kadak25/runbook-executor
GitHub: kadak25/runbook-executor
这是一个基于AI决策的自主事件响应系统,能够自动执行故障补救、生成RCA报告并创建Jira工单,实现从告警到自愈的闭环管理。
Stars: 0 | Forks: 0
# Runbook Executor — 自动化事件响应引擎
一个自愈系统,能够检测生产环境事件,决定正确的补救措施,自动执行,生成包含完整事件时间线的 AI 驱动 RCA 报告,并创建 Jira 工单 —— 全程无需人工干预。
## 工作原理
```
Prometheus Alert → Alertmanager Webhook → API → Container Logs
↓
AI Triage (log-triage-service)
↓
Condition Engine → Decision
↓
Action Executed
↓
Jira Ticket + RCA Report + Timeline Auto-Generated
```
**真实示例:**
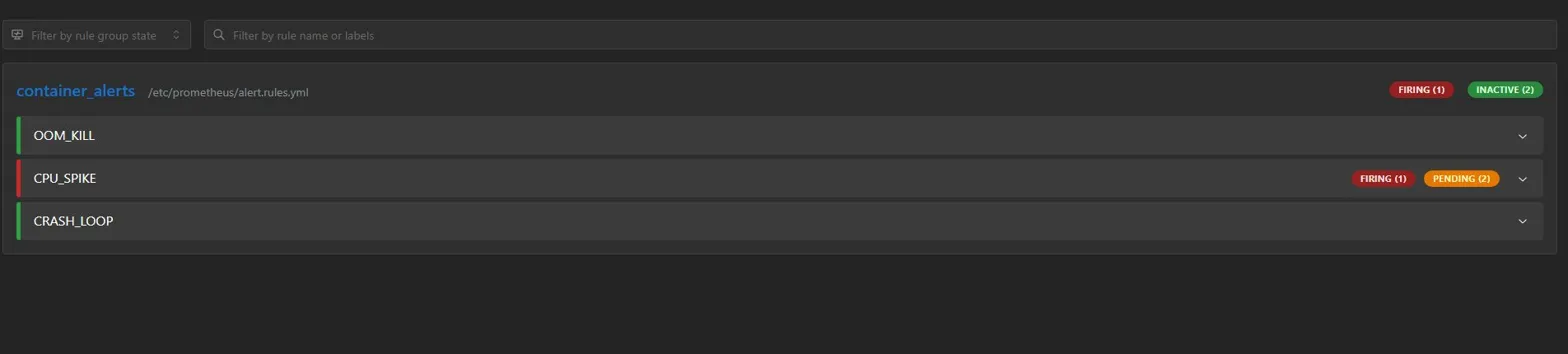
1. Prometheus 检测到 CPU_SPIKE 或 OOM_KILL
2. Alertmanager 发送 webhook 到 `/incident`
3. 自动拉取容器日志
4. 日志发送到 [log-triage-service](https://github.com/kadak25/log-triage-service) —— AI 生成根本原因假设 + 严重程度
5. 条件引擎检查来自 SQLite 的重启历史
