Mallikarjun501/privacy-preserving-secure-aggregation-fl
GitHub: Mallikarjun501/privacy-preserving-secure-aggregation-fl
PSSA 是一个面向边缘计算场景的隐私保护联邦学习端到端实现,在同态加密、差分隐私、梯度压缩和拜占庭容错的联合框架下,基于 NSL-KDD 数据集实现了安全的分布式网络入侵检测协作训练。
Stars: 100 | Forks: 0
# PSSA:边缘计算中联邦学习的隐私保护与可扩展安全聚合
IEEE ICC-ROBINS 2025 - 研究实现
TTEH 实验室






《边缘计算中联邦学习的隐私保护与可扩展安全聚合》的实现。
论文 DOI:https://doi.org/10.1109/ICC-ROBINS64345.2025.11086126
## 概述
PSSA 是一个实用的、端到端的联邦学习实现,专为同时存在数据隐私、有限通信容量和对抗性可靠性风险这三个约束的边缘场景而设计。该项目并未将它们视为独立的功能,而是将它们结合到一个可以直接执行和评估的训练工作流中。
在运行时,系统启动 6 个独立进程(1 个服务器 + 5 个客户端),并在 NSL-KDD 数据分片上进行协作训练。每个客户端在本地进行训练,并且只发送受保护的稀疏更新,从不发送原始训练数据。服务器协调通信轮次、聚合更新、应用全局模型更新规则、评估性能并记录实验指标。
该实现按顺序集成了四个关键机制:
- Paillier 同态加密 (HE),用于加密值的安全聚合。
- 客户端差分上的差分隐私 (DP) 噪声,以减少信息泄漏。
- 自适应量化和稀疏梯度共享,以减少通信有效载荷。
- 基于 Krum 的 Byzantine 评分,以监视潜在的恶意或异常客户端更新。
本仓库的结构是一个可复现的研究实现:它包括分布式服务器/客户端代码、数据集处理、轮次级指标记录,以及一个基线比较脚本(`comparison.py`),该脚本可报告 FedAvg、SecAgg、DP-FL 和 PSSA 的结果。最终得到一个可运行的 FL 流水线,不仅设计与论文一致,而且可以在标准开发系统上运行和检查。
当有支持 CUDA 的 GPU 可用时,客户端训练和服务器端评估步骤会自动转移到 GPU,而密码学聚合路径则保持基于 CPU 运行。
**关键词:** Privacy-Preserving、Federated Learning、Secure Aggregation、Homomorphic Encryption、Differential Privacy、Byzantine-Robust、Gradient Compression、Edge Computing、Cybersecurity、NSL-KDD Dataset
## 目录
1. 问题陈述
