weareaisle/nano-analyzer
GitHub: weareaisle/nano-analyzer
一个利用 LLM 对源代码进行三阶段扫描的零日漏洞研究工具,聚焦 C/C++ 为主的内存安全缺陷。
Stars: 296 | Forks: 57
# Nano-analyzer
**一个由 [AISLE](https://aisle.com) 提供的最小化 LLM 零日漏洞扫描器。**
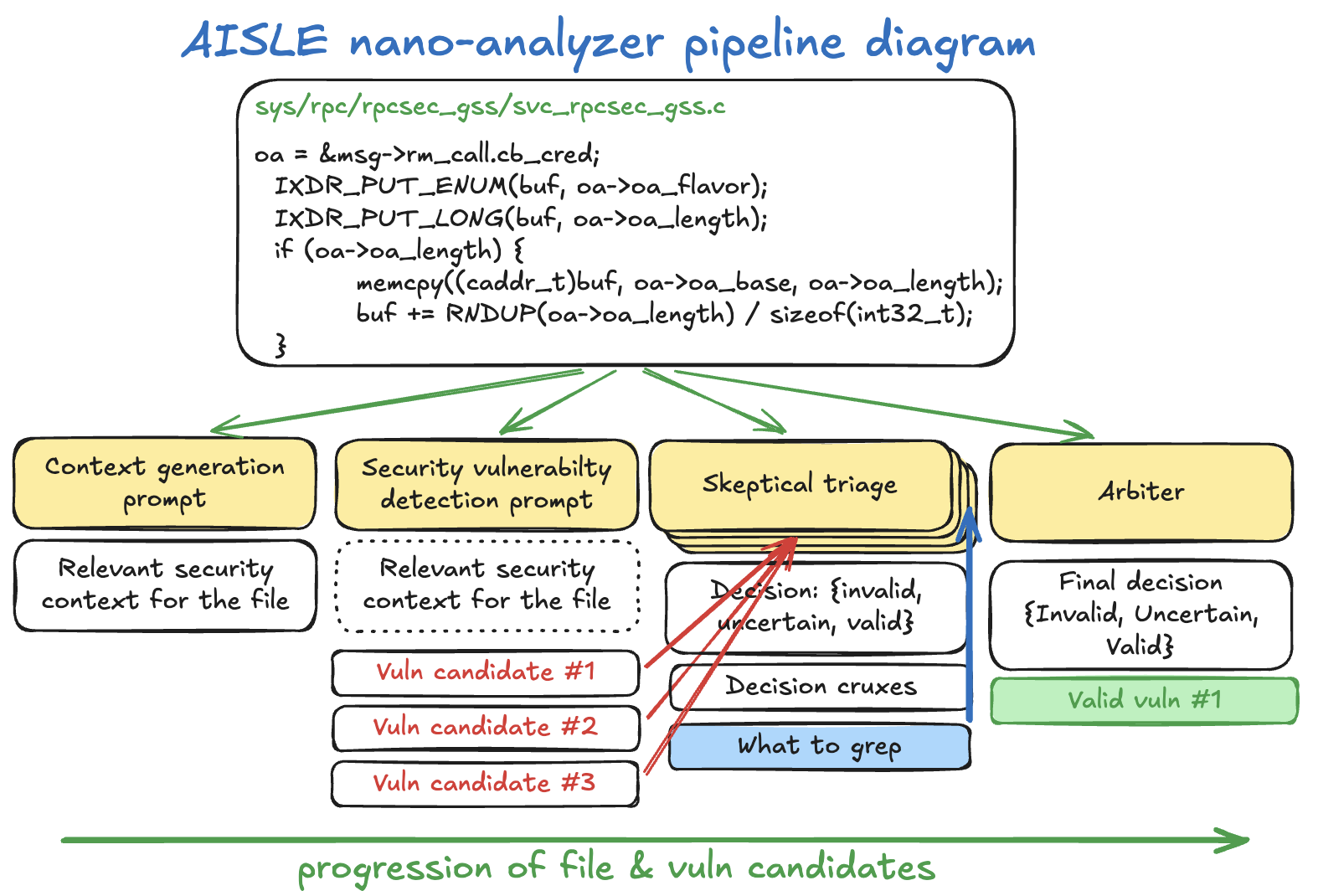
## 功能
Nano-analyzer 是一个简单的单文件 Python 扫描器,它将源代码通过三阶段 LLM 流水线:
1. **上下文生成** — 模型编写关于文件的安全简报:它的功能、不可信数据的流动位置、存在的缓冲区及其大小。
2. **漏洞扫描** — 使用已提供上下文的同一模型,逐函数查找零日漏洞并输出结构化发现。
3. **怀疑式分类** — 每个发现都会经过多轮质疑,由一个怀疑的审查者 grep 代码库来验证(或反驳)防御措施。仲裁者做出最终判定。
结果会保存为 Markdown 和 JSON 文件供人工审查。
## 当前限制
这是一个 v0.1 原型版本,请注意以下几点:
- **C/C++ 偏向。** 提示词、少样本示例和启发式方法主要针对 C/C++ 内存安全漏洞(缓冲区溢出、空指针解引用、整数溢出、类型混淆)。它可以扫描其他语言,但效果差很多。
- **误报。** 即使经过多轮分类,仍可能出现经不起仔细检查的发现。请务必手动验证。
- **漏报。** 扫描器可能遗漏整个漏洞类别:逻辑漏洞、竞态条件、加密问题、认证绕过等。干净的扫描结果并不意味着代码安全。
- **单文件分析。** 每个文件独立扫描。跨文件的漏洞,特别是依赖编译单元间交互的,很可能被遗漏。
- **依赖 LLM。** 结果随使用的模型不同而变化,不同的模型会发现不同的问题并产生不同的误报。
## 安装
### 需求
- Python 3.8+
- OpenAI API 密钥(用于 OpenAI 模型)或 OpenRouter API 密钥(用于其他提供商)
- 可选:[ripgrep](https://github.com/BurntSushi/ripgrep) (`rg`) 用于分类阶段的 grep 查询
- 可选:[Google codesearch](https://github.com/google/codesearch) (`csearch`/`cindex`) 用于在大型仓库中加速 grep
### 安装
```
git clone https://github.com/weareaisle/nano-analyzer.git
cd nano-analyzer
# 无需安装依赖,直接运行:
python3 scan.py --help
```
### API 密钥
将 API 密钥设置为环境变量:
```
# 对于 OpenAI 模型(不带斜杠的模型名称,例如 "gpt-5.4-nano"):
export OPENAI_API_KEY=sk-...
