kngsoomin/anti-scraping-detection-pipeline
GitHub: kngsoomin/anti-scraping-detection-pipeline
一个基于会话行为与规则的可解释反爬虫检测管道,解决从原始日志到可追溯检测结果的生产化流程问题。
Stars: 0 | Forks: 0
# 从行为到解释:一个可解释的机器人检测管道
## 1. 本项目的作用
本项目构建了一个**可重放的反爬虫分析管道**,将原始网络访问日志转换为可解释的会话级检测结果。
它使用行为信号识别可疑流量,同时保留完整的追溯能力,能够回溯到请求级别的事件。
除了检测结果,该管道还会生成一个可复用的会话级特征数据集,供后续分析和模型开发使用。
### 简述 🤓
- 构建可靠的检测管道,使用会话级行为信号识别可疑的网络流量
- 从检测结果完整追溯到原始请求事件
- 将检测(行为)与解释(上下文)分离,提升可解释性
- 同时提供面向分析师的检测结果和面向机器学习的特征数据集
## 2. 这个问题为何困难
从网络日志中检测爬取行为之所以困难,是因为合法爬虫和恶意抓取者往往表现出相似的模式。
两者都可能产生:
- 高请求速率
- 系统化地遍历大量路径
- 缺失引用来源(referer)信号
因此,基于行为的检测可以识别自动化活动,但无法可靠地区分善意与恶意意图。
这就在检测与解释之间形成了一个差距,仅凭行为不足以理解被标记的流量。
## 3. 本管道生成的内容
本管道生成两类数据产品,面向不同的使用者。
### 1. 检测结果(主要)
主要输出是一个面向分析师和运营监控的可解释检测数据集。
它回答以下问题:
- 哪些会话可疑?
- 为什么会被标记?
- 应该如何解释?
主数据集 `suspicious_sessions` 提供:
- 会话级风险评分与风险等级
- 基于规则的信号,解释为何标记该会话
- 上下文注释以辅助解释
这些输出使分析师能够调查可疑流量、识别误报,并区分可能的良性爬虫与未知自动化行为。
### 2. 特征数据(次要)
管道还会生成一个会话级特征数据集(`session_features`),供后续分析和模型开发使用。
该数据集提供:
- 从会话活动派生的行为信号
- 最小的上下文特征
它作为可复用的输入,用于:
- 训练检测模型
- 行为分析与实验
## 4. 工作原理
### 数据
- `access.log`
以 Apache 组合日志格式存储的原始网络访问日志,包含请求级信息,如 IP、时间戳、请求路径、状态码、引用来源和用户代理。
数据集包含约 1000 万条请求,时间跨度为 5 天(2019-01-22 至 2019-01-26)。
- `ip_hostname_lookup.csv`
用于将 IP 地址映射到主机名的查找表,用于轻量级上下文增强。
访问日志作为行为分析的主要输入,而主机名映射则为解释检测流量提供额外信号。
### 数据流程
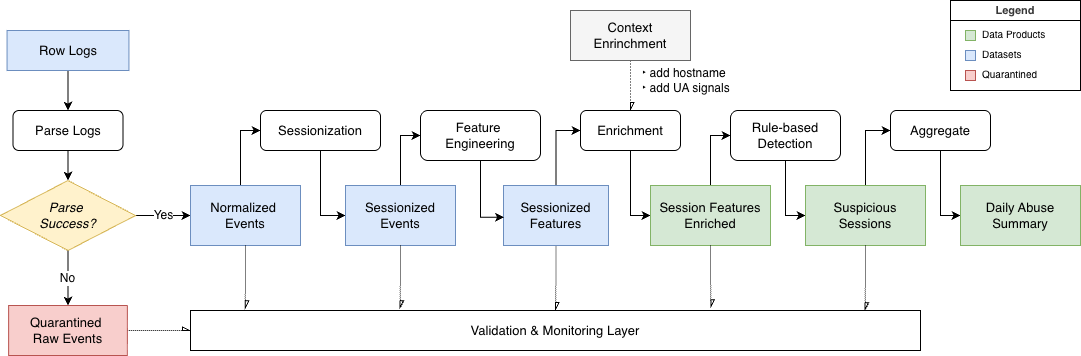
### 分层结构
#### 核心转换
- **原始日志(Raw Logs)**
不可变的、仅追加的源数据,作为传入网络流量的来源。
