GikomboC/machine-learning-for-financial-fraud-detection
GitHub: GikomboC/machine-learning-for-financial-fraud-detection
一个端到端的机器学习项目,旨在检测金融交易中的欺诈行为,降低财务损失并提升支付系统可信度。
Stars: 1 | Forks: 0
# 使用机器学习进行金融欺诈检测
## 概述
本项目构建了一个端到端的机器学习系统,用于检测欺诈性金融交易。
数据集包含以下交易级信息:
- 交易类型
- 交易金额
- 发送方和接收方余额
- 欺诈标签
它预测一笔交易是:
- 0 → 合法
- 1 → 欺诈
## 问题陈述
金融欺诈是数字支付和银行系统中的重大问题。
基于规则的经典系统难以检测现代欺诈模式。
机器学习能够在大规模交易数据中检测隐藏模式。 :contentReference[oaicite:0]{index=0}
## 商业影响
该系统可用于:
- 实时检测欺诈交易
- 减少财务损失
- 提高数字支付系统的信任度
在生产环境中,类似系统被用于:
- 银行业平台
- 支付网关
- 欺诈监控流水线
### 部署场景
在真实系统中:
1. 交易实时流入
2. 模型分配欺诈概率
3. 高风险交易被标记
4. 人工分析师审查标记案例
## 实时演示
[Streamlit 应用](https://machine-learning-for-financial-fraud-detection-f4sj6a3e4rasnpi.streamlit.app/)
## 仪表板预览
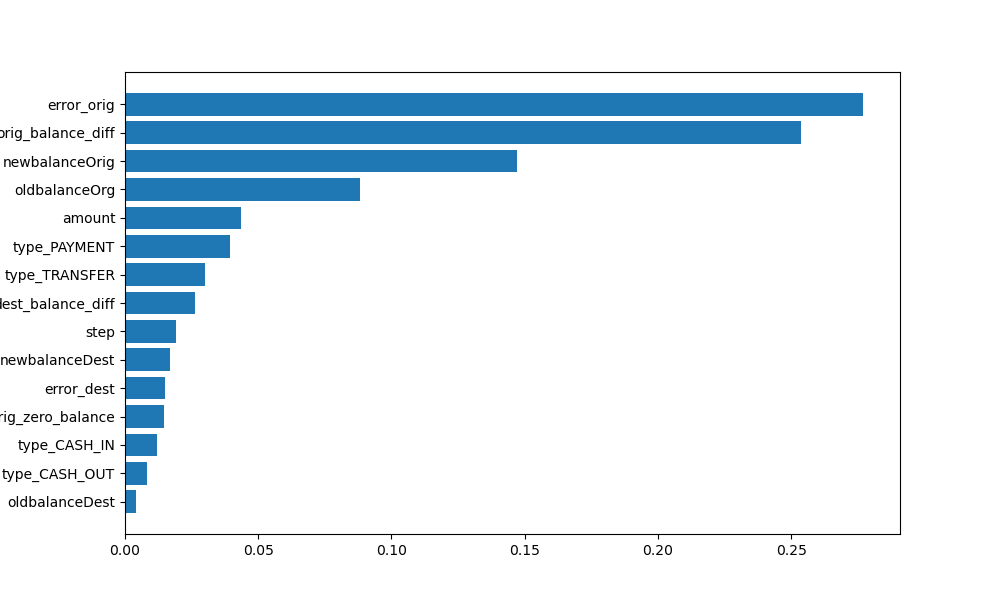
## 特征重要性
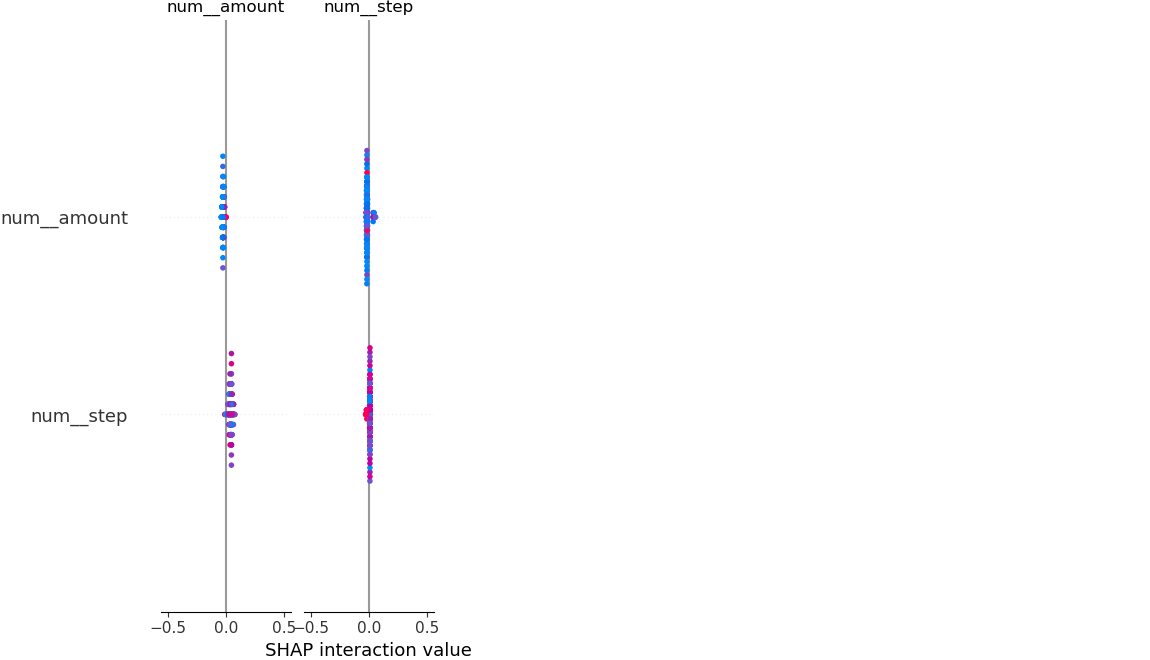
## 模型可解释性(SHAP)
## 概率分布
## 数据集
本项目使用的数据集在 Kaggle 上公开可得:
- [金融欺诈检测数据集(Kaggle)](https://www.kaggle.com/datasets/sriharshaeedala/financial-fraud-detection-dataset)
### 描述
该数据集是使用 PaySim 模拟器生成的合成金融数据集。它模拟了真实的移动货币交易,并包含合法和欺诈行为。
### 关键特征
- 744 个时间步(30 天的交易)
- 多种交易类型(CASH-IN、CASH-OUT、TRANSFER 等)
- 高度不平衡(欺诈案例罕见)
- 专为欺诈检测建模设计
| 特征 | 描述 |
|--------|------------|
| step | 时间步(1 步 = 1 小时) |
| type | 交易类型(CASH-IN、CASH-OUT、TRANSFER 等) |
| amount | 交易金额 |
| nameOrig | 发送方 ID |
| oldbalanceOrg | 交易前发送方余额 |
| newbalanceOrig | 交易后发送方余额 |
| nameDest | 接收方 ID |
| oldbalanceDest | 交易前接收方余额 |
| newbalanceDest | 交易后接收方余额 |
| isFraud | 目标变量(0 = 合法,1 = 欺诈) |
| isFlaggedFraud | 大额非法交易标记 |
## 项目流程
### 1. 数据处理
- 加载并清理数据集
- 删除重复项
- 检查缺失值
### 2. 探索性数据分析
- 欺诈分布
- 按交易类型划分的欺诈
- 可疑模式
### 3. 特征工程
创建关键特征:
