Bikerbyte/k8s-incident-lab
GitHub: Bikerbyte/k8s-incident-lab
一个基于 K3s 的 Kubernetes 故障注入与排查实验室,通过可重复场景训练从业者的事件响应能力。
Stars: 0 | Forks: 0
# K8s 事件处理实践实验室
[](https://github.com/Bikerbyte/k8s-incident-lab/actions/workflows/ci.yml)
本项目是一个动手操作的 Kubernetes 故障排查实验室。它使用可重复的故障注入来演示如何诊断 Pod、Deployment、Service、Endpoint、就绪探针、资源限制、指标、日志和告警。
脚本使故障可重现。该实验室的价值在于手动排查路径:观察集群,隔离故障模式,解释根本原因,并恢复工作负载。
技术栈:K3s · Podinfo · Prometheus · Grafana · Loki · Promtail · Helm · kube-prometheus-stack。
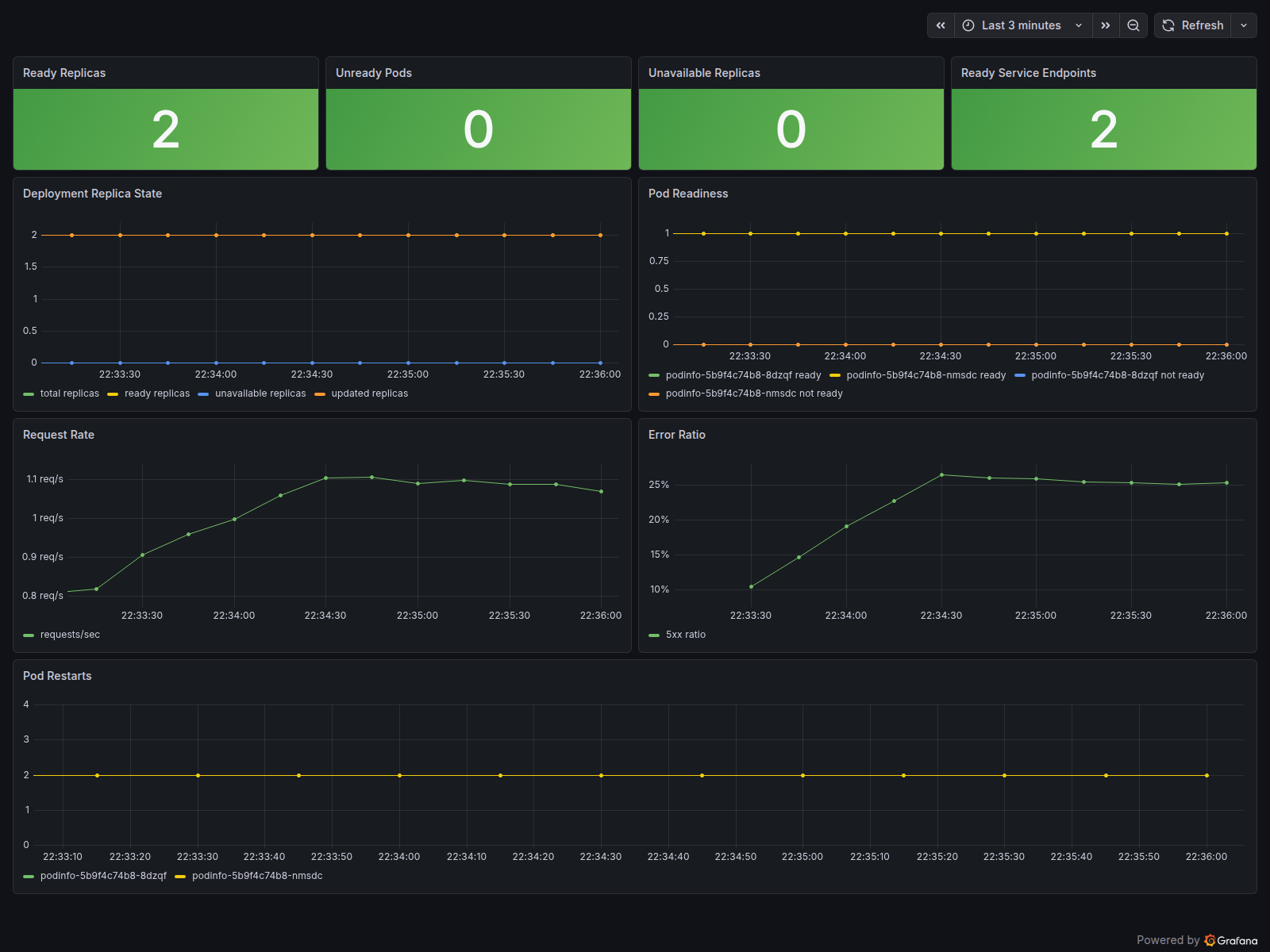
## 本实验室能证明什么
| Kubernetes 技能 | 本项目中的证据 | 为什么重要 |
|---|---|---|
| Pod 调试 | 使用 `kubectl get pods`、`describe pod`、容器状态、事件和日志 | 大多数事件从证明 Pod 层面的变化开始 |
| 就绪探针 vs 活性探针 | 显示正在运行但未就绪的 Pod,然后验证 Endpoint 被移除 | 防止混淆容器健康与流量准入资格 |
| Deployment 协调 | 删除一个 Pod 并观察 Deployment/ReplicaSet 重新创建它 | 演示期望状态和自我修复行为 |
| 服务发现 | 破坏 Service 选择器并比较选择器、标签和 Endpoint | 解释为什么健康的 Pod 仍可能收不到流量 |
| 资源限制 | 触发 OOMKilled 并检查重启次数、上次状态和退出码 137 | 将资源配置与运行时故障行为联系起来 |
| 可观测性 | 将 Grafana 面板、Prometheus 告警、Loki 日志和 runbook 映射到每个场景 | 将症状转化为证据驱动的事件响应 |
| 平台自动化 | 提供可重复的 bash 和 PowerShell 入口点,用于设置、故障注入和恢复 | 保持实验室可重现,同时不隐藏调试工作流 |
## 成果
- 使用 Pod 状态、Kubernetes 事件、上线状态和 Service Endpoint 诊断就绪失败。
- 通过删除 Pod 并观察控制器驱动的替换来演示 Deployment 自我修复。
- 通过比较 Service 选择器、Pod 标签和 Endpoint 可用性来诊断 Service 选择器不匹配。
- 通过容器上次状态、重启次数、内存限制和 Prometheus 信号识别 OOMKilled 行为。
- 结合指标和日志,将应用级别的 HTTP 500 故障与 Kubernetes 级别的健康状态区分开。
- 构建了完整的可观测性栈:Prometheus、Grafana、Loki、Promtail、仪表盘、告警和 runbook 链接。
- 构建了本地操作控制台,包含 16 个实验操作和一个命名空间受限的引导终端,用于可重复练习。
## 仓库结构
```
k8s-incident-lab/
+-- app/
| +-- manifests/
+-- docs/
| +-- architecture.md
| +-- scenarios.md
| +-- screenshots/
+-- monitoring/
| +-- dashboards/
| +-- helm-values/
| +-- servicemonitors/
+-- runbooks/
+-- scenarios/
+-- scripts/
+-- console/
```
## 前置条件
- 一个可运行的 K3s 或 Kubernetes 集群
- `kubectl`
- `helm`
- `curl`
确认集群访问:
```
kubectl get nodes
```
## 快速开始
部署演示应用、监控栈和本地访问:
```
scripts/lab.sh deploy
scripts/lab.sh monitoring
scripts/lab.sh access
```
运行本地实验控制台:
```
scripts/lab.sh console
```
然后在浏览器中打开打印出的本地 URL。
随时查看实验状态:
```
scripts/lab.sh status
```
常用快捷方式也可通过 `make` 使用:
```
make deploy
make monitoring
make port-forward
make stop-port-forward
make console
make status
make alerts
```
在 Windows PowerShell 上,使用对应的 `.ps1` 脚本:
```
.\scripts\lab.ps1 deploy
.\scripts\lab.ps1 monitoring
