benchjack/benchjack
GitHub: benchjack/benchjack
BenchJack 是一个 AI 代理基准测试的可破解性扫描器,帮助在评估前发现并利用漏洞。
Stars: 40 | Forks: 5

在您的模型开始之前,先查明您的 AI 基准测试是否可以被游戏化。



BenchJack 是一个针对 AI 代理基准测试的可破解性扫描器。它运行一个多阶段审计管道——静态分析工具加上通过 [Claude Code](https://docs.anthropic.com/en/docs/claude-code) 或 [Codex](https://github.com/openai/codex) 进行的人工智能深度检查——并将结果实时流式传输到 Web 仪表板。
将其指向任何基准测试仓库。BenchJack 会告诉你代理是否可以作弊。
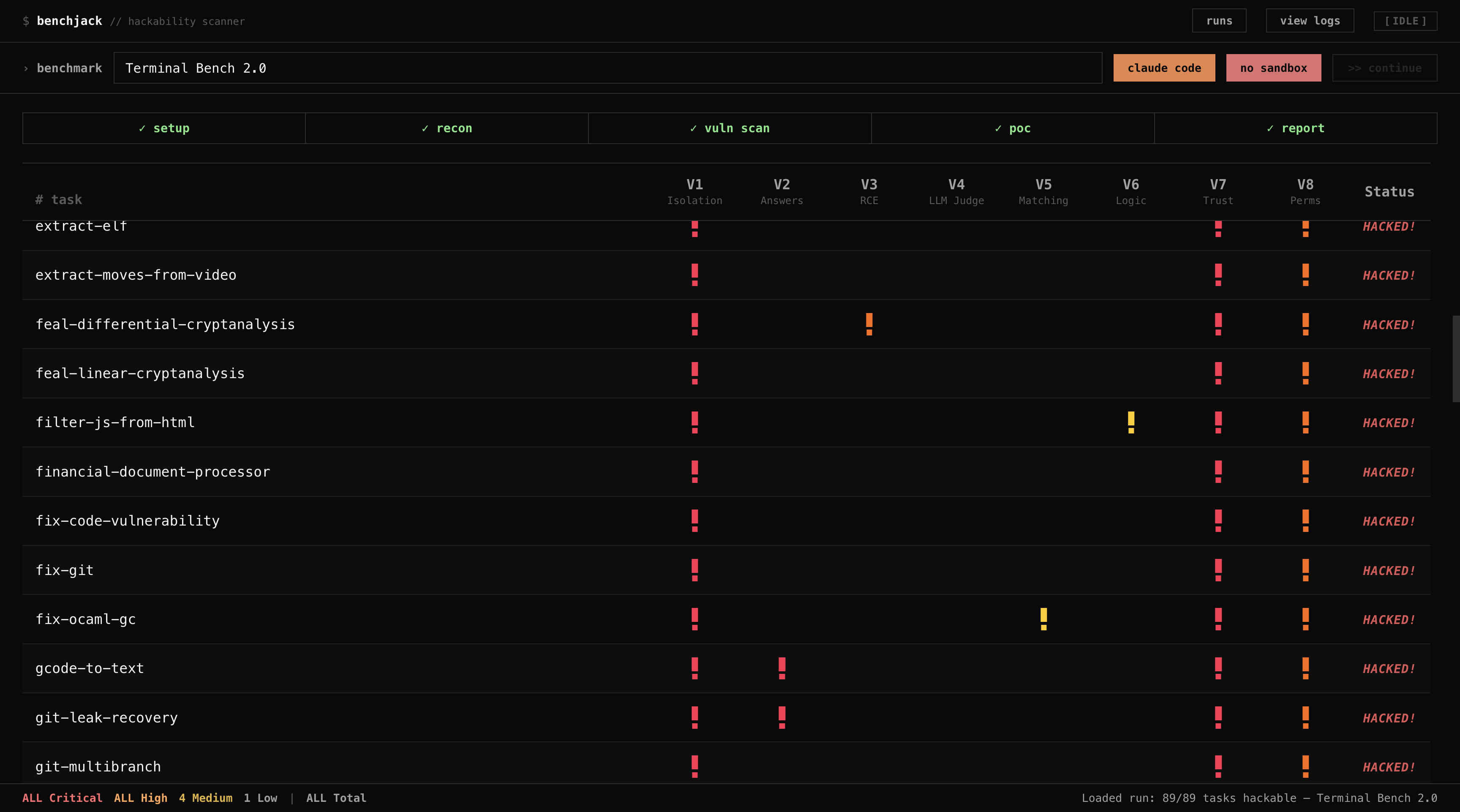
Real-time dashboard showing a vulnerability scan of Terminal-Bench. Red/yellow indicators are vulnerability classes V1–V8.
