OpenMOSS/MOSS-Audio
GitHub: OpenMOSS/MOSS-Audio
MOSS-Audio 是一个开源的统一音频理解基础模型,支持语音、声音、音乐的识别、问答与推理,解决真实场景下多维度音频理解问题。
Stars: 621 | Forks: 42
# MOSS-Audio



 MOSS-Audio 是由 [MOSI.AI](https://mosi.cn/#hero)、[OpenMOSS 团队](https://www.open-moss.com/) 和 [上海创智学院](https://www.sii.edu.cn/) 联合开源的 **音频理解模型**。该模型针对复杂的真实世界音频进行了统一建模,支持 **语音理解、环境声音理解、音乐理解、音频字幕生成、时间感知问答和复杂推理**。在本次发布中,我们提供了 **四个模型**:**MOSS-Audio-4B-Instruct**、**MOSS-Audio-4B-Thinking**、**MOSS-Audio-8B-Instruct** 和 **MOSS-Audio-8B-Thinking**。Instruct 版本针对直接指令遵循进行了优化,而 Thinking 版本则提供了更强大的思维链(chain-of-thought)推理能力。
## 新闻
* 2026.6.1:我们在 arXiv 上发布了 [MOSS-Audio 技术报告](https://arxiv.org/pdf/2606.01802)。
* 2026.4.20:我们添加了 MOSS-Audio 的微调代码和文档。有关 LoRA 和全参数训练的示例,请参阅 `finetune/FINETUNE.md`。
* 2026.4.13:🎉🎉🎉 我们发布了 [MOSS-Audio](https://huggingface.co/collections/OpenMOSS-Team/moss-audio)。博客文章即将推出!
## 目录
- [简介](#introduction)
- [模型架构](#model-architecture)
- [DeepStack 跨层特征注入](#deepstack-cross-layer-feature-injection)
- [时间感知表示](#time-aware-representation)
- [已发布模型](#released-models)
- [评测](#evaluation)
- [快速开始](#quickstart)
- [环境配置](#environment-setup)
- [基本用法](#basic-usage)
- [微调](#fine-tuning)
- [Gradio 应用](#gradio-app)
- [SGLang 服务](#sglang-serving)
- [更多信息](#more-information)
- [引用](#citation)
## 简介
MOSS-Audio 是由 [MOSI.AI](https://mosi.cn/#hero)、[OpenMOSS 团队](https://www.open-moss.com/) 和 [上海创智学院](https://www.sii.edu.cn/) 联合开源的 **音频理解模型**。该模型针对复杂的真实世界音频进行了统一建模,支持 **语音理解、环境声音理解、音乐理解、音频字幕生成、时间感知问答和复杂推理**。在本次发布中,我们提供了 **四个模型**:**MOSS-Audio-4B-Instruct**、**MOSS-Audio-4B-Thinking**、**MOSS-Audio-8B-Instruct** 和 **MOSS-Audio-8B-Thinking**。Instruct 版本针对直接指令遵循进行了优化,而 Thinking 版本则提供了更强大的思维链(chain-of-thought)推理能力。
## 新闻
* 2026.6.1:我们在 arXiv 上发布了 [MOSS-Audio 技术报告](https://arxiv.org/pdf/2606.01802)。
* 2026.4.20:我们添加了 MOSS-Audio 的微调代码和文档。有关 LoRA 和全参数训练的示例,请参阅 `finetune/FINETUNE.md`。
* 2026.4.13:🎉🎉🎉 我们发布了 [MOSS-Audio](https://huggingface.co/collections/OpenMOSS-Team/moss-audio)。博客文章即将推出!
