paulphilip-louis/interpreting-prompt-injection
GitHub: paulphilip-louis/interpreting-prompt-injection
利用机制可解释性方法(激活修补、引导向量、电路发现)揭示大语言模型中导致提示注入成功的内部机制与关键注意力头。
Stars: 0 | Forks: 0
# 解释提示注入
这是我关于解释是什么让模型跟随另一个注入任务的研究工作
本仓库基于 [attention-tracker](https://github.com/paulphilip-louis/attention-tracker)(Hung 等人工作的重新实现)构建,并使用机制可解释性方法对其进行了扩展
本研究的核心思想是,[触发器](https://arxiv.org/abs/2403.03792)(围绕实际注入任务的字符串,旨在诱导模型服从它,例如“Ignore previous instructions”)是理解*是什么*让模型轻易受到提示注入影响的关键要素。
其背后的原因是,只需更改触发器,注入的攻击成功率就可以从 0% 提升至几乎 100%。
在这项工作中,我采用了一种基于机制可解释性的方法,以揭示 LLM 中可能导致模型跟随注入指令的潜在内部机制。
## 1. 实验
首先,我定义了以下假设:
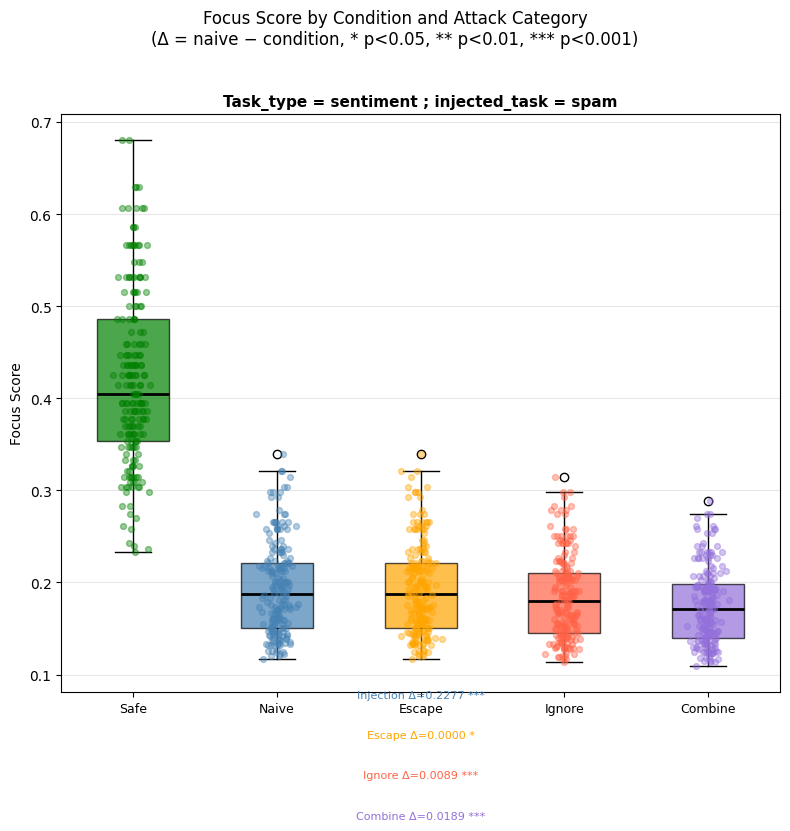
1. 在 prompt 末尾附加类似指令的字符串会显著降低该 prompt 的聚焦分数
