Simran-Kumari92/fraud-detection-system
GitHub: Simran-Kumari92/fraud-detection-system
这是一个结合机器学习和规则逻辑的混合系统,用于实时检测金融交易中的欺诈行为。
Stars: 0 | Forks: 0
# 💳 混合欺诈检测系统
一个基于机器学习的欺诈检测系统,通过结合 **机器学习模型与基于规则的逻辑** 来识别可疑金融交易。
## 🚀 概述
本项目专注于在高度不平衡的金融数据集中检测欺诈交易。
它结合了:
* **机器学习 (随机森林)**
* **SMOTE (处理类别不平衡)**
* **特征工程 (余额不一致检测)**
* **混合逻辑 (机器学习 + 基于规则的验证)**
## 🎯 核心功能
* 🔍 使用 Streamlit 进行实时欺诈预测
* ⚖️ 使用 SMOTE 处理不平衡数据
* 🧠 特征工程 (余额误差、余额比率、取款模式)
* 🔗 结合机器学习预测与基于规则检查的混合系统
* 📊 模型比较 (逻辑回归、随机森林、XGBoost)
* 📈 带置信度可视化的风险评分
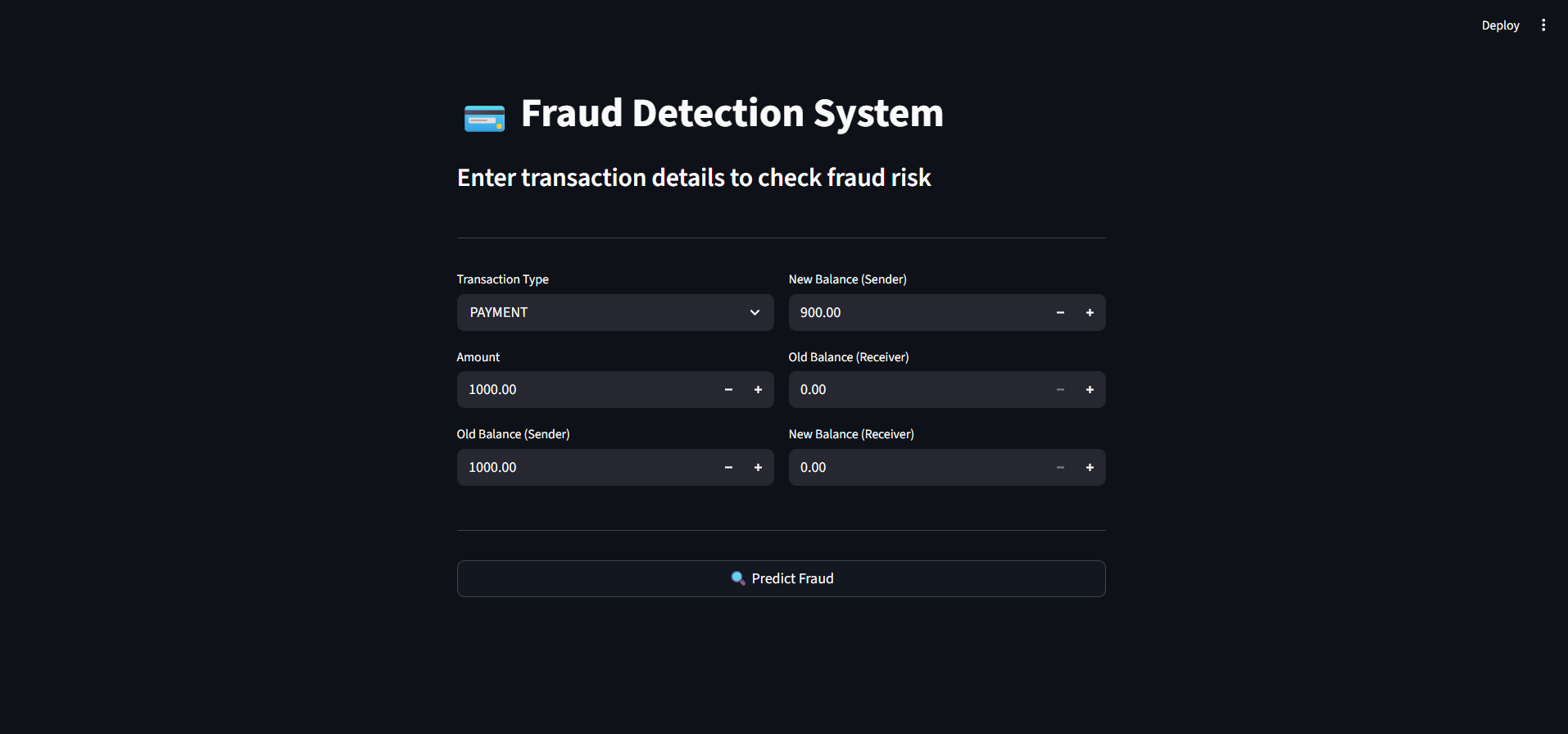
## 📸 界面截图
### 🔹 应用程序界面
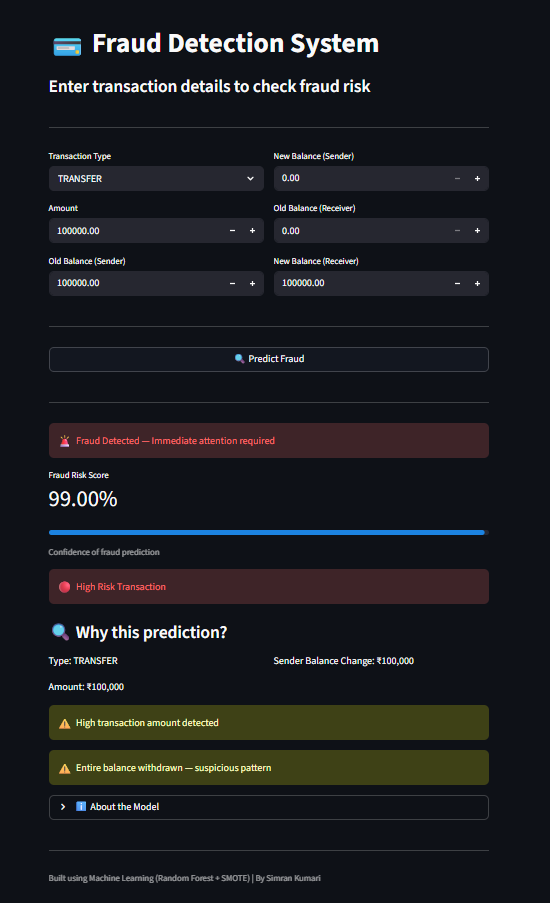
### 🔹 欺诈检测 (高风险)
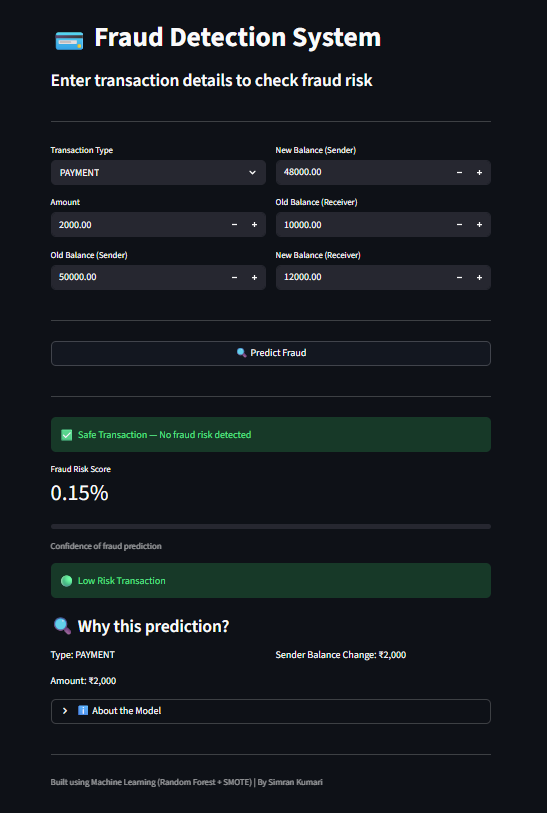
### 🔹 安全交易
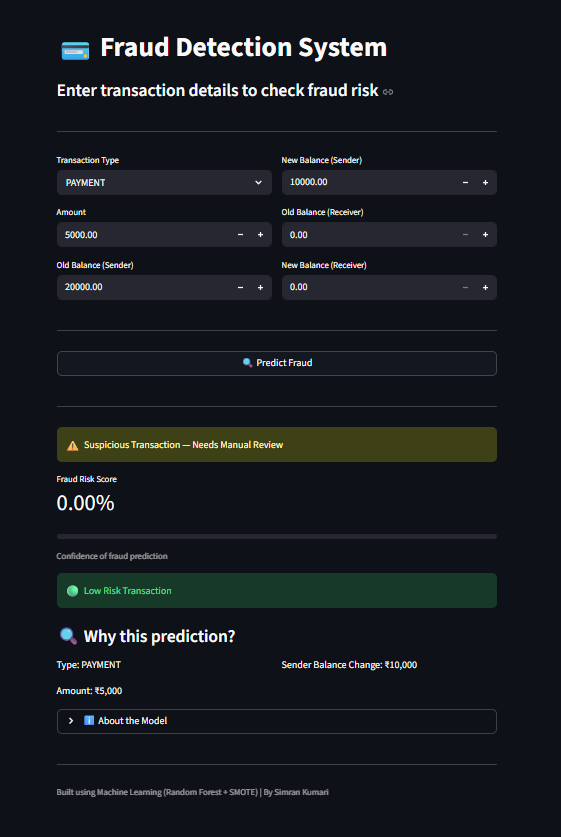
### 🔹 可疑交易
## 🛠️ 技术栈
* Python
* Pandas, NumPy
* Scikit-learn
* XGBoost
* Imbalanced-learn (SMOTE)
* Streamlit
