SiminFahimi/Breast-Cancer-Classifier-From-Scratch
GitHub: SiminFahimi/Breast-Cancer-Classifier-From-Scratch
使用纯 NumPy 从零实现前馈神经网络进行乳腺癌分类,旨在帮助理解深度学习底层原理。
Stars: 0 | Forks: 0
# 从零开始的神经网络 (NumPy)
一个完全使用 Python 和 NumPy 实现的全连接前馈神经网络——不依赖 PyTorch 或 TensorFlow 等深度学习框架。
本项目旨在通过从基本原理实现每个组件(前向传播、反向传播、优化和评估),为您提供对神经网络深入且动手实践的理解。
## 核心特性
- **纯 NumPy 实现**(不使用 ML 框架)
- 从零开始的前向和反向传播
- Mini-batch 梯度下降
- 二元交叉熵损失
- L2 正则化(权重衰减)
- **He 初始化**(隐藏层)和 **Xavier 初始化**(输出层)
- 数值梯度检查(有限差分)
- K 折交叉验证
- 自动超参数搜索(学习率和正则化强度)
- 特征工程(多项式扩展 + 皮尔逊相关系数选择)
- 用于训练动态和实验的可视化工具
## 项目结构
```
.
├── main.py # Entry point — runs full pipeline
├── model.py # Neural network implementation (forward, backward, training)
├── build_network.py # Model construction and configuration
├── data.py # Data loading, preprocessing, feature engineering
├── eval.py # Cross-validation and hyperparameter tuning
├── plots.py # Visualization utilities
├── utils.py # Activation functions and derivatives
├── results/
│ ├── loss.png
│ ├── lr_effect.png
│ ├── lambda_effect.png
│ ├── size_effect_on_accuracy.png
│ └── size_effect_on_cost.png
└── README.md
```
## 数据集
- **Breast Cancer Wisconsin (Original) 数据集**(UCI ID: 15)
- 二元分类:
- 恶性 → `1`
- 良性 → `0`
- 缺失值使用列中位数进行插补
- ID 列(`Sample_code_number`)已被移除
- 数据划分:**80% 训练 / 20% 测试**
## 模型架构
输入层 (n 个特征)