2. 提出的解决方案
3. 工作原理
4. 流水线
5. 结果与指标
6. 数据集
7. 与论文的差异
8. 项目结构
9. 安装与使用
10. 系统要求
11. 局限性
12. 未来改进
13. 团队成员与导师
14. 实验室
## 1. 问题陈述
联邦学习对于边缘和网络安全工作负载极具吸引力,因为原始数据可以保留在本地。然而,实际部署面临三个相互关联的问题:
- 原始梯度或明文更新导致的隐私泄漏。
- 资源受限设备上的通信和加密开销。
- 可能毒害全局训练的对抗性或故障客户端。
传统的 FL 流水线通常一次只解决其中一个问题。例如,普通的 FedAvg 很轻量但隐私性较弱;强大的安全聚合提高了隐私性,但可能会变得昂贵;Byzantine-Robust 聚合有助于完整性,但增加了复杂性。
本项目针对的是这个综合性问题:提供一个单一的端到端训练工作流,它具有足够的私密性、高效性和鲁棒性,可以在现实的多进程设置中运行。
## 2. 提出的解决方案
本仓库中提出的解决方案是一个集成的 PSSA 训练循环,其中每个客户端更新在离开客户端之前都要经过隐私和效率控制。
客户端流程:
- 训练本地模型 5 个 epoch。
- 根据接收到的全局权重计算更新差值。
- 应用 DP 高斯噪声。
- 应用自适应量化和稀疏梯度共享。
- 使用 Paillier 加密所有非零稀疏值。
- 发送加密的稀疏有效载荷 + 索引 + 数据集大小。
服务器流程:
- 安全地聚合加密的稀疏更新。
- 构建每个客户端的解密向量,用于 Krum 评分(监控/检测角色)。
- 应用 Weighted FedAvg 作为全局模型更新规则。
- 评估模型性能并记录每轮的隐私/通信指标。
本实现中使用的设计选择:
- Krum 用于 Byzantine 监控和获胜者记录。
- Weighted FedAvg 用于实际的模型更新。
### 核心组件
| 组件 | 目的 | 论文章节 |
|---|---|---|
| Homomorphic Encryption | 加密更新并安全聚合 | III.B |
| Differential Privacy | 为更新差值添加高斯噪声 | III.C |
| Adaptive Compression | 量化 + 稀疏共享以降低通信成本 | III.D |
| Byzantine Resilience | 用于对抗性监控的 Krum 评分 | III.E |
## 3. 工作原理
本节介绍从启动到最终结果记录的完整端到端执行流程。
