jarems421/Beaconing-detection-system
GitHub: jarems421/Beaconing-detection-system
一套面向网络流级别 C2 信标行为的比较检测研究框架,在合成和 CTU-13 数据上系统评估规则、统计、异常和机器学习四类检测器,并揭示最小证据和域偏移对检测效果的影响。
Stars: 1 | Forks: 0
# 信标检测系统
在存在时间抖动、大小变化、突发流量、高难度良性配置文件以及 CTU-13 公共数据域偏移的情况下,基于流级别的命令与控制 (C2) 信标行为检测。
**核心结论:** 在受控合成数据上的强劲表现并不能自动迁移到公共流数据上。最小证据要求和 CTU-13 模式/域偏移是主要的限制因素。
## 分支指南
- `main`:保留的研究分支,用于最终的比较研究、基准测试叙述以及报告风格的结构展示。
- `operational-system`:可操作的 CLI 分支,用于规范化 CSV、Zeek 和 NetFlow/IPFIX 数据接入、混合评分、清单、诊断以及经过 CI 测试的工作流。
## 概览
| 问题 | 简答 |
| --- | --- |
| 任务 | 从流级别的行为而非负载签名中检测 C2 信标。 |
| 方法 | 在合成和 CTU-13 流量上,比较可解释规则、统计评分、异常检测和监督式 ML。 |
| 最佳合成模型 | Random Forest 在受控合成基准测试中表现最强。 |
| 核心发现 | 最小证据至关重要:隐蔽的低事件、高抖动、大小重叠的流需要更多的历史数据支持。 |
| CTU 结论 | 公共 CTU-13 验证暴露了仅靠合成结果无法发现的模式/域偏移问题。 |
| 最终声明 | 这是一项流级别的比较检测研究,而不是一个可投入生产的 SOC 检测器。 |
## 动机
信标活动可能看起来具有周期性,但真实的良性流量和攻击者的隐蔽行为使得简单的周期性检查变得不可靠。攻击者可以添加时间抖动、改变负载大小、进行突发通信,或者将流保持得足够短,以至于没有足够的证据可供学习。本项目研究了基于流级别的行为检测在哪些情况下有效、在哪些情况下会失效,以及当相同的概念针对 CTU-13 公共流数据进行测试时,结果会发生怎样的变化。
## 主要发现
- 流级别的行为特征能够很好地检测固定的、带抖动的和突发的合成信标活动。
- 复杂的重复良性流量以及快捷方式/重叠压力暴露了误报和脆弱的假设。
- 最有力的研究结果是关于最小证据的发现:要使聚合特征变得可靠,隐蔽的信标活动需要足够多的流历史记录。
## 研究问题
当攻击者引入时间抖动、大小变化和基于突发的通信模式时,基于流级别的统计和机器学习方法能多有效地检测信标流量?
## 架构
```
flowchart LR
A[Synthetic generator / CTU-13 public data] --> B[Flow construction]
B --> C[Behavioural feature extraction]
C --> D[Detector families]
D --> E[Evaluation tracks]
E --> F[Report-ready tables and figures]