# 对于 OpenRouter 模型(带斜杠的模型名称,例如 "qwen/qwen3-32b"):
export OPENROUTER_API_KEY=sk-or-...
```
扫描器会根据模型名称决定使用哪个密钥:如果名称中包含 `/`,则通过 OpenRouter 路由;否则直接使用 OpenAI API。
## 使用
### 基本扫描
```
# 扫描单个文件
python3 scan.py ./path/to/file.c
# 递归扫描目录
python3 scan.py ./path/to/src/
```
### 常用选项
```
# 使用其他模型
python3 scan.py ./src --model gpt-5.4
# 控制并行度
python3 scan.py ./src --parallel 30
# 将 triage grep 指向完整的仓库根目录(在扫描子目录时很有用)
python3 scan.py ./lib/crypto/ --repo-dir ./
# 仅显示高置信度结果
python3 scan.py ./src --min-confidence 0.7
# 更高准确度的更多 triage 轮次(默认值:5)
python3 scan.py ./src --triage-rounds 7
```
### 所有标志
| 标志 | 默认值 | 描述 |
|------|---------|------|
| `path` | *(必需)* | 要扫描的文件或目录 |
| `--model` | `gpt-5.4-nano` | 所有阶段(上下文、扫描、分类)使用的模型 |
| `--parallel` | `50` | 最大并发扫描 API 调用数 |
| `--triage-threshold` | `medium` | 达到或超过此严重性的发现将进入分类 |
| `--triage-rounds` | `5` | 每个发现的分类轮数 |
| `--triage-parallel` | `50` | 最大并发分类 API 调用数 |
| `--max-connections` | `parallel + triage-parallel` | 总 API 调用上限 |
| `--min-confidence` | `0.0` | 仅显示置信度高于此值(0.0–1.0)的发现 |
| `--project` | 目录名 | 分类提示中使用的项目名称 |
| `--repo-dir` | auto | grep 查询的仓库根目录(auto:文件对应父目录,文件夹对应扫描目录) |
| `--output-dir` | `~/nano-analyzer-results//` | 结果保存位置 |
| `--max-chars` | `200,000` | 跳过大于此大小的文件 |
| `--verbose-triage` | off | 显示每轮分类进度 |
## 输出
结果保存到 `~/nano-analyzer-results//`(或 `--output-dir`):
```
/
├── summary.json # machine-readable scan summary
├── summary.md # human-readable scan summary
├── .md # raw scanner output per file
├── .context.md # context briefing per file
├── .json # full result data per file
├── triages/ # detailed triage reasoning
│ └── T0001__.md
├── findings/ # findings that survived triage
│ └── VULN-001_<file>.md
├── triage.json # all triage verdicts
└── triage_survivors.md # summary of validated findings
```
## 分类如何工作
当扫描发现中或以上严重性的问题时,分类流水线会启动:
1. 一个怀疑的审查者对照实际代码检查发现,并可以 **grep 代码库** 来验证或反驳声称的防御措施。
2. 这会重复多轮(默认:5 轮),每轮审查者都能看到之前的论证,并被鼓励寻找 *新的* 证据而非重复旧观点。
3. 一个最终的 **仲裁者** 阅读所有轮次并做出 VALID/INVALID 判定。
4. 置信度分数(例如 80% \[VVIVV→V\])反映判定为 VALID 的轮次比例。
通过分类的发现会连同完整的推理链一起写入 `findings/` 目录。
## 免责声明
该工具是一个研究原型。它不能替代专业的安全审计、人工代码审查或成熟的静态分析工具。不要将其作为唯一的安全评估手段。请自行承担风险使用。
## 许可证
Apache License 2.0</div><div><strong>标签:</strong>AI安全扫描, AI驱动安全, API安全, API密钥, C/C++安全审计, JSON输出, LLM安全分析, Markdown报告, OpenAI, OpenRouter, Petitpotam, Python安全工具, ripgrep, 三阶段流水线, 上下文生成, 内存安全漏洞, 内存规避, 单文件扫描, 多轮验证, 多阶段提示, 安全原型, 安全测试, 安全研发, 开源安全工具, 怀疑论审查, 攻击性安全, 整数溢出, 空指针解引用, 类型混淆, 缓冲区溢出, 网络情报, 逆向工具, 逆向工程平台, 错误基检测, 零日漏洞扫描, 静态代码分析</div></article></div>
<!-- 人机验证 -->
<script>
(function () {
var base = (document.querySelector('base') && document.querySelector('base').getAttribute('href')) || '';
var path = base.replace(/\/?$/, '') + '/cap-wasm/cap_wasm.min.js';
window.CAP_CUSTOM_WASM_URL = new URL(path, window.location.href).href;
})();
</script>
</body>
</html>