### 端到端工作流(从头到尾)
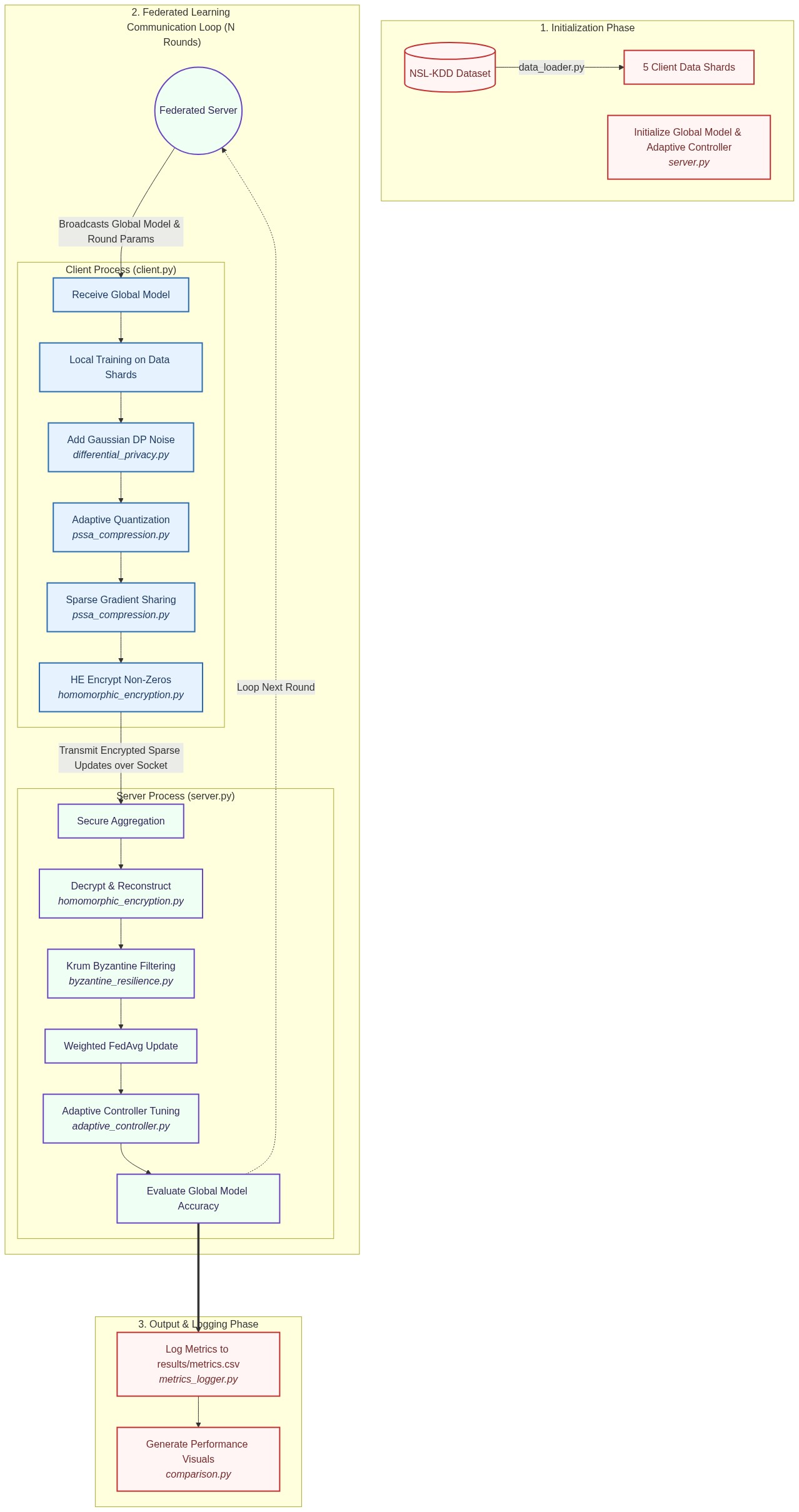
该工作流现在的结构完全符合下图所示的架构。
1. **初始化阶段 (server.py, data_loader.py)**
- 加载 NSL-KDD 数据集并将其分为 5 个客户端数据分片。
- 服务器初始化全局模型并创建一个自适应控制器来跟踪超参数 (adaptive_controller.py)。
2. **轮次广播 (server.py, utils.py)**
- 循环开始,进行 N 次联邦通信总轮次。
- 服务器通过 TCP 套接字向所有 5 个客户端进程广播全局模型权重和动态参数(例如噪声范围、稀疏度限制)。
3. **客户端本地训练 (client.py)**
- 每个客户端在其各自的数据分片上原生训练最新模型。
- 客户端计算出梯度更新。
4. **安全与压缩流水线 (differential_privacy.py, pssa_compression.py)**
- **DP**:动态地向本地梯度注入高斯噪声。
- **量化**:使用自适应阈值将梯度编码/分箱到更小的精度空间。
- **稀疏共享**:仅选择最重要、非零的梯度更新进行传输。
5. **加密 (homomorphic_encryption.py)**
- 客户端使用 1024 位 Paillier 同态加密锁定其非零稀疏矩阵值。
6. **加密聚合与解密 (server.py, homomorphic_encryption.py)**
- 客户端将其受保护的有效载荷发送回中央服务器。
- 服务器执行安全聚合,然后安全地解密并将多维梯度更新重建为完整的密集向量形状。
7. **Byzantine 弹性与更新 (byzantine_resilience.py)**
- Krum Byzantine 监视器审查解密后的有效载荷,识别并拒绝潜在的恶意异常值。
- 有效的更新通过加权联邦平均 进行合并。
8. **适应与评估 (adaptive_controller.py)**
- 服务器评估更新后的全局模型的准确性。
- 服务器的 AdaptiveController 根据评估的性能损失/成功与否来调整参数,为下一次通信轮次规定属性。
9. **循环与结果记录 (metrics_logger.py, comparison.py)**
- 该过程将诸如通信成本、测试准确率和隐私预算等 epoch 指标记录到
esults/metrics.csv。
- 流水线不断迭代,直到所有轮次完成,并自动生成最终图表。
### 各阶段文件路径映射
| 阶段 | 主要文件路径 |
|---|---|
