DaniAkash/codex-crisis-room
GitHub: DaniAkash/codex-crisis-room
一个在模拟生产环境中运行、由 AI 驱动的事件响应代理,演示从告警检测到修复验证的全流程自动化与人工协作。
Stars: 0 | Forks: 0
# 危机指挥官代理
**🚨 检测事件。🧠 运行根因分析。🛠️ 协调修复。✅ 仅在生产环境稳定后关闭。**
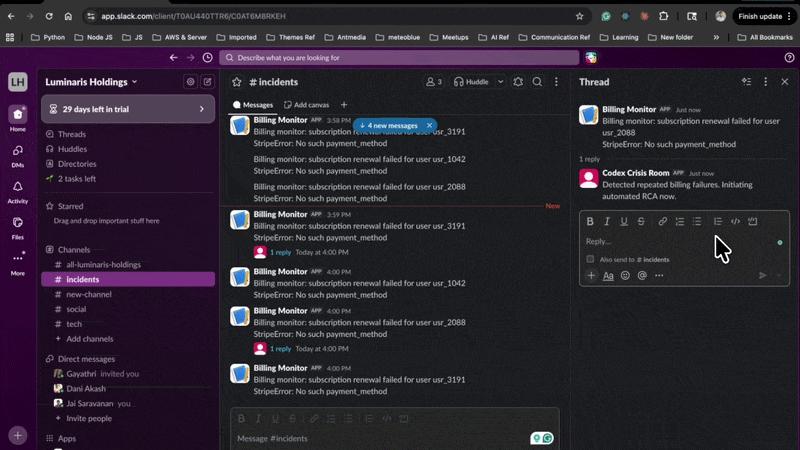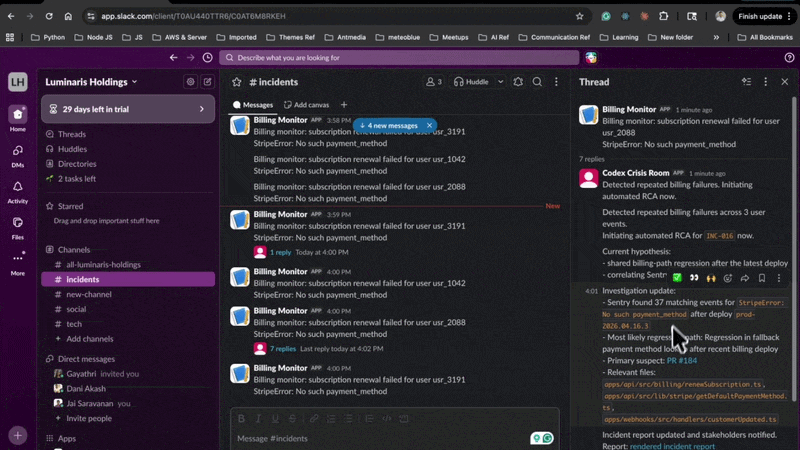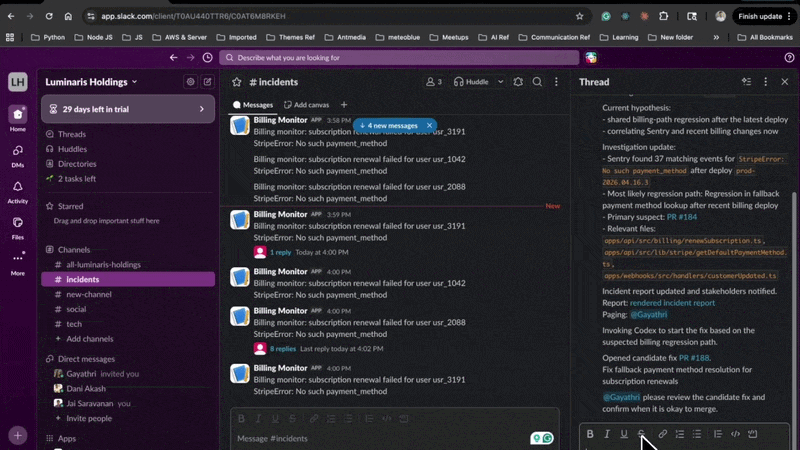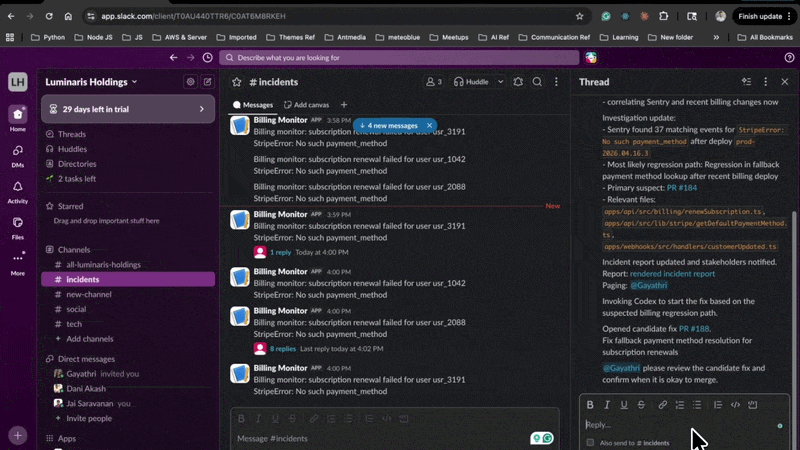
Crisis Commander Agent 被设计成像一位运营同事一样响应软件事件:它检测重复故障,自动启动根因分析(RCA),关联监控和仓库证据,更新事件报告,通知利益相关者,调用 Codex 启动修复路径,等待人工合并确认,并监控生产环境直到事件真正稳定。
`codex-crisis-room` 是一个展示该代理实际运作的黑客松环境。当前构建在模拟生产环境中运行指挥官,但命令循环本身是真实的,并设计用于接入真实的仓库、监控系统和事件工作流。
标签:agentic incident response, AI incident-response agent, AI 代理, AI 协作, Codex, codex-crisis-room, GitHub 集成, incident simulation, RCA 根因分析, Sentry 集成, SEO 关键词, Slack 集成, SRE, Stakeholder 通知, 事件仿真, 事件报告, 人类确认, 代码修复, 偏差过滤, 健康检查, 危机管理, 合并确认, 告警关联, 操作自动化, 模拟生产环境, 监控告警, 站点可靠性工程, 自动化响应, 自动化攻击, 自动化运维, 证据关联