D --> D1[Rules]
D --> D2[Statistical scoring]
D --> D3[Anomaly detection]
D --> D4[Supervised ML]
E --> E1[Synthetic hardened grid]
E --> E2[Stress and minimum-evidence studies]
E --> E3[CTU-13 validation]
```
## 关键结果
项目最重要的发现是最小证据结果:只需少量流历史记录即可检测出简单的信标模式,而针对具有时间和大小抖动的隐蔽流量,则需要更多证据才能使当前的流级别特征变得可靠。
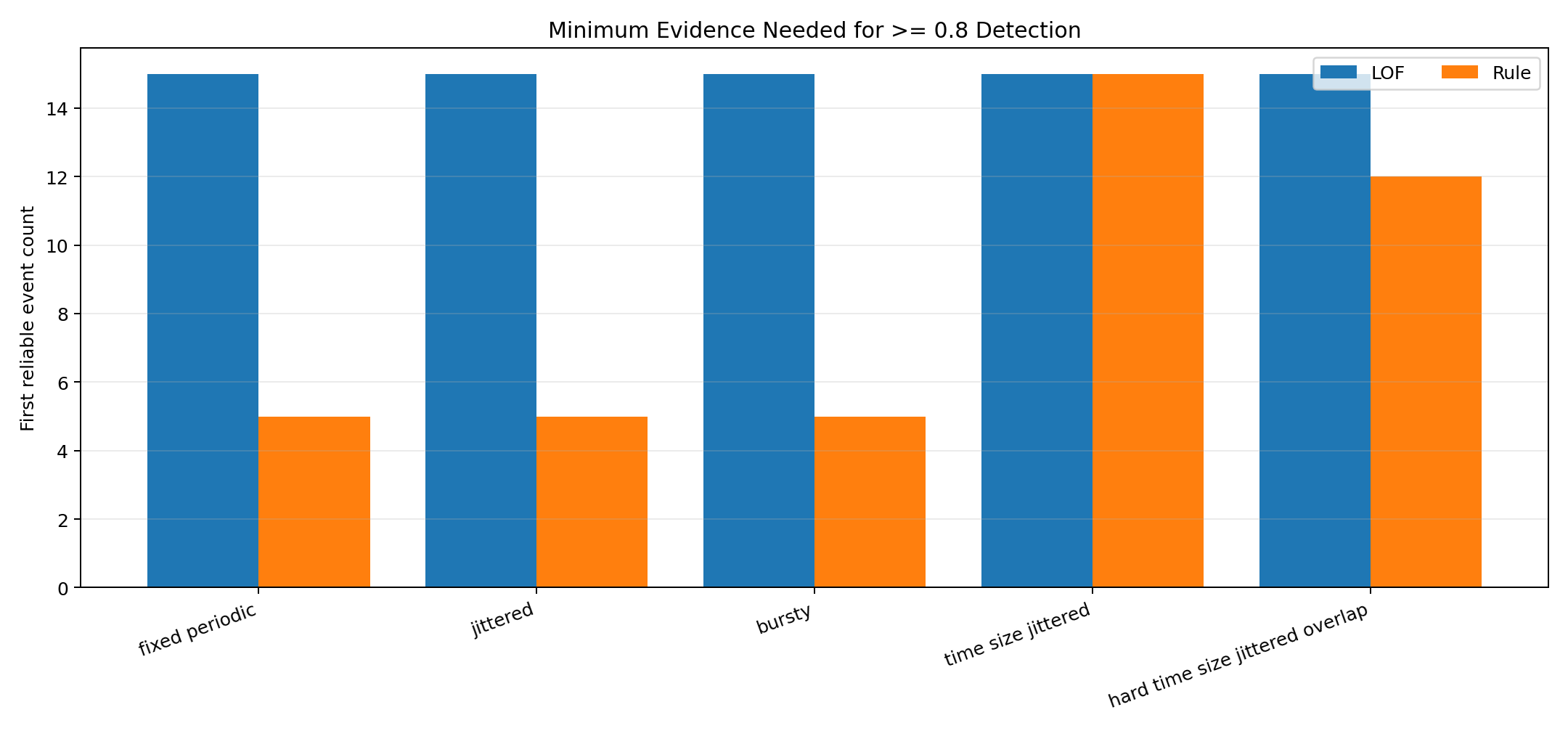
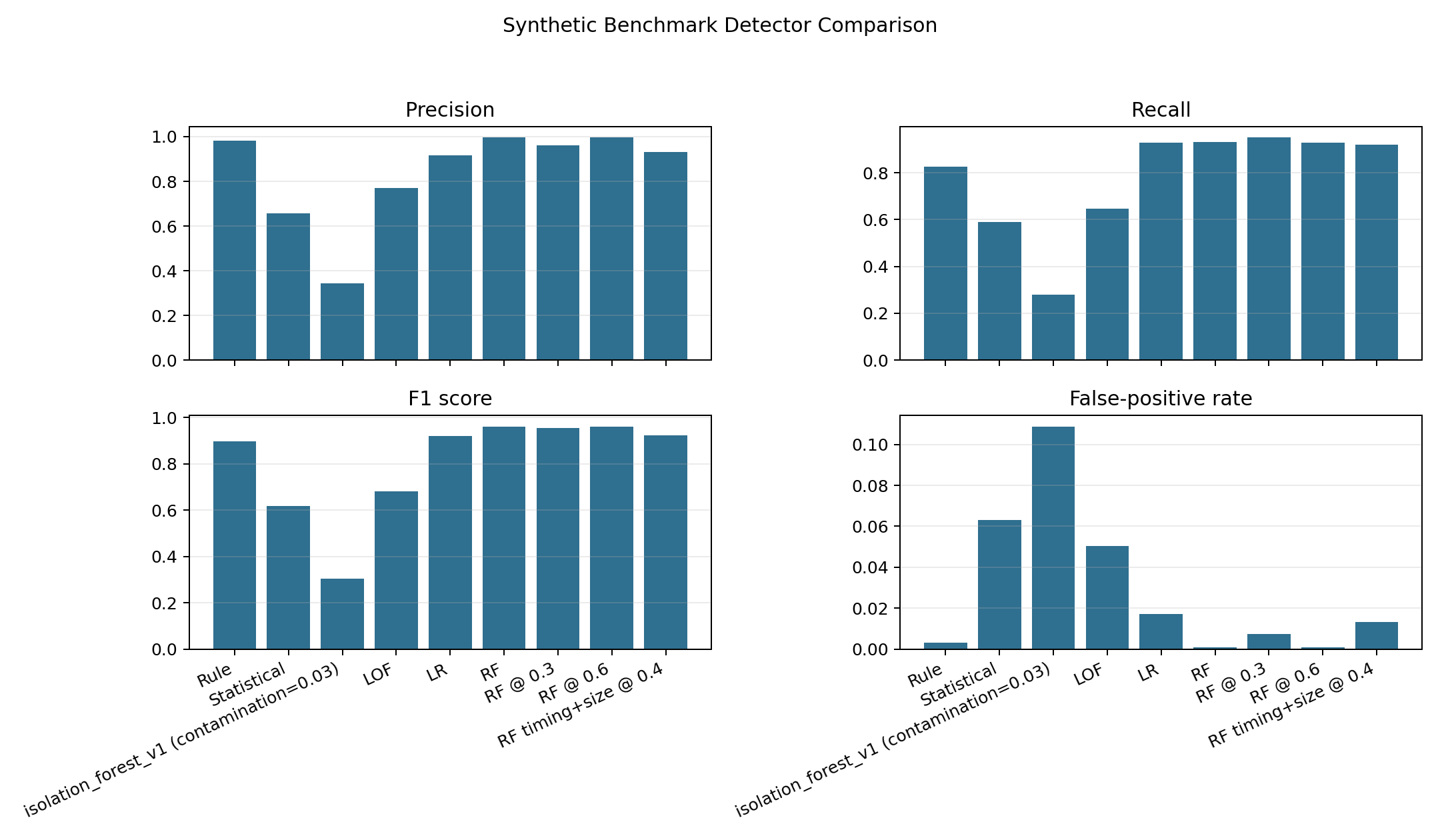
在受控合成基准测试中,Random Forest 是整体表现最强的模型,而冻结规则基线仍然是主要的可解释性参考标准。
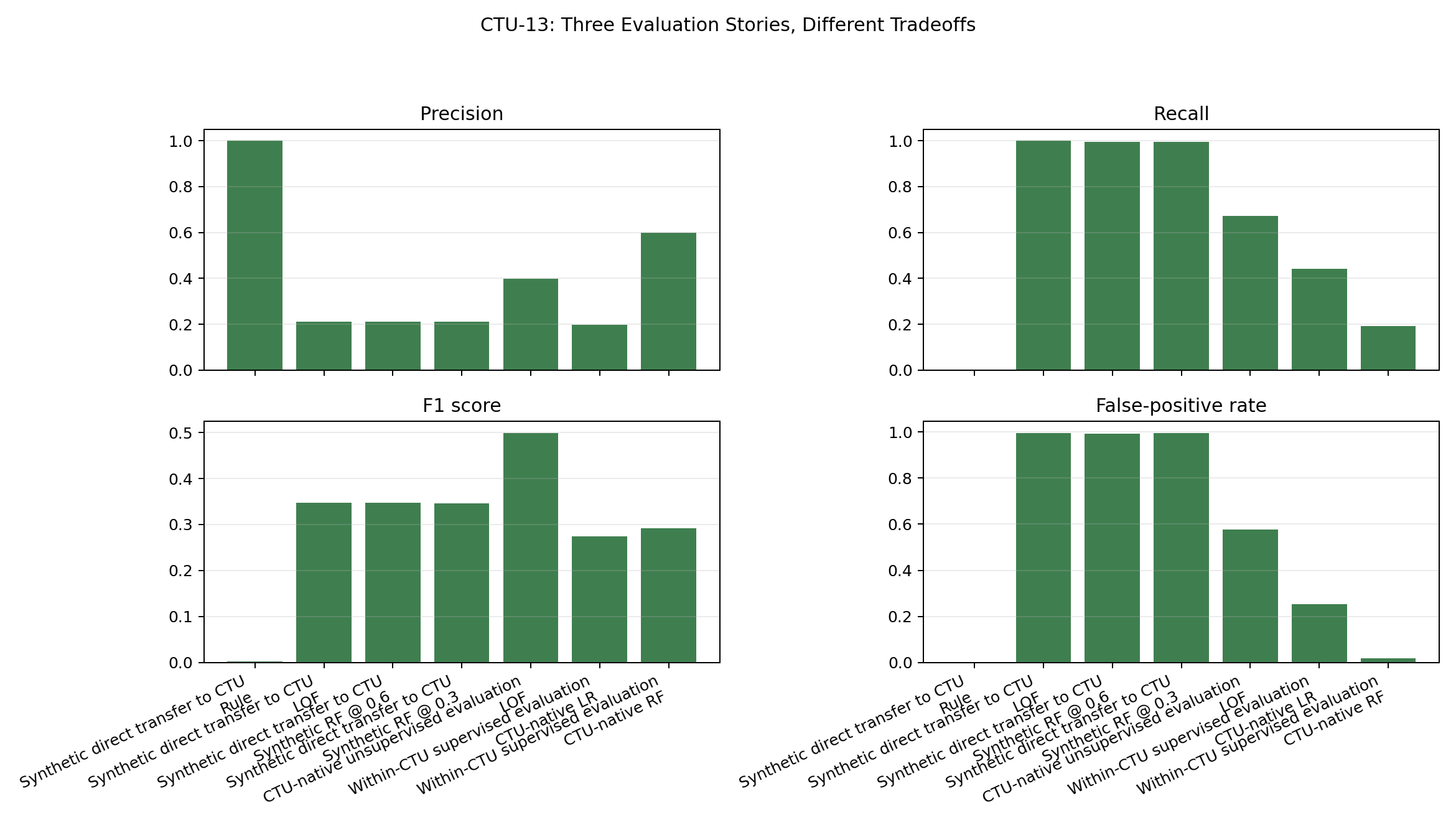
公共数据验证的结果则更为谨慎。CTU-13 暴露了模式和域偏移问题:合成数据迁移的 RF 可以检测出许多标记为僵尸网络的流,但会产生大量误报;而 CTU 原生方法虽然能更好地适应公共数据模式,但仍然存在局限性。
## 检测器权衡
| 检测器家族 | 在项目中的角色 | 主要优势 | 主要局限性 |
| --- | --- | --- | --- |
| 冻结规则 | 可解释的参考基线 | 易于检查和解释 | 在隐蔽的定时和良性重复流量下表现脆弱 |
| 统计 z-score | 透明的统计基线 | 简单的良性参考比较 | 在多模态良性行为下表现较弱 |
| Isolation Forest / LOF | 异常基线 | 有用的无监督比较参考点 | 整体并非最强;在低证据情况下可能不稳定 |
| Logistic Regression | 线性监督基线 | 清晰的监督参考 | 不如 Random Forest 灵活 |
| Random Forest | 最强的合成基准模型 | 在受控合成数据上表现最佳 | 可解释性较低,且在最困难的低证据场景下仍然较弱 |
## 公共数据验证
CTU-13 的证据被故意分为三个阶段:
```
Synthetic direct transfer to CTU
CTU-native unsupervised evaluation
Within-CTU supervised evaluation
```
这种分离非常重要。合成数据直接迁移暴露了域偏移问题,CTU 原生无监督评估直接使用了 `.binetflow` 字段,而 CTU 内部监督评估则测试了这些原生特征在感知场景的拆分下是否具有判别力。
## 仓库指南
| 路径 | 用途 |
| --- | --- |
| `demo-app/` | 用于操作演示的 Next.js 应用,以 `demo-app` 作为根目录,可直接部署到 Vercel。 |
| `src/beacon_detector/` | 核心包:生成/加载、流、特征、检测器、评估和 CLI。 |
