saurabhchaudhary05/NLP-Log-Classifier
GitHub: saurabhchaudhary05/NLP-Log-Classifier
一个基于级联 NLP 与机器学习的可解释日志分类系统,旨在以低延迟、低成本处理大规模日志并输出可信分类结果。
Stars: 0 | Forks: 0
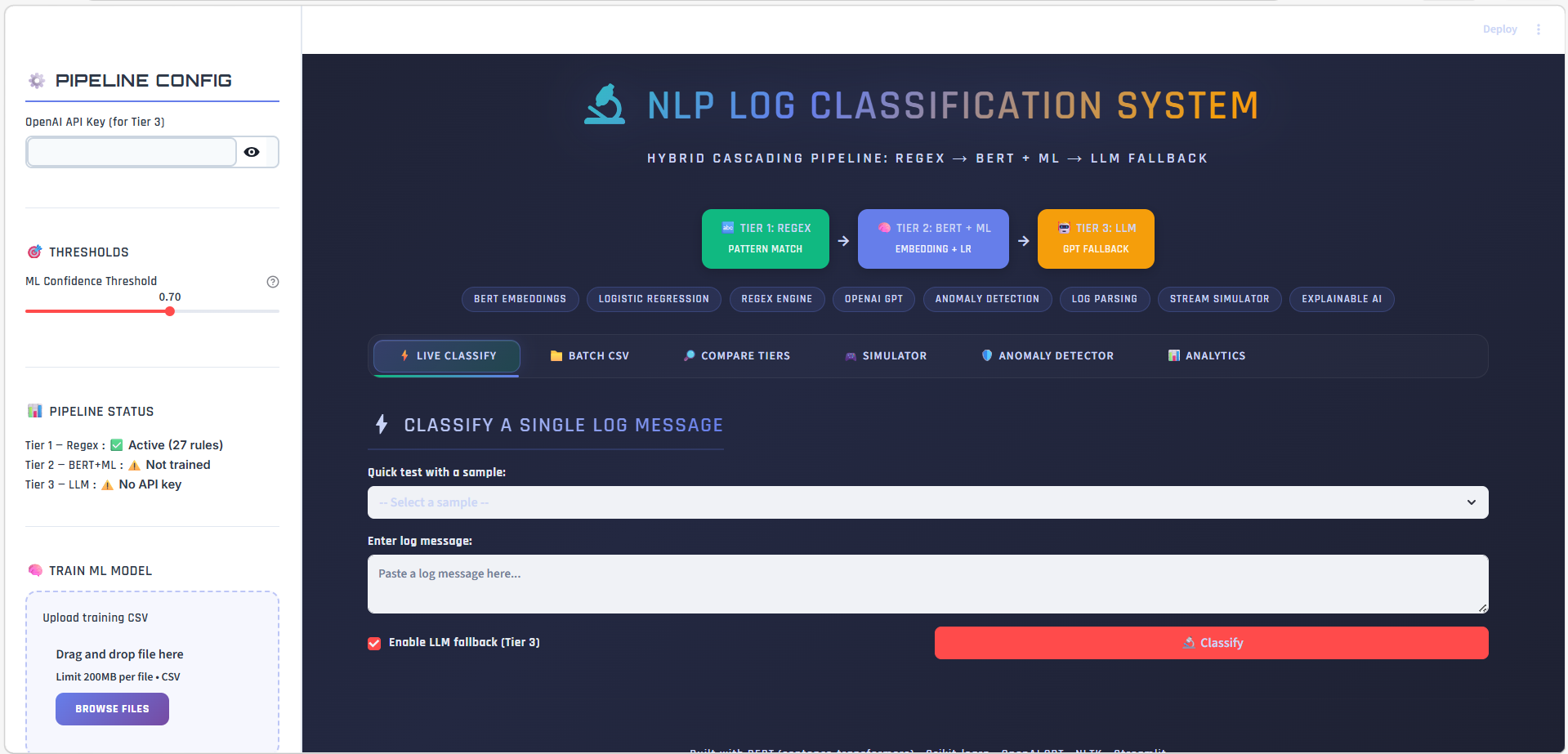
# 🔬 基于NLP的日志分类系统
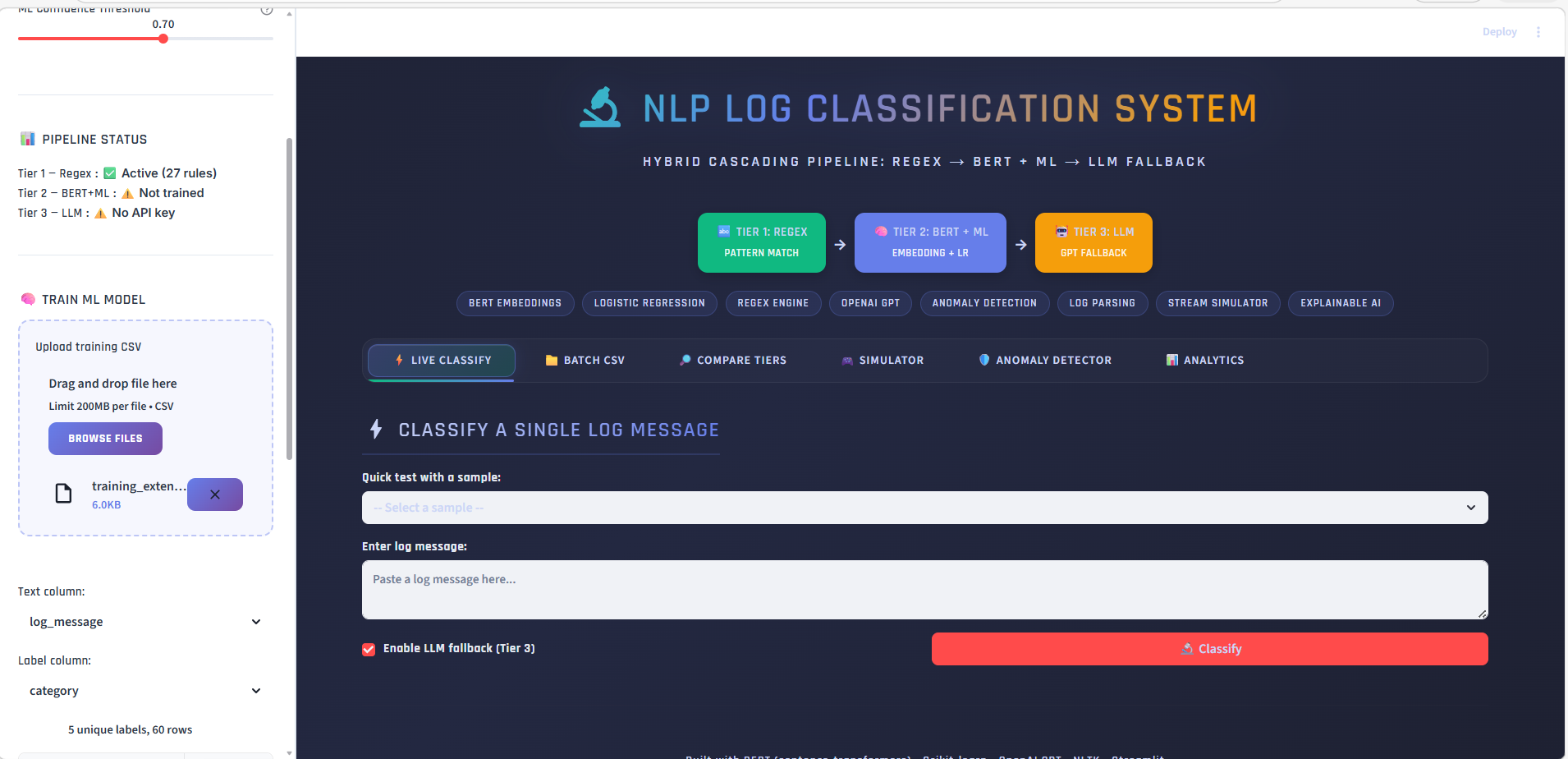
**一个智能、可解释的日志分诊系统,将每条日志依次通过正则 → BERT+ML → LLM 处理,在无需 LLM 