## 目录
- [简介](#introduction)
- [模型架构](#model-architecture)
- [DeepStack 跨层特征注入](#deepstack-cross-layer-feature-injection)
- [时间感知表示](#time-aware-representation)
- [已发布模型](#released-models)
- [评测](#evaluation)
- [快速开始](#quickstart)
- [环境配置](#environment-setup)
- [基本用法](#basic-usage)
- [微调](#fine-tuning)
- [Gradio 应用](#gradio-app)
- [SGLang 服务](#sglang-serving)
- [更多信息](#more-information)
- [引用](#citation)
## 简介
### 语音字幕生成 (LLM-as-a-Judge 得分↑)
### ASR
| 模型 | 总体 | 健康状况 | 方言 | 歌唱 | 非语音发声 | 语码转换 | 声学环境 (纯净) | 声学环境 (嘈杂) | 声学特征: 耳语 | 声学特征: 远场 / 近场 | 多说话人 | 年龄 | 语义内容 |
|---|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|
| Paraformer-Large | 15.77 | 22.18 | 43.45 | 32.34 | 4.95 | 12.65 | 3.11 | 4.67 | 5.02 | 17.46 | 20.33 | 14.96 | 7.14 |
| GLM-ASR-Nano | 17.29 | 24.49 | 22.39 | 51.95 | 4.65 | 11.88 | 3.68 | 5.02 | 4.94 | 27.51 | 28.02 | 17.19 | 7.32 |
| Fun-ASR-Nano | 12.04 | 21.99 | **7.80** | 19.35 | 4.76 | 11.23 | 2.98 | 3.46 | 3.78 | 18.38 | 19.82 | 14.95 | 6.08 |
| SenseVoice-Small | 14.50 | 24.04 | 8.89 | 23.79 | 4.92 | 13.90 | 4.13 | 4.93 | 5.57 | 26.66 | 24.06 | 17.63 | 7.55 |
| Kimi-Audio-7B-Instruct | 14.12 | 21.11 | 29.34 | 21.76 | 4.68 | 16.38 | **2.20** | **2.15** | 2.66 | 21.02 | 20.61 | 16.74 | 6.12 |
| Audio-Flamingo-Next | 30.19 | 36.13 | 25.85 | 25.80 | 8.25 | 34.53 | 8.64 | 38.85 | 12.84 | 42.90 | 62.13 | 38.30 | 30.18 |
| Qwen2.5-Omni-3B | 15.26 | 24.65 | 33.87 | 24.24 | 5.54 | 11.66 | 2.76 | 3.56 | 4.32 | 22.15 | 22.91 | 15.17 | 7.24 |
| Qwen2.5-Omni-7B | 15.05 | 23.85 | 31.91 | 22.69 | 4.56 | 12.97 | 2.52 | 3.16 | 3.64 | 25.38 | 21.01 | 16.13 | 6.78 |
| Qwen3-Omni-30B-A3B-Instruct | 11.39 | 20.73 | 15.63 | 16.01 | 4.73 | 11.30 | 2.23 | 2.47 | **1.90** | **17.08** | **18.15** | **11.46** | **5.74** |
| **MOSS-Audio-4B-Instruct** | 11.58 | 21.11 | 11.84 | 10.79 | **4.01** | **10.11** | 3.11 | 3.72 | 3.29 | 18.48 | 20.33 | 15.09 | 8.15 |
| **MOSS-Audio-8B-Instruct** | **11.30** | **19.18** | 8.76 | **9.81** | 4.31 | 10.18 | 2.70 | 3.20 | 2.75 | 24.04 | 24.36 | 15.26 | 7.69 |
### 时间戳 ASR (AAS↓)
| 模型 | AISHELL-1(zh) | LibriSpeech(en) |
|---|---:|---:|
| Audio-Flamingo-Next | -- | 211.15 |
| Qwen3-Omni-30B-A3B-Instruct | 833.66 | 646.95 |