格式错误或无法解析的行会在早期被隔离并单独存储以供检查。
- **标准化事件(请求级)**
从原始日志提取的结构化请求记录,不应用任何检测逻辑。
该层标准化核心字段,并对路径进行模板化处理,将动态 URL 泛化为可重用的模式。
- **会话化事件(事件级)**
在请求级记录基础上增加 `session_id`,其由 `(src_ip, user_agent)` 和不活动阈值推导得出。
包含从前一天回溯的窗口,以保留跨分区的会话边界。
- **会话特征(会话级)**
在会话粒度上计算的聚合行为特征。
该层将事件级活动转换为模型就绪的会话表示。
#### 数据产品
- **增强的会话特征(会话级)**
基于主机名查找和用户代理模式派生的轻量级上下文信号增强的会话级特征。
这些信号用于解释,而非检测分数本身。
- **可疑会话(会话级)**
基于行为特征进行规则评分后产生的可解释检测结果。
每个会话被分配一个 `risk_band`,仅以注释形式附加上下文信号。
- **每日滥用汇总(天级)**
可疑活动的每日聚合,用于监控与报告。
该层在更高层级汇总流量模式与风险分布。
### 验证与监控
管道在每个阶段都强制执行数据质量检查,并记录执行元数据以实现可观测性。
- **核心验证检查**
行数一致性、粒度一致性、重复检测、空值与范围验证,确保转换过程保持数据完整性。
- **执行行为**
错误级检查在出现关键问题时快速失败,而警告级检查则暴露非阻塞的数据质量问题。
- **隔离处理**
格式错误或无法解析的原始行在解析阶段被隔离,防止无效数据向下游传播。
同时生成解析失败摘要,以支持调试与监控。
- **指标与元数据**
每次运行都会生成结构化指标(如行数、验证结果、风险分布)和运行时元数据(运行 ID、持续时间、状态),用于追溯与调试。
### 执行模型
管道以 `process_date` 为驱动的每日批处理方式运行,为每次运行生成分区输出。
- **批处理模型**
每次运行处理单个日期或日期范围,支持可重现、回填和隔离重处理。
- **分区输出**
输出按日期写入,允许高效过滤与回放,而无需处理整个数据集。
- **离线优先设计**
虽然以批处理方式实现,但系统围绕分区数据设计,便于扩展为近实时处理,而无需更改核心数据模型。
- **环境感知执行**
同一管道可在不同环境(本地与 EC2)中运行,行为由配置文件驱动。
本地运行默认处理采样数据以避免内存限制,而 EC2 则处理完整数据集。
- **配置驱动行为**
管道的多个方面通过配置控制,包括检测阈值与采样限制。
这使系统能够针对不同环境与数据规模进行调优,而无需修改核心逻辑。
## 5. 结果
### Q1. 可疑会话与正常流量有何不同?
**高风险会话表现出突发性、机器类行为,且请求间隔接近零。**
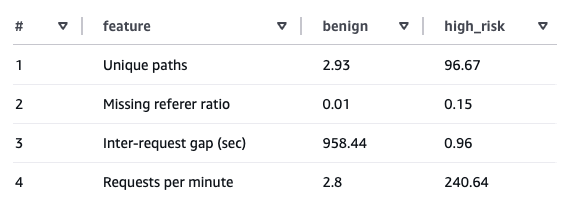
- 请求速率显著更高
- 请求间隔接近零
- 相比良性会话,导航模式更不自然
### Q2. 已知爬虫在风险谱系中出现在哪里?
**已知爬虫信号集中在低风险会话中,而高风险会话主要由未解析的上下文流量主导。**