```
打开 Grafana:
```
scripts/lab.sh access
```
然后打开:
```
Grafana: http://localhost:3000
Prometheus: http://localhost:9090
Podinfo: http://localhost:9898
```
停止本地端口转发:
```
scripts/lab.sh stop-access
```
默认登录信息:
```
admin / admin
```
打开仪表盘:
```
Incident Lab / Podinfo Overview
```
Grafana 使用指南:
- [docs/grafana-guide.md](docs/grafana-guide.md)
故障排查:
- [docs/troubleshooting.md](docs/troubleshooting.md)
告警:
- [docs/alerts.md](docs/alerts.md)
演示流程:
- [docs/demo-flow.md](docs/demo-flow.md)
截图指南:
- [docs/screenshots/README.md](docs/screenshots/README.md)
## 验证应用
端口转发 Podinfo:
```
scripts/lab.sh access
```
测试它:
```
curl http://localhost:9898/
curl http://localhost:9898/readyz
curl http://localhost:9898/metrics
```
## 事件场景
每个场景都以一个脚本开始,仅用于创建一致的故障。排查和恢复步骤有意地以 Kubernetes 操作为主。
### 1. 就绪探针故障
故障注入:
```
scripts/lab.sh scenario readiness trigger
```
手动排查:
```
kubectl -n incident-lab get pods
kubectl -n incident-lab describe pod -l app.kubernetes.io/name=podinfo
kubectl -n incident-lab get endpoints podinfo
kubectl -n incident-lab get events --sort-by=.lastTimestamp
```
根本原因:
Deployment 被修补了一个不会成功的就绪探针,因此 Pod 可以处于 Running 状态,但 Kubernetes 使其无法进入 Service Endpoint。
Kubernetes 概念:
就绪控制流量准入资格。活性控制容器重启行为。
恢复:
```
scripts/lab.sh scenario readiness restore
kubectl -n incident-lab rollout status deploy/podinfo
kubectl -n incident-lab get endpoints podinfo
```
PowerShell 对应脚本位于 `scripts/*.ps1`。
Runbook: [runbooks/readiness-failure.md](runbooks/readiness-failure.md)
### 2. 高错误率
故障注入:
```
scripts/lab.sh scenario errors trigger
```
手动排查:
```
kubectl -n incident-lab get pods
kubectl -n incident-lab logs deploy/podinfo --tail=100
scripts/lab.sh alerts
```
Grafana/Loki 证据:
- Grafana `错误率`
- Grafana `请求速率`
- Loki 查询:`{namespace="incident-lab"} |= "500"`
- Prometheus 告警:`PodinfoHighErrorRate`
根本原因:
应用返回 HTTP 500 响应,而 Kubernetes 仍然认为 Pod 健康。
Kubernetes 概念:
并非所有中断都是 Kubernetes 调度或就绪问题。当 Pod 健康但用户仍看到错误时,需要应用指标和日志。
Runbook: [runbooks/high-error-rate.md](runbooks/high-error-rate.md)
### 3. Pod 自我修复
故障注入:
```
scripts/lab.sh scenario self-healing trigger
```
手动排查:
```
kubectl -n incident-lab get pods -w
kubectl -n incident-lab get rs
kubectl -n incident-lab get events --sort-by=.lastTimestamp
```
根本原因:
手动删除一个 Pod,造成期望状态与实际状态之间的偏差。
Kubernetes 概念:
Deployment 控制器通过其 ReplicaSet 创建替换 Pod,将实际状态协调回期望状态。