成本的情况下解决 90%+ 的日志,且不遗漏任何日志。**






 |
| 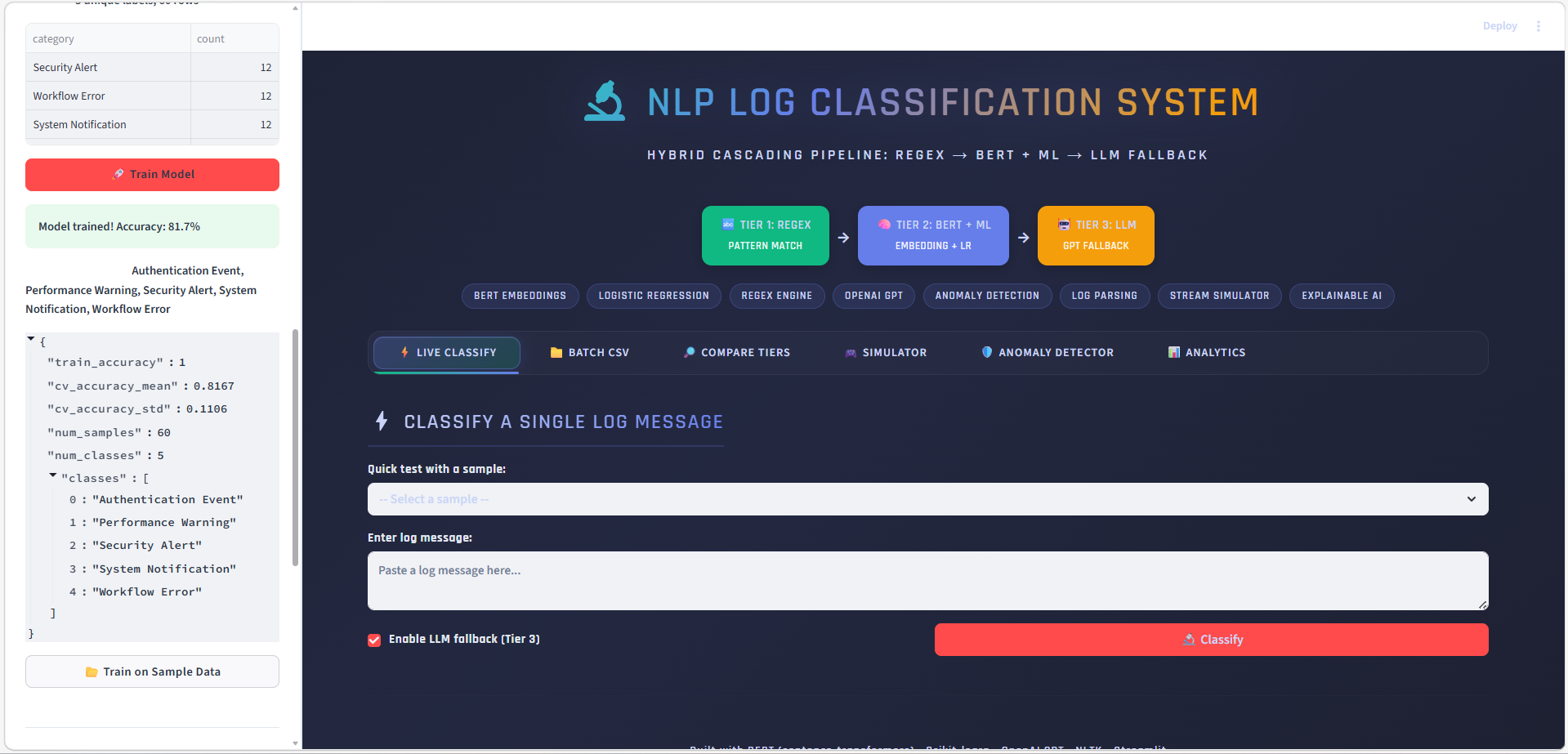 |
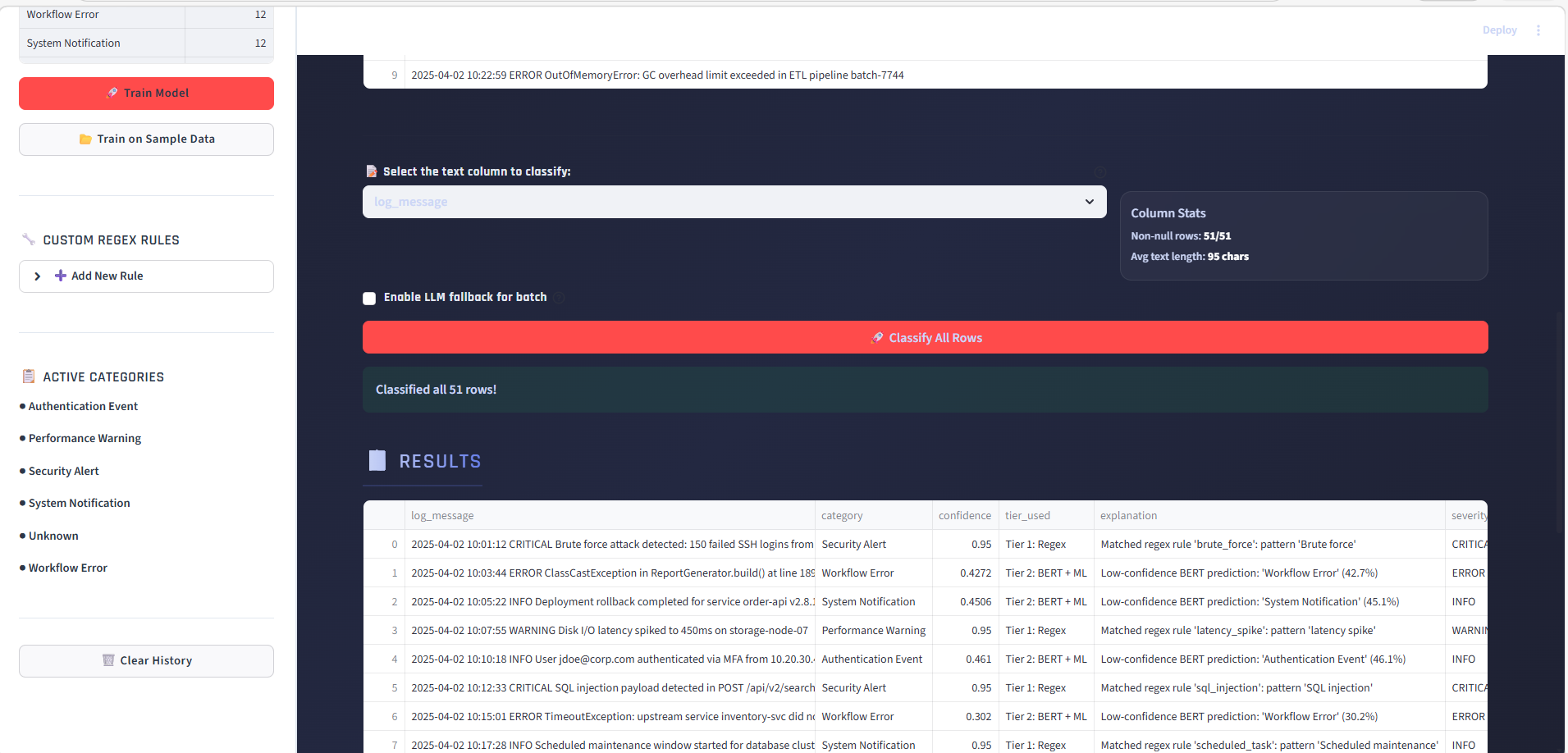
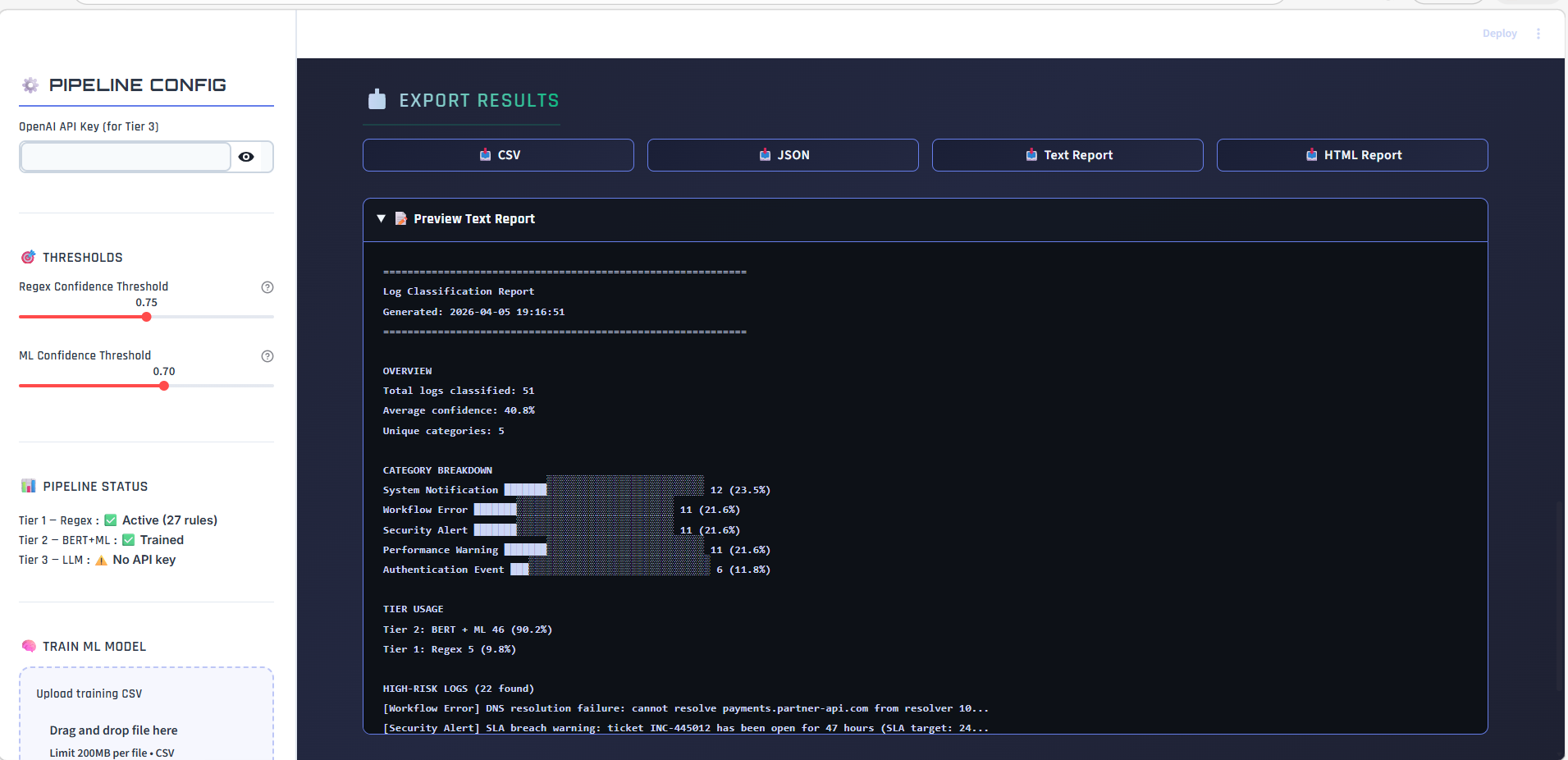