| `tests/` | 针对模型、特征、评估、CTU 适配器、导出和 CLI 管道的回归测试。 |
| `docs/operational_demo.md` | 真实的 CLI 演示流程和静态可视化演示入口。 |
| `docs/operational_system.md` | 操作批量评分设计和 v1 命令约定。 |
| `docs/operational_example.md` | 使用提交的 CSV 固定数据的小型端到端操作 CLI 示例。 |
| `docs/project_walkthrough.md` | 引导式项目 walkthrough。 |
| `docs/report_draft.md` | 更详尽的技术报告。 |
| `results/figures/final_story/` | 建议优先查看的核心图表。 |
| `results/tables/final_story/` | 为最终结论整理的汇总表格。 |
| `results/tables/report_ready/` | 被最终结论层使用的中间态就绪报告汇总。 |
| `data/synthetic/sample_events.csv` | 生成的小规模合成样本。 |
| `data/public/README.md` | 预期的 CTU-13 本地数据布局;原始 CTU 文件未被提交。 |
## 项目演练
如需获取面向读者的精简版项目概览,请使用:
```
docs/project_walkthrough.md
```
该演练将 README 图表、最小证据结果、CTU 域偏移结果以及一个本地评分器命令串联起来。它不是一个仪表板或生产监控界面。
## 设置
```
py -3.10 -m venv .venv
.\.venv\Scripts\Activate.ps1
python -m pip install --upgrade pip
python -m pip install -r requirements.txt
python -m pip install -e .
```
可选的代码检查工具:
```
python -m pip install -e ".[dev]"
```
## 快速开始
运行测试:
```
python -m unittest discover -s tests
```
运行代码检查:
```
python -m ruff check .
```
运行一次快速的合成评估:
```
python -m beacon_detector.evaluation.run --quick
```
## 操作批量 CLI
操作批处理路径将规范化 CSV、Zeek `conn.log` 或 NetFlow/IPFIX 格式的 CSV 作为一批数据进行评分,并输出四个默认结果:
```
alerts.csv
scored_flows.csv
run_summary.json
report.md
```
规范的标准化 CSV 列:
| 列名 | 是否必填 | 备注 |
| --- | --- | --- |
| `timestamp` | 是 | ISO-8601 时间戳;未指定时区的时间戳将被视为 UTC。 |
