet.
- **Image generation** (`/v1/images/*`)
- **Audio / speech** (`/v1/audio/*`)
- **Legacy completions** (`/v1/completions`) — only the chat endpoint is implemented
- **Moderation** (`/v1/moderations`)
- **`n > 1`** (multiple completions per request)
- **Per-user billing / multi-tenant auth** — single-user by design
PRs that add any of these are very welcome. See [Contributing](#contributing).
## Quick start
**One-liner** (Docker required — sets up `~/freellmapi`, generates an encryption key, pulls the image, and starts the container):
curl -fsSL https://freellmapi.co/install.sh | bash
Prefer to read before you pipe to bash? [The script is here](https://freellmapi.co/install.sh). Re-running it is safe: your `.env` (and encryption key) is preserved and the container updates to `:latest`. Override the defaults with `FREELLMAPI_DIR`, `PORT`, or `HOST_BIND` env vars.
On Windows, the easiest path is the desktop **[`.exe` installer from Releases](https://github.com/tashfeenahmed/freellmapi/releases/latest)** (below); the Docker steps work in WSL or any bash shell.
**Or manually with Docker Compose.** It runs the API and dashboard together on port 3001 and persists SQLite in a named volume.
**Prerequisites:** Docker, Docker Compose, OpenSSL.
git clone https://github.com/tashfeenahmed/freellmapi.git
cd freellmapi
# Generate an encryption key for at-rest key storage
ENCRYPTION_KEY="$(openssl rand -hex 32)"
printf "ENCRYPTION_KEY=%s\nPORT=3001\n" "$ENCRYPTION_KEY" > .env
docker compose up -d
Open http://localhost:3001, add your provider keys on the **Keys** page, reorder the **Fallback Chain** to taste, and grab your unified API key from the **Keys** page header. That unified key is what you point your OpenAI SDK at.
### Local development
**Prerequisites:** Node.js 20+, npm.
git clone https://github.com/tashfeenahmed/freellmapi.git
cd freellmapi
npm install
cp .env.example .env
ENCRYPTION_KEY="$(node -e 'console.log(require("crypto").randomBytes(32).toString("hex"))')"
printf "ENCRYPTION_KEY=%s\nPORT=3001\n" "$ENCRYPTION_KEY" > .env
npm run dev
`ENCRYPTION_KEY` is required for startup. The server only falls back to a
database-stored development key when `DEV_MODE=true` and `NODE_ENV` is not
`production`; do not use that fallback with real provider keys.
Request analytics are retained for 90 days or 100000 request rows by default,
whichever limit prunes first. Set `REQUEST_ANALYTICS_RETENTION_DAYS=0` or
`REQUEST_ANALYTICS_MAX_ROWS=0` in `.env` to disable either retention limit.
Open http://localhost:5173 (the Vite dev UI), add your provider keys on the **Keys** page, reorder the **Fallback Chain** to taste, and grab your unified API key from the **Keys** page header. That unified key is what you point your OpenAI SDK at.
For a production build without Docker:
npm run build
node server/dist/index.js # server + dashboard both served on :3001
## Docker
FreeLLMAPI publishes a single production image that contains the Express server and the built React dashboard:
docker pull ghcr.io/tashfeenahmed/freellmapi:latest # or pin a release, e.g. :v1.2.3
The image is multi-arch (`linux/amd64` + `linux/arm64`, so it runs on a Raspberry Pi). Published tags: `latest` (default branch), `v*.*.*` (git release tags), and `sha-
`.
The included `docker-compose.yml` is the recommended install path:
docker compose up -d
docker compose logs -f freellmapi
By default the container's port is bound to `127.0.0.1` (localhost only). To reach the dashboard/API from another machine on your network, publish it on all interfaces with `HOST_BIND=0.0.0.0 docker compose up -d` — only on a trusted LAN, since the proxy is single-user.
SQLite data is stored in the `freellmapi-data` volume at `/app/server/data`. Keep the same `.env` `ENCRYPTION_KEY` and volume when upgrading, because provider keys are encrypted at rest.
More Docker operations and examples live in [docker/README.md](./docker/README.md).
## Desktop app
A native menu-bar app lives in [`desktop/`](./desktop): the entire router +
dashboard running locally from your tray, with a glass popover showing live
request stats.
**[Download from Releases](https://github.com/tashfeenahmed/freellmapi/releases/latest)** — the macOS `.dmg` and the Windows `.exe` installer are built and attached to every release by the [`desktop-release`](.github/workflows/desktop-release.yml) workflow. Or build it from this repo in a few minutes:
npm install
npm run desktop:dist # macOS → desktop/dist-electron/FreeLLMAPI-…-arm64.dmg
npm run desktop:dist:win # Windows → "desktop/dist-electron/FreeLLMAPI Setup ….exe"
## Premium (live catalog)
The router keeps its model catalog fresh on its own: it pulls a signed catalog
from [freellmapi.co](https://freellmapi.co) twice a day and applies new models,
quota changes, and provider quirk fixes to your local DB (your own enable/disable
choices and custom providers are never touched; every download is verified
against a pinned Ed25519 key before it is applied).