### 批量 CSV 分类
上传包含日志消息的 CSV,选择文本列,并一键分类所有行。
|
### 批量 CSV 分类
上传包含日志消息的 CSV,选择文本列,并一键分类所有行。
 |
| 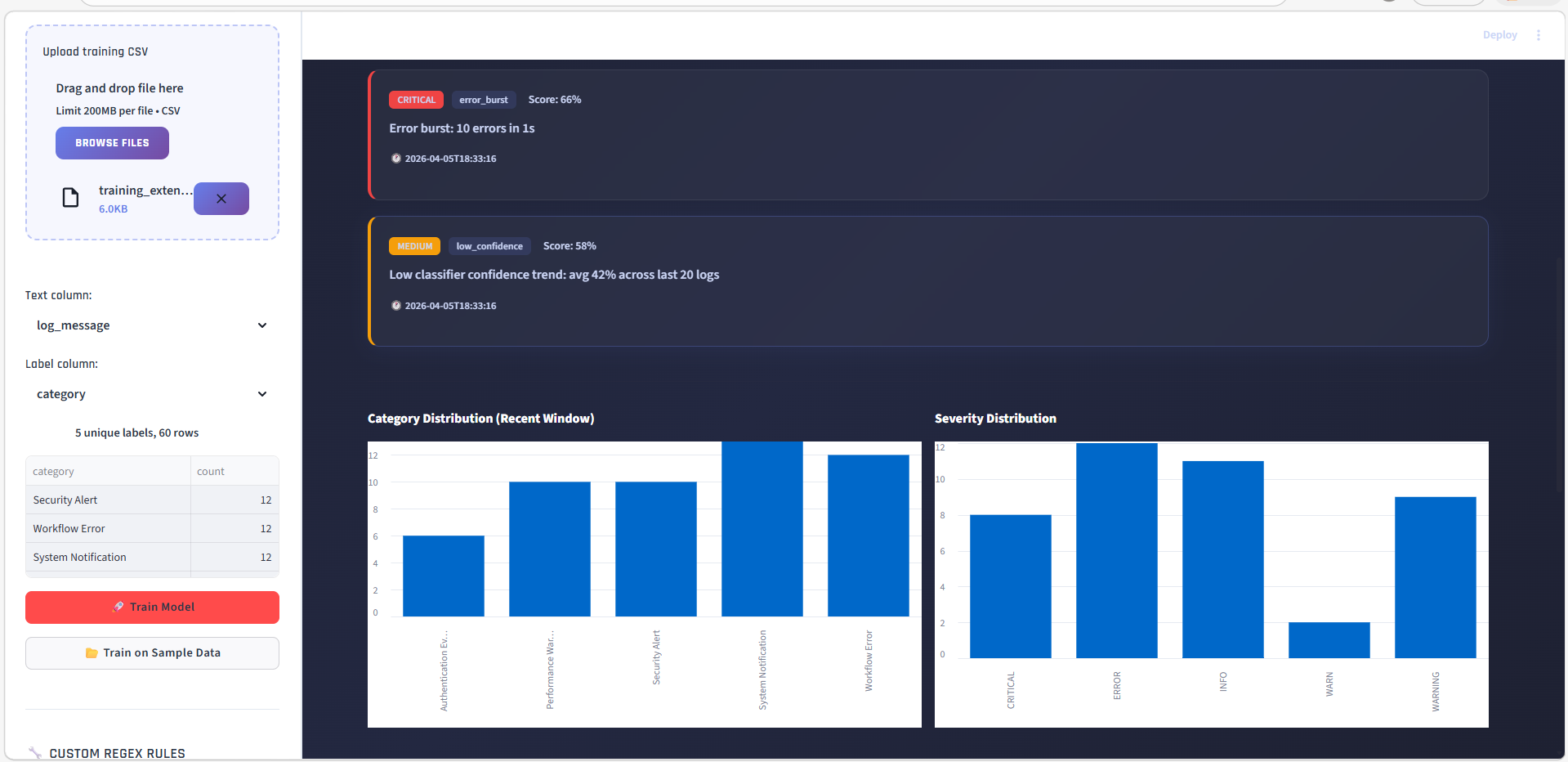 |