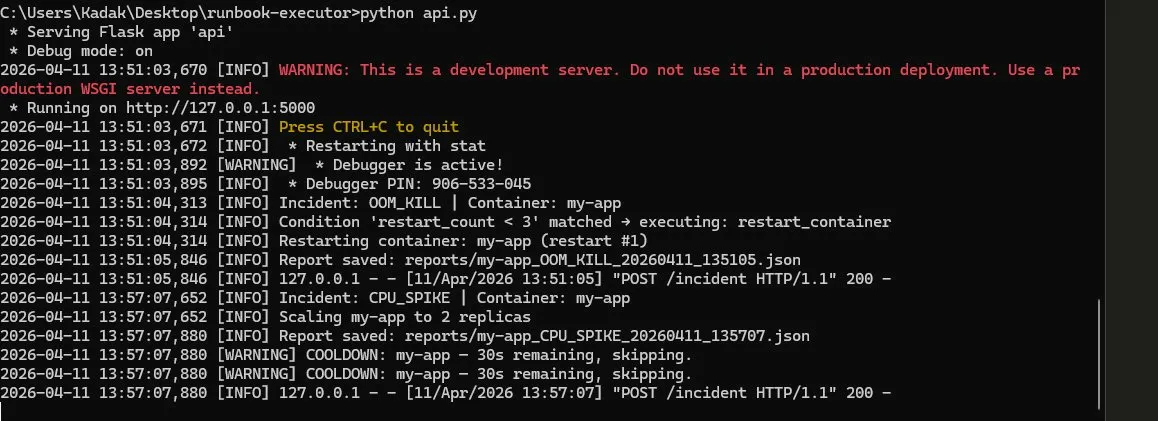
6. 如果 restart_count < 3 → 重启容器;如果 >= 3 → 升级
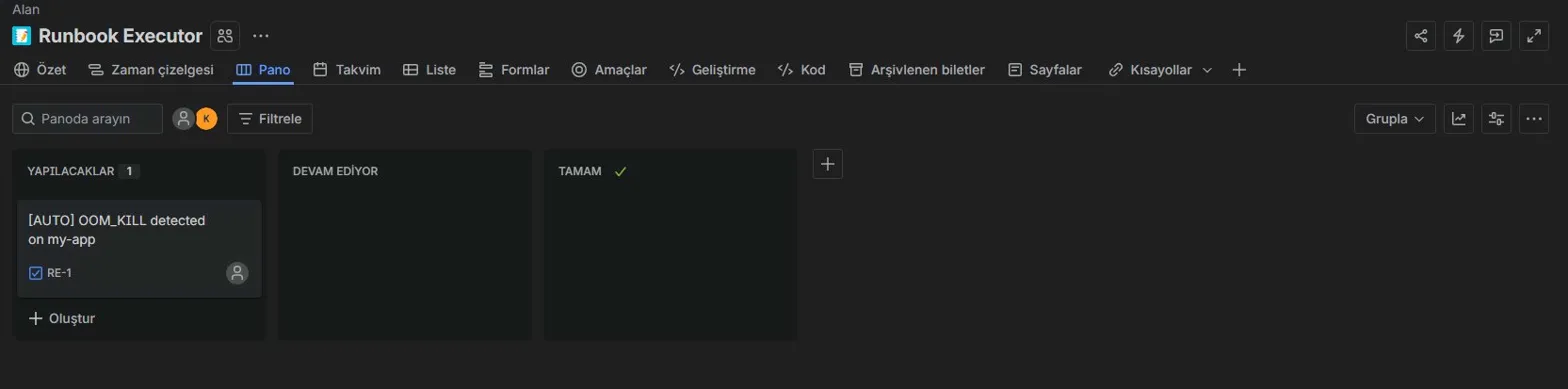
7. 自动创建包含 AI 根本原因和后续步骤的 Jira 工单
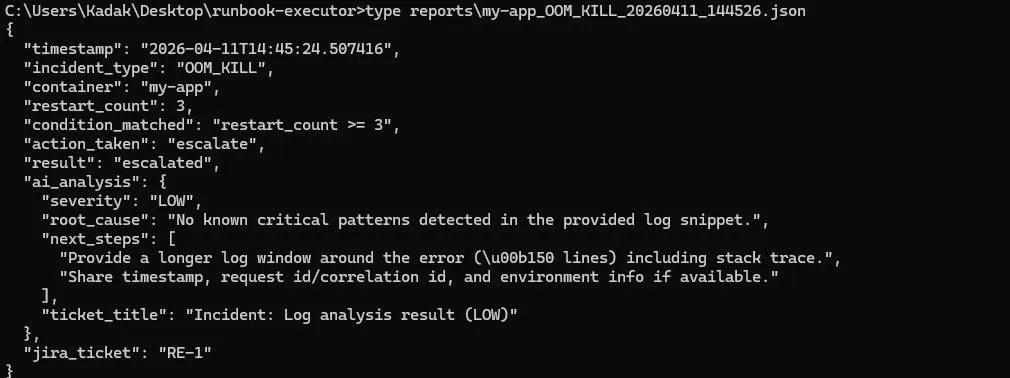
8. 完整的 RCA 报告保存为 JSON —— 包括事件时间线、AI 分析和 Jira 工单编号
## 演示
### Prometheus — CPU Spike & OOM Kill 触发
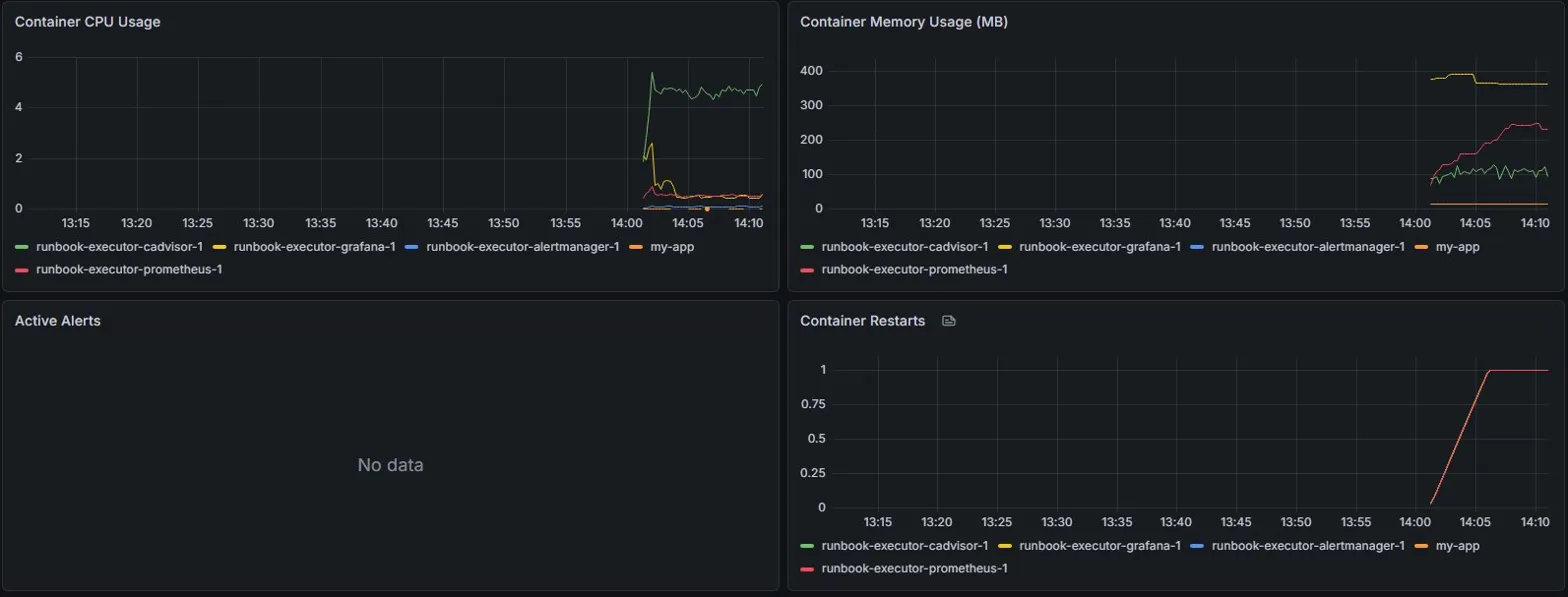
### Grafana — 实时基础设施仪表板
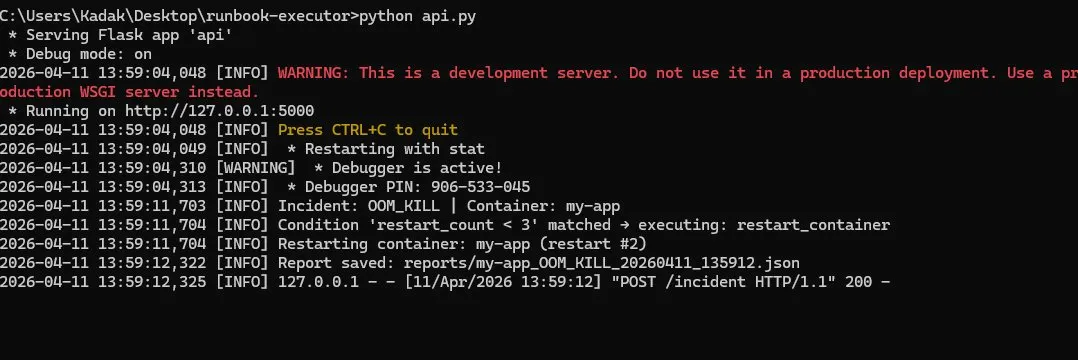
### API — 自动响应(OOM Kill + CPU Spike)
### API — AI Triage + Jira 工单自动创建
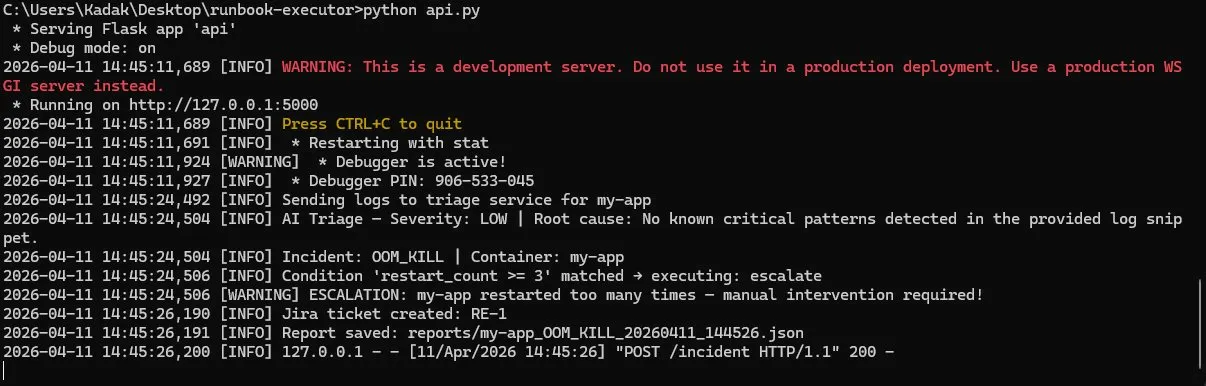
### API — 反复重启后升级
### Jira Board — 自动生成的事件工单
### RCA Report — 包含 AI 分析 + 时间线的完整 JSON
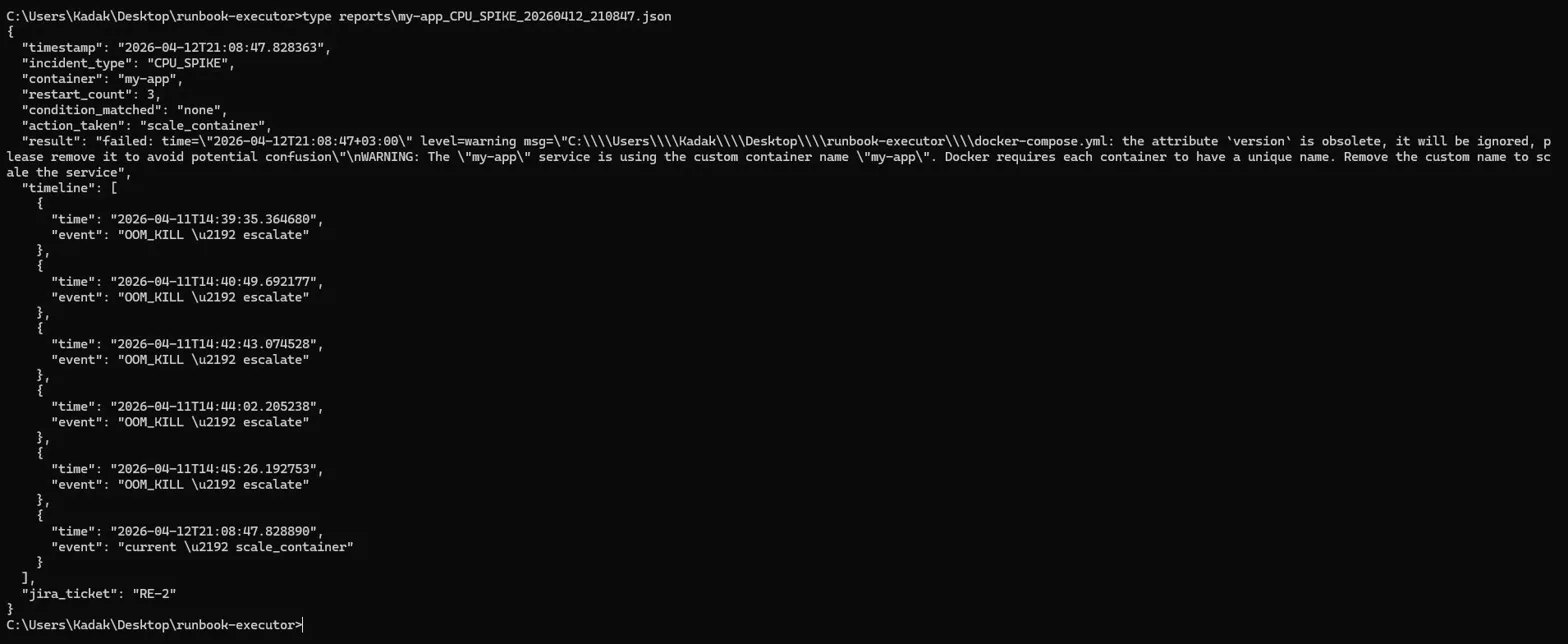
### Timeline RCA — 跨会话的事件历史
## 功能特性
- **基于条件的决策引擎** —— 评估重启历史,应用升级逻辑
- **AI 驱动诊断** —— 集成 [log-triage-service](https://github.com/kadak25/log-triage-service) 以分析容器日志并生成带有严重程度评分的根本原因假设