- **Free** installs follow a **monthly snapshot** — zero cost, forever.
- **[Premium](https://freellmapi.co/#pricing)** ($19/yr or $49 lifetime) follows
the **live feed**, refreshed every 2-3 days, so new free models are in your
router the moment they exist. One key covers all your devices; activate it in
the dashboard under **Premium**. Cancel or manage billing self-serve at
[freellmapi.co/manage](https://freellmapi.co/manage).
The catalog server never sees your prompts, completions, or provider keys — the
router stays fully self-hosted either way.
Locally built apps launch without Gatekeeper/SmartScreen warnings — no code
signing involved. Full instructions in [desktop/README.md](./desktop/README.md).
## Using the API
Any OpenAI-compatible client works. Examples:
**Python**
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:3001/v1",
api_key="freellmapi-your-unified-key",
)
resp = client.chat.completions.create(
model="auto", # let the router pick; or specify e.g. "gemini-2.5-flash"
messages=[{"role": "user", "content": "Summarise the fall of Rome in one sentence."}],
)
print(resp.choices[0].message.content)
print("Routed via:", resp.headers.get("x-routed-via"))
**curl**
curl http://localhost:3001/v1/chat/completions \
-H "Authorization: Bearer freellmapi-your-unified-key" \
-H "Content-Type: application/json" \
-d '{
"model": "auto",
"messages": [{"role": "user", "content": "hi"}]
}'
**Streaming**
stream = client.chat.completions.create(
model="auto",
messages=[{"role": "user", "content": "Stream me a haiku about SQLite."}],
stream=True,
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="", flush=True)
**Tool calling**
Pass OpenAI-style `tools` and `tool_choice`; the assistant response round-trips back through the proxy exactly like the OpenAI API. Multi-step flows (assistant `tool_calls` → `tool` role follow-up → final answer) work across every provider the router can reach.
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city.",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
# 1. Model asks for a tool call
first = client.chat.completions.create(
model="auto",
messages=[{"role": "user", "content": "What's the weather in Karachi?"}],
tools=tools,
tool_choice="required",
)
call = first.choices[0].message.tool_calls[0]
# 2. You execute the tool, feed the result back
final = client.chat.completions.create(
model="auto",
messages=[
{"role": "user", "content": "What's the weather in Karachi?"},
first.choices[0].message,
{"role": "tool", "tool_call_id": call.id, "content": '{"temp_c": 32, "cond": "sunny"}'},
],
tools=tools,
)
print(final.choices[0].message.content)
**Gemini Google Search grounding**
Google's models can ground their answers in live Google Search results. Since the OpenAI wire format has no way to express that, request a tool named `google_search` and the Google provider translates it into Gemini's native grounding tool. It can be sent on its own or alongside your normal function tools.
resp = client.chat.completions.create(
model="gemini-2.5-flash", # pin a Google model so the request routes there
messages=[{"role": "user", "content": "Who won the F1 race this weekend?"}],
tools=[{"type": "function", "function": {"name": "google_search", "parameters": {}}}],
)
print(resp.choices[0].message.content)
**Vision / image input**
Send images with the standard OpenAI `image_url` content blocks (base64 `data:` URLs or `http(s)` URLs). When a request contains an image, the router restricts itself to **vision-capable models** and ignores text-only ones. Vision models are tagged with a **Vision** badge on the Fallback Chain page; the current set includes Gemini (2.5 / 3.x), Llama 4 Scout/Maverick (Groq, NVIDIA), GLM-4.6V Flash (Z.ai), Nemotron Nano 12B VL (OpenRouter), and GitHub's GPT-4o / GPT-4.1.
resp = client.chat.completions.create(
model="auto", # auto-routes to a vision model
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{"type": "image_url", "image_url": {"url": "data:image/png;base64,<...>"}},
],
}],
)
print(resp.choices[0].message.content)
If no vision-capable model is enabled in your Fallback Chain, an image request returns a clear `422` (`code: "no_vision_model"`) rather than silently dropping the image. (Image input on `/v1/responses` isn't supported yet — use `/v1/chat/completions`.)
Works with `stream=True` as well — you'll get `delta.tool_calls` chunks followed by a `finish_reason: "tool_calls"` close. Under the hood, OpenAI-compatible providers (Groq, Cerebras, Mistral, OpenRouter, GitHub Models, HuggingFace, Cloudflare, Cohere compat) get the request passed through; Gemini requests get translated into Google's `functionDeclarations` / `functionResponse` shape and the response is translated back.
Every response carries an `X-Routed-Via: /` header so you can see which provider actually served each call. If a request fell over between providers, you'll also see `X-Fallback-Attempts: N`.