## 📂 项目结构
```
fraud-detection/
│
├── app/
│ └── fraud_detection.py # Streamlit UI
│
├── src/
│ └── train_models.py # Model training script
│
├── data/
│ └── AIML Dataset.csv # (Not included - see below)
│
├── models/
│ └── fraud_detection_pipeline.pkl # Generated after training
│
├── results/
│ └── model_comparison.csv
│
├── notebooks/
│ └── analysis_model.ipynb
│
└── README.md
```
## 📊 数据集
本项目使用了一个 **使用 PaySim 生成的合成金融交易数据集**。
⚠️ 由于文件大小限制,数据集未包含在本仓库中。
👉 从 Kaggle 下载数据集:
https://www.kaggle.com/datasets/amanalisiddiqui/fraud-detection-dataset?resource=download
下载后,将文件放置于:
```
data/AIML Dataset.csv
```
## ⚙️ 设置说明
### 1️⃣ 克隆仓库
```
git clone https://github.com/Simran-Kumari92/fraud-detection-system
cd hybrid-fraud-detection-system
```
### 2️⃣ 安装依赖项
```
pip install -r requirements.txt
```
### 3️⃣ 训练模型
```
cd src
python train_models.py
```
👉 这将生成:
```
models/fraud_detection_pipeline.pkl
```
### 4️⃣ 运行应用程序
```
cd ..
streamlit run app/fraud_detection.py
```
## 🧠 工作原理
### 🔹 机器学习模型
* 基于交易数据训练的随机森林分类器
* 使用 SMOTE 处理数据不平衡问题
### 🔹 特征工程
* 检测交易余额中的不一致情况
* 为模型添加领域特定的洞察
### 🔹 混合逻辑 (核心亮点)
* 机器学习预测概率
* 基于规则的逻辑检测:
* 余额全额提取
* 大额交易
* 余额不一致
👉 最终决策结合两种方法
## 📈 模型性能
| 模型 | 精确率 | 召回率 | F1 分数 |
| ------------------- | ------ | ------ | ------- |
| 逻辑回归 | 低 | 高 | 低 |
| 随机森林 | 中等 | 高 | 最佳 |
| XGBoost | 中等 | 高 | 良好 |
## ⚠️ 局限性
* 数据集高度不平衡
* 部分交易类型 (如 PAYMENT) 的欺诈案例极少
* 模型依赖数据集的模式
## 🚀 未来改进方向
* 使用更大、更多样的数据集
* 添加深度学习模型
* 改进稀有交易类型的欺诈检测
* 部署到云平台 (AWS / Streamlit Cloud)
标签:Apex, Kubernetes, PaySim模拟, Python, SMOTE, Streamlit, XGBoost, 不平衡数据处理, 云计算, 交易监控, 合成数据, 实时系统, 数据科学, 无后门, 机器学习, 模型评估, 混合逻辑, 特征工程, 规则引擎, 访问控制, 财务安全, 资源验证, 逆向工具, 金融欺诈检测, 随机森林, 风险控制, 风险评分