| Gemini-3.1-Pro| 708.24 | 871.19 |
| MOSS-Audio-4B-Instruct | 76.96 | 358.13 |
| **MOSS-Audio-8B-Instruct** | **35.77** | **131.61** |
## 快速开始
### 环境配置
我们推荐使用 Python 3.12 和干净的 Conda 环境。以下命令足以进行本地推理。
#### 推荐设置
```
git clone https://github.com/OpenMOSS/MOSS-Audio.git
cd MOSS-Audio
conda create -n moss-audio python=3.12 -y
conda activate moss-audio
conda install -c conda-forge "ffmpeg=7" -y
pip install --extra-index-url https://download.pytorch.org/whl/cu128 -e ".[torch-runtime]"
```
#### 可选:FlashAttention 2
如果你的 GPU 支持 FlashAttention 2,你可以将最后一条安装命令替换为:
```
pip install --extra-index-url https://download.pytorch.org/whl/cu128 -e ".[torch-runtime,flash-attn]"
```
### 基本用法
首先下载模型:
```
hf download OpenMOSS-Team/MOSS-Audio-4B-Instruct --local-dir ./weights/MOSS-Audio-4B-Instruct
hf download OpenMOSS-Team/MOSS-Audio-4B-Thinking --local-dir ./weights/MOSS-Audio-4B-Thinking
hf download OpenMOSS-Team/MOSS-Audio-8B-Instruct --local-dir ./weights/MOSS-Audio-8B-Instruct
hf download OpenMOSS-Team/MOSS-Audio-8B-Thinking --local-dir ./weights/MOSS-Audio-8B-Thinking
```
然后根据需要编辑 `infer.py` 中的 `MODEL_PATH` / `AUDIO_PATH`,并运行:
```
python infer.py
```
`infer.py` 中的默认提示词是 `Describe this audio.`。如果你想尝试转录、音频问答或语音字幕生成,可以直接编辑那一行。
### 微调
我们现在在 `etune/finetune.py` 中提供了官方的微调脚本,并在 `finetune/FINETUNE.md` 中提供了完整的说明。
安装训练所需的额外依赖项:
```
pip install librosa peft
```
LoRA 微调的最小示例:
```
accelerate launch finetune/finetune.py \
--model_dir ./weights/MOSS-Audio-4B-Instruct \
--data_path train.jsonl \
--output_dir ./output/lora \
--use_lora \
--bf16
```
训练数据应为包含音频-文本对话的 JSONL 文件。有关数据格式、支持的参数、多 GPU 示例和全参数微调,请参阅 `finetune/FINETUNE.md`。
### Gradio 应用
使用以下命令启动 Gradio demo:
```
python app.py
```
### SGLang 服务
如果你想使用 SGLang 为 MOSS-Audio 提供服务,请参阅 `moss_audio_usage_guide.md` 中的完整指南。
最简设置如下:
```
git clone -b moss-audio https://github.com/OpenMOSS/sglang.git
cd sglang
pip install -e "python[all]"
pip install nvidia-cudnn-cu12==9.16.0.29
cd ..
sglang serve --model-path ./weights/MOSS-Audio --trust-remote-code
```
如果你使用默认的 `torch==2.9.1+cu128` 运行时,建议在启动 `sglang serve` 之前安装 `nvidia-cudnn-cu12==9.16.0.29`。
## 更多信息
- **MOSI.AI**: [https://mosi.cn](https://mosi.cn)