- 已知机器人候选者(known_bot_candidate)最常出现在低风险等级
- 高风险会话大多与未解析的主机上下文相关
- 上下文信号有助于区分可识别的爬虫与未知自动化
上下文信号仅用于解释,不会影响检测分数。
### Q3. 可疑会话实际看起来是什么样的?
**可疑会话通常会在短时间内显示快速、重复的请求模式。**
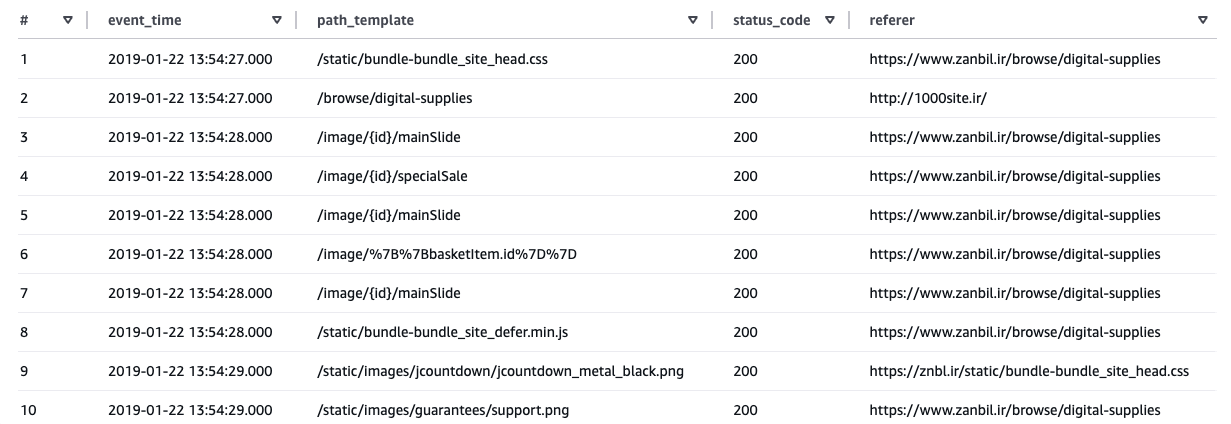
- 初始导航后出现连续的请求爆发
- 重复访问类似的路径模板(例如图像端点)
- 极短的请求间隔
这些模式展示了会话级信号如何直接映射到请求级行为,从而实现追溯与检查。
### Q4. 可疑活动是否集中在少数 IP 上?
**可疑活动高度集中,少数 IP 产生了大量被标记的会话。**
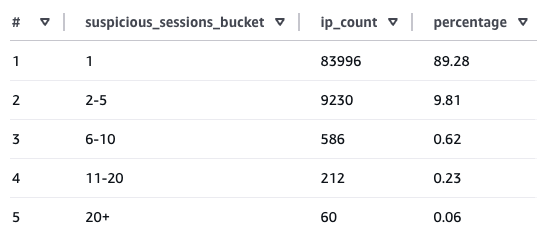
- 大多数 IP 仅生成少量可疑会话
- 少数子集 IP 占据了不成比例的比例
- 重复的自动化行为往往可追溯到 recurring actors
## 6. 限制
### 1. 仅凭行为无法确定意图
检测逻辑基于行为信号,能有效识别自动化活动,但无法捕捉意图。
因此,合法爬虫与潜在恶意抓取者可能表现出相似模式,在没有额外上下文的情况下难以区分。
### 2. 上下文信号不完整且可能不可靠
上下文增强依赖于主机名解析和用户代理模式,这些本身存在局限。
- 并非所有 IP 都能映射到已知主机名
- 用户代理字符串可能被伪造
- 查找数据集可能未覆盖所有相关域名
这意味着上下文信号仅提供有用提示,但不应被视为确定性指标。
### 3. 解析效率受限于逐行 Python 执行
当前解析层在 Spark 中对每个日志条目应用基于 Python 的逻辑,优先考虑处理原始日志格式的灵活性。
然而,相较于原生的 Spark SQL 转换,这种方法引入了额外开销,特别是在数据规模较大时。
虽然适用于当前场景,但可通过将更多解析逻辑表达为内置的 Spark 函数来进一步优化,以减少 Python 执行成本。
## 7. 后续改进
### 1. 近实时检测
当前管道作为每日批处理系统运行,但架构可扩展以支持近实时处理。
通过引入流式摄取层(例如 Kafka)并处理更短的时间窗口,即可实现。
由于管道已基于分区数据运行,核心数据模型与转换逻辑可在不做重大修改的情况下复用于增量或流式执行。
### 2. 增强的上下文信号
当前的上下文增强依赖于主机名和用户代理模式,可进一步扩展,加入 IP 信誉数据、ASN 信息或历史行为模式,以提升可解释性。
### 3. 基于模型的检测
虽然当前系统使用基于规则的检测,但会话级特征数据集为未来集成机器学习模型提供了可能。
这些模型可以捕捉更复杂的行为模式,超越手动定义的规则,从而提升检测性能。
## 8. 项目结构
### 项目目录
```
docs
├── config/ # Environment-specific configuration
├── docs/ # Documentation and analysis artifacts
├── jobs/ # Entry points for each pipeline stage
├── src/
│ ├── parsing/ # Raw log parsing logic
│ ├── sessionization/ # Session reconstruction
│ ├── features/ # Session-level feature engineering
│ ├── enrichment/ # Context signal enrichment
│ ├── detection/ # Rule-based detection logic
│ ├── monitoring/ # Validation, metrics, and manifest
│ └── common/ # Shared utilities and Spark setup
├── tests/ # Unit tests for core transformations
└── requirements.txt
```
每个管道阶段在 `src/` 中实现为模块化转换,并通过 `jobs/` 下的对应作业入口点进行调用,以实现灵活的编排与阶段级执行。
### 存储布局
管道输出以分区布局存储,以支持可重现性与回填。
```
anti-scraping/
├── raw_logs/event_date=YYYY-MM-DD/
