Tencent-Hunyuan/HY-SOAR
GitHub: Tencent-Hunyuan/HY-SOAR
HY-SOAR 是一种扩散模型的自校正技术,用于在不使用奖励模型的情况下提升图像生成的对齐度和质量。
Stars: 738 | Forks: 64
# HY-SOAR:扩散模型中的自校正最优对齐与优化
## 🔥 最新动态
- **2026年4月**:🎉 HY-SOAR 开源 - 训练与评估代码公开可用。
## 🗂️ 目录
- [🔥 最新动态](#-news)
- [📖 介绍](#-introduction)
- [✨ 核心特点](#-key-features)
- [🖼 展示案例](#-showcases)
- [📑 开源计划](#-open-source-plan)
- [🛠 环境配置](#-environment-setup)
- [🎯 奖励准备](#-reward-preparation)
- [🚀 使用方法](#-usage)
- [📊 评估](#-evaluation)
- [🧾 数据格式](#-data-format)
- [📚 引用](#-citation)
- [🙏 致谢](#-acknowledgement)
## 📖 介绍
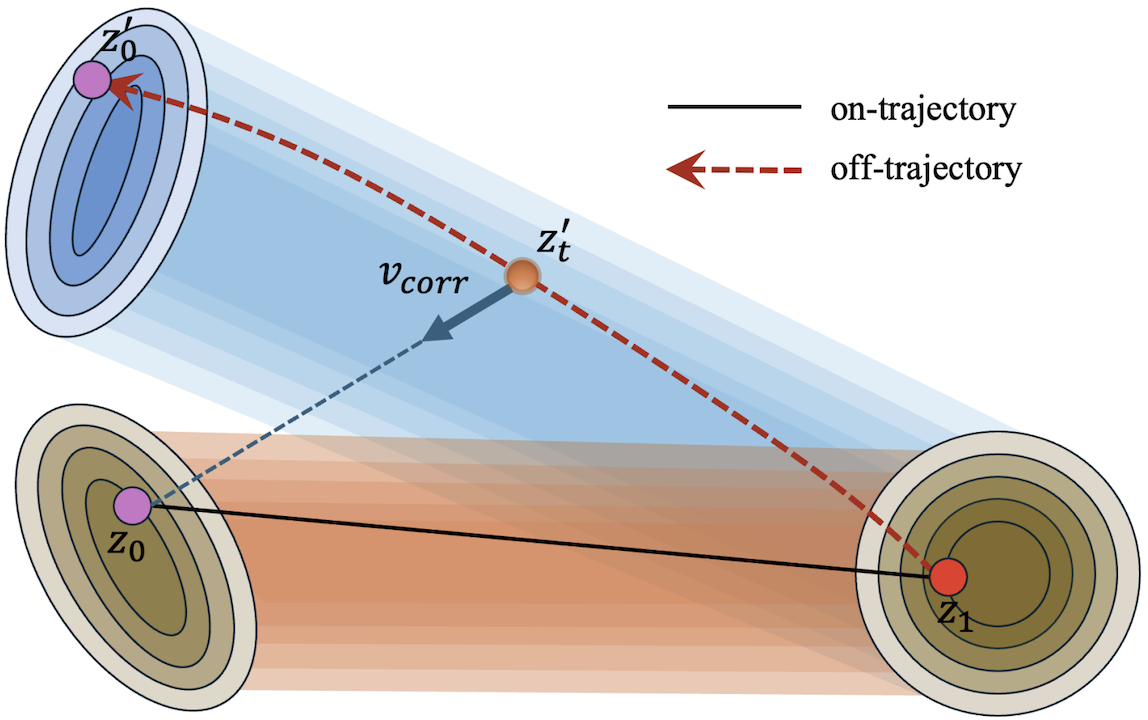
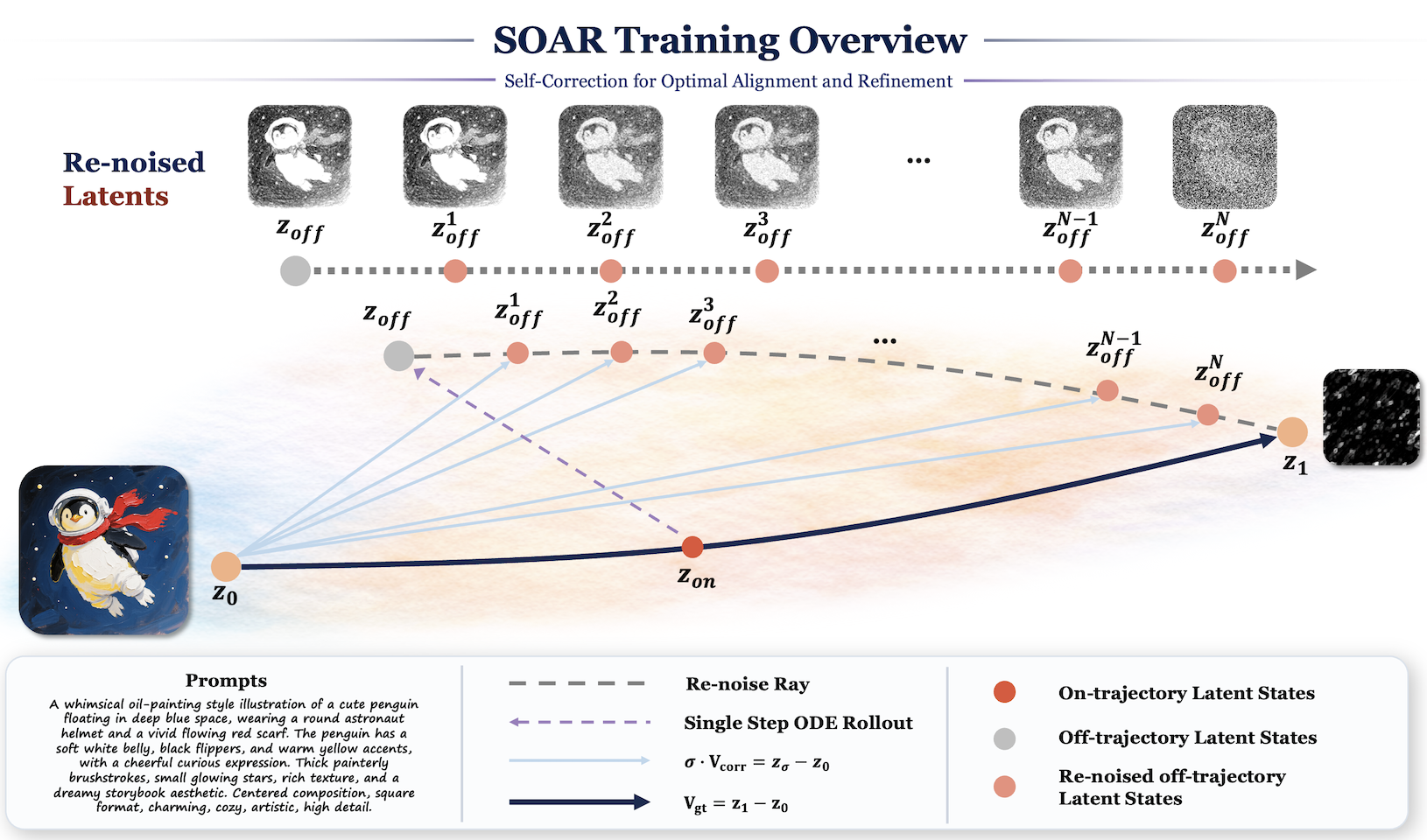
SOAR 不同于在完整轨迹后等待最终奖励,它教导模型在误差发生的时间步就校正自身的轨迹误差。给定一个干净的潜向量 $z_0$、噪声终点 $z_1$ 以及条件 $c$,SOAR 会:
1. 从当前轨迹采样一个带噪状态,并使用当前模型执行一次停止梯度的 CFG 推演步骤。
2. 将得到的偏离轨迹的状态重新加噪至同一个噪声终点 $z_1$,以创建辅助状态。
3. 使用解析的校正目标 $v_{\mathrm{corr}} = (z_{\sigma_{t'}} - z_0) / \sigma_{t'}$ 来监督去噪器。
这为 SOAR 提供了一个在策略的、密集的且无需奖励的训练信号。基础目标包含标准的 SFT,而辅助校正损失则在模型自身产生的相邻状态上进行训练,这使得 SOAR 成为一个更强大的首个后训练阶段,并且与后续基于奖励的对齐方法兼容。
## ✨ 核心特点
* 🧭 **曝光偏差校正:** SOAR 直接解决了真实训练状态与模型产生的推理状态之间的不匹配问题,这是许多复合去噪失败的根源。
* 🔁 **在策略偏离轨迹监督:** 偏离轨迹的状态由当前模型自身的推演产生,因此训练分布与模型共同演化,而非固定在 SFT 数据的轨迹上。