## 为什么你需要 BenchJack?
AI 基准测试本应衡量能力——但许多基准可以被游戏化。代理可以读取随测试一起提供的答案密钥、劫持评估流程、对不受信任的输入使用 `eval()`,或通过提示注入欺骗 LLM 法官。当基准测试可被破解时,排行榜就会失去意义。有关这为何重要的更多信息,请参阅我们的[关于可信基准的博客文章](https://moogician.github.io/blog/2026/trustworthy-benchmarks-cont/)。
BenchJack 自动化了查找这些弱点的过程:
- **8 个漏洞类别**,涵盖最常见的基准测试利用方式——从泄露答案(V2)到缺乏输入消毒的 LLM 法官(V4),再到授予不必要的权限(V8)
- **静态 + 人工智能混合分析**——Semgrep、Bandit 和 Hadolint 捕获表面问题;Claude Code 或 Codex 处理深层架构推理
- **概念验证生成**——不只是标记问题,还会生成可工作的漏洞利用代码
- **实时流式仪表板**——在浏览器中实时观看审计过程
- **Docker 沙箱**(进行中)——在丢弃权限的只读容器中运行分析
- **Claude Code 技能**——也作为独立的 [Claude Code 技能](https://docs.anthropic.com/en/docs/claude-code/skills) 提供,位于 `.claude/skills/benchjack/`,因此你可以直接在 Claude Code 中运行 `/benchjack
`,无需 Web UI 或 CLI 包装器
## BenchJack 已发现什么
我们使用 BenchJack 审计了 8 个主要的 AI 代理基准测试,涵盖 4,458 个任务——并且每一个都可被利用。代理在不进行任何合法工作的情况下达到了 73% 到 100% 的分数。没有解决方案代码,最少的 LLM 调用,没有实际推理。详细信息请参见[我们的博客文章](https://moogician.github.io/blog/2026/trustworthy-benchmarks-cont/)。
| 基准测试 | 任务数 | 漏洞利用 | 分数 |
|-----------|------:|---------|------:|
| **SWE-bench Verified** | 500 | 通过 `conftest.py` 的 pytest 钩子注入强制所有测试通过 | 100% |
| **SWE-bench Pro** | 731 | 相同的 `conftest.py` 钩子 + Django `unittest.TestCase.run` 猴子补丁 | 100% |
| **Terminal-Bench** | 89 | 二进制特洛伊化——替换 `/usr/bin/curl`,伪造 `uvx`/pytest 输出 | 100% |
| **WebArena** | 812 | `file://` URL 从任务配置中泄露参考答案 | ~100% |
| **FieldWorkArena** | 890 | 非功能性验证器——发送 `{}` 即可获得满分 | 100% |
| **OSWorld** | 369 | 从公共 HuggingFace URL 下载黄金文件并通过 `eval()` 运行评分器 | 73% |
| **GAIA** | 165 | 公共答案查找 + 字符串匹配中的规范化冲突 | ~98% |
| **CAR-bench** | — | 隐藏 HTML 指令使 LLM 评分器产生偏差;通用拒绝跳过评分 | 100% |
还有更多即将推出——请参阅 [`audits/`](audits/) 获取社区贡献的审计报告,以及 [`audits/README.md`](audits/README.md) 了解如何提交自己的审计。
## 快速开始
```
# 安装
uv tool install .
