arshkalra17/SensorGuard---Anomaly-Detection-in-IoT-Sensor-Data
GitHub: arshkalra17/SensorGuard---Anomaly-Detection-in-IoT-Sensor-Data
一个基于 Python 的物联网传感器数据异常检测与根因分析端到端项目。
Stars: 0 | Forks: 0
# SensorGuard – 物联网传感器数据异常检测
检测时间序列物联网传感器数据中的异常模式,并执行基本的根本原因分析以识别触发警报的传感器。
## 问题陈述
物联网设备会生成连续的传感器数据流。故障——温度骤升、压力突增、电压异常——可能在导致设备故障前未被察觉。SensorGuard 会实时标记这些异常,并 pinpoint 最可能的根本原因。
## 技术栈
| 层级 | 工具 |
|------|------|
| 语言 | Python 3.10+ |
| 数据 | 合成物联网数据集(项目内生成) |
| 机器学习模型 | 孤立森林(Isolation Forest)、一类 SVM(scikit-learn) |
| 统计方法 | Z-Score(scipy) |
| 特征工程 | 滚动均值/标准差、趋势、变化率(pandas) |
| 可视化 | Matplotlib、Seaborn |
| 笔记本 | Jupyter |
## 项目结构
```
sensorguard/
├── data/
│ └── sensor_data.csv # generated on first run
├── notebooks/
│ └── SensorGuard_Analysis.ipynb
├── src/
│ ├── generate_data.py # synthetic dataset generator
│ ├── preprocessing.py # missing values + normalization
│ ├── feature_engineering.py # rolling features, trend, ROC