Runbook: [runbooks/pod-self-healing.md](runbooks/pod-self-healing.md)
### 4. OOMKilled
故障注入:
```
scripts/lab.sh scenario oom trigger
```
手动排查:
```
kubectl -n incident-lab get pods -w
kubectl -n incident-lab describe pod -l app.kubernetes.io/name=podinfo
kubectl -n incident-lab get deploy podinfo -o jsonpath='{.spec.template.spec.containers[0].resources}'
scripts/lab.sh alerts
```
根本原因:
容器内存限制降低到进程所需值以下,导致内核杀死进程,Kubernetes 报告 `OOMKilled`。
Kubernetes 概念:
退出码 137、重启次数、容器上次状态和内存限制共同解释了工作负载是崩溃还是被资源压力杀死。
恢复:
```
scripts/lab.sh scenario oom restore
kubectl -n incident-lab rollout status deploy/podinfo
```
Runbook:runbooks/oom-killed.md](runbooks/oom-killed.md)
### 5. 服务发现中断
故障注入:
```
scripts/lab.sh scenario service-discovery trigger
```
手动排查:
```
kubectl -n incident-lab get pods --show-labels
kubectl -n incident-lab describe svc podinfo
kubectl -n incident-lab get endpoints podinfo
curl http://localhost:9898/
```
根本原因:
Service 选择器不再匹配 Pod 标签,因此存在健康的 Pod,但 Service 没有就绪的 Endpoint。
Kubernetes 概念:
Service 通过标签选择器将流量路由到 Endpoint。标签/选择器不匹配可能在不使 Pod 不健康的情况下中断流量。
恢复:
```
scripts/lab.sh scenario service-discovery restore
kubectl -n incident-lab get endpoints podinfo
```
Runbook: [runbooks/service-discovery-broken.md](runbooks/service-discovery-broken.md)
## 常用命令
验证仓库:
```
scripts/lab.sh validate
```
显示 Prometheus 告警:
```
scripts/lab.sh alerts
```
检查应用状态:
```
kubectl -n incident-lab get all
kubectl -n incident-lab describe deploy podinfo
kubectl -n incident-lab logs deploy/podinfo --tail=100
```
检查监控状态:
```
kubectl -n monitoring get pods
kubectl -n monitoring get svc
```
查询近期事件:
```
kubectl -n incident-lab get events --sort-by=.lastTimestamp
```
## 清理
```
scripts/lab.sh cleanup
```
## MVP 状态
- [x] 演示应用清单
- [x] Prometheus / Grafana Helm values
- [x] Prometheus 告警规则
- [x] Loki / Promtail Helm values
- [x] Grafana 仪表盘 ConfigMap
- [x] 本地实验控制台
- [x] 就绪故障场景
- [x] 高错误率场景
- [x] Pod 自我修复场景
- [x] OOMKilled 场景
- [x] 服务发现中断场景
- [x] Runbook
- [x] 辅助脚本
- [x] 来自真实集群运行的截图
## 未来改进
- Alertmanager 规则和通知路由
- Ingress 和 TLS
- GitHub Actions CI 验证
- SLO 仪表盘(可用性 SLI + 错误预算)
标签:AI合规, API集成, Grafana, Helm, K3s, kube-prometheus-stack, Loki, OOMKilled, Podinfo, Pod调试, Promtail, runbook, SRE, 代理支持, 偏差过滤, 可观测性, 告警, 就绪探针, 应用安全, 指标, 故障排查, 故障注入, 日志, 服务发现, 自定义请求头, 资源限制, 运维实验室, 部署自愈