### Embeddings
`/v1/embeddings` is OpenAI-compatible, with one deliberate difference from chat routing: **failover never crosses models.** Vectors from different models live in incompatible spaces — silently switching models would corrupt any vector store built on top of the proxy. So embeddings route by **family** (one model identity + dimension), and failover only walks the providers serving that same family.
resp = client.embeddings.create(
model="auto", # default family; or a family name like "bge-m3"
input=["the quick brown fox", "pack my box with five dozen liquor jugs"],
)
print(len(resp.data), "vectors of", len(resp.data[0].embedding), "dims")
curl http://localhost:3001/v1/embeddings \
-H "Authorization: Bearer freellmapi-your-unified-key" \
-H "Content-Type: application/json" \
-d '{"model": "auto", "input": "hello world"}'
`model` accepts `auto` (the configured default family), a family name, or a provider-specific model id (which resolves to its family). Available families:
| Family (`model`) | Dims | Providers (failover order) |
| --- | --- | --- |
| `gemini-embedding-001` *(default)* | 3072 | Google |
| `text-embedding-3-large` | 3072 | GitHub Models |
| `text-embedding-3-small` | 1536 | GitHub Models |
| `embed-v4.0` | 1536 | Cohere |
| `bge-m3` | 1024 | Cloudflare → Hugging Face |
| `qwen3-embedding-0.6b` | 1024 | Cloudflare |
| `nv-embedqa-e5-v5` | 1024 | NVIDIA |
| `llama-nemotron-embed-1b-v2` | 2048 | NVIDIA |
| `llama-nemotron-embed-vl-1b-v2` | 2048 | NVIDIA → OpenRouter |
| `embeddinggemma-300m` | 768 | Cloudflare |
The default family, per-provider toggles, and priorities live on the dashboard's **Models → Embeddings** page. Pick your family once and stick with it for a given vector store — that's the whole point of the family model.
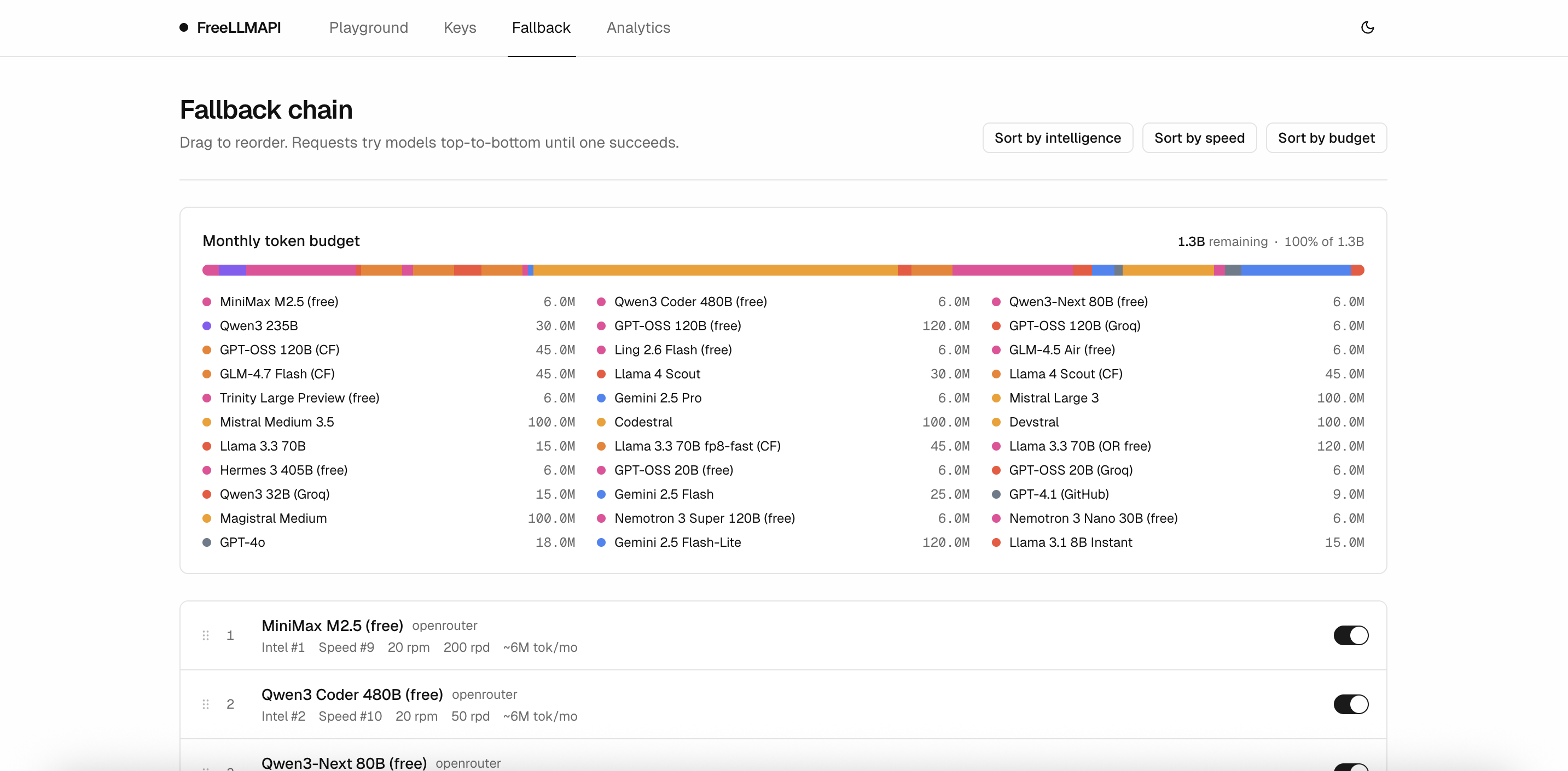
## Screenshots
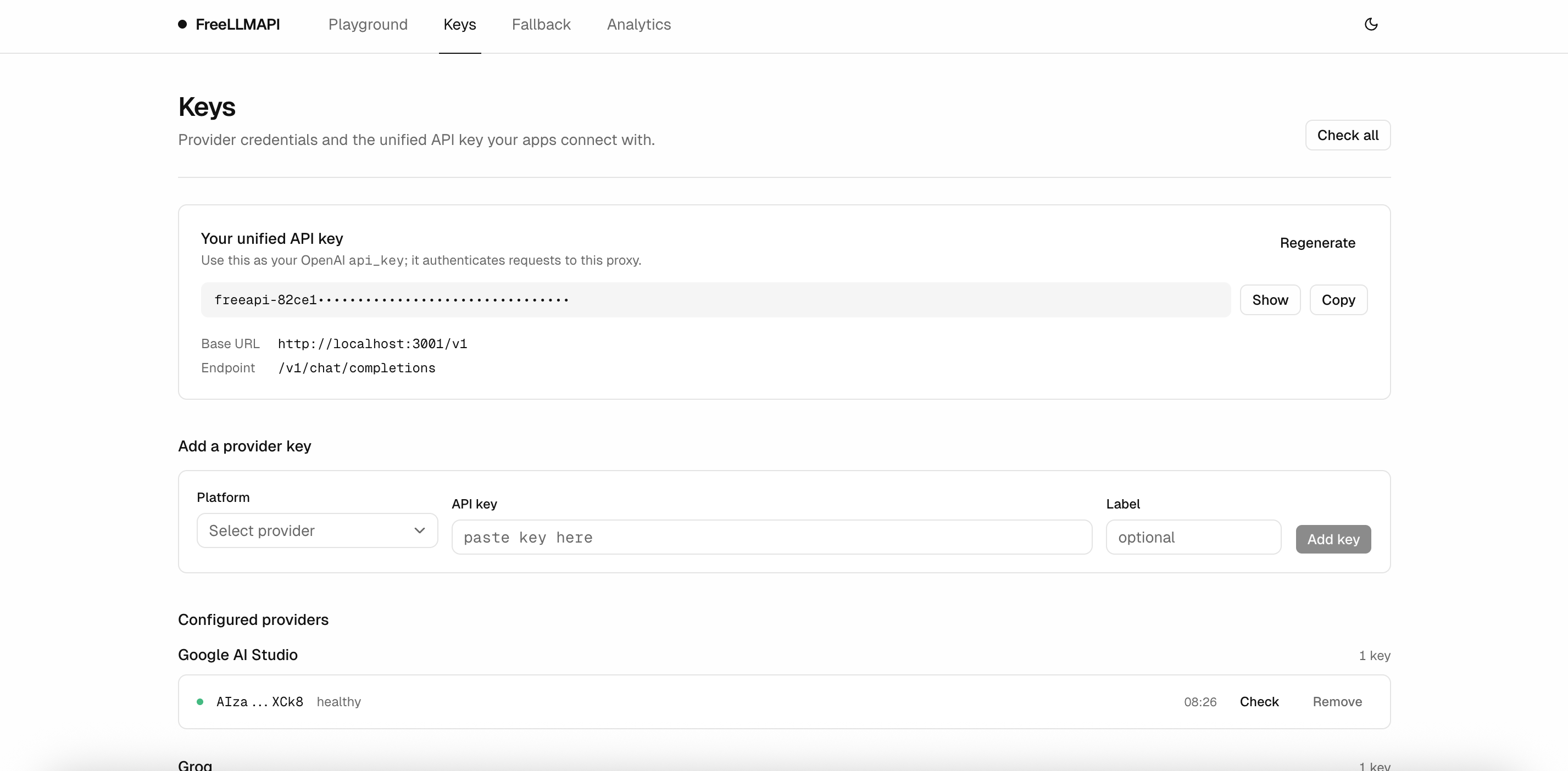
### Keys
Manage provider credentials and grab the unified API key your apps connect with. Each key shows a status dot and when it was last health-checked.