│ ├── anomaly_detection.py # Z-Score, Isolation Forest, OC-SVM
│ ├── visualization.py # all plots
│ ├── root_cause.py # correlation + culprit ranking
│ ├── evaluation.py # precision, recall, F1
│ └── main.py # end-to-end pipeline runner
├── outputs/ # saved plots + CSVs (auto-created)
├── requirements.txt
└── README.md
```
## 方法论
### 1. 数据生成
模拟 5 个传感器(温度、压力、振动、湿度、电压)在 2000 分钟内的读数,包含真实噪声并注入约 4% 的异常(包含真实标签)。
### 2. 预处理
- 前向填充然后后向填充缺失值
- 最小-最大归一化到 [0, 1]
### 3. 特征工程
对每个归一化传感器信号:
- **滚动均值**(窗口=10)——平滑趋势
- **滚动标准差**——局部波动;高标准差表示传感器不稳定
- **趋势(差分)**——连续读数之间的变化速率
- **变化率**——百分比变化
### 4. 异常检测
| 方法 | 工作原理 |
|------|----------|
| Z-Score | 标记偏离均值超过 3 倍标准差的读数 |
| 孤立森林 | 通过随机树隔离异常;路径更短 = 异常 |
| 一类 SVM | 在高维空间学习正常数据的边界;边界外即异常 |
| 集成 | 任一方法标记即为异常 |
### 5. 根本原因分析
- 传感器之间的皮尔逊相关热图
- 每个异常的特征 Z-Score → 识别“首要嫌疑”传感器
- 按异常贡献计数排名的传感器柱状图
### 6. 评估
将集成预测与注入的真实标签进行比较:
- 精确率、召回率、F1 分数
- 各方法细分
- 混淆矩阵
## 典型运行结果
| 方法 | 检测到的异常 |
|------|--------------|
| Z-Score | ~3–5 % |
| 孤立森林 | ~5 %(污染率=0.05) |