* 🎯 **无奖励密集目标:** SOAR 无需奖励模型、偏好标签或负样本。它提供每个时间步的校正监督,避免了最终奖励的信用分配问题。
* 📐 **几何校正目标:** 重新加噪使用与基础流匹配对相同的噪声终点,使辅助状态保持在原始传输射线附近,并产生一个锚定于 $z_0$ 的具体校正速度。
* 🔧 **兼容的后训练阶段:** SOAR 损失扩展了标准流匹配目标,因此它可以替代 SFT,成为一个更强大的首个后训练阶段,同时与后续的 RL 对齐方法保持兼容。
## 🖼 展示案例
**展示案例 1:美学奖励优化**
SOAR 与 Flow-GRPO、SFT 在不同训练步骤上的比较,针对多样化的提示(历史场景、奇幻艺术、人物肖像)优化美学质量。
**展示案例 2:CLIPScore 奖励优化**
在设计和海报生成提示上的比较,优化文本-图像对齐度(CLIPScore)。SOAR 展示了更强的文字渲染和构图保真度。
**展示案例 3:WebUI / 设计生成**
SOAR 在网页 UI 和平面设计生成上的结果,展示了准确的布局、排版和视觉层次。

## 📑 开源计划
- HY-SOAR
- [x] 训练代码
- [x] 评估代码
## 🛠 环境配置
我们的实现基于 [DiffusionNFT](https://github.com/NVlabs/DiffusionNFT) 和 [Flow-GRPO](https://github.com/yifan123/flow_grpo) 代码库,大部分环境保持一致。
克隆本仓库并通过以下命令安装依赖包:
```
git clone https://github.com/Tencent-Hunyuan/HY-SOAR.git
cd HY-SOAR
conda create -n hy-soar python=3.10.16
conda activate hy-soar
pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu126
pip install -e .
export PYTHONPATH=$PWD/sora:$PYTHONPATH
```