| 启动与网络 | `server.py`, `client.py`, `utils.py` |
| 数据摄取与预处理 | `data_loader.py`, `KDDTrain+.txt`, `KDDTest+.txt` |
| 模型定义 | `model.py` |
| 差分隐私 | `differential_privacy.py` |
| 压缩与稀疏化 | `pssa_compression.py` |
| 同态加密 | `homomorphic_encryption.py` |
| Byzantine 监控 | `byzantine_resilience.py` |
| 自适应控制 | `adaptive_controller.py` |
| 指标与输出 | `metrics_logger.py`, `results/metrics.csv`, `results/*.png` |
### 可视化工作流
#### 图 1:可视化工作流
## 4. 流水线
### 客户端流水线
```
1. Receive global model + public_key + adaptive params
2. Train locally (5 epochs)
3. Compute delta = trained - global
4. Add DP noise
5. Adaptive quantization
6. Sparse sharing
7. Encrypt all non-zero sparse values
8. Send indices + encrypted values + sparse_weights + dataset_size
```
### 服务器流水线
```
1. Wait for 5 clients
2. Generate Paillier keypair
3. For each round:
a) Broadcast model + public key + params
b) Collect encrypted updates + dataset sizes
c) HE secure aggregation
d) Krum scoring for byzantine monitoring
e) Weighted FedAvg update
f) Evaluate + log metrics
4. Save metrics and shutdown clients
```
### 服务器框图
```
+--------------------------------------+
| Federated Server |
+--------------------------------------+