| `src_ip` | 是 | 源主机。 |
| `direction` | 是 | 用于流分组键的方向标签。 |
| `dst_ip` | 是 | 目标主机。 |
| `dst_port` | 是 | 目标端口。 |
| `protocol` | 是 | `tcp` 或 `udp`。 |
| `total_bytes` | 是 | 非负整数。 |
| `src_port` | 否 | 仅为上下文捕获,不用于默认分组。 |
| `duration_seconds` | 否 | 非负数值。 |
| `total_packets` | 否 | 非负整数。 |
| `label` | 仅限训练时 | `benign`、`beacon` 或 `unknown`;未知行在训练时将被跳过。 |
验证标准化 CSV:
```
beacon-ops validate --input data/operational/sample_normalized.csv
```
对标准化 CSV 进行评分:
```
beacon-ops score --input data/operational/sample_normalized.csv --input-format normalized-csv --output-dir results/operational/run_001
```
从带标签的标准化 CSV 行训练 Random Forest 模型:
```
beacon-ops train-model --train data/operational/labelled_train.csv --output-dir models/operational/rf_v1
```
当存在足够的 benign 和 beacon 分组时,训练产物将包含 StratifiedGroupKFold 验证指标。这些分组使用与评分相同的操作键:
`src_ip + dst_ip + dst_port + protocol + direction`。
模型目录还包含一个产物清单,记录了特征名称、标签映射、验证指标、依赖版本、训练来源引用以及持久化警告。
将合成流量导出至相同的训练约定中,用于引导/演示运行:
```
beacon-ops export-synthetic --output data/operational/synthetic_train.csv --seed 7
```
合成导出适用于冒烟测试和演示,但它们不能作为具备部署就绪状态的训练证据。
在运行时加载已保存的模型产物进行评分:
```
beacon-ops score --input data/operational/sample_normalized.csv --input-format normalized-csv --model-artifact models/operational/rf_v1 --output-dir results/operational/run_002
```
保存的 RF 产物包含经过验证的阈值配置文件:`conservative`、`balanced` 和 `sensitive`。在评分时选择其中之一:
```