- `orig_balance_diff`
- `dest_balance_diff`
- `orig_zero_balance`
- `dest_zero_balance`
- `error_orig`
- `error_dest`
这些特征捕捉交易中的不一致性,是欺诈的强指示器。
### 4. 预处理
- 数值缩放(StandardScaler)
- 类别编码(OneHotEncoder)
### 5. 建模
使用的模型:
- 逻辑回归(基线)
- 随机森林(最终模型)
### 6. 模型评估
使用的指标:
- 精确率
- 召回率
- F1 分数
- ROC-AUC
- PR-AUC
欺诈检测更注重 **召回率和精确率**,而非准确率。
## 模型决策策略
欺诈检测需要在以下方面取得平衡:
- **高召回率** → 捕获更多欺诈(减少漏报)
- **高精确率** → 减少误报
本项目支持 **阈值调节**:
```
threshold = 0.3 # Higher recall
threshold = 0.7 # Higher precision
```
这反映了现实世界中基于成本的欺诈检测系统。
## 结果
| 模型 | ROC-AUC | PR-AUC | 精确率 | 召回率 | F1 分数 |
|------|--------|--------|----------|-----------|----------|
| 逻辑回归 | 0.995182 | 0.631581 | 0.024494 | 0.978089 | 0.047790 |
| 随机森林 | 0.999086 | 0.998138 | 1.000000 | 0.997565 | 0.998781 |
## 关键洞察
- 欺诈集中在特定交易类型(TRANSFER、CASH-OUT)
- 余额不一致是欺诈的强指示器
- 构造的特征显著提升模型性能
- 随机森林优于逻辑回归
## 可解释性(SHAP)
为了提高透明度,使用 SHAP 来解释模型预测。
这有助于:
- 理解交易为何被标记
- 识别欺诈的关键驱动因素
- 提高对模型的信任
- 可解释性在现实世界的欺诈系统中至关重要。
## 项目结构
```
fraud-detection/
├── app/
│ └── dashboard.py
├── outputs/
│ └── fraud_predictions.csv
├── README.md
├── model.pkl
└── requirements.txt
```
## Streamlit 仪表板功能
- 上传交易数据
- 实时欺诈预测
- 欺诈概率评分
- 汇总指标(欺诈率、数量)
- 交互式图表
- 下载预测结果
- SHAP 可解释性
## 后续改进
- XGBoost / LightGBM 模型
- 用于不平衡处理的 SMOTE
- 超参数调节
- 实时 API 部署
## 使用技术
- Python
- Pandas
- NumPy
- Scikit-learn
- Matplotlib
- Streamlit
- SHAP
## 作者
- Caleb Gikombo - 机电工程师 | 数据科学家
# 许可证
本项目是开源的,采用 MIT 许可证。
标签:Apex, Kaggle, Kubernetes, PaySim, SHAP, Streamlit, 业务影响, 交易欺诈, 分类模型, 实时检测, 异常检测, 探索性数据分析, 支付系统, 数据清洗, 数据预处理, 机器学习, 概率预测, 模型训练, 模型评估, 特征工程, 特征重要性, 生产部署, 监督学习, 结构化数据, 访问控制, 逆向工具, 金融欺诈检测, 金融科技, 银行平台, 风控