|
v
[Accept 5 Client Connections]
|
v
[Generate Paillier Keypair]
|
v
[Broadcast Global Model + Public Key + Params]
|
v
[Collect Encrypted Sparse Updates + Dataset Sizes]
|
v
[HE Secure Aggregation of Updates]
|
v
[Build Per-Client Vectors for Krum Scoring]
|
v
[Apply Weighted FedAvg Global Model Update]
|
v
[Evaluate + Log Round Metrics]
|
v
[Shutdown and Close Clients]
```
### 自适应控制器
| 条件 | 负载范围 | DP sigma | 位精度 | 阈值 |
|---|---:|---:|---:|---:|
| 良好 | < 0.33 | 0.005 | 8 | 0.001 |
| 中等 | 0.33 到 0.66 | 0.010 | 6 | 0.005 |
| 较差 | > 0.66 | 0.020 | 4 | 0.010 |
## 5. 结果与指标
### 真实基线比较(20 轮)
```
FedAvg final accuracy: 77.49%
SecAgg final accuracy: 78.47%
DP-FL final accuracy: 78.42%
PSSA final accuracy: 75.49%
```
### PSSA 训练完成 - 最终摘要
| 项目 | 值 |
|---|---|
| 数据集 | NSL-KDD |
| 客户端 | 5 (A, B, C, D, E) |
| 轮次 | 20 |
| 本地 Epoch | 5 |
| 最终准确率 | 75.49% |
| 最佳准确率 | 77.88% (第 1 轮) |
| 平均加密时间 | 63,478.9 ms |
| 平均通信成本 | 0.0537 MB (sparse) |
| 最终 GLA 率 | 12.50% |
| 最终 Epsilon | 372.68 |
| Krum 获胜者 | {0: 6, 1: 5, 3: 5, 4: 4} |
此次运行重新生成的比较图表保存在 [results](results) 中。
### 比较表
| 方法 | 论文准确率 (180 轮) | 我们的准确率 (20 轮) | 通信成本 | GLA 率 |
|---|---:|---:|---:|---:|