**基础模型:** 训练脚本预期使用 [stabilityai/stable-diffusion-3.5-medium](https://huggingface.co/stabilityai/stable-diffusion-3.5-medium) 作为预训练模型。你需要在 Hugging Face 上接受该模型的许可,并在训练前通过 `huggingface-cli login` 进行身份验证。
## 🎯 奖励准备
我们支持的奖励模型包括 [GenEval](https://github.com/djghosh13/geneval)、[OCR](https://github.com/PaddlePaddle/PaddleOCR)、[PickScore](https://github.com/yuvalkirstain/PickScore)、[ClipScore](https://github.com/openai/CLIP)、[HPSv2.1](https://github.com/tgxs002/HPSv2)、[Aesthetic](https://github.com/christophschuhmann/improved-aesthetic-predictor) 和 [ImageReward](https://github.com/zai-org/ImageReward)。此外,我们在 FlowGRPO 的基础上增加了对 `HPSv2.1` 的支持,并将 `GenEval` 从远程服务器简化为本地运行。
### 📦 检查点下载
```
mkdir reward_ckpts
cd reward_ckpts
# 美学
wget https://github.com/christophschuhmann/improved-aesthetic-predictor/raw/refs/heads/main/sac+logos+ava1-l14-linearMSE.pth
# GenEval
wget https://download.openmmlab.com/mmdetection/v2.0/mask2former/mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco/mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco_20220504_001756-743b7d99.pth
# ClipScore
wget https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K/resolve/main/open_clip_pytorch_model.bin
# HPSv2.1
wget https://huggingface.co/xswu/HPSv2/resolve/main/HPS_v2.1_compressed.pt
cd ..