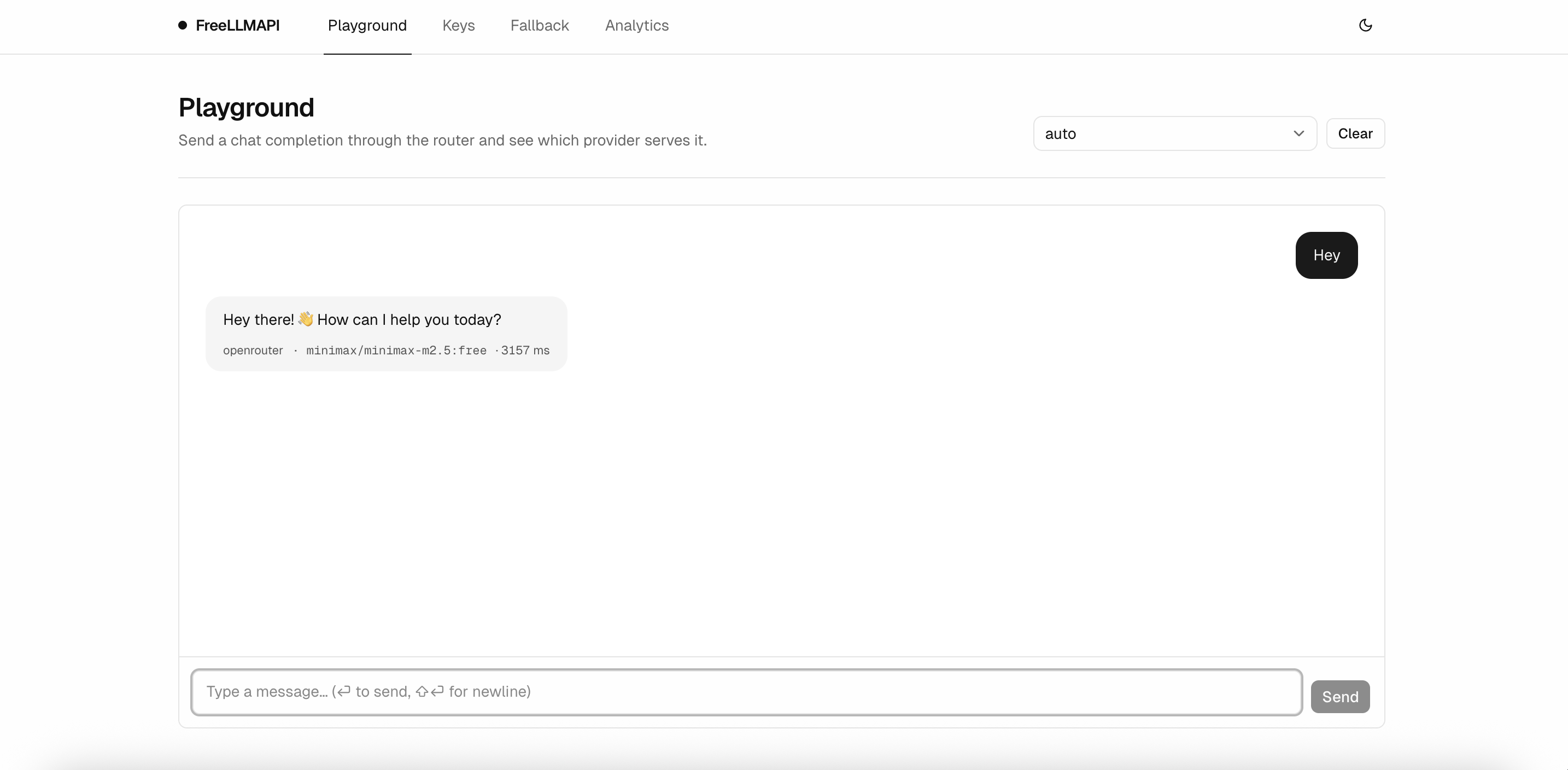
### Playground
Send a chat completion through the router and see which provider served it, with the model ID and latency printed right on the message.
