browser-use/video-use
GitHub: browser-use/video-use
video-use 是一个开源的 Claude Code 技能插件,让用户通过自然语言对话指挥 AI agent 自动完成视频剪辑。
Stars: 18163 | Forks: 2235
# video-use
隆重介绍 **video-use** —— 使用 Claude Code 编辑视频。100% 开源。
将原始素材拖入文件夹,与 Claude Code 对话,即可拿回 `final.mp4`。适用于任何内容 —— 口播、混剪、教程、旅行、访谈 —— 无需预设或菜单。
## 功能简介
- **剪除冗余词汇**(`umm`、`uh`、口误)和片段间的无效空白
- **自动调色**每个片段(温暖电影感、中性强对比,或任何自定义的 ffmpeg 链)
- **30ms 音频淡入淡出**应用于每个剪切点,让您永远不会听到爆破音
- **按照您的风格硬编码烧录字幕** —— 默认为 2 个词的大写切片,完全可自定义
- **生成动画叠加**,通过 [HyperFrames](https://github.com/heygen-com/hyperframes)、[Remotion](https://www.remotion.dev/)、[Manim](https://www.manim.community/) 或 PIL 实现 —— 在并行子 agent 中生成,每个动画对应一个子 agent
- **自我评估渲染输出**,在向您展示之前,于每个剪切边界进行检查
- **持久化会话记忆**于 `project.md` 中,以便下周的会话能从您上次中断的地方继续
## 设置提示词
将其粘贴到 Claude Code、Codex、Hermes、Openclaw 或任何具备 shell 访问权限的 agent 中:
```
Set up https://github.com/browser-use/video-use for me.
Read install.md first to install this repo, wire up ffmpeg, register the skill with whichever agent you're running under, and set up the ElevenLabs API key — ask me to paste it when you need it. Then read SKILL.md for daily usage, and always read helpers/ because that's where the editing scripts live. After install, don't transcribe anything on your own — just tell me it's ready and wait for me to drop footage into a folder.
```
该 agent 会处理克隆、依赖项安装、skill 注册,并提示您输入一次 ElevenLabs API 密钥(可在 [elevenlabs.io/app/settings/api-keys](https://elevenlabs.io/app/settings/api-keys) 获取)。
然后,将您的 agent 指向一个包含原始录制片段的文件夹:
```
cd /path/to/your/videos
claude # or codex, hermes, etc.
```
若要在您自己的 VPS 或 Telegram 上实现常驻编辑,请通过 [Browser Use Box](https://browser-use.com/bux) 运行该 agent。[观看 15 秒演示](https://www.tiktok.com/@browser_use/video/7639824093721758989)。