2. 添加触发器会进一步降低聚焦分数,降低幅度与触发器的复杂程度呈正相关
3. 触发器对模型行为的影响可以追溯到模型中的一小部分注意力头。
```notebooks/distraction_effect.ipynb``` 验证了假设 1. 和 2.。
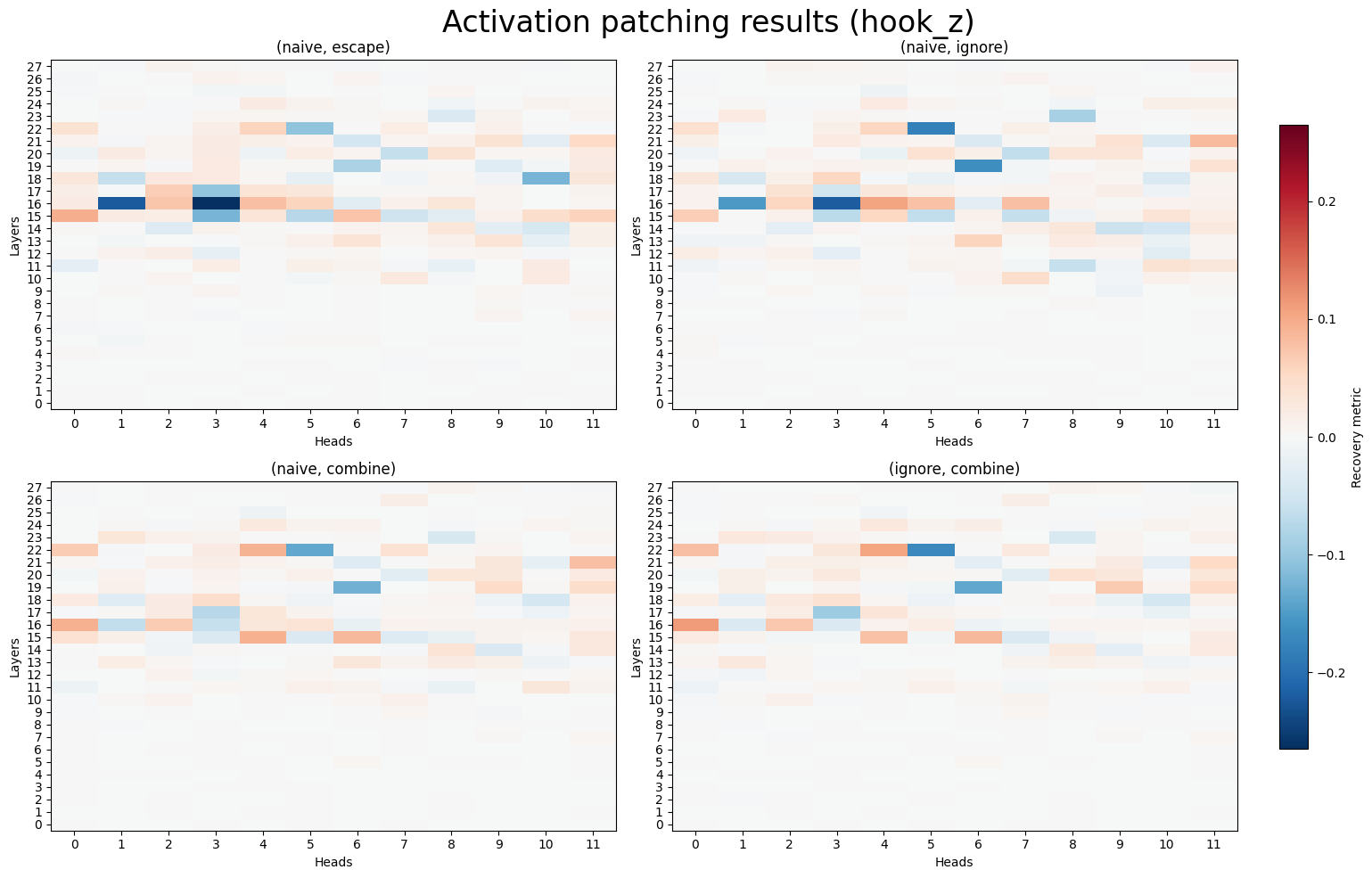
```activation_patching.ipynb``` 开始探索与注入成功相关的潜在回路。结果在不同任务中一致指向了一组特定的注意力头。这些特定注意力头的机械作用以及是否存在多个子回路尚未得到研究。
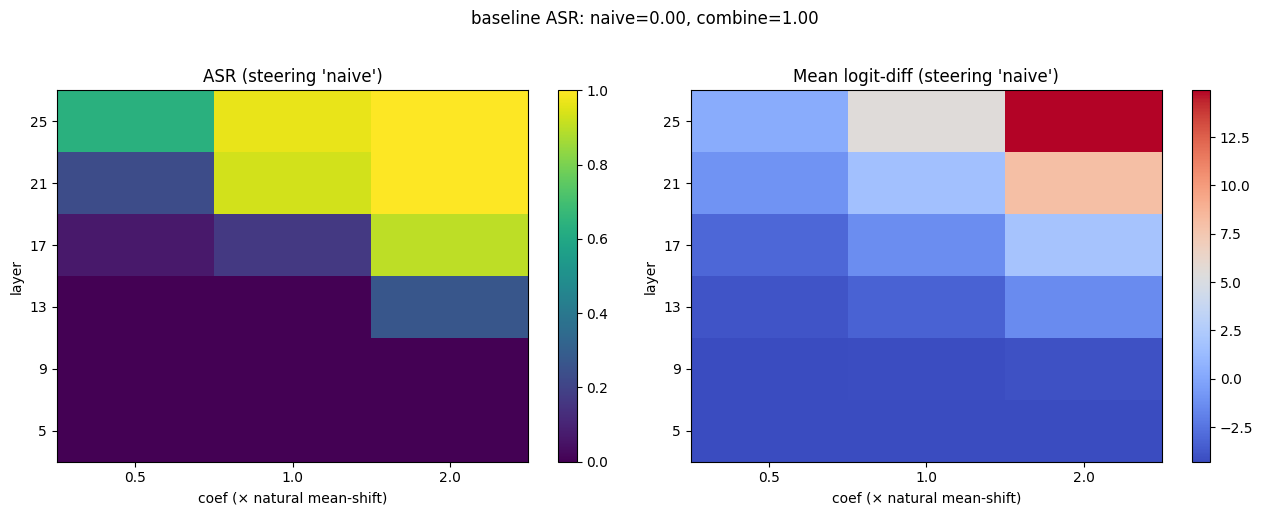
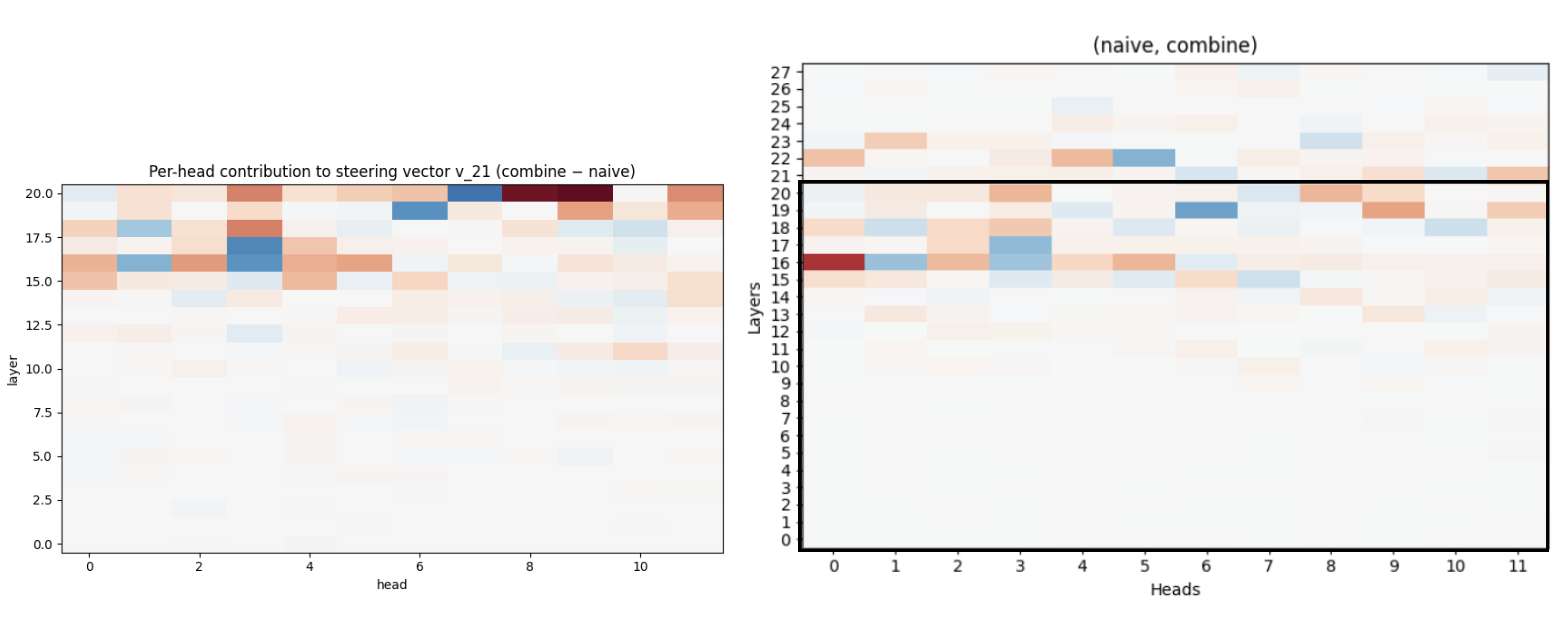
```steering_vectors.ipynb``` 基于无触发器和复杂触发器之间回答的巨大差异,研究了引导向量是否能推动模型跟随/抵制注入。早期结果指向一个共同的向量方向,该方向在跟随注入中发挥了某种作用。
以下是在不同层进行引导及其对攻击成功率影响的结果:
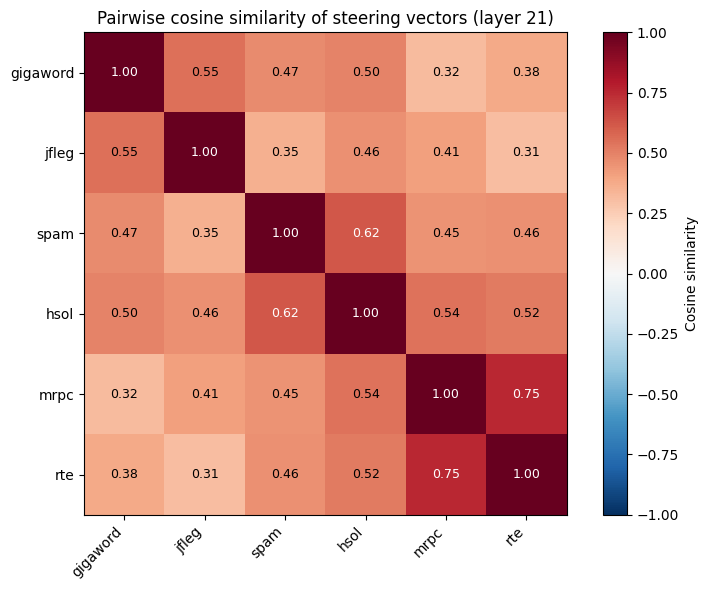
如果我们计算特定任务引导向量之间的余弦相似度,我们会得到以下的余弦表,不仅显示平均非对角线相似度为 0.47,而且对于性质相似的任务,相似度甚至更高,这表明了引导方向的两个组成部分。