beacon-ops score --input data/operational/sample_normalized.csv --input-format normalized-csv --model-artifact models/operational/rf_v1 --profile balanced --output-dir results/operational/run_003
```
对 Zeek `conn.log` 进行评分:
```
beacon-ops score --input data/zeek/conn.log --input-format zeek-conn --output-dir results/operational/zeek_run_001
```
对 NetFlow/IPFIX 风格的 CSV 进行评分:
```
beacon-ops score --input data/flows/netflow.csv --input-format netflow-ipfix-csv --output-dir results/operational/netflow_run_001
```
运行一个已提交的 NetFlow/IPFIX 示例:
```
beacon-ops score --input data/operational/fixtures/netflow_common_aliases.csv --input-format netflow-ipfix-csv --output-dir results/operational/example_netflow_fixture
```
打开已提交的视觉演示页面:
```
docs/operational_demo.html
```
运行已提交的端到端示例:
```
beacon-ops score --input data/operational/example_score.csv --input-format normalized-csv --output-dir results/operational/example_rules
```
如果不使用 `--model-artifact`,评分将使用保守的规则路径。如果使用了 `--model-artifact`,评分将加载已保存的 Random Forest 产物,并写入混合的规则与 RF 分数,而不会重新训练。
`run_summary.json` 文件同时也是评分运行的清单:它记录了输出角色、评分语义、接入计数、跳过行的原因、分组策略、运行时环境以及加载的模型元数据。
## 解释分数
- `rule_score` 是应用阈值之前的可解释基线分数。
- `rf_score` 是来自已保存产物的未校准 Random Forest 分数。请将其用于排序和阈值策略,而不是直接作为概率使用。
- `hybrid_score` 是用于结合规则和 RF 信号的归一化排名分数。
- `confidence` 是 `alerts.csv` 中的一种相对于阈值的显示启发式指标,而不是校准后的概率。
- `report.md` 和 `run_summary.json` 记录了当前活动的阈值配置文件、分组验证指标以及来自外折训练分数的校准诊断信息。