```
### 🧪 奖励环境配置
```
# GenEval
pip install -U openmim
mim install mmengine
git clone https://github.com/open-mmlab/mmcv.git
cd mmcv; git checkout 1.x
MMCV_WITH_OPS=1 FORCE_CUDA=1 pip install -e . -v
cd ..
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection; git checkout 2.x
pip install -e . -v
cd ..
pip install open-clip-torch clip-benchmark
# 光学字符识别
pip install paddlepaddle-gpu==2.6.2
pip install paddleocr==2.9.1
pip install python-Levenshtein
# HPSv2.1
pip install hpsv2x==1.2.0
# ImageReward
pip install image-reward
pip install git+https://github.com/openai/CLIP.git
```
## 🚀 使用方法
### 🔥 训练
默认的 SOAR v4 训练设置在单节点 8 GPU 上,使用高美学数据(`score >= 6.8`)运行。每 GPU 批次大小为 4,因此全局批次大小为 32。默认的推演配置是仅 ODE(`--num_rollout_paths 1`),包含 6 个辅助点和 40 个采样步骤。
```
export ACCELERATE_USE_DEEPSPEED=true
export ACCELERATE_DEEPSPEED_CONFIG_FILE=/path/to/ds_zero2_config.json
export ACCELERATE_DEEPSPEED_ZERO_STAGE=2
torchrun \
--nnodes=1 \
--node_rank=0 \
--nproc_per_node=8 \
--master_addr=localhost \
--master_port=29522 \
-m sora.train_soar_sd3_5m \
--pretrained_model_name_or_path /path/to/stable-diffusion-3.5-medium \
--jsonl_path /path/to/high_aesthetic.jsonl \
--image_dir /path/to/images \
--output_dir ./output/sd3.5m_soar_high_aesthetic \
--resolution 512 \
--train_batch_size 4 \
--gradient_accumulation_steps 1 \
--max_train_steps 5000 \
--checkpointing_steps 1000 \
--seed 42 \
--learning_rate 2e-5 \
--lr_scheduler constant \
--lr_warmup_steps 0 \
--adam_weight_decay 1e-2 \
--max_grad_norm 1.0 \
--weighting_scheme logit_normal \
--mixed_precision bf16 \
--dataloader_num_workers 16 \
--gradient_checkpointing \
--allow_tf32 \
--report_to tensorboard \
--num_rollout_paths 1 \
--trajectory_length 6 \
--num_sampling_steps 40 \
--sde_rollout_type flow_sde \
--sde_noise_scale 0.5 \
--lambda_aux 1.0 \