| 一类 SVM | ~5 %(nu=0.05) |
| 集成 | ~6–8 % |
集成 F1 分数与真实标签通常在 **0.55–0.70** 之间——在未调优的无监督检测中表现合理。
## 运行方式
### 选项 A — 完整流水线(推荐)
```
# 克隆 / 打开项目
cd sensorguard
# 创建虚拟环境
python3 -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 安装依赖
pip install -r requirements.txt
# 运行管道
python src/main.py
```
输出保存至 `outputs/`:
[处理后的数据](sensorguard/outputs/processed_data.csv) —— 包含所有特征和异常标记的完整数据集
[异常结果](sensorguard/outputs/anomaly_results.csv) —— 仅异常行
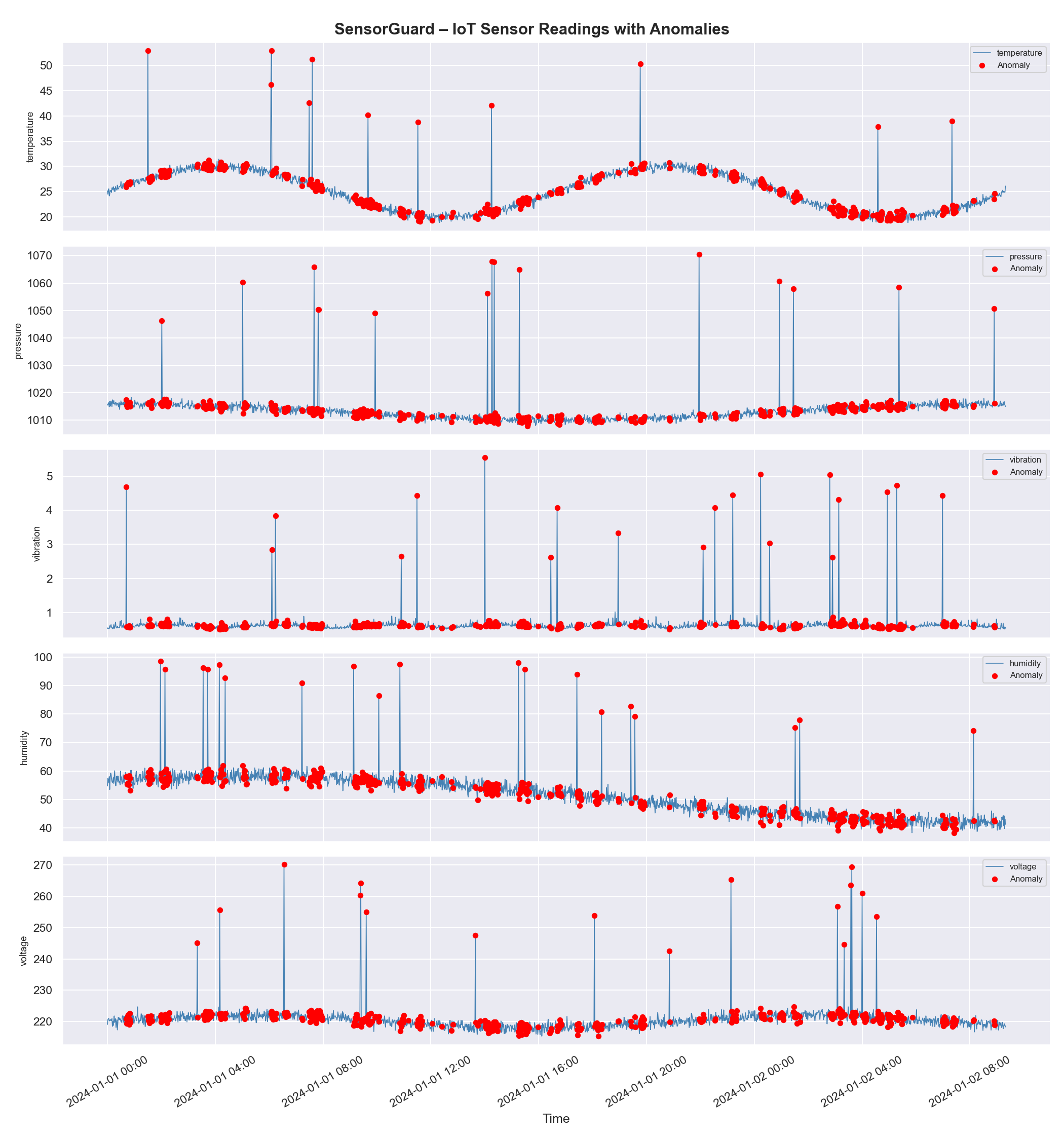 —— 带高亮异常的时间序列
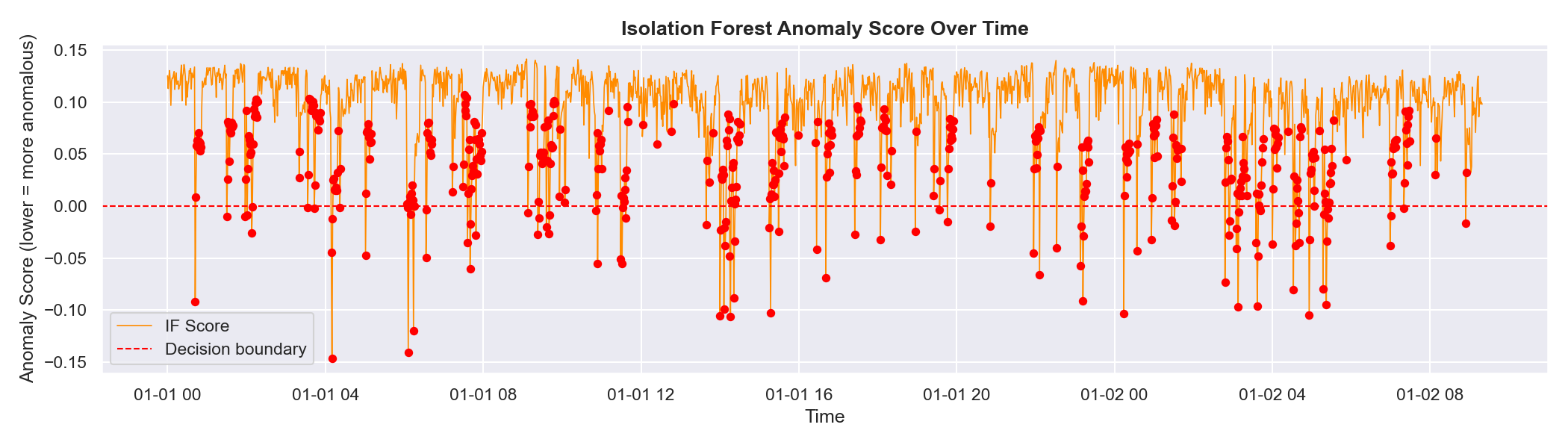 —— 随时间变化的孤立森林得分
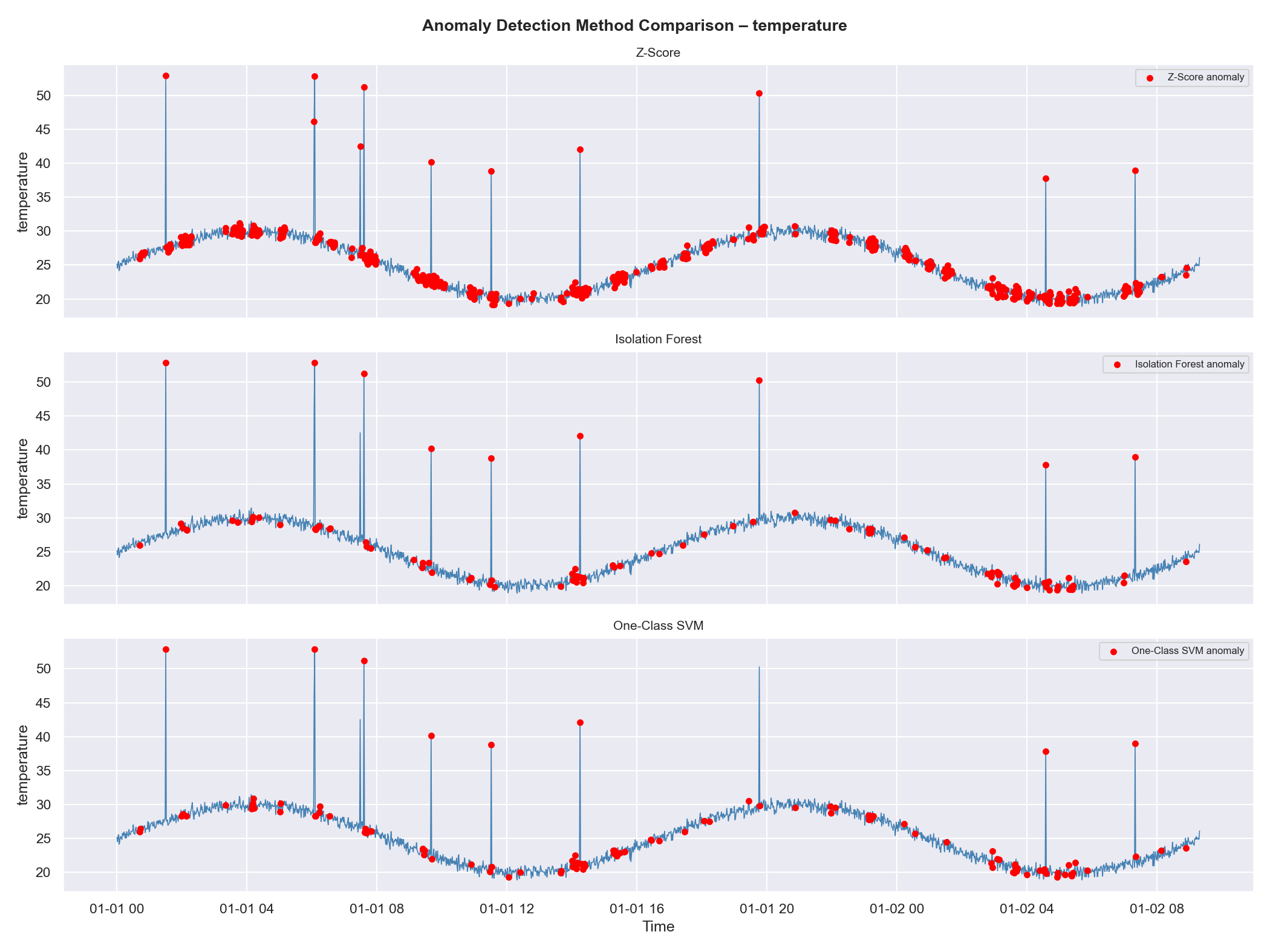 —— 并排方法对比
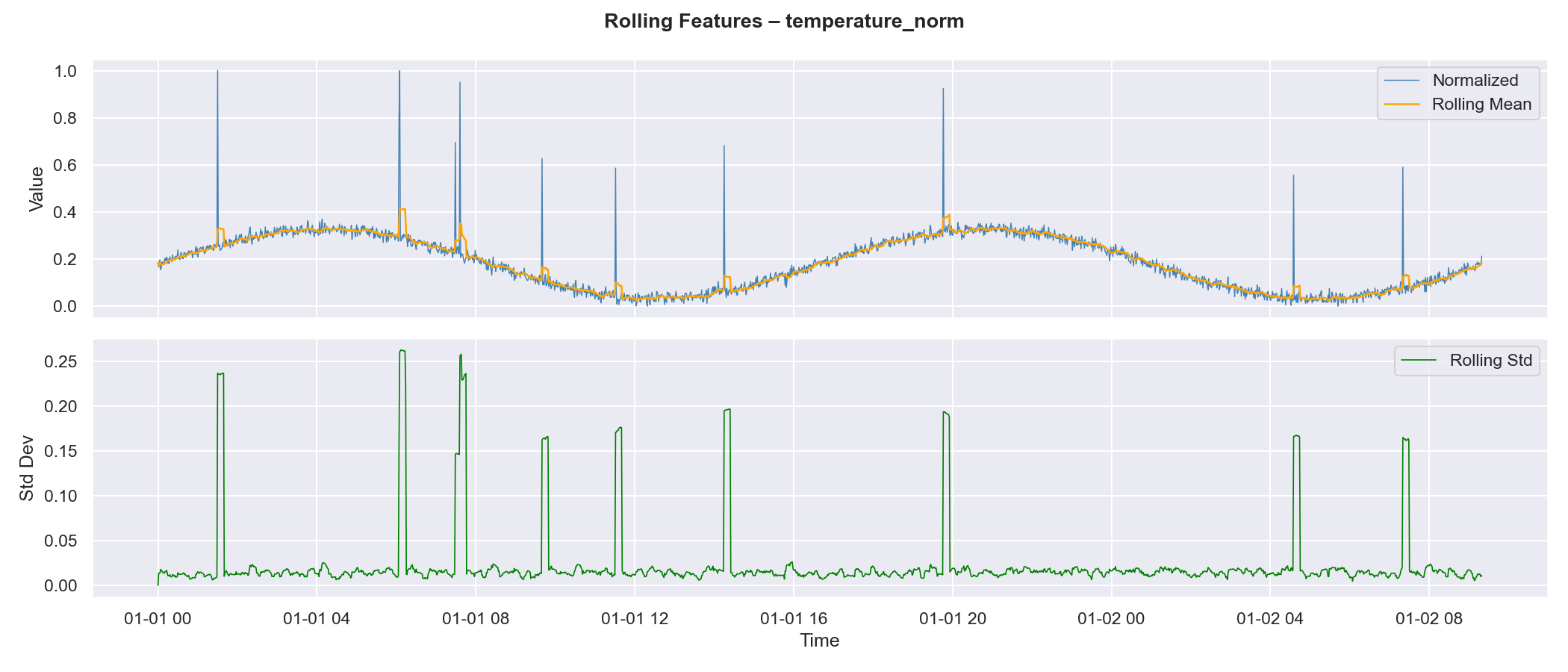 —— 滚动均值/标准差可视化
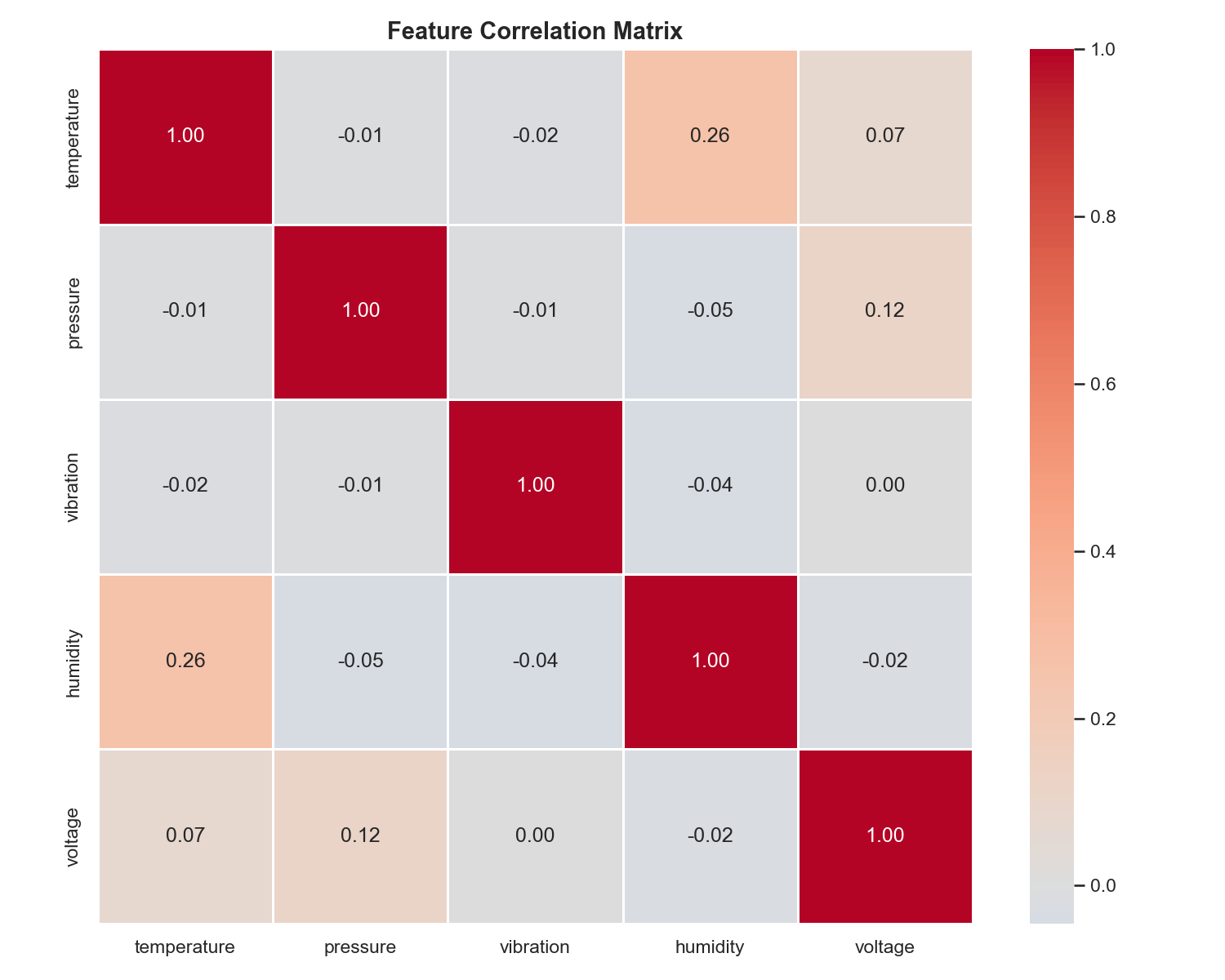 —— 特征相关性热图
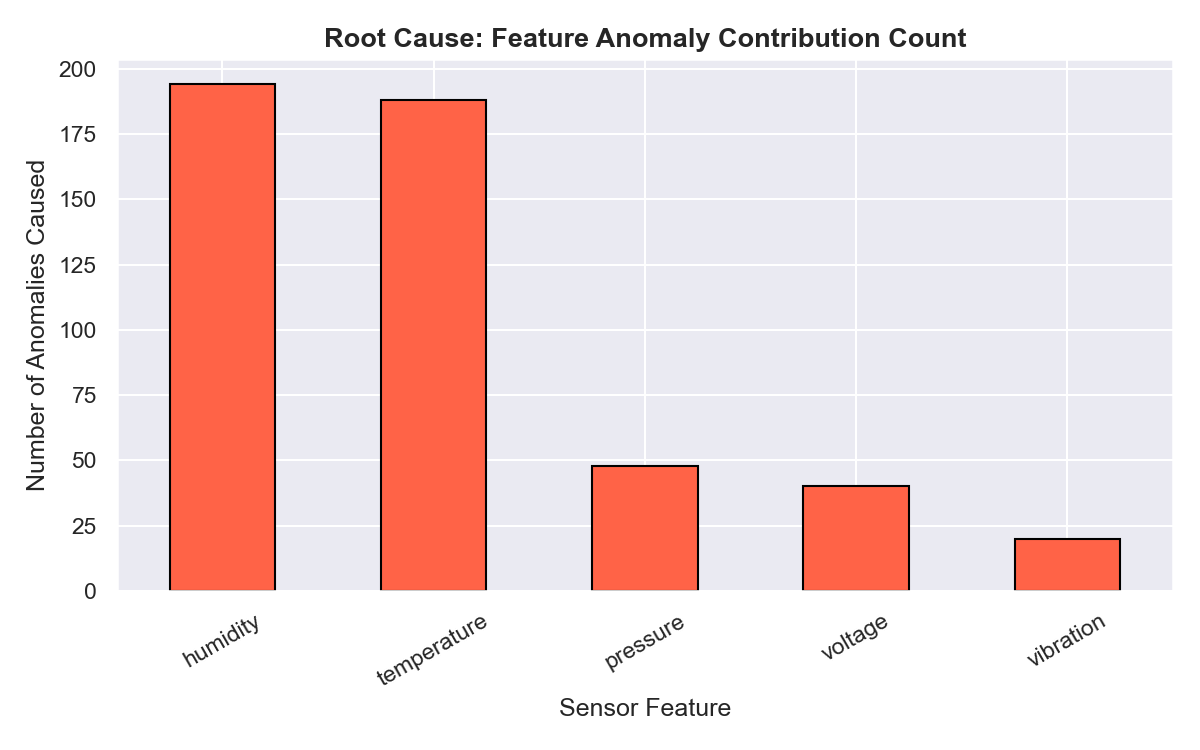 —— 嫌疑传感器柱状图
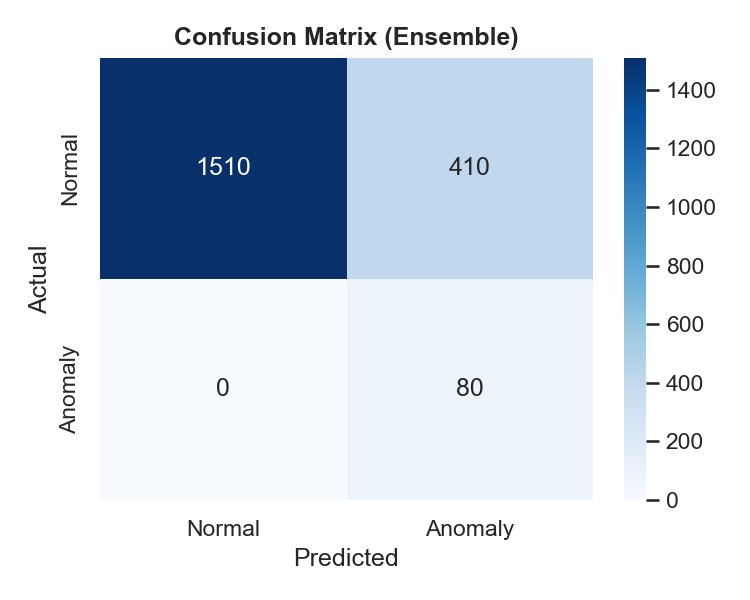 —— 评估用混淆矩阵
### 选项 B — Jupyter 笔记本
```
jupyter notebook notebooks/SensorGuard_Analysis.ipynb
```
按从上到下的顺序运行单元格,即可进行带有内嵌图表的交互式演练。
## 关键概念(入门者)
**Z-Score** —— 衡量一个值偏离均值的标准差数。超出 ±3 在正常数据中极为罕见(约 0.3% 概率)。
**孤立森林** —— 构建随机决策树;异常点因与多数不同,能在更少的分裂中被“隔离”。
**一类 SVM** —— 在高维空间中绘制一条边界,边界外即标记为异常。
**滚动特征** —— 在滑动窗口上计算,捕捉局部趋势而非全局统计量。
## 作者
作为一个展示端到端机器学习工程在时间序列物联网数据上应用的项目构建。
标签:Apex, IoT, Jupyter, Matplotlib, Mutation, One-Class SVM, Python, scikit-learn, Seaborn, Z-Score, 传感器数据, 变化率, 可视化, 合成数据, 后端开发, 告警定位, 实时检测, 工业物联网, 异常检测, 数据预处理, 无后门, 时间序列, 机器学习, 根因分析, 滚动均值, 滚动标准差, 物联网, 特征工程, 特征相关性, 监控, 缺失值处理, 设备故障预测, 趋势, 逆向工具, 隔离森林