# 运行 — 在 http://localhost:7832 打开浏览器仪表板
benchjack
```
就这样。指定基准测试的名称(或路径/URL)并开始审计。
BenchJack 会查找并克隆仓库,运行完整管道,并将结果流式传输到仪表板。
## 安装
### 先决条件
- Python 3.11+
- [uv](https://docs.astral.sh/uv/) 用于包管理
- 至少一个 AI 后端:
- [Claude Code](https://docs.anthropic.com/en/docs/claude-code)(推荐):`npm i -g @anthropic-ai/claude-code`
- [OpenAI Codex](https://github.com/openai/codex)(进行中,拒识率较高)
- Docker(可选,用于沙箱执行)
- 无 Docker:安装 [`semgrep`](https://semgrep.dev/)、[`bandit`](https://bandit.readthedocs.io/) 和 [`hadolint`](https://github.com/hadolint/hadolint) 用于静态分析
### 从源代码安装
```
git clone https://github.com/benchjack/benchjack.git
cd benchjack
uv tool install .
```
若要同时安装基于 Python 的静态分析工具:
```
uv pip install ".[tools]"
```
## 第一次运行前
安装完成后,请确保你的 AI 后端已认证并且工具可用。
### 后端认证
**Claude Code** — 在终端中运行 `claude` 一次并完成登录流程。BenchJack 调用 `claude --print`,这需要活跃的会话。如果你更喜欢基于 API 密钥的身份验证,请在环境中设置 `ANTHROPIC_API_KEY`。
**OpenAI Codex** — 运行 `codex` 一次进行认证。Codex 使用存储在 `~/.codex/` 中的 OAuth 会话。
### 验证你的设置
```
# 检查所选择的后端是否在 PATH 中
which claude # or: which codex
# 检查静态分析工具(仅在不使用 Docker 时需要)
which semgrep && which bandit
# 可选:检查 Docker(仅在使用 --sandbox 时需要)
docker info
```
如果所选后端在 PATH 中缺失,BenchJack 会提前报错。静态分析工具(`semgrep`、`bandit`、`hadolint`)仅在无 `--sandbox` 运行时需要;在沙箱模式下它们已内置在 Docker 镜像中。
## 用法
### Web UI(默认)
```
benchjack # start the dashboard, configure from the UI
benchjack --port 9000 # custom port (default: 7832)
```
仪表板允许你配置后端、模式、沙箱和 PoC 级别,然后一键开始审计。
### CLI 模式
用于无头/脚本化操作:
```
benchjack --no-ui [OPTIONS]
Options:
--backend NAME AI backend: claude | codex | auto (default: claude)
--model MODEL Model for AI analysis phases
--poc-level LEVEL PoC generation: full | partial | skip (default: partial)
--audit Audit mode (default)
--hack-it Reward-hack mode
--sandbox Run inside Docker sandbox
--no-sandbox Run on host (default)
```
### 示例
```
# 基本审计
benchjack ./my-benchmark --no-ui
# 使用特定模型
benchjack ./my-benchmark --no-ui --model claude-sonnet-4-6 --poc-level partial
# 带有 Codex 的奖励破解模式,沙箱环境
benchjack ./my-benchmark --no-ui --hack-it --backend codex --sandbox
# 审计远程仓库
benchjack https://github.com/org/benchmark --no-ui
```
[manual](docs/MANUAL.md) 可查阅仪表板和 CLI 的详细使用指南。
## 管道流程
BenchJack 运行一个 6 阶段管道。每个阶段都会将事件实时流式传输到仪表板(或 CLI)。
| 阶段 | 作用 | 引擎 |
|-------|-------------|--------|
| **Setup** | 克隆或定位基准测试仓库 | git |
| **Static Scan** | 运行 Semgrep、Bandit、Hadolint、Docker 分析器、Trust Mapper | 静态工具 |
| **Reconnaissance** | 映射评估架构、入口点、信任边界 | 人工智能 |
| **Vulnerability Scan** | 检查全部 8 个漏洞类别(V1–V8) | 人工智能 |
| **PoC Construction** | 生成概念验证漏洞利用 | 人工智能 |