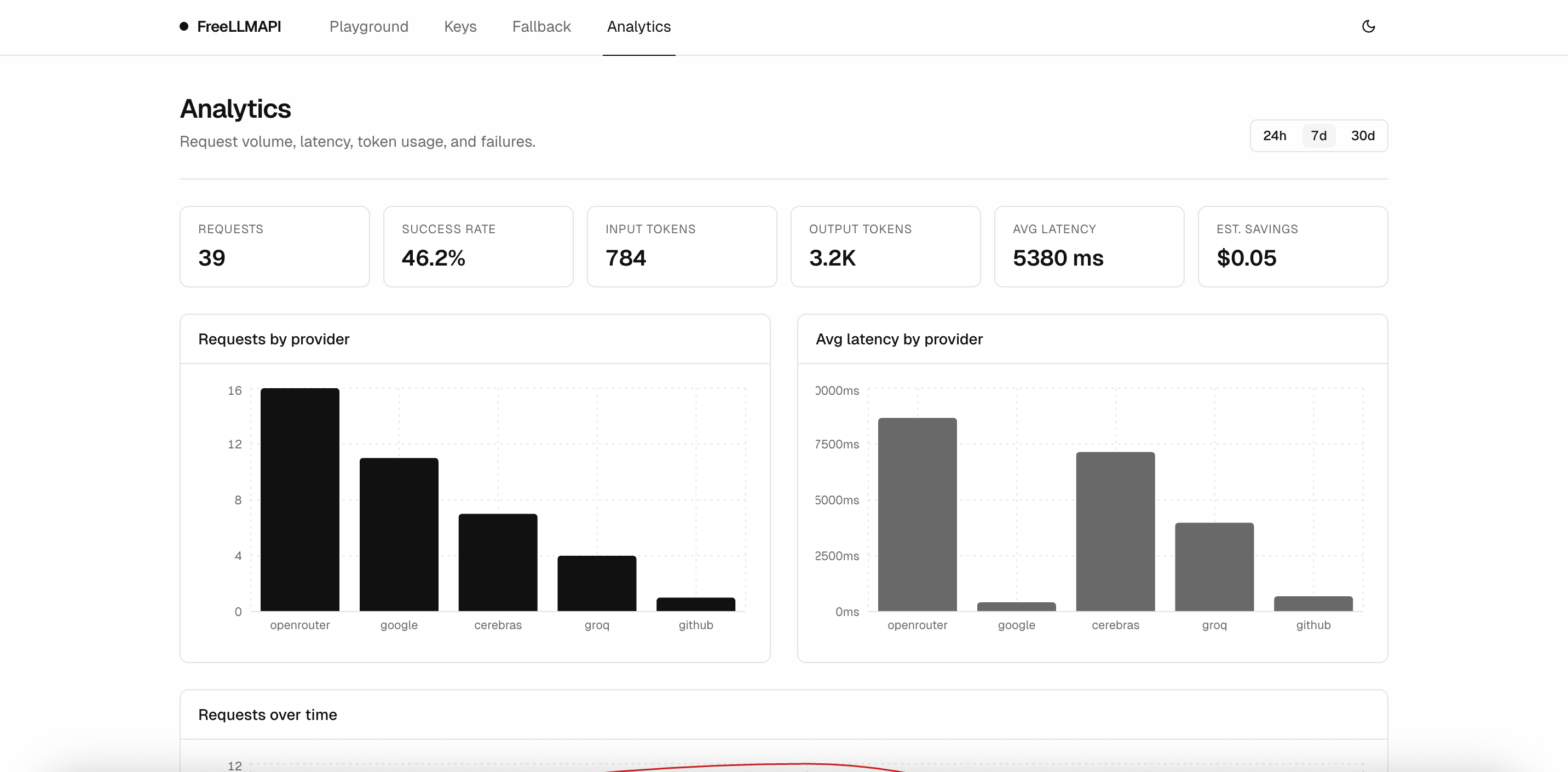
### Analytics
Request volume, success rate, tokens in and out, average latency, and per-provider breakdowns over 24h / 7d / 30d windows.
## How it works
┌──────────────────┐ Bearer freellmapi-… ┌─────────────────────────┐
│ OpenAI SDK / │ ──────────────────────▶ │ Express proxy (:3001) │
│ curl / any │ ◀────────────────────── │ /v1/chat/completions │
│ OpenAI client │ streamed tokens └────────────┬────────────┘
└──────────────────┘ │
▼
┌────────────────────────────────────────────────┐
│ Router │
│ 1. Pick highest-priority model that │
│ (a) has a healthy key and │
│ (b) is under all its rate limits. │
│ 2. Decrypt key, call provider SDK. │
│ 3. On 429/5xx → cooldown + retry next model. │
└────────────────────────────────────────────────┘
│
┌──────────────┬────────────┬──────────┴─────────┬─────────────┬──────────┐
▼ ▼ ▼ ▼ ▼ ▼
Google Groq Cerebras OpenRouter HF …10 more
- **Router** (`server/src/services/router.ts`) — picks a model per request.
- **Rate-limit ledger** (`server/src/services/ratelimit.ts`) — in-memory RPM/RPD/TPM/TPD counters backed by SQLite, with cooldowns on 429s.
- **Provider adapters** (`server/src/providers/*.ts`) — one file per provider, implementing the `Provider` base class: `chatCompletion()` and `streamChatCompletion()`.
- **Health service** (`server/src/services/health.ts`) — periodic probe keeps key status fresh.
- **Dashboard** (`client/`) — React + Vite + shadcn/ui admin surface.
- **Storage** — SQLite (`better-sqlite3`) with AES-256-GCM envelope encryption for keys.
## Context Handoff
When FreeLLMAPI falls over to a different model mid-conversation (quota, rate limit, cooldown), the new model has no idea it is picking up someone else's task. **Context handoff** adds a single compact `system` message to the outbound request that tells the new model exactly that:
FreeLLMAPI context handoff:
You are taking over an ongoing conversation from another model (groq:llama-3 → google:gemini-flash).
