harshvardhansingh3010/AllEars
GitHub: harshvardhansingh3010/AllEars
一个基于深度学习的多模态音频智能分析系统,实现语音转写、声事件检测与上下文解释。
Stars: 0 | Forks: 0
# 🎧 AllEars – AI 音频智能系统
一个使用现代深度学习模型进行**语音转录**、**声音事件检测**和**上下文感知解释**的 AI 音频分析系统。
## 🚀 功能
* 🎤 **语音转文字转录**
* 由 Whisper 提供支持,实现准确转录
* 🔊 **声音事件检测**
* 使用 YAMNet 识别环境声音
* 🧠 **上下文理解**
* 使用 Transformers + Ollama 进行智能解释
* 🌐 **网页界面**
* 使用 Flask 构建,便于交互
## 🛠️ 技术栈
* Python
* Flask
* OpenAI Whisper
* TensorFlow / YAMNet
* Transformers
* Ollama
## 📂 项目结构
```
AllEars/
│── app.py
│── templates/
│── static/
│── models/
│── utils/
│── requirements.txt
```
## ⚙️ 安装与设置
1. 克隆仓库:
```
git clone https://github.com/harshvardhansingh3010/AllEars.git
cd AllEars
```
2. 安装依赖:
```
pip install -r requirements.txt
```
3. 运行应用:
```
python app.py
```
4. 在浏览器中打开:
```
http://127.0.0.1:5000
```
## 📸 演示
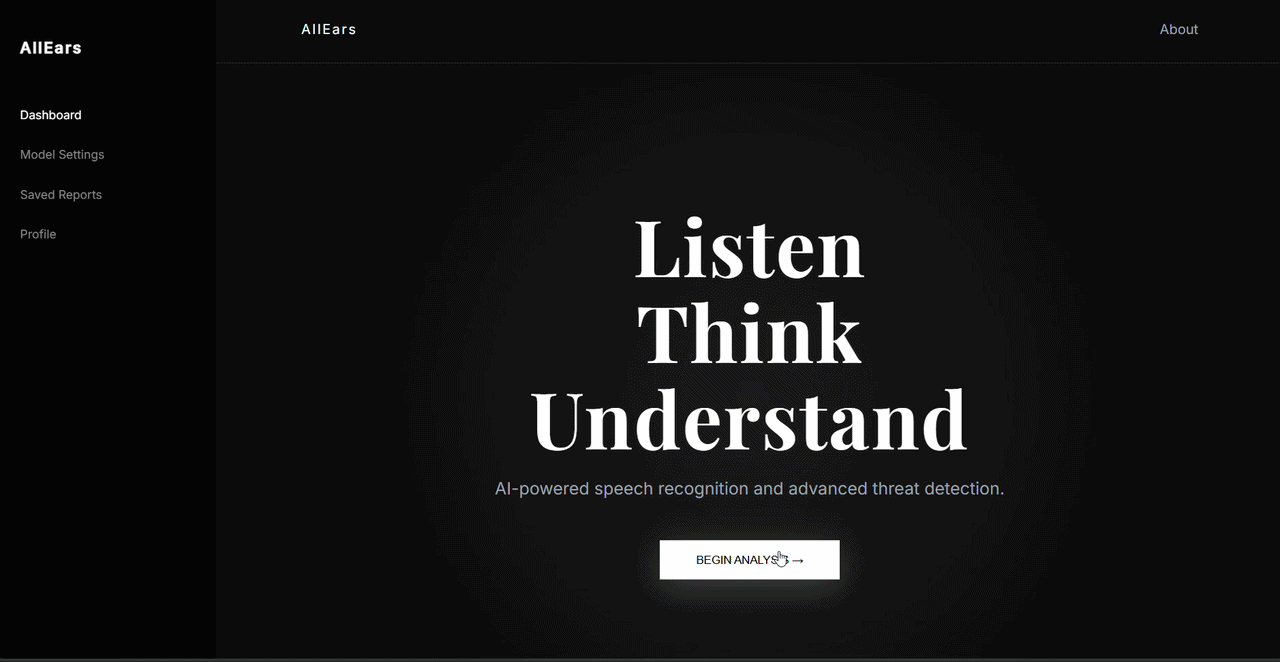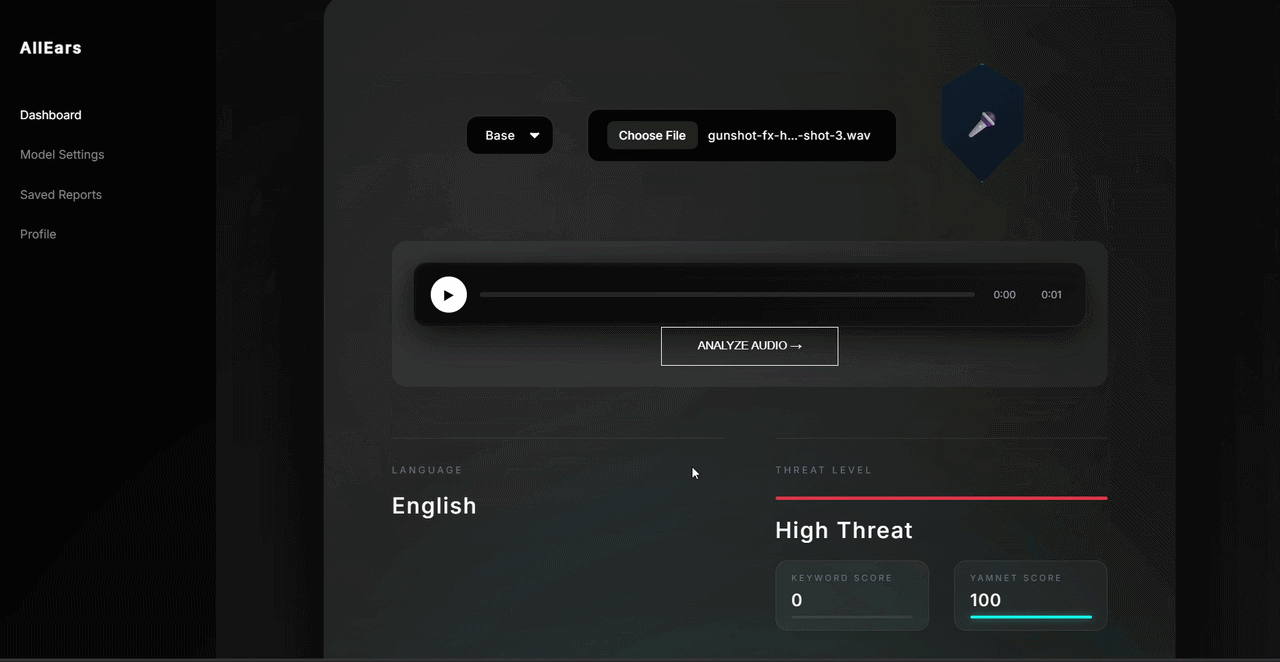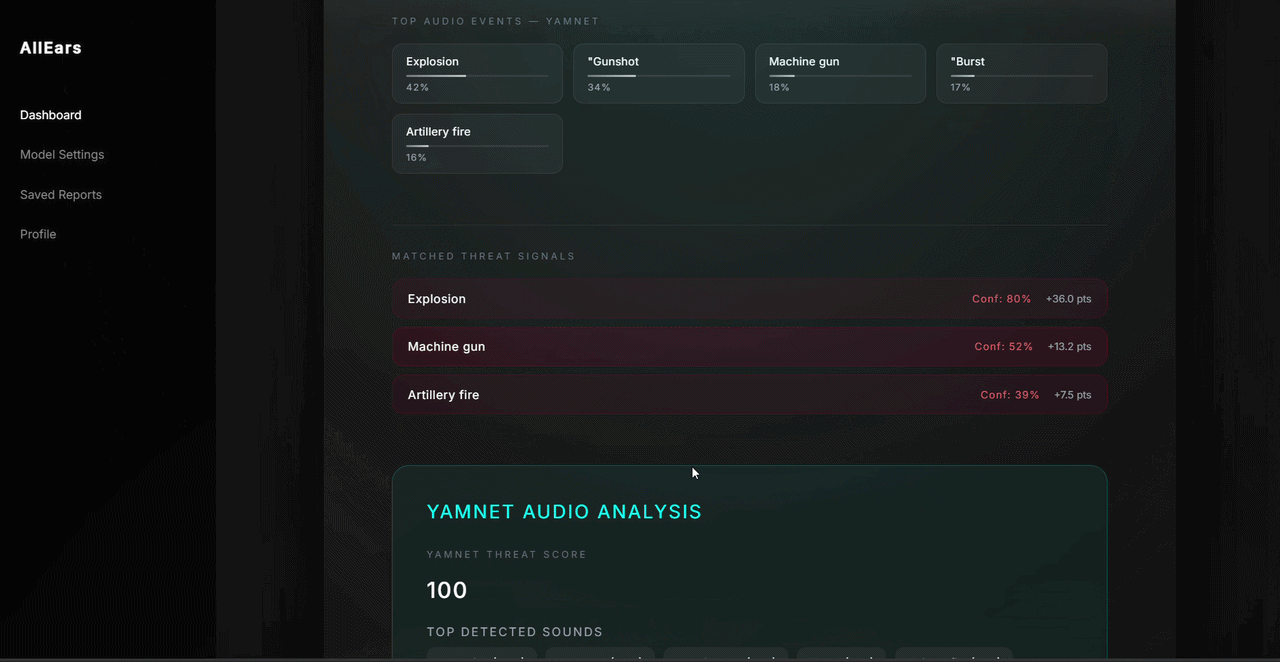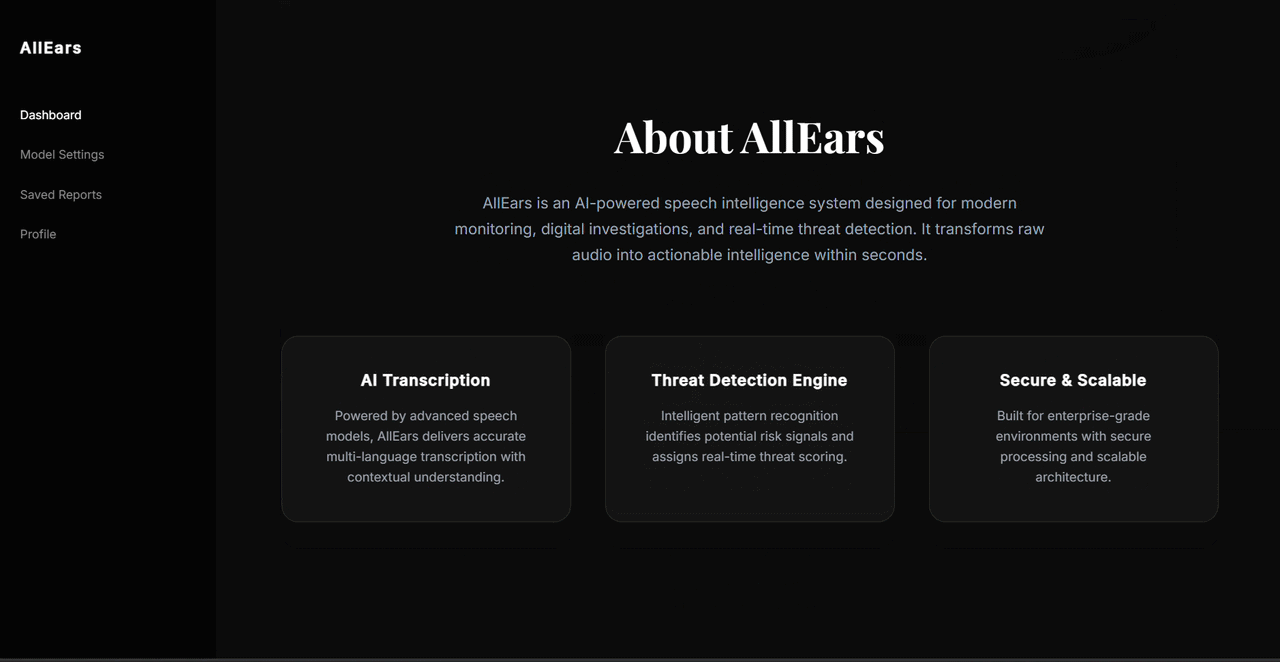 ## 💡 后续改进
* 实时音频流
* 移动应用集成
* 更佳的 UI/UX
* 多语言支持
## 👨💻 作者
Harsh Vardhan Singh
## ⭐ 支持我们
如果喜欢这个项目,请在 GitHub 上给它一个 ⭐!
## 💡 后续改进
* 实时音频流
* 移动应用集成
* 更佳的 UI/UX
* 多语言支持
## 👨💻 作者
Harsh Vardhan Singh
## ⭐ 支持我们
如果喜欢这个项目,请在 GitHub 上给它一个 ⭐!
## 💡 后续改进
* 实时音频流
* 移动应用集成
* 更佳的 UI/UX
* 多语言支持
## 👨💻 作者
Harsh Vardhan Singh
## ⭐ 支持我们
如果喜欢这个项目,请在 GitHub 上给它一个 ⭐!标签:AI音频, AI风险缓解, DNS解析, Flask, LLM评估, Ollama, Python, SEO, Web界面, Whisper, YAMNet, 上下文理解, 后端开发, 声音事件检测, 多语言支持, 威胁分析, 安全测试框架, 实时音频, 开源项目, 无后门, 深度学习, 环境声音识别, 移动应用, 系统调用监控, 自动化侦查工具, 语音识别, 语音转写, 逆向工具, 音频分析