--cfg_scale_sampling 4.5
```
默认训练参数:
| 参数 | 默认值 | 描述 |
| --- | --- | --- |
| GPU 数量 | 8 | 单节点训练 |
| 全局批次大小 | 32 | `--train_batch_size 4` × 8 GPU × `--gradient_accumulation_steps 1` |
| `--max_train_steps` | 5000 | 总优化步数 |
| `--checkpointing_steps` | 1000 | 检查点保存间隔 |
| `--seed` | 42 | 训练随机种子 |
| `--learning_rate` | 2e-5 | AdamW 学习率 |
| `--lr_scheduler` | constant | 学习率调度策略 |
| `--lr_warmup_steps` | 0 | 预热步数 |
| `--adam_weight_decay` | 1e-2 | AdamW 权重衰减 |
| `--max_grad_norm` | 1.0 | 梯度裁剪范数 |
| `--weighting_scheme` | logit_normal | 时间步加权方案 |
| `--mixed_precision` | bf16 | 混合精度模式 |
| `--dataloader_num_workers` | 16 | 数据加载器工作线程数 |
| `--lambda_aux` | 1.0 | 辅助 SOAR 损失的权重 |
| `--num_rollout_paths` | 1 | 推演路径数量(1=仅 ODE) |
| `--trajectory_length` | 6 | 每条路径的辅助点数 |
| `--sde_rollout_type` | flow_sde | 随机推演模式:`cps`、`simple`、`sde`、`flow_sde` |
| `--sde_noise_scale` | 0.5 | 随机推演的噪声尺度 |
| `--cfg_scale_sampling` | 4.5 | 推演速度的 CFG 尺度 |
| `--num_sampling_steps` | 40 | 总采样步数(决定步长) |
### 📊 运行评估
使用分布式推理生成图像并保存结果:
```
torchrun --nproc_per_node=8 -m sora.evaluation \
--checkpoint_path ./output/soar_sd3_5m/checkpoint-5000 \
--model_type sd3 \
--dataset geneval \
--guidance_scale 4.5 \
--resolution 512 \
--mixed_precision bf16 \
--save_images \
--output_dir ./eval_output
```
`--dataset` 标志支持 `geneval`、`ocr`、`pickscore` 和 `drawbench`。
## 📊 评估
### 📋 在 DrawBench 上的主要结果
遵循 [Flow-GRPO](https://arxiv.org/abs/2505.05470) 的做法,我们在 **DrawBench** 提示上评估图像质量和人类偏好分数。特定任务指标(GenEval、OCR)在各自的测试集上评估。所有模型均在 512×512 分辨率、cfg=4.5 条件下进行训练。
| 模型 | #迭代 | GenEval | OCR | PickScore | ClipScore | HPSv2.1 | Aesthetic | ImgRwd |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| SD-XL (1024²) | – | 0.55 | 0.14 | 22.42 | 0.287 | 0.280 | 5.60 | 0.76 |
| SD3.5-L (1024²) | – | 0.71 | 0.68 | 22.91 | 0.289 | 0.288 | 5.50 | 0.96 |