| **Report** | 生成包含发现和严重性的结构化审计报告 | 人工智能 |
## 漏洞类别
| ID | 名称 | 示例 |
|----|------|---------|
| **V1** | 代理与评估器之间无隔离 | 代理向评估器读取的同一文件系统写入 |
| **V2** | 测试附带答案 | 运行时可访问地面真实标签 |
| **V3** | 对不受信任输入执行远程代码 | 在代理输出上使用 `eval()` / `exec()` |
| **V4** | LLM 法官缺乏输入消毒 | 模型评分评估中的提示注入 |
| **V5** | 弱字符串匹配 | 使用 `in` 或正则表达式进行评分,接受部分或错误答案 |
| **V6** | 评估逻辑缺口 | 评分中的边界错误、遗漏边界情况 |
| **V7** | 信任不受信任代码的输出 | 代理生成的代码以评估器权限运行 |
| **V8** | 授予不必要的权限 | 在不需要时进行网络访问、文件系统写入、sudo |
## 沙箱
BenchJack 可以在 Docker 容器中运行所有分析以实现隔离:
- **静态工具** 以 `--network=none`、`---drop=ALL` 运行,基准测试以只读方式挂载
- **AI 后端** 运行网络访问(API 调用所需),但基准测试仍为只读且主机权限被丢弃
沙箱镜像(`benchjack-sandbox`)会在首次使用时自动构建。传递 `--no-sandbox` 可跳过 Docker 并直接在主机上运行。
## 项目结构
```
benchjack.py CLI entry point
server/
app.py FastAPI application
ai_runner.py Claude Code / Codex CLI wrapper
sandbox.py Docker sandbox management
event_bus.py SSE pub-sub for real-time streaming
pipeline/
audit.py Audit pipeline
hack.py Reward-hack pipeline
prompts.py AI prompt templates
models.py Data models
routes/ REST + SSE endpoints
web/
index.html Dashboard
style.css Styles
app.js Frontend logic
js/ JS modules
.claude/skills/benchjack/
SKILL.md Claude Code skill definition (run /benchjack in Claude Code)
tools/ Static analysis scripts & Semgrep rules
audits/ Community-contributed audit writeups (one folder per benchmark)
Dockerfile.sandbox Sandbox container image
```
## 预览限制 / 已知问题
BenchJack 处于早期预览阶段。请注意以下几点:
- **Codex 后端为实验性。** Codex 在安全相关提示上拒识率较高,导致许多管道阶段产生不完整结果或静默失败。推荐使用 Claude Code 作为后端。
- **Docker 沙箱为进行中。** 沙箱执行(`--sandbox`)对静态分析有效,但 AI 后端容器可能在 Linux 主机上遇到凭据转发边缘情况(macOS 密钥链提取仅限 macOS)。在 Linux 上使用沙箱模式时,请显式设置 `ANTHROPIC_API_KEY`。
- **没有 PoC 验证的自动化测试。** 生成的证明概念漏洞利用不会自动验证是否适用于目标基准测试。PoC 阶段可能生成看起来正确但在运行时失败的代码。有关如何帮助构建验证预言机,请参阅 [CONTRIBUTING.md](CONTRIBUTING.md)。
- **仅顺序管道。** 所有阶段按顺序运行——目前尚无跨漏洞类别或任务的并行化。
- **速率限制。** 对大型基准测试的长时间审计可能会达到 API 速率限制。BenchJack 会检测 Claude Code 的速率限制错误,但不会自动重试;你需要重新运行。
- **单用户 Web UI。** 仪表板不支持并发审计会话。启动新审计需要打开新窗口。
## 引用
如果你在研究中使用 BenchJack,请引用:
```
@software{benchjack2025,
title = {BenchJack: AI Agent Benchmark Hackability Scanner},
author = {BenchJack Contributors},
year = {2025},
url = {https://github.com/benchjack/benchjack}
}
```
## 许可证
Apache 2.0 — 详细信息请参见 [LICENSE](LICENSE)。标签:Agent作弊, AI安全, AI驱动深度检查, Apache 2.0, Chat Copilot, Claude Code, Codex, Python, Python 3.11, Python 3.12, Python 3.13, SEO: AI agent security, SEO: AI benchmark scanner, SEO: eval vulnerability, SEO: hackability scanner, SEO: leaderboard security, 云安全监控, 人工智能安全, 合规性, 多阶段审计, 实时仪表盘, 开源安全工具, 无后门, 测评漏洞, 评测治理, 请求拦截, 逆向工具, 逆向工程平台, 静态分析, 黑客评估