## 已知接入限制
- 操作适配器路径支持 `tcp` 和 `udp`;不支持的协议将被跳过并记录在 `run_summary.json` 中。
- Zeek 接入预期接收标准的 `conn.log`,该文件需包含 `#fields` 头部和常见的连接列。
- NetFlow/IPFIX CSV 接入基于别名。它可以处理常见的导出器字段名称和 IPFIX Information Element 名称,但不实现模板协商或支持每个供应商特定的列。
- 仅含头部内容的输入会快速失败,格式错误的必填值也会快速失败,可选缺失字段在标准化事件记录中将留空。
- CTU `.binetflow` 仍保留在研究/演示路径中,并不属于操作训练的约定。
## 复现关键产物
从现有导出重新生成就绪报告和最终结论产物:
```
python -c "from beacon_detector.evaluation.report_artifacts import build_report_artifacts; build_report_artifacts()"
```
## CTU 评估命令
运行 CTU 直接迁移评估:
```
python -m beacon_detector.evaluation.run_ctu13 --scenario ctu13_scenario_5=data/public/ctu13/scenario_5/capture20110815-2.binetflow --scenario ctu13_scenario_7=data/public/ctu13/scenario_7/capture20110816-2.binetflow --scenario ctu13_scenario_11=data/public/ctu13/scenario_11/capture20110818-2.binetflow --output-dir results/tables/ctu13_multi
```
可选的“背景即良性”敏感度路径默认会限制每个场景保留的 CTU Background 特征行数,以便能够在本地工作站上完成运行;保守策略依然是主要的 CTU 直接迁移结果。
运行 CTU 原生特征路径比较:
```
python -m beacon_detector.evaluation.run_ctu13_native --scenario ctu13_scenario_5=data/public/ctu13/scenario_5/capture20110815-2.binetflow --scenario ctu13_scenario_7=data/public/ctu13/scenario_7/capture20110816-2.binetflow --scenario ctu13_scenario_11=data/public/ctu13/scenario_11/capture20110818-2.binetflow --output-dir results/tables/ctu13_native
```
运行 CTU 内部监督评估:
```