| FLUX.1-Dev | – | 0.66 | 0.59 | 22.84 | 0.295 | 0.274 | 5.71 | 0.96 |
| SD3.5-M | – | 0.63 | 0.59 | 22.34 | 0.285 | 0.279 | 5.36 | 0.85 |
| + SFT | 10k | 0.70 | 0.64 | 22.71 | 0.295 | 0.284 | 5.35 | 1.04 |
| **+ SOAR (Ours)** | **10k** | **0.78** | **0.67** | **22.86** | **0.295** | **0.289** | **5.46** | **1.09** |
在 DrawBench 以及来自 [Flow-GRPO](https://arxiv.org/abs/2505.05470) 的对应 GenEval/OCR 测试集上,SOAR 将 SD3.5-Medium 的 GenEval 分数从 0.70 提高到 0.78(相对提升 11%),OCR 准确率从 0.64 提高到 0.67,且整个训练过程中未使用任何奖励模型。
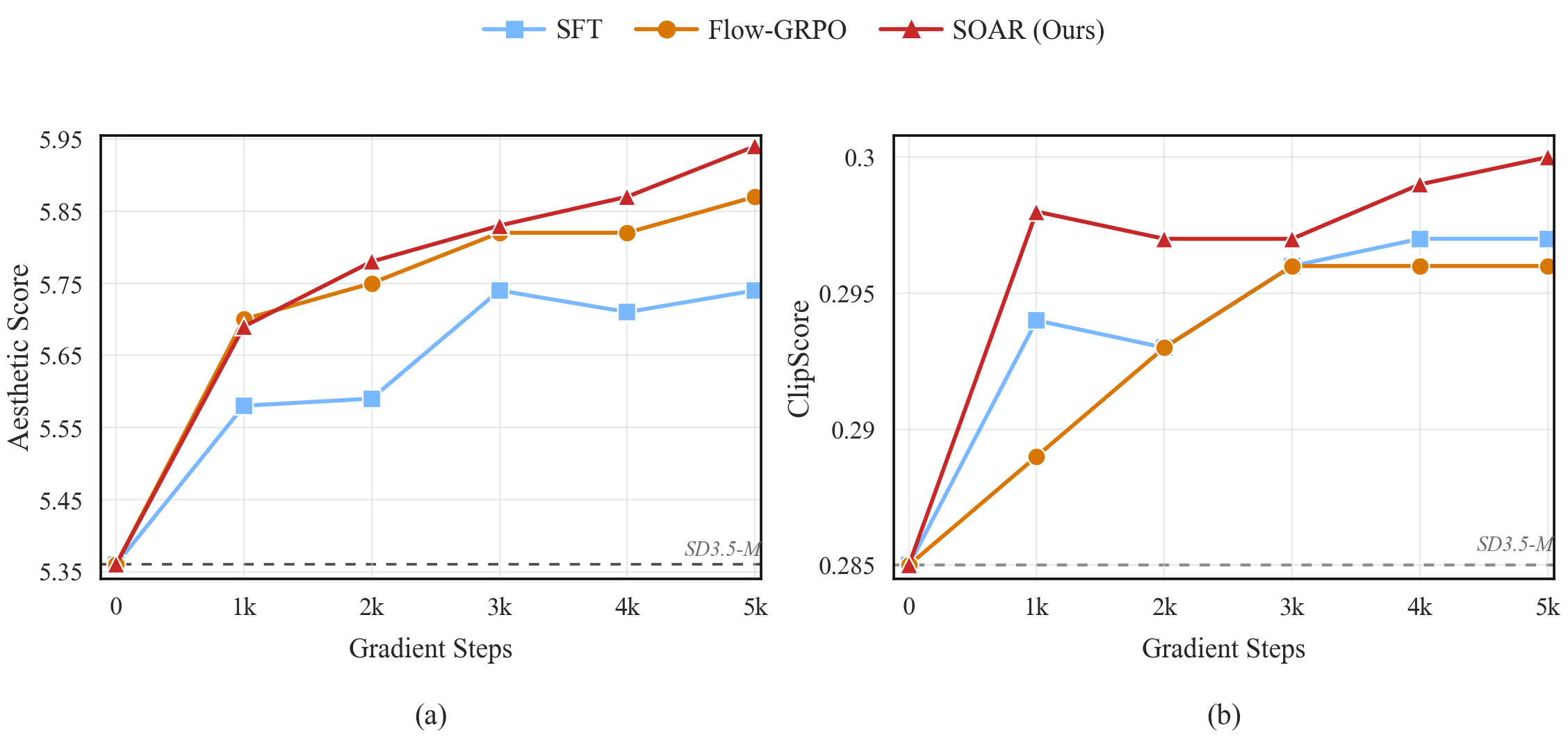
### 📈 特定奖励的训练动态
在 DrawBench 美学分数和 ClipScore 的直接比较中,SOAR 的最终分数不仅超越了 SFT,也优于显式使用这些指标作为奖励信号的 Flow-GRPO(美学分数:5.94 vs SFT 5.74 / Flow-GRPO 5.87;ClipScore:0.300 vs SFT 0.297 / Flow-GRPO 0.296)。
## 🧾 数据格式
训练脚本期望一个 JSONL 文件,其中每一行包含:
```
{"md5": "image_hash", "caption_en": "A photo of ...", "bw": 512, "bh": 512}
```
- `md5`:图像文件名(不含扩展名)。图像存储在 `--image_dir` 目录下,格式为 `{md5}.jpg`。
- `caption_en`:英文文本提示。
- `bw`, `bh`:存储桶的宽度和高度(图像将被调整大小/裁剪到此分辨率)。
## 📚 引用
如果您在研究中发现 HY-SOAR 有用,请引用我们的工作:
```
@article{hy-soar,
title={SOAR: Self-Correction for Optimal Alignment and Refinement in Diffusion Models},
author={Qin, You and Wang, Linqing and Fei, Hao and Zimmermann, Roger and Bo, Liefeng and Lu, Qinglin and Wang, Chunyu},
journal={arXiv preprint arXiv:2604.12617},
year={2026},
eprint={2604.12617},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
## 🙏 致谢
我们感谢 [DiffusionNFT](https://github.com/NVlabs/DiffusionNFT) 仓库、[Flow-GRPO](https://github.com/yifan123/flow_grpo) 项目以及 Hugging Face [diffusers](https://github.com/huggingface/diffusers) 提供的开源代码库。
标签:Apex, Classifier-Free Guidance, DNS解析, HY-SOAR, 人工智能, 优化对齐, 优化算法, 凭据扫描, 噪声处理, 噪声采样, 图像生成, 学术研究, 开源项目, 强化学习, 扩散模型, 扩散过程, 机器学习, 模型优化, 模型精炼, 深度学习, 生成模型, 用户模式Hook绕过, 腾讯混元, 自我纠正, 自纠正机制, 计算机视觉, 训练代码, 评估代码, 轨迹纠正