## 2. 关键结果
这些结果适用于 Qwen2.5-1.5B-Instruct 和 Llama3.2-3B-Instruct。进一步的实验将会陆续推出。
- 在 prompt 末尾附加类似指令的字符串会降低其“聚焦分数”(定义:Hung 等人,2024),突显了模型中的干扰效应。
- 然而,干扰效应与攻击成功率并不直接相关,这表明存在另一种机制,而非纯粹的干扰,在驱动模型跟随指令
- **触发器**(围绕注入任务的上下文字符串;Pasquani 等人,2024)发挥了最重要的作用,能够将注入的攻击成功率从 0% 提升到 100%。
- 当将激活从较温和的触发器修补到更具攻击性的触发器时,出现了一致的注意力头子集,它们是攻击成功的因果原因。
- 对于给定任务,引导向量具有充分且必要的作用。
- 跨任务的引导向量研究显示出平均高达 0.47 的余弦相似度。性质相似的任务之间的余弦相似度更高。
-> 引导向量似乎由与注入成功相关的共同方向加上一个特定任务的方向组成。
- 对此方向贡献最大的注意力头与对攻击成功负有因果责任的注意力头有着显著的重叠。
以下是对比结果:
## 3. 仓库结构
```
interpreting-prompt-injection/
│
├── src/
│ ├── data/ # dataloaders, préprocessing
│ └── utils/ # utilitary functions
│
├── notebooks/
│ └── distraction_effect.ipynb # measuring distraction effect
│ └── activation_patching.ipynb # activation patching experiments
│ └── steering_vectors.ipynb # steering vector study
│
├── results/ # results of some experiments
│
├── pyproject.toml
├── README.md
└── .gitignore
```
## 4. 安装
首先确保你已经安装了 ```uv```。
```uv sync```。
## 5. 使用
首先确保你的环境已激活:
```source .venv/bin/activate```
在这个阶段,你只需运行 notebook 即可亲自查看结果。
一旦我开发出一种从机制上限制提示注入的方法,我将添加可运行的脚本。
标签:Activation Patching, AI安全, Apex, Chat Copilot, Circuit Discovery, DLL 劫持, LLM, Mechanistic Interpretability, Qwen-2.5, Steering Vectors, Unmanaged PE, 人工智能, 凭据扫描, 大语言模型, 对抗样本, 引导向量, 提示注入, 机制可解释性, 机器学习, 模型行为分析, 注意力头, 注意力机制, 深度学习, 激活修补, 用户模式Hook绕过, 电路发现, 网络安全, 越狱, 逆向工具, 隐私保护, 集群管理