Continue the user's task using the conversation context already provided in this request.
Do not restart the task, re-ask already answered setup questions, or discard prior tool results.
Respect the user's latest message as the highest-priority instruction.
Recent session summary:
User: …
Assistant: …
**Enable it in `.env`:**
FREELLMAPI_CONTEXT_HANDOFF=on_model_switch
**How it works:**
- Messages per session are stored in memory (TTL: 3 hours).
- Only injected when the selected model changes for a given session key.
- Not injected on the first request, on same-model continuations, or if a handoff message is already present.
- Session key: `X-Session-Id` header if present, otherwise SHA-1 of the first user message (same as sticky sessions).
- Storage is in-memory only. Nothing is written to disk or logged.
## Limitations
Stacking free tiers has real trade-offs. Be honest with yourself about them:
- **No frontier models.** The free-tier catalog tops out around Llama 3.3 70B, GLM-4.5, Qwen 3 Coder, and Gemini 2.5 Pro. You will not get GPT-5 or Claude Opus class reasoning through this. For hard problems, pay for a real API.
- **Intelligence degrades as the day progresses.** Your top-ranked models (usually Gemini 2.5 Pro, GPT-4o via GitHub Models) have the lowest daily caps. Once they hit their limits, the router falls down your priority chain to smaller/weaker models. Expect the effective intelligence of the endpoint to drop in the late hours of each day — then reset at UTC midnight.
- **Latency is highly variable.** Cerebras and Groq are extremely fast; others are not. You get whichever one is available.
- **Free tiers can change without notice.** Providers regularly tighten, loosen, or remove free tiers. When that happens you'll see 429s or auth errors until you update the catalog. Re-seed scripts live in `server/src/scripts/`.
- **No SLA, by definition.** If you need reliability, use a paid provider with a contract.
- **Local-first.** There's no multi-tenant auth. Run this for yourself; don't expose it to the internet.
## Contributing
Contributors very welcome! See [CONTRIBUTING.md](CONTRIBUTING.md) for the dev loop, PR expectations, and the policy on AI/LLM-assisted contributions (short version: welcome, same quality bar as any other PR). Good first PRs:
- **Add a provider** — copy `server/src/providers/openai-compat.ts` as a template, wire it into `server/src/providers/index.ts`, seed its models in `server/src/db/index.ts`, add a test in `server/src/__tests__/providers/`.
- **Add an endpoint** — images, moderations, audio. The provider base class can grow new methods; adapters declare which they support.
- **Improve the router** — cost-aware routing (cheapest-healthy-fastest tradeoffs), better latency-weighted priority, regional pinning.
- **Dashboard polish** — charts on the Analytics page, key rotation UX, batch import of keys from `.env`.
- **Docs** — more examples, client library snippets for Go/Rust/etc., a deployment recipe for Docker or Fly.
**Development loop:**
npm install
npm run dev # server on :3001, dashboard on :5173, both with HMR
npm test # server vitest; also runs client tests if the workspace adds them
npm run build # compile server and dashboard
PRs should include a test, keep the existing test suite green, and match the `.editorconfig` / tsconfig defaults already in the repo. Issues and discussions are open.
### Contributors





















































 ## Terms of Service review
A self-hosted, single-user, personal-use setup was re-reviewed against each provider's ToS (May 2026). Summary:
| Provider | Verdict | Notes |
|---|---|---|
| Google Gemini | ⚠️ Caution | March 2026 ToS narrows scope to *"professional or business purposes, not for consumer use"* — a self-hosted developer proxy is still defensible, but the clause is new. |
| Groq | ✅ Likely OK | GroqCloud Services Agreement permits Customer Application integration. |
| Cerebras | ✅ Likely OK | Permitted; explicitly forbids selling/transferring API keys. |
| Mistral | ✅ Likely OK | APIs allowed for personal/internal business use. |
| OpenRouter | ✅ Likely OK | April 2026 ToS sharpens the no-resale / no-competing-service clause; private single-user proxy still fine. |
| Cloudflare Workers AI | ⚠️ Ambiguous | No anti-proxy clause; covered by general Self-Serve Subscription Agreement. |
| NVIDIA NIM | ⚠️ Caution | Trial ToS §1.2 / §1.4: *"evaluation only, not production."* Free access is a recurring 40 RPM rate limit (the 2025 credit system was discontinued), but the evaluation-only scope stands. |
| GitHub Models | ⚠️ Caution | Free tier explicitly scoped to *"experimentation"* and *"prototyping."* |
| Cohere | ❌ Avoid | Terms §14 still forbids *"personal, family or household purposes."* |
| Zhipu (open.bigmodel.cn) | ✅ Likely OK | Personal/non-commercial research carve-out still in the platform docs. |
| Z.ai (api.z.ai) | ⚠️ Caution | New row — Singapore entity (distinct from Zhipu CN). §III.3(l) anti-traffic-redirect clause could plausibly be read against a proxy; no explicit personal-use carve-out. |
| Ollama Cloud | ✅ Likely OK | New row — Free plan permits cloud-model access (1 concurrent, 5-hour session caps). No anti-proxy / anti-resale clauses found. *(Integration tracked in #14.)* |
| OVH AI Endpoints | ✅ Likely OK | New row (June 2026) — anonymous access is officially documented (2 req/min per IP per model). OVH reserves the right to introduce token/consumption caps. |
Rules of thumb that keep most providers happy: **one account per provider**, **no reselling**, **no sharing your endpoint with other humans**, **don't hammer a free tier as a paid production backend**. This is informational, not legal advice — read each provider's ToS and make your own call.