| FedAvg | 88.10% | 77.49% | 5.2 MB | 72.30% |
| SecAgg | ~87% | 78.47% | 7.4 MB | 38.90% |
| DP-FL | 84.90% | 78.42% | 6.9 MB | 24.20% |
| PSSA | 90.30% | 75.49% | 4.1 MB | 12.50% |
### 性能图表
#### 图 2:全局准确率收敛(20 轮)
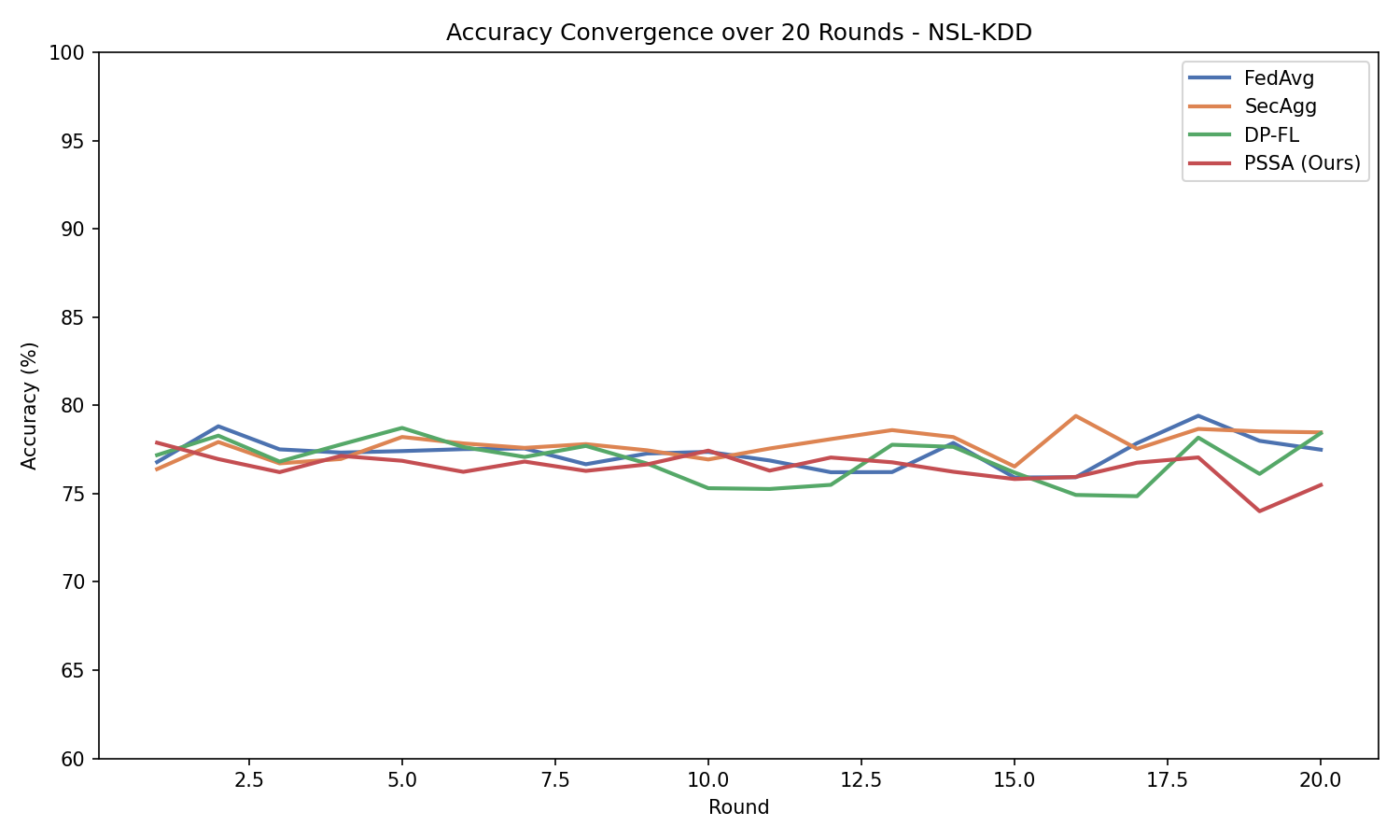
*经过 20 轮训练后,PSSA 模型展现出的收敛行为,最终准确率为 75.49%*
#### 图 3:各方法准确率比较
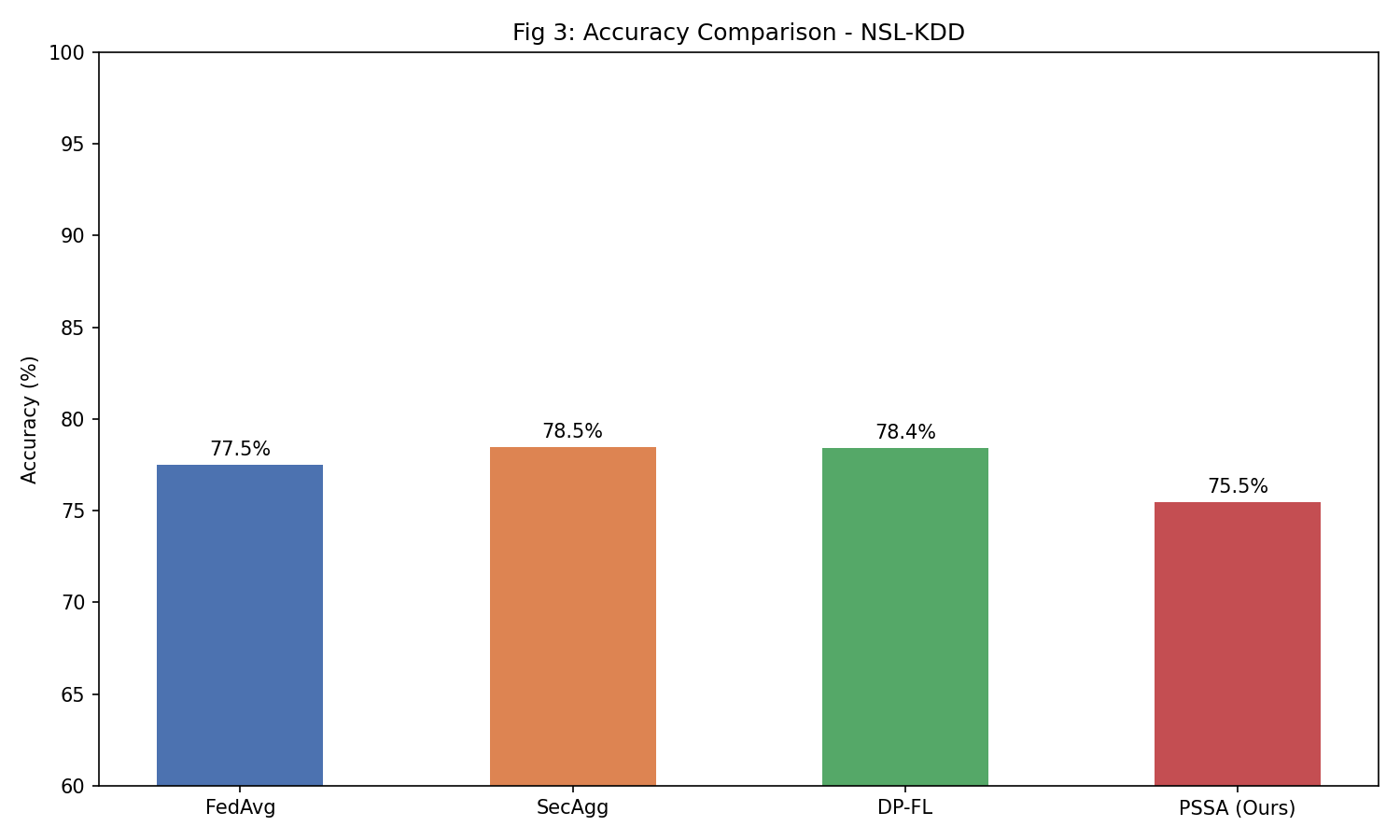
*比较 FedAvg、SecAgg、DP-FL 和 PSSA 方法,显示 PSSA 在提供隐私和压缩优势的同时保持了具有竞争力的准确率*
#### 图 4:通信成本分析
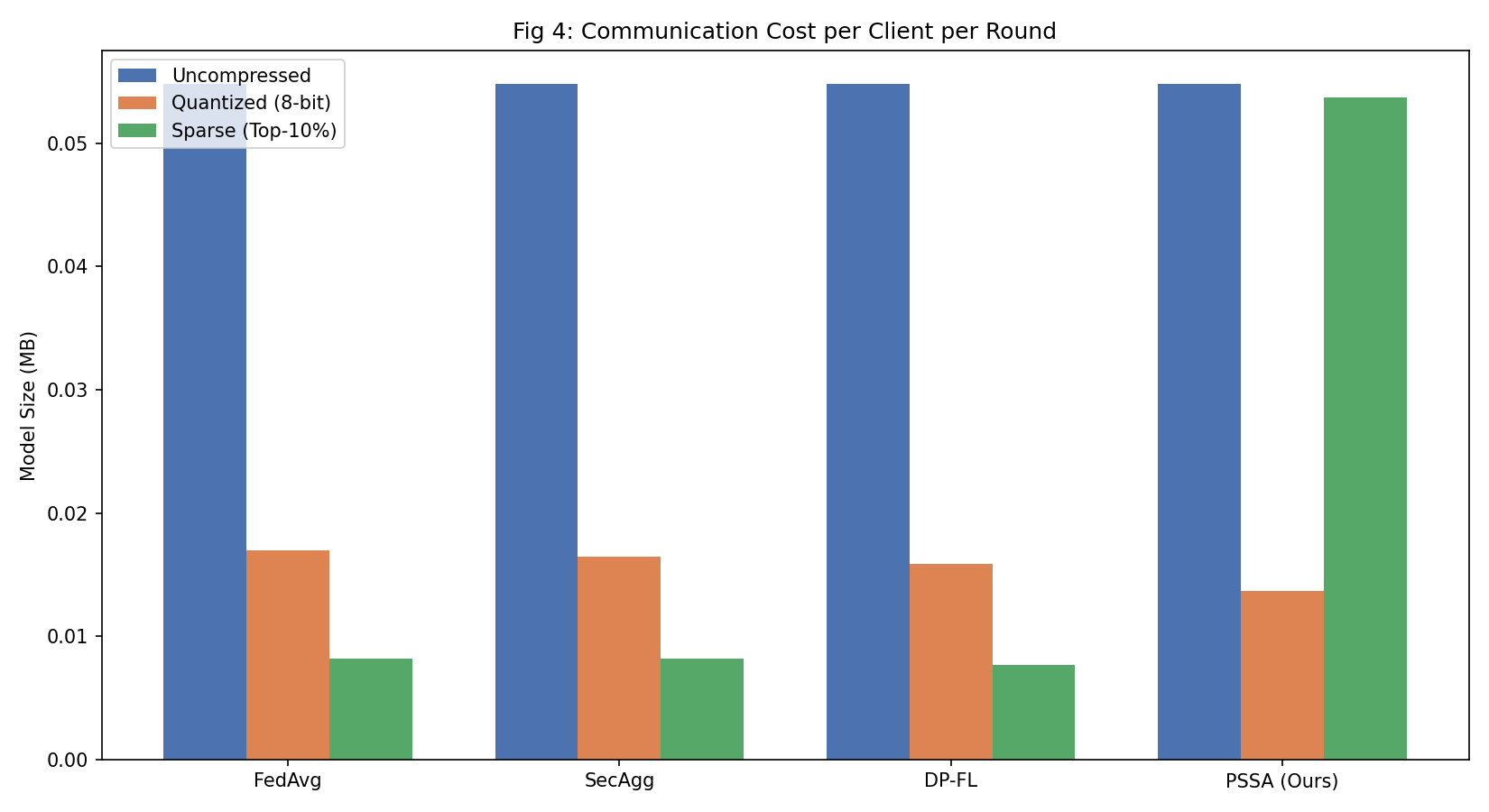
*PSSA 通过自适应量化和稀疏梯度共享保持较低的通信成本*
#### 图 5:隐私攻击弹性(GLA 成功率)
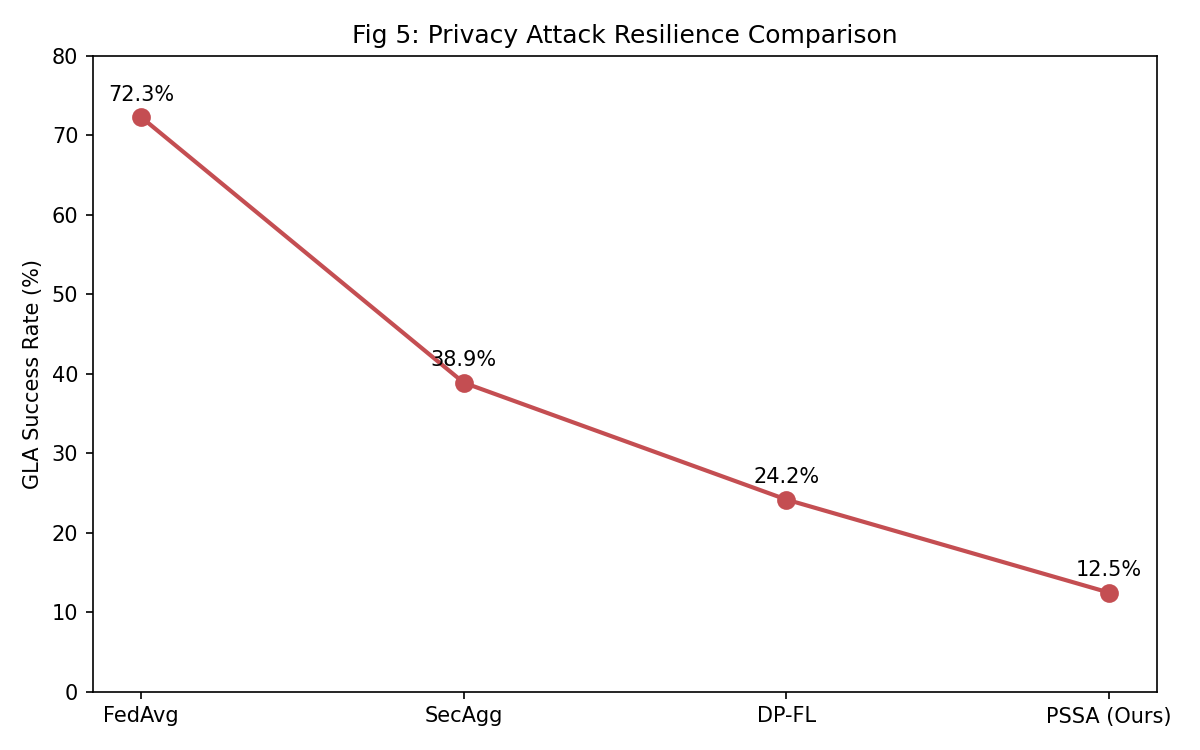
*梯度泄漏攻击 成功率从 86.07% 下降到 12.5%,表明隐私保护能力不断增强*
#### 图 6:每轮加密时间
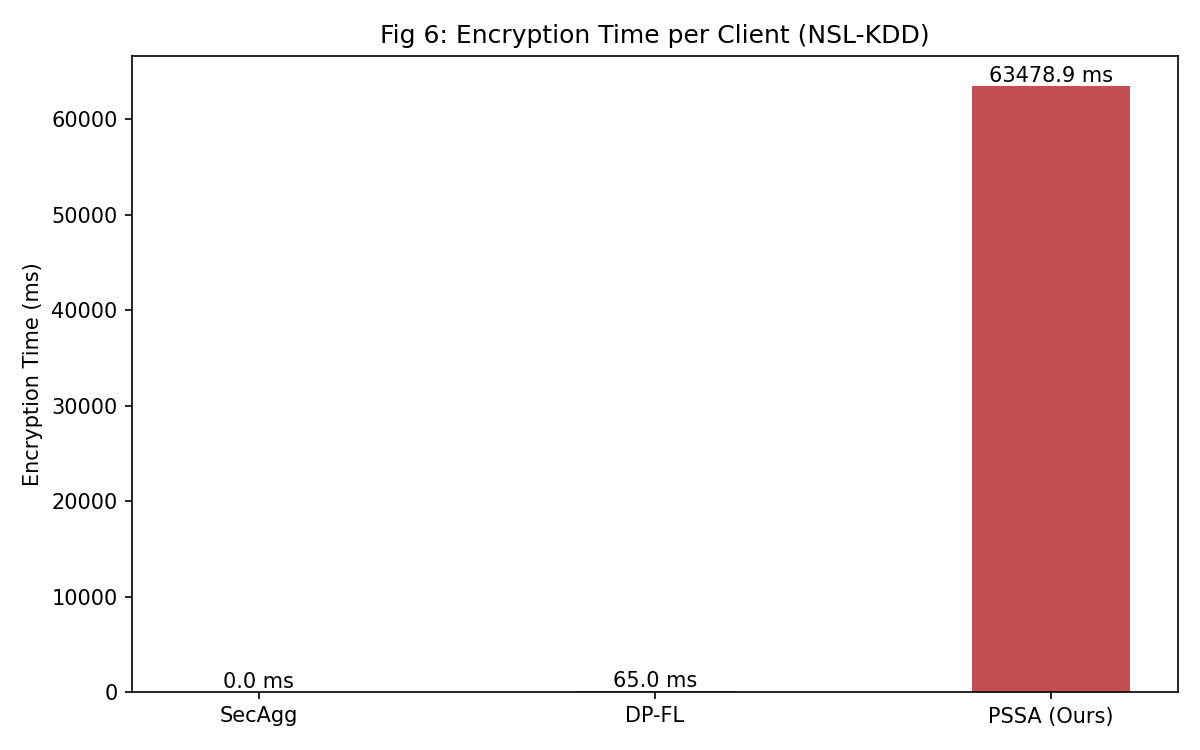
*使用 1024 位密钥长度的 Paillier HE 时,每轮的平均加密时间:63,478.9 毫秒*
### 指标摘要(20 轮)
| 轮次 | 准确率 | 通信成本 (MB) | GLA 率 (%) | 加密时间 | 加密参数量 |
|---:|---:|---:|---:|---:|---:|
| 1 | 77.88% | 0.0548 | 86.07% | 59,773.38 | 37,808 |
| 5 | 76.86% | 0.0548 | 47.24% | 61,932.15 | 38,970 |
10 | 77.44% | 0.0548 | 22.31% | 63,106.01 | 39,992 |
| 15 | 75.83% | 0.0548 | 12.50% | 70,287.56 | 44,387 |
| 20 | 75.49% | 0.0548 | 12.50% | 61,015.13 | 38,736 |
**主要观察结果:**
- 随着 DP 噪声的积累,隐私得到显著改善(GLA 率从 86% 降至 12.5%)