python -m beacon_detector.evaluation.run_ctu13_supervised --scenario ctu13_scenario_5=data/public/ctu13/scenario_5/capture20110815-2.binetflow --scenario ctu13_scenario_7=data/public/ctu13/scenario_7/capture20110816-2.binetflow --scenario ctu13_scenario_11=data/public/ctu13/scenario_11/capture20110818-2.binetflow --output-dir results/tables/ctu13_supervised
```
## 本地评分器
运行轻量级本地 CTU 评分器:
```
python -m beacon_detector.cli.score --input data/public/ctu13/scenario_7/capture20110816-2.binetflow --input-format ctu13-binetflow --detector ctu-native-random-forest --train-scenario ctu13_scenario_5=data/public/ctu13/scenario_5/capture20110815-2.binetflow --train-scenario ctu13_scenario_11=data/public/ctu13/scenario_11/capture20110818-2.binetflow --output-dir results/scored/ctu13_scenario_7
```
## 局限性
- 合成流量适用于受控实验,但它是简化过的,可能包含生成器产生的伪影。
- CTU-13 引入了模式和域偏移;公共数据的结果已被刻意分开报告。
- 流级别的聚合特征对于隐蔽的低事件流量存在证据限制。
- 本地评分器是一个研究型接口,而不是可投入生产的 SOC 检测器。
## 最终结论
合成基准测试的结果非常强劲,尤其是对于 Random Forest 而言,但最重要的研究发现是最小证据结果:只需少量流历史记录即可检测出简单的信标模式,而隐蔽的低事件、高抖动、大小重叠的模式则需要大量更多的证据。CTU-13 验证暴露了仅靠合成结果无法发现的模式和域偏移问题。CTU 原生建模是比强制将 CTU 双向行通过合成风格特征处理更好的公共数据路径,但它仍然不能作为部署证明。本项目是一项流级别的比较检测研究,而不是可投入生产的 SOC 检测器。
标签:Apex, C2 Beaconing, CSV解析, CTU-13, IPFIX, IP 地址批量处理, NetFlow, PB级数据处理, pip 包, Python, Rootkit, SOC工具, Zeek, 信标检测, 可解释性, 合成数据, 命令与控制, 域偏移, 安全研究社区, 安全运维, 异常基线, 异常检测, 恶意流量检测, 数据展示, 无后门, 时间抖动, 机器学习, 漏洞发现, 监督学习, 研究项目, 突发流量, 红队, 统计评分, 网络安全, 网络流量分析, 逆向工具, 随机森林, 隐私保护