- **事件时间线** —— 每份 RCA 报告都包含该容器在跨会话中的所有过往操作历史
- **冷却保护** —— 防止重复警报时的操作刷屏(可配置,默认 30s)
- **持久化状态 (SQLite)** —— 重启计数和事件历史在服务重启后依然保留
- **自动生成的 RCA 报告** —— 每个事件的结构化 JSON:时间戳、匹配的条件、采取的操作、AI 分析、时间线、Jira 工单编号
- **Jira 集成** —— 事件工单自动创建,附带 AI 根本原因和后续步骤
- **HTTP API** —— 接受 Alertmanager webhook 格式和手动 POST 请求
- **基于 cAdvisor 的真实指标** —— 实际的容器 CPU 和内存数据,非模拟数据
## 架构
```
┌─────────────┐ ┌──────────────┐ ┌─────────────────┐
│ Prometheus │────▶│ Alertmanager │────▶│ Flask API │
└─────────────┘ └──────────────┘ └────────┬────────┘
│
┌───────────▼───────────┐
│ Get Container Logs │
└───────────┬───────────┘
│
┌───────────▼───────────┐
│ log-triage-service │
│ (AI Root Cause + Sev) │
└───────────┬───────────┘
│
┌────────▼────────┐
│ Condition Engine │
└────────┬────────┘
│
┌──────────────┼──────────────┐
│ │ │
┌──────▼─────┐ ┌─────▼──────┐ ┌────▼──────┐
│ Restart │ │ Scale │ │ Escalate │
└──────┬─────┘ └─────┬──────┘ └────┬──────┘
│ │ │
└──────────────┼──────────────┘
│
┌──────────────┼──────────────┐
│ │
┌──────▼──────┐ ┌───────▼──────┐
│ JSON Report │ │ Jira Ticket │
│ + Timeline │ │ (AUTO) │
│ + SQLite │ └──────────────┘
└─────────────┘
```
## 支持的事件类型
| 事件 | 条件 | 操作 |
|---|---|---|
| OOM_KILL | restart_count < 3 | restart_container |
| OOM_KILL | restart_count >= 3 | escalate + Jira ticket |
| CRASH_LOOP | restart_count < 3 | restart_container |
| CRASH_LOOP | restart_count >= 3 | escalate + Jira ticket |
| CPU_SPIKE | — | scale_container |
## 示例 RCA 报告
```
{
"timestamp": "2026-04-12T21:08:47",
"incident_type": "CPU_SPIKE",
"container": "my-app",
"restart_count": 3,
"condition_matched": "none",
"action_taken": "scale_container",
"result": "success",
"timeline": [
{ "time": "2026-04-11T14:39:35", "event": "OOM_KILL → escalate" },
{ "time": "2026-04-11T14:40:49", "event": "OOM_KILL → escalate" },
{ "time": "2026-04-11T14:45:26", "event": "OOM_KILL → escalate" },
{ "time": "2026-04-12T21:08:47", "event": "current → scale_container" }
],
"ai_analysis": {
"severity": "LOW",
"root_cause": "No known critical patterns detected in the provided log snippet.",
"next_steps": [
"Provide a longer log window around the error including stack trace.",
"Share timestamp, request id/correlation id, and environment info."