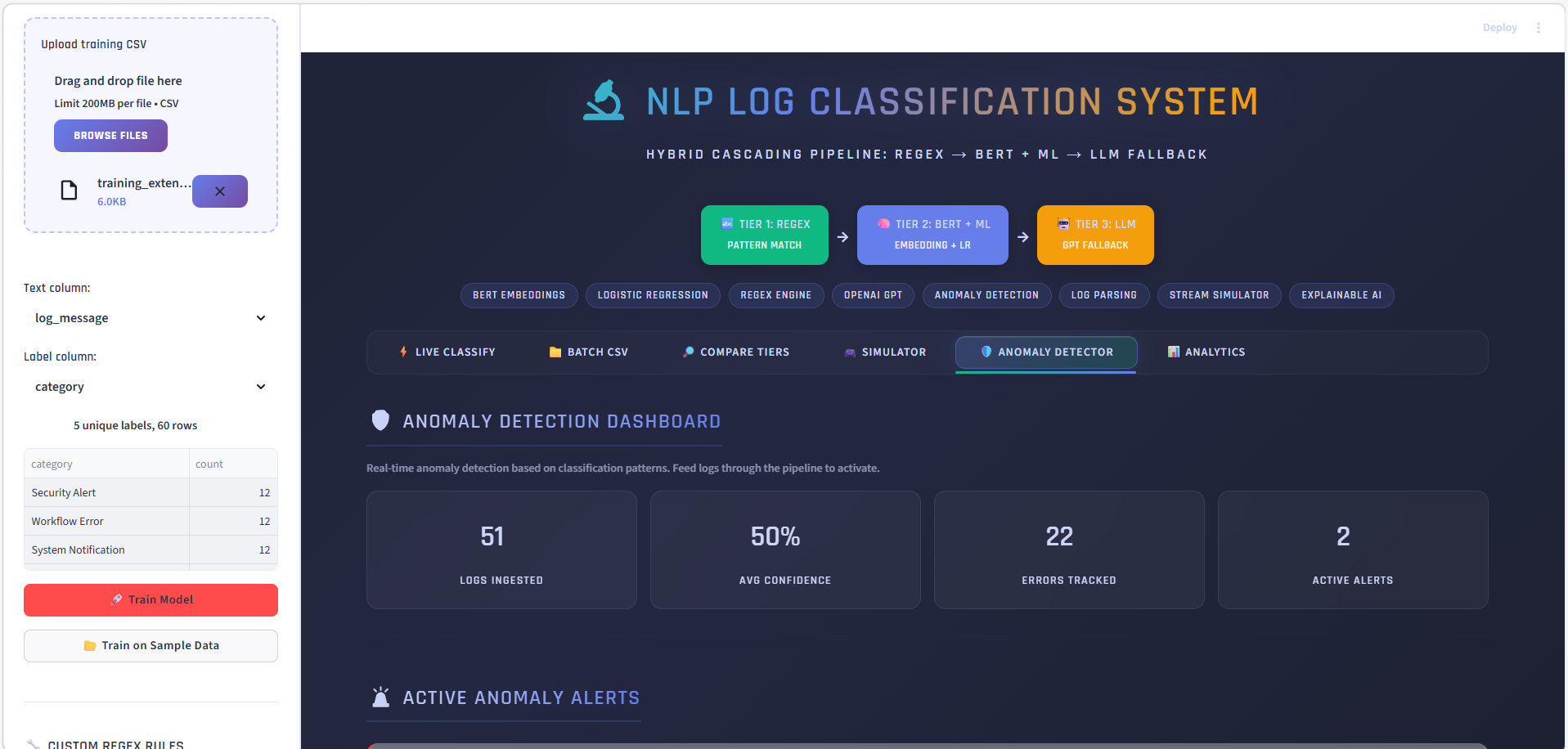
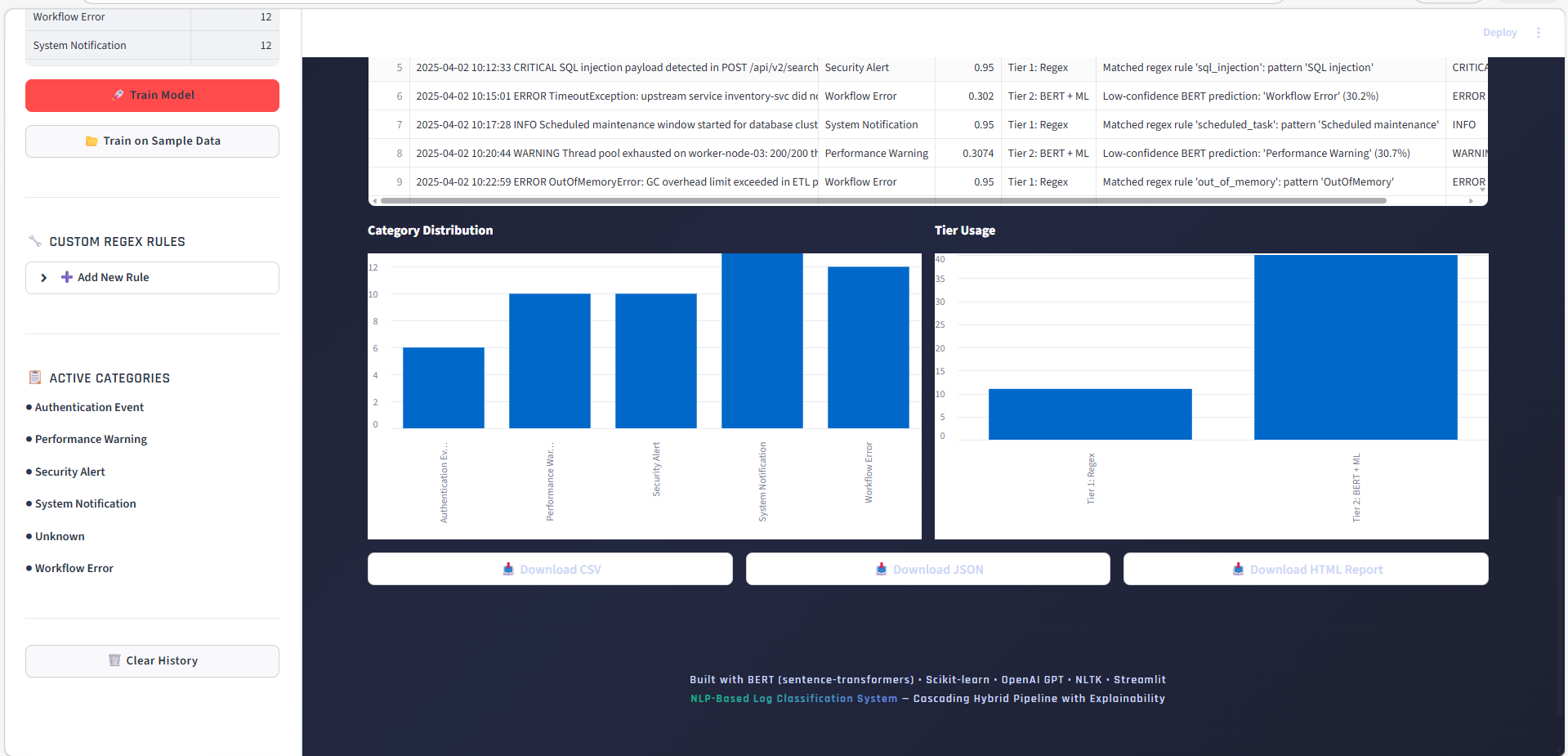
### 分析 — 分类方法占比
查看各层级(正则 vs BERT+ML vs LLM)解决了多少百分比的日志。
|
### 分析 — 分类方法占比
查看各层级(正则 vs