- **OpenMOSS**: [https://www.open-moss.com](https://www.open-moss.com)
## LICENSE
MOSS-Audio 中的模型均在 Apache License 2.0 许可下发布。
## 引用
```
@misc{yang2026mossaudiotechnicalreport,
title={MOSS-Audio Technical Report},
author={Chen Yang and Chufan Yu and Hanfu Chen and Jie Zhu and Jingqi Chen and Ke Chen and Wenxuan Wang and Yang Wang and Yaozhou Jiang and Yi Jiang and Zhengyuan Lin and Ziqi Chen and Zhaoye Fei and Chenghao Liu and Jun Zhan and Kang Yu and Kexin Huang and Mingshu Chen and Qinyuan Cheng and Ruixiao Li and Shimin Li and Songlin Wang and Yang Gao and Yiyang Zhang and Xipeng Qiu},
year={2026},
eprint={2606.01802},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2606.01802},
}
```
## Star History
[](https://www.star-history.com/#OpenMOSS/MOSS-Audio&type=date&legend=top-left)



| 模型 | 模型大小 | MMAU | MMAU-Pro | MMAR | MMSU | 平均 |
|---|---|---|---|---|---|---|
| 开源 (小) | ||||||
| Kimi-Audio | 7B | 72.41 | 56.58 | 60.82 | 54.74 | 61.14 |
| Qwen2.5-Omni | 7B | 65.60 | 52.20 | 56.70 | 61.32 | 58.96 |
| Audio Flamingo 3 | 7B | 61.23 | 51.70 | 57.96 | 60.04 | 57.73 |
| Audio Flamingo Next | 8B | 76.10 | 56.34 | 51.01 | 57.20 | 60.16 |
| MiMo-Audio-7B | 7B | 74.90 | 53.35 | 61.70 | 61.94 | 62.97 |
| MiniCPM-o-4.5 | 9B | 70.97 | 39.65 | 55.75 | 60.96 | 56.83 |
| MOSS-Audio-4B-Instruct | 4B | 75.79 | 58.16 | 62.54 | 59.68 | 64.04 |
| MOSS-Audio-4B-Thinking | 4B | 77.64 | 60.75 | 63.91 | 71.20 | 68.37 |
| MOSS-Audio-8B-Instruct | 8B | 77.03 | 57.48 | 64.42 | 66.36 | 66.32 |
| MOSS-Audio-8B-Thinking | 8B | 77.33 | 64.92 | 66.53 | 75.52 | 71.08 |
| 开源 (大) | ||||||
| Qwen3-Omni-30B-A3B-Instruct | 30B | 75.00 | 61.22 | 66.40 | 69.00 | 67.91 |
| Step-Audio-R1.1 | 33B | 72.18 | 60.80 | 68.75 | 64.18 | 66.48 |
| Step-Audio-R1 | 33B | 7867 | 59.68 | 69.15 | 75.18 | 70.67 |
| 闭源 | ||||||
| GPT4o-Audio | - | 65.66 | 52.30 | 59.78 | 58.76 | 59.13 |
| Gemini-3-Pro | - | 80.15 | 68.28 | 81.73 | 81.28 | 77.86 |
| Gemini-3.1-Pro | - | 81.10 | 73.47 | 83.70 | 81.30 | 79.89 |
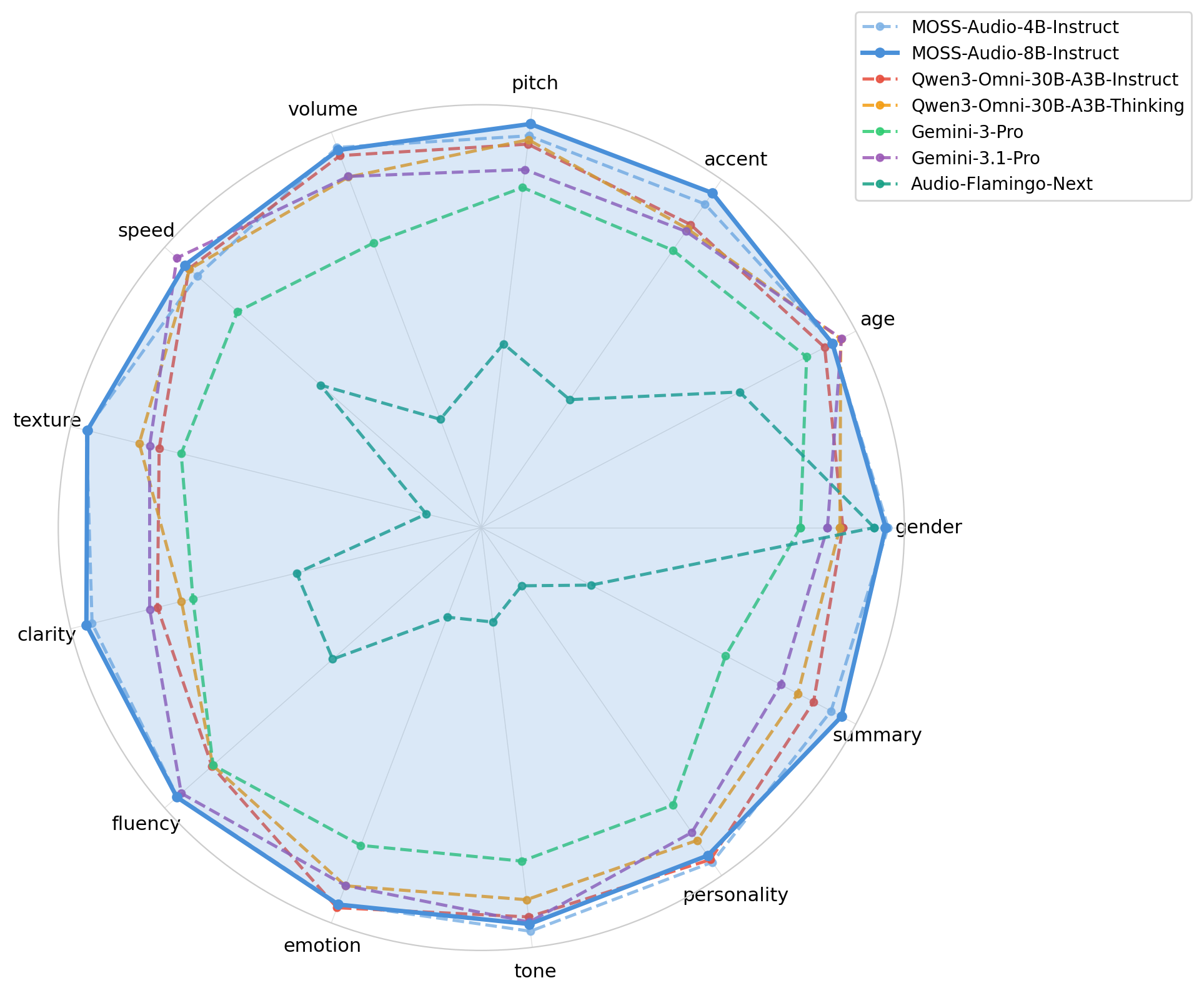
语音字幕生成 (点击展开)