├── normalized_events/event_date=YYYY-MM-DD/
├── sessionized_events/session_date=YYYY-MM-DD/
├── session_features/session_date=YYYY-MM-DD/
├── session_features_enriched/session_date=YYYY-MM-DD/
├── suspicious_sessions/session_date=YYYY-MM-DD/
├── daily_abuse_summary/event_date=YYYY-MM-DD/
├── quarantined_raw_events/process_date=YYYY-MM-DD/
├── quarantined_raw_lines/ ← no partition
├── manifests/process_date=YYYY-MM-DD/
└── metrics/process_date=YYYY-MM-DD/
```
分析数据集按事件或会话日期分区,便于高效过滤与按日粒度重处理。
相比之下,操作输出(如清单、指标与聚合的隔离记录)按处理日期分区,反映每次管道运行的执行上下文。
隔离输出根据用途不同而采用不同分区策略:聚合隔离数据集按处理日期分区,而原始隔离行则不分区存储以简化检查与调试。
鉴于此场景中原始隔离数据量较小,采用非分区布局足够且避免了不必要的复杂性。
## 9. 基础设施
该管道在本地与云端环境中开发与测试。
环境选择在成本与基于 Spark 的批处理内存之间取得平衡。
### 计算
- AWS EC2(Ubuntu 22.04 LTS)
- 实例类型:m5.xlarge(4 vCPU,16 GB RAM,50 GiB (gp3) EBS)
### 存储
- Amazon S3 用于数据湖存储
- 分区 Parquet 数据集用于分析输出
### 处理
- Apache Spark 用于分布式数据处理
### 查询与分析
- Amazon Athena 用于交互式查询与结果验证
## 10. 如何运行
#### 先决条件
- Python 3.10+
- Java 11+(Spark 所必需)
- Apache Spark(PySpark)
#### 设置
```
git clone https://github.com/kngsoomin/anti-scraping-detection-pipeline.git
cd anti-scraping-detection-pipeline
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
```
#### 环境准备
该管道支持本地与 EC2 执行。
以下命令中,最后一个位置参数指定环境(`local` 或 `ec2`)。
**本地**
- 从 Kaggle 下载数据集并放置到:
data/kaggle/access.log
- 默认处理采样数据子集以避免内存问题
**EC2**
- 将原始数据集(`access.log`)上传至 EC2 实例(本地文件系统)
- 为输出配置 S3 存储桶
- 更新 `config/ec2.yml` 以设置环境配置
- 输出将写入 S3
#### 一次性设置(原始数据分区)
原始数据集以单个日志文件提供。
在运行管道前,必须按日期将其分区为 `raw_logs/`:
```
python -m jobs.run_prepare_raw_partitions
```
此步骤每个数据集只需执行一次。
#### 运行管道
单日期:
```
python -m jobs.run_pipeline --process-date 2019-01-22
```
日期范围(回填):
```
python -m jobs.run_pipeline --start-date 2019-01-22 --end-date 2019-01-26
```
#### 检查输出
```
python -m jobs.inspect_outputs --process-date 2019-01-22
```
#### 注意事项
- 跨环境使用相同的执行逻辑,行为由配置文件控制
- 本地运行处理采样数据,而 EC2 处理完整数据集
标签:SEO反作弊, Web安全, 云计算, 会话化, 会话特征, 反爬虫, 可解释性, 异常检测, 数据管道, 机器学习特征, 爬虫识别, 监控, 蓝队分析, 行为检测, 规则引擎, 软件工程, 逆向工具