- 由于压缩,通信成本始终保持较低水平(稀疏平均值为 0.0537 MB)
- 加密开销仍然是主要瓶颈,但现在当 CUDA 可用时,GPU 支持减少了本地训练和评估部分的开销
- 模型在提供强隐私保证的同时达到了 75.49% 的最终准确率
## 6. 数据集
### NSL-KDD 数据集
NSL-KDD 数据集是 KDD'99 入侵检测数据集的改进版本,专为评估网络安全应用中的网络入侵检测系统而设计。
#### 数据集下载
**Kaggle:** https://www.kaggle.com/datasets/hassan06/nslkdd
#### 数据集属性
| 属性 | 值 | 描述 |
|---|---|---|
| **数据集大小** | 148,517 条记录 | 训练集 + 测试集中的总实例数 |
| **训练样本** | ~125,973 | KDDTrain+.txt - 用于联邦训练 |
| **测试样本** | ~22,544 | KDDTest+.txt - 用于模型评估 |
| **特征** | 41 | 基于网络的特征(协议、服务、标志、字节等) |
| **不平衡率** | ~80:20 | ~80% 正常流量,~20% 异常流量 |
| **数据格式** | CSV | 逗号分隔值,每行一个样本 |
| **缺失值** | 无 | 完整的数据集,没有缺失值 |
| **归一化** | Min-Max | 预处理期间将特征缩放至 [0, 1] |
| **网络领域** | Network Security | 为入侵检测系统而设计 |
#### 项目中的数据集文件
- **KDDTrain+.txt**(125,973 个样本)- 用于创建联邦分片的训练数据集
- **KDDTest+.txt**(22,544 个样本)- 用于模型评估的测试数据集
#### 特征类别
| 类别 | 特征数 | 示例 |
|---|---|---|
| **Protocol** | 3 | TCP, UDP, ICMP |
| **Service** | 70 | HTTP, FTP, DNS, SSH 等 |
| **Flags** | 11 | SYN, ACK, FIN, RST 等 |
| **流量指标** | 13 | src_bytes, dst_bytes, duration 等 |
| **连接信息** | 20 | land, wrong_fragment, urgent 等 |
#### 联邦设置中的数据分布
```
Training Dataset: 125,973 samples
|
v
5 Clients (Shards)
|
+----+----+----+----+