Removed since the April 2026 review: Hugging Face, Moonshot, and MiniMax direct integrations were dropped from the catalog (HF — tool-call format issues; Moonshot — moved to paid only; MiniMax — superseded by the OpenRouter `minimax/minimax-m2.5:free` route).
## Disclaimer
**This project is for personal experimentation and learning, not production.** Free tiers exist so developers can prototype against them; they aren't a stable, supported inference substrate and shouldn't be treated as one. If you build something real on top of FreeLLMAPI, swap in a paid API before you ship. Your relationship with each upstream provider is governed by the terms you accepted when you created your account — those terms still apply when the traffic is proxied through this project, and you're responsible for complying with them.
## Star History
[](https://www.star-history.com/?repos=tashfeenahmed%2Ffreellmapi&type=date&legend=top-left)
## License
[MIT](./LICENSE)
## Terms of Service review
A self-hosted, single-user, personal-use setup was re-reviewed against each provider's ToS (May 2026). Summary:
| Provider | Verdict | Notes |
|---|---|---|
| Google Gemini | ⚠️ Caution | March 2026 ToS narrows scope to *"professional or business purposes, not for consumer use"* — a self-hosted developer proxy is still defensible, but the clause is new. |
| Groq | ✅ Likely OK | GroqCloud Services Agreement permits Customer Application integration. |
| Cerebras | ✅ Likely OK | Permitted; explicitly forbids selling/transferring API keys. |
| Mistral | ✅ Likely OK | APIs allowed for personal/internal business use. |
| OpenRouter | ✅ Likely OK | April 2026 ToS sharpens the no-resale / no-competing-service clause; private single-user proxy still fine. |
| Cloudflare Workers AI | ⚠️ Ambiguous | No anti-proxy clause; covered by general Self-Serve Subscription Agreement. |
| NVIDIA NIM | ⚠️ Caution | Trial ToS §1.2 / §1.4: *"evaluation only, not production."* Free access is a recurring 40 RPM rate limit (the 2025 credit system was discontinued), but the evaluation-only scope stands. |
| GitHub Models | ⚠️ Caution | Free tier explicitly scoped to *"experimentation"* and *"prototyping."* |
| Cohere | ❌ Avoid | Terms §14 still forbids *"personal, family or household purposes."* |
| Zhipu (open.bigmodel.cn) | ✅ Likely OK | Personal/non-commercial research carve-out still in the platform docs. |
| Z.ai (api.z.ai) | ⚠️ Caution | New row — Singapore entity (distinct from Zhipu CN). §III.3(l) anti-traffic-redirect clause could plausibly be read against a proxy; no explicit personal-use carve-out. |
| Ollama Cloud | ✅ Likely OK | New row — Free plan permits cloud-model access (1 concurrent, 5-hour session caps). No anti-proxy / anti-resale clauses found. *(Integration tracked in #14.)* |
| OVH AI Endpoints | ✅ Likely OK | New row (June 2026) — anonymous access is officially documented (2 req/min per IP per model). OVH reserves the right to introduce token/consumption caps. |
Rules of thumb that keep most providers happy: **one account per provider**, **no reselling**, **no sharing your endpoint with other humans**, **don't hammer a free tier as a paid production backend**. This is informational, not legal advice — read each provider's ToS and make your own call.
Removed since the April 2026 review: Hugging Face, Moonshot, and MiniMax direct integrations were dropped from the catalog (HF — tool-call format issues; Moonshot — moved to paid only; MiniMax — superseded by the OpenRouter `minimax/minimax-m2.5:free` route).
## Disclaimer
**This project is for personal experimentation and learning, not production.** Free tiers exist so developers can prototype against them; they aren't a stable, supported inference substrate and shouldn't be treated as one. If you build something real on top of FreeLLMAPI, swap in a paid API before you ship. Your relationship with each upstream provider is governed by the terms you accepted when you created your account — those terms still apply when the traffic is proxied through this project, and you're responsible for complying with them.
## Star History
[](https://www.star-history.com/?repos=tashfeenahmed%2Ffreellmapi&type=date&legend=top-left)
## License
[MIT](./LICENSE)