| 模型 | 性别 | 年龄 | 口音 | 音高 | 音量 | 语速 | 质感 | 清晰度 | 流畅度 | 情绪 | 语调 | 个性 | 摘要 | 平均 | |---|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:| | Audio-Flamingo-Next | 4.617 | 3.461 | 3.160 | 2.679 | 2.391 | 2.818 | 1.941 | 2.839 | 2.788 | 2.056 | 2.025 | 1.940 | 2.157 | 2.6825 | | Qwen3-Omni-30B-A3B-Instruct | 4.436 | 3.936 | 4.356 | 3.590 | 3.682 | 3.614 | 3.093 | 3.521 | 3.531 | **3.328** | 3.224 | 3.292 | 3.179 | 3.5986 | | Qwen3-Omni-30B-A3B-Thinking | 4.419 | 4.026 | 4.327 | 3.610 | 3.577 | 3.610 | 3.179 | 3.403 | 3.526 | 3.232 | 3.154 | 3.197 | 3.107 | 3.5667 | | Gemini-3-Pro | 4.191 | 3.835 | 4.181 | 3.392 | 3.254 | 3.320 | 2.998 | 3.347 | 3.524 | 3.055 | 2.997 | 3.023 | 2.775 | 3.3763 | | Gemini-3.1-Pro | 4.347 | **4.030** | 4.310 | 3.474 | 3.580 | **3.687** | 3.134 | 3.559 | 3.720 | 3.231 | 3.245 | 3.158 | 3.028 | 3.5772 | | MOSS-Audio-4B-Instruct | **4.697** | 3.980 | 4.497 | 3.628 | **3.722** | 3.564 | **3.407** | 3.841 | 3.744 | 3.311 | **3.282** | **3.305** | 3.259 | 3.7105 | | MOSS-Audio-8B-Instruct | 4.683 | 3.979 | **4.572** | **3.682** | 3.709 | 3.638 | 3.403 | **3.869** | **3.747** | 3.314 | 3.253 | 3.272 | **3.307** | **3.7252** |详细 ASR 结果 (点击展开)
| 模型 | 声学环境 (纯净) | 声学环境 (嘈杂) | 声学特征: 耳语 | 声学特征: 远场 / 近场 | 多说话人 | 年龄 | 健康状况 | 语义内容 | 语码转换 | 方言 | 歌唱 | 非语音发声 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AISHELL-1 test |
AISHELL-2 Android | IOS | Mic |
THCHS-30 test |
MAGICDATA-READ test |
AISHELL6-Whisper normal | whisper |
AliMeeting Test_Ali_far | Test_Ali_near |
AISHELL-4 test |
SeniorTalk sentence |
ChildMandarin test |
AISHELL-6A mild | moderate | severe | StutteringSpeech |
AISHELL_6B LRDWWS | Uncontrol |
WenetSpeech test-meeting |
Fleurs cmn_hans_cn |
CS-Dialogue test |
TALCS test |
ASCEND test |
KeSpeech test |
WSYue-ASR-eval short |
MIR-1K test |
openc-pop test |
MNV_17 | |
| Paraformer-Large | 1.98 | 3.28 | 3.21 | 3.00 | 4.07 | 4.67 | 1.11 | 8.92 | 25.64 | 9.27 | 20.33 | 17.31 | 12.60 | 6.98 | 9.30 | 13.34 | 10.74 | 47.59 | 45.08 | 7.88 | 6.40 | 10.64 | 10.77 | 16.55 | 11.48 | 75.42 | 57.70 | 6.98 | 4.95 |
| GLM-ASR-Nano | 2.89 | 3.75 | 3.73 | 3.78 | 5.02 | 0.83 | 9.06 | 40.27 | 14.76 | 28.02 | 20.33 | 14.06 | 8.74 | 12.11 | 14.38 | 12.29 | 50.34 | 49.09 | 9.70 | 4.94 | 11.06 | 11.07 | 13.50 | 9.72 | 35.07 | 95.87 | 8.03 | 4.65 | |