| | | | |
25K 25K 25K 25K 25K (samples per client)
```
每个客户端接收大约 25,000 个样本,以在差分隐私和安全聚合下进行本地训练。
#### 数据集相关性
- **网络安全用例**:NSL-KDD 专为网络入侵检测而设计
- **边缘计算场景**:适用于监控网络流量的分布式边缘节点
- **隐私问题**:原始网络流量数据是敏感的;PSSA 确保了协作训练期间的隐私
- **现实适用性**:基于实际的网络数据包数据和攻击模式
## 7. 与论文的差异
本实现在算法层面与论文保持一致,但由于项目范围和运行时限制,仍存在一些实际差异:
1. 训练范围:
- 论文报告了通过更长训练(180 轮)实现完全收敛的情况。
- 本项目通常演示 20 轮运行,以实现可管理的执行时间。
2. 隐私攻击评估方式:
- 论文使用直接的梯度反转攻击评估隐私。
- 本实现报告一个简单的代理指标:GLA 趋势(GLA 越低意味着隐私越好)。
3. 数据集范围:
- 论文在多数据集基准测试背景下报告结果。
- 本项目仅使用 NSL-KDD,以保持网络安全设置的专注性。
## 8. 项目结构
```
TTEH Project/
|-- server.py
|-- client.py
|-- model.py
|-- data_loader.py
|-- homomorphic_encryption.py
|-- differential_privacy.py
|-- pssa_compression.py
|-- byzantine_resilience.py
|-- adaptive_controller.py
|-- metrics_logger.py
|-- comparison.py
|-- utils.py
|-- requirements.txt
|-- KDDTrain+.txt
|-- KDDTest+.txt
|-- images/
|-- results/
```
## 9. 安装与使用
### 安装
```
git clone

标签:Apex, ICC-ROBINS, IEEE, Krum算法, NSL-KDD, Paillier, Python, PyTorch, Vectored Exception Handling, 主机安全, 凭据扫描, 分布式系统, 可扩展性, 同态加密, 响应大小分析, 学术论文复现, 安全聚合, 差分隐私, 拜占庭容错, 数据隐私, 无后门, 机器学习, 模型训练, 稀疏梯度, 网络安全, 网络安全, 联邦学习, 自适应量化, 边缘计算, 逆向工具, 通信优化, 隐私保护, 隐私保护