↓ 隐藏层 1:16 个单元,ReLU
↓ 隐藏层 2:8 个单元,ReLU
↓ 输出层:1 个单元,Sigmoid
text
所有架构选择(层大小、激活函数、正则化)均可通过 `build_network.py` 进行配置。
## 特征工程
基于**皮尔逊相关系数**的可选特征增强:
- 选择与目标变量最相关的前 **2 个特征**
- 将它们的平方值 (\(x^2\)) 附加到输入中
### 性能对比
| 输入类型 | 测试准确率 |
|----------------------|---------------|
| 原始特征 | 0.9587 |
| 工程特征 | 0.9663 |
提升是稳定的,尽管幅度不大。
## 梯度检查
使用**有限差分**验证反向传播的正确性:
$$
\frac{\partial J}{\partial \theta} \approx \frac{J(\theta + \varepsilon) - J(\theta - \varepsilon)}{2\varepsilon}
$$
- 检查每层的 **10 个随机参数**
- 在**第一个 epoch** 期间执行
- 通过在 `model.fit(...)` 中设置 `debug=True` 来启用
## 超参数调优
### 搜索空间
- **学习率:** `(0.005, 0.01, 0.02, 0.05, 0.1, 0.5)`
- **L2 正则化 (\(\lambda\)):** `(0, 0.002, 0.005, ..., 10.24)`
### 方法
- **3 折交叉验证**
- 基于**最小验证损失**进行选择
## 实验与结果
本项目包含多项实验分析:
- 每个 epoch 的训练损失
- 数据集大小对性能的影响
- 正则化强度 (\(\lambda\)) 的影响
- 学习率敏感度
*(见 `results/` 目录中的图像)*
## 实验与结果
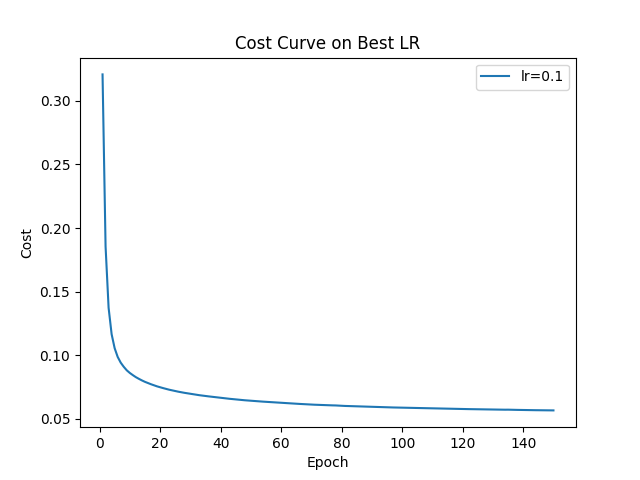
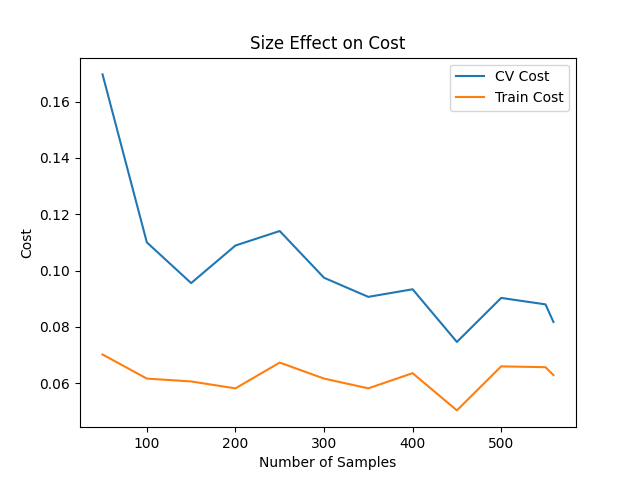
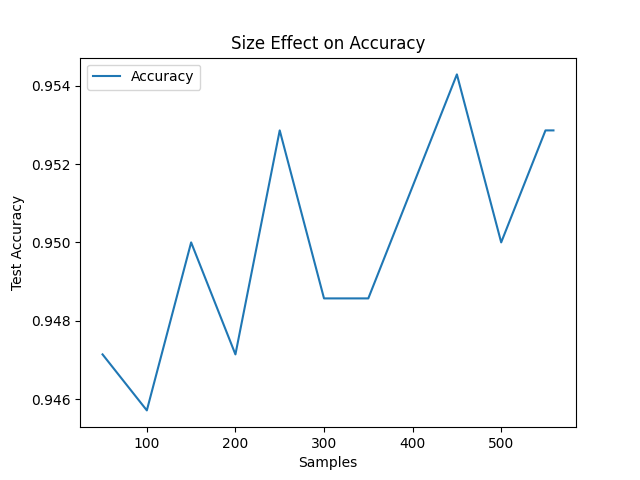
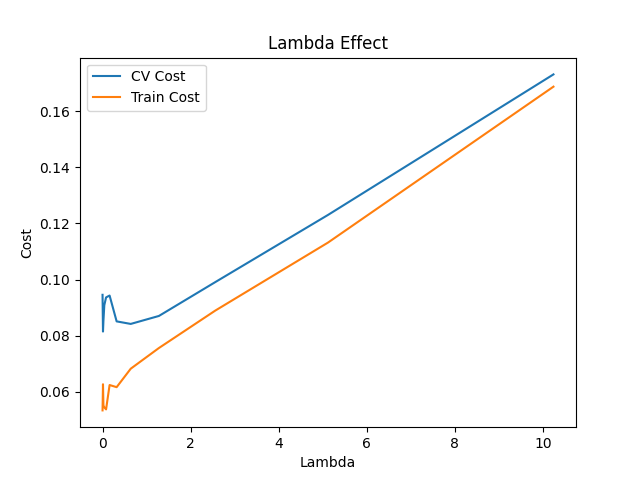
## 安装与使用
```
pip install -r requirements.txt
python main.py
```
## 可能的扩展
- Adam / RMSProp 优化器
- 多类分类(softmax 输出)
- Dropout 正则化
- Early stopping
- PyTorch 重新实现以进行基准测试
- 更高级的特征选择方法
## 注意事项
- 完全使用 NumPy 构建,以确保清晰度和教育价值
- 偏置单元在前向传播期间添加(不单独存储)
- L2 正则化不包括偏置权重(标准做法)
标签:Apex, NumPy, 二分类, 医疗AI, 机器学习, 深度学习, 神经网络, 逆向工具