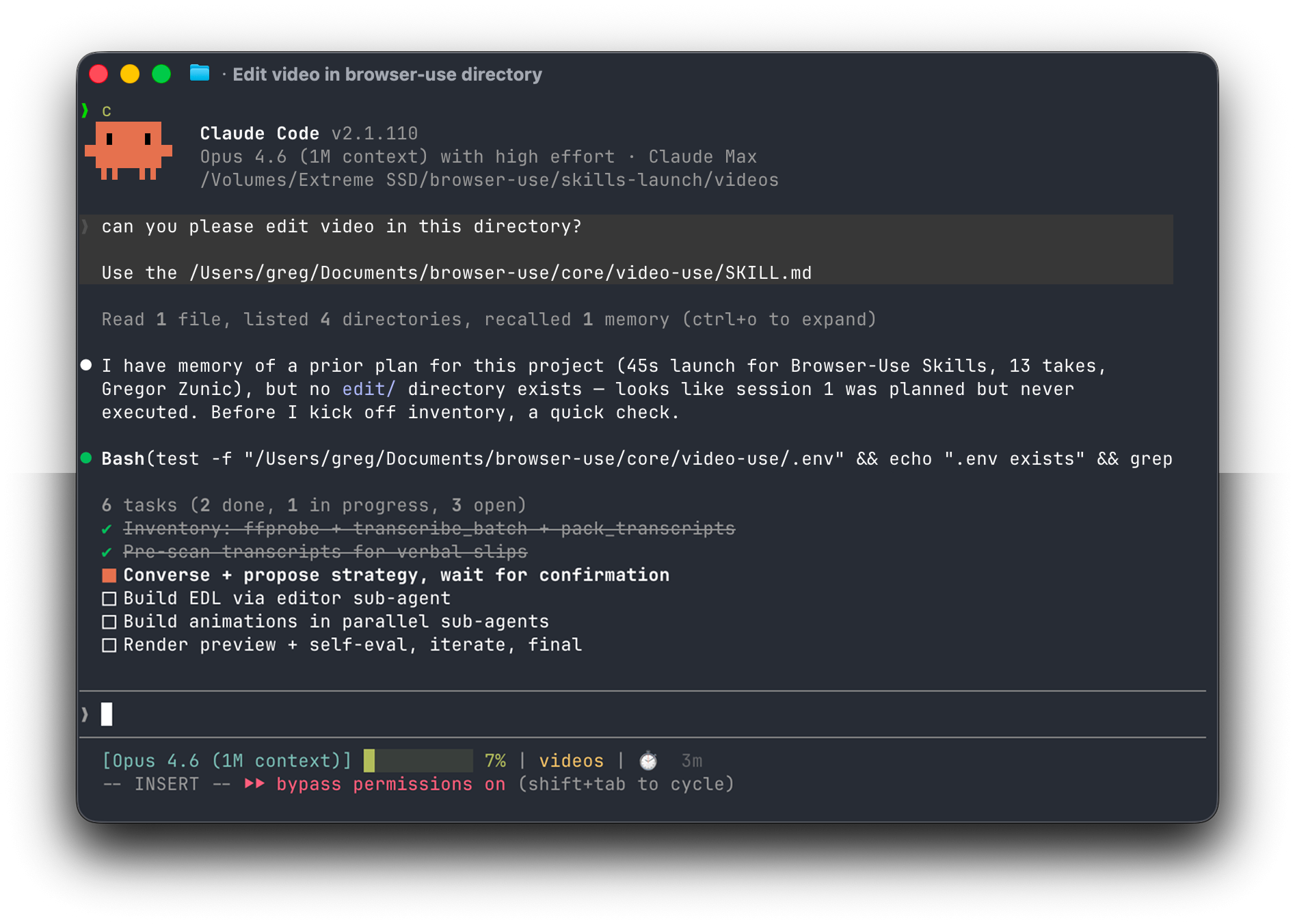
而在会话中:
它会盘点素材源,提出策略,等待您确认,然后在您的素材旁边生成 `edit/final.mp4`。所有输出文件都存放在 `
/edit/` 中 —— skill 目录保持整洁。
## 手动安装
如果您更愿意手动操作:
```
# 1. Clone 并 symlink 到你的 agent 的 skills 目录中
git clone https://github.com/browser-use/video-use ~/Developer/video-use
ln -sfn ~/Developer/video-use ~/.claude/skills/video-use # Claude Code
# ln -sfn ~/Developer/video-use ~/.codex/skills/video-use # Codex
# 2. 安装 deps
cd ~/Developer/video-use
uv sync # or: pip install -e .
brew install ffmpeg # required
brew install yt-dlp # optional, for downloading online sources
# 3. 添加你的 ElevenLabs API key
cp .env.example .env
$EDITOR .env # ELEVENLABS_API_KEY=...
```
## 工作原理
LLM 从不“观看”视频。它是在**阅读**视频 —— 通过两层结构,为其提供实现精确到词汇边界剪切所需的一切信息。

**第 1 层 —— 音频转写文本(始终加载)。** 每个素材源调用一次 ElevenLabs Scribe,即可提供词汇级别的时间戳、说话人分离以及音频事件(`(laughter)`、`(applause)`、`(sigh)`)。所有录制片段打包进一个约 12KB 的 `takes_packed.md` 文件中 —— 这是 LLM 的主要阅读视图。
```
## C0103 (持续时间: 43.0秒, 8 个短语)
[002.52-005.36] S0 Ninety percent of what a web agent does is completely wasted.
[006.08-006.74] S0 We fixed this.
```
**第 2 层 —— 可视化合成(按需调用)。** `timeline_view` 会针对任何时间范围生成包含胶片条 + 波形 + 词汇标签的 PNG 图像。仅在需要做决策的点被调用 —— 比如模糊的停顿、重拍对比、剪切点合理性检查。
这与 browser-use 为 LLM 提供结构化 DOM 而非屏幕截图的思路相同 —— 只不过是针对视频的。
## 流水线
```
Transcribe ──> Pack ──> LLM Reasons ──> EDL ──> Render ──> Self-Eval
│
└─ issue? fix + re-render (max 3)
```
自评估循环会在每个剪切边界对_渲染后的输出_运行 `timeline_view` —— 用于捕捉画面跳变、音频爆破音、被隐藏的字幕。只有通过检查后,您才会看到预览。
## 设计原则
1. **文本 + 按需可视化。** 不进行帧转储。转写文本即是操作界面。
2. **音频为主,画面为辅。** 剪切基于语音边界和静音间隙。
3. **询问 → 确认 → 执行 → 自评估 → 持久化。** 未经策略批准,绝不触碰剪辑。
4. **对内容类型零假设。** 先观察,询问,然后再剪辑。
5. **12 条硬性规则,其余给予艺术自由。** 制作层面的正确性不容妥协。但品味不在此列。
完整的生产规则和编辑技巧请参阅 [`SKILL.md`](./SKILL.md)。标签:AI编程助手, FFmpeg, LLM代理, 网络调试, 自动化, 视频编辑, 逆向工具