| Fun-ASR-Nano | 2.16 | 3.04 | 2.99 | 3.07 | 3.65 | 3.46 | 0.81 | 6.76 | 27.21 | 9.55 | 19.82 | 16.96 | 12.94 | 6.60 | 8.81 | 12.98 | 10.30 | 47.42 | 45.84 | 7.39 | 4.76 | 10.47 | 8.09 | 15.13 | 7.43 | 8.17 | 35.85 | 2.84 | 4.76 |
| SenseVoice-Small | 3.23 | 4.16 | 4.02 | 3.96 | 5.26 | 4.93 | 1.25 | 9.88 | 37.01 | 16.31 | 24.06 | 21.07 | 14.18 | 7.62 | 9.85 | 14.39 | 11.47 | 52.92 | 47.97 | 8.35 | 6.75 | 12.81 | 10.52 | 18.38 | 10.45 | 7.34 | 39.51 | 8.07 | 4.92 |
| Kimi-Audio-7B-Instruct | 0.79 | 2.91 | 3.03 | 2.88 | 1.39 | 2.15 | 0.69 | 4.63 | 28.22 | 13.82 | 20.61 | 19.70 | 13.79 | 7.00 | 9.34 | 12.56 | 10.75 | 44.44 | 42.57 | 7.15 | 5.10 | 14.56 | 12.74 | 21.83 | 5.51 | 53.17 | 38.35 | 5.17 | 4.68 |
| Audio Flamingo Next | 6.85 | 7.22 | 8.12 | 8.62 | 12.41 | 6.24 | 6.48 | 19.20 | 60.68 | 25.12 | 62.13 | 39.44 | 23.06 | 24.13 | 29.40 | 35.69 | 21.90 | 56.17 | 49.52 | 54.46 | 12.86 | 30.52 | 40.42 | 32.63 | 16.97 | 34.74 | 40.06 | 11.54 | 8.25 |
| Qwen2.5-Omni-3B | 1.51 | 3.10 | 2.94 | 2.93 | 3.32 | 3.56 | 0.82 | 7.82 | 32.14 | 12.16 | 22.91 | 17.38 | 12.96 | 6.87 | 10.55 | 14.57 | 11.33 | 54.54 | 50.03 | 9.04 | 5.45 | 10.78 | 10.94 | 13.25 | 7.67 | 60.06 | 45.00 | 3.47 | 5.54 |
| Qwen2.5-Omni-7B | 1.16 | 2.88 | 2.77 | 2.73 | 3.06 | 3.16 | 0.71 | 6.57 | 32.03 | 18.73 | 21.01 | 19.96 | 12.29 | 7.27 | 10.94 | 12.92 | 10.53 | 51.99 | 49.45 | 8.43 | 5.13 | 14.02 | 10.46 | 14.42 | 6.40 | 57.43 | 42.62 | 2.75 | 4.56 |
| Qwen3-Omni-30B-A3B-Instruct | 0.95 | 2.70 | 2.72 | 2.57 | 2.21 | 2.47 | 0.59 | 3.22 | 25.72 | 8.44 | 18.15 | 14.13 | 8.79 | 6.20 | 8.88 | 11.59 | 10.25 | 45.80 | 41.65 | 6.64 | 4.84 | 12.94 | 8.33 | 12.64 | 5.87 | 25.39 | 30.81 | 1.21 | 4.73 |
| MOSS-Audio-4B-Instruct | 2.26 | 3.22 | 3.20 | 3.33 | 3.53 | 3.72 | 0.73 | 5.86 | 27.27 | 9.68 | 20.33 | 16.93 | 13.25 | 6.36 | 9.77 | 12.68 | 10.28 | 43.35 | 44.25 | 8.17 | 8.13 | 9.14 | 8.37 | 12.83 | 14.65 | 9.04 | 18.47 | 3.10 | 4.01 |
| MOSS-Audio-8B-Instruct | 1.82 | 2.97 | 2.95 | 2.91 | 2.82 | 3.20 | 0.69 | 4.80 | 36.82 | 11.25 | 24.36 | 17.42 | 13.10 | 5.84 | 8.94 | 11.52 | 9.72 | 39.76 | 39.27 | 7.86 | 7.52 | 9.07 | 8.22 | 13.26 | 9.18 | 8.33 | 17.24 | 2.39 | 4.31 |
标签:DLL 劫持, 人工智能, 凭据扫描, 多模态模型, 大语言模型, 开源模型, 用户模式Hook绕过, 语音识别, 逆向工具, 音频处理