BERT+ML vs LLM)解决了多少百分比的日志。
| |
### 批量 CSV 分类
上传包含日志消息的 CSV,选择文本列,并一键分类所有行。
| |
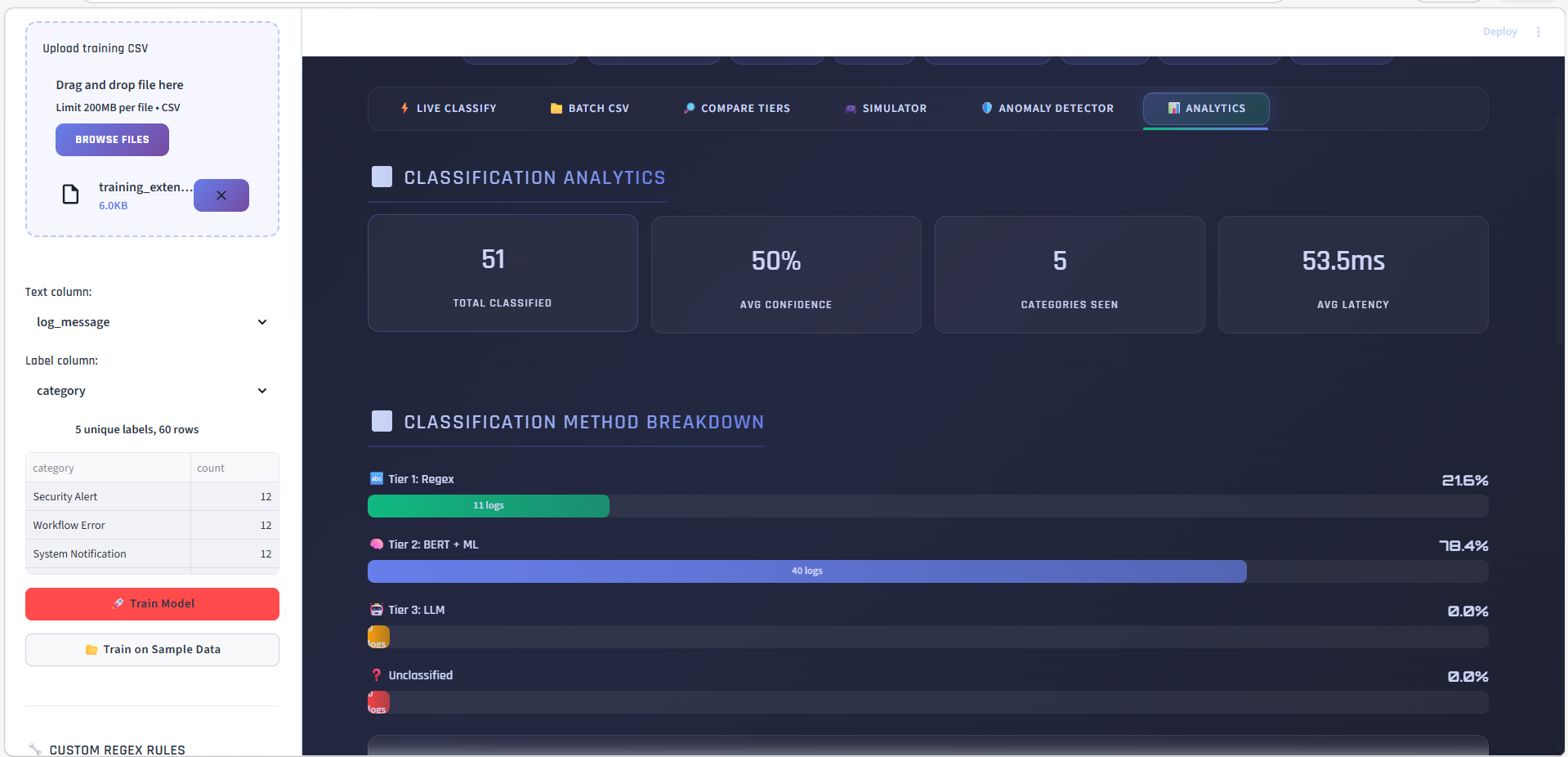
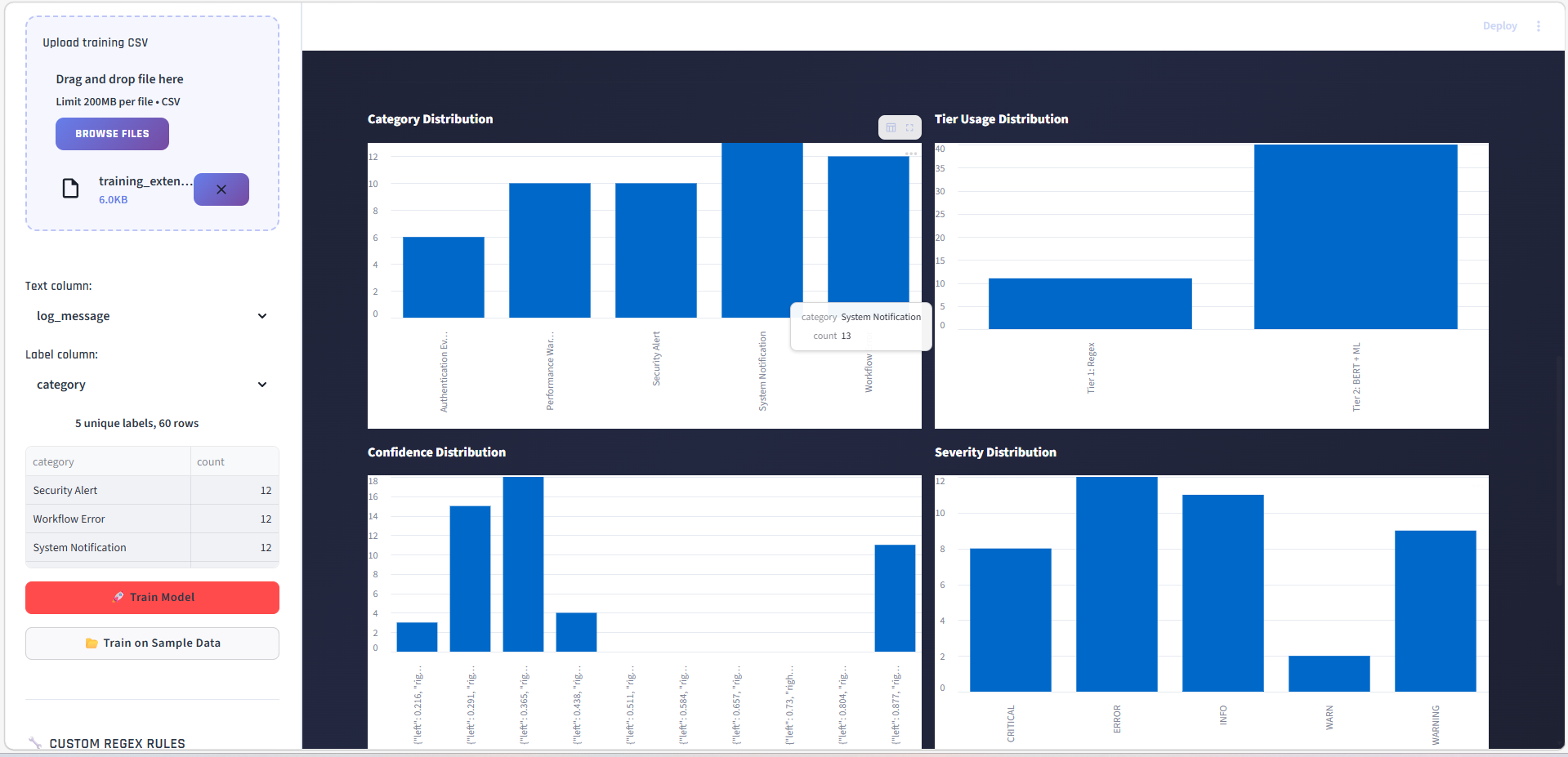
### 分析 — 分类方法占比
查看各层级(正则 vs BERT+ML vs LLM)解决了多少百分比的日志。
标签:AI分级, Apex, BERT, Kubernetes, LLM, NLP日志分析, OpenAI GPT-4o, Python, Scikit-learn, sentence-transformers, Streamlit仪表盘, Unmanaged PE, 可解释性, 实时分析, 异常检测, 性能监控, 无后门, 无日志未分类, 日志分流, 日志分类, 日志告警, 日志解析, 机器学习, 流处理, 混合级联管道, 生产级, 系统日志, 自动化分类, 证书伪造, 逆向工具, 降本增效, 高置信度路由