],
"ticket_title": "Incident: Log analysis result (LOW)"
},
"jira_ticket": "RE-2"
}
```
## 技术栈
- **Python** —— 条件引擎、操作执行器、报告生成器、时间线构建器
- **Flask** —— webhook API
- **SQLite** —— 持久化事件状态和历史
- **[log-triage-service](https://github.com/kadak25/log-triage-service)** —— AI 驱动的日志分析、根本原因假设、严重程度评分 (Java 17 + Spring Boot + Hugging Face LLM)
- **Prometheus + Alertmanager** —— 警报生成和路由
- **cAdvisor** —— 实际的容器 CPU/内存指标
- **Grafana** —— 实时基础设施仪表板
- **Jira API** —— 自动生成的事件工单
- **Docker + Docker Compose** —— 容器管理和测试环境
- **YAML** —— runbook 定义(人类可读,易于扩展)
## 快速开始
```
# 启动 infrastructure
docker compose up -d
# 启动 log-triage-service (参见 https://github.com/kadak25/log-triage-service)
cd ../log-triage-service && docker compose up -d
# 启动 API
cd ../runbook-executor
set JIRA_TOKEN=your_token_here # Windows
export JIRA_TOKEN=your_token_here # Linux/Mac
python api.py
# 手动测试
curl -X POST http://localhost:5000/incident \
-H "Content-Type: application/json" \
-d '{"incident_type": "OOM_KILL", "context": {"container": "my-app"}}'
```
## 触发真实的 CPU Spike
```
docker run --name cpu-stress --rm progrium/stress --cpu 4 --timeout 60
```
观察 Prometheus 触发警报,Alertmanager 将其路由到 API,AI 分析日志,然后系统自动扩容并创建 Jira 工单。
## 为什么这很重要
L1 支持团队花费大量时间在重复的事件响应上:
- 凌晨 3 点被叫醒
- 查阅 runbook
- 手动分析日志
- 重启容器
- 编写 Jira 工单
该系统消除了整个循环。Runbook **就是**代码。日志被自动**分析**。工单**自动编写**。时间线自动**构建**。
## 扩展
只需 3 行 YAML 即可添加新的事件类型:
```
DISK_FULL:
actions:
- rotate_logs
```
然后在 `executor.py` 中实现 `rotate_logs()`。完成。
## 相关项目
- [log-triage-service](https://github.com/kadak25/log-triage-service) —— AI 驱动的日志分析工具,用作本系统的诊断层
标签:AI运维, Alertmanager, CPU监控, Grafana, Jira集成, JS文件枚举, OOMKill处理, REST API, SQLite, SRE, Webhook, 偏差过滤, 力导向图, 容器编排, 容量规划, 工作流自动化, 故障诊断, 智能决策, 根因分析, 生产环境监控, 自动化运维, 自定义请求头, 自愈系统, 请求拦截, 逆向工具