chasebarrett/scarpa-rag-agent
GitHub: chasebarrett/scarpa-rag-agent
基于 ChatGPT Agent Builder 构建的 RAG 学习项目,通过类别分片向量数据库、双端护栏和查询分类六阶段工作流,演示检索增强生成 agent 的完整架构设计。
Stars: 0 | Forks: 0
# SCARPA RAG Agent
**学习项目 | Retrieval-Augmented Generation | ChatGPT Agent Builder**
一个实操学习项目:一个基于 **ChatGPT 的 Agent Builder** 构建的 **RAG (Retrieval-Augmented Generation)** agent,能够用自然语言回答有关 SCARPA 鞋类产品线的问题。
目标是通过亲自动手构建并观察其运行情况,而不是仅仅阅读相关文章,来真正理解 agent 工作流的实际行为——包括 **RAG、prompt 分类和 guardrails**。
## 目录
- [我构建了什么](#-what-i-built)
- [我的收获](#-what-i-took-away)
- [为什么在此止步](#-why-i-stopped-here)
- [技术栈](#-stack)
- [代码库](#-repository)
- [免责声明](#-disclaimer)
## 🧱 我构建了什么
我使用 ChatGPT 的 Agent Builder 设计并测试了一个六阶段的工作流:
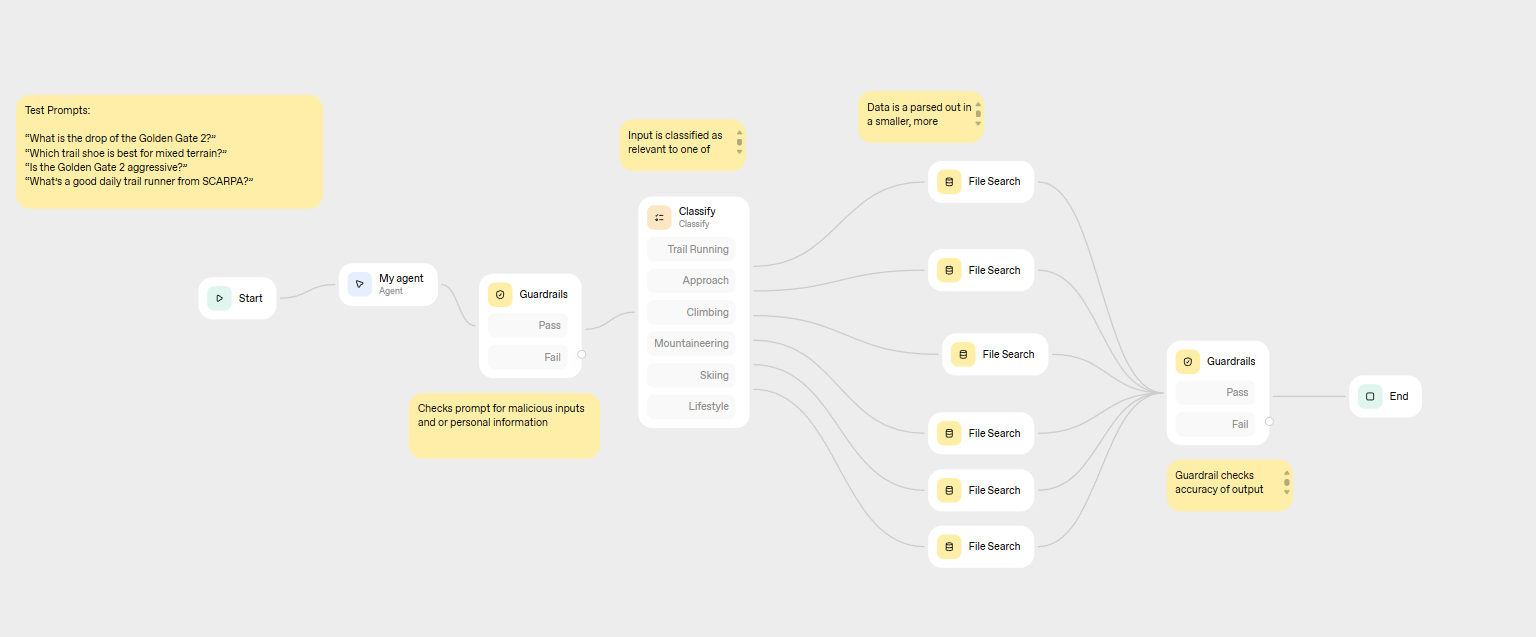
该 agent 接收一个自然语言问题,将其通过输入 guardrail 进行路由,分类到六个产品类别之一,查询特定类别的 vector database,运行输出 guardrail 检查,最后返回答案。
概念层面如下:

| 步骤 | 组件 | 功能描述 |
|------|-----------|--------------|
| 1 | Prompt 输入 | 用户提交一个自然语言问题 |
| 2 | 输入 guardrail | 筛查 PII、越狱尝试和 prompt injection |
| 3 | 分类器 | 将 prompt 路由到六个产品类别之一 |
| 4 | Vector DB 搜索 | 查询特定类别的数据库 |
| 5 | 输出 guardrail | 检查答案对检索数据的忠实度 |
| 6 | 交付 | 将验证后的响应返回给用户 |
SCARPA 的产品目录被转换为 Markdown 格式,并加载到六个独立的 vector store 中——每个类别一个——而不是单一的组合索引。
### 产品类别
| 类别 | 查询示例 |
|----------|--------------|
| 越野跑 | "Golden Gate 2 的前后掌落差是多少?" |
| 接近 | "哪款鞋最适合混合地形?" |
| 攀岩 | "Instinct S 是激进款吗?" |
| 登山 | "Ribelle 和 Phantom 相比如何?" |
| 滑雪 | "Maestrale RS 的硬度指数是多少?" |
| 生活方式 | "SCARPA 有什么适合日常的多功能选择?" |
## 🧠 我的收获
架构只是起点。有趣的部分在于探索它*为什么*必须设计成那样。
**Retrieval-Augmented Generation。** 将 LLM 的输出建立在外部检索到的数据之上,而不是依赖于模型的参数化记忆。该 agent 是根据目录来回答问题,而不是根据模型自认为对 SCARPA 的了解。这种区别重新定义了许多 LLM 的行为方式。
**Context pollution。** 检索到的上下文并非越多越好。无关或关联性弱的 chunk 会与正确信息产生竞争,从而降低回答质量。按类别进行分片不仅仅是一种优化手段,更是一种保护模型免受自身干扰的方法。
**概率性检索与生成。** LLM 并不是在“查找”答案,vector search 也不是在“找到”它们。这两个阶段都是基于相似度的概率性工作。如果将其中任何一个视为确定性的过程,往往会导致系统在部署后出现不可预测的故障。
**分类作为路由层。** 在检索*之前*将查询发送到正确的索引,正是让分片发挥作用的关键。如果没有分类,分片就会失去意义。
**双端 guardrails。** 输入 guardrails 负责筛查传入的内容。输出 guardrails 负责验证答案是否偏离了检索到的数据。它们应对的是不同的失败模式,因此需要不同的检查机制。
## 🛑 为什么在此止步
ChatGPT 的 Agent Builder 是一个工作流建模和原型设计环境——而不是部署平台。如果要让该项目超越构建和测试阶段,就意味着必须在 Agent Builder 之外,使用不同的技术栈重新构建相同的工作流,这将是一项部署练习,而不是学习练习。
当我能够提交一个 prompt,观察它通过分类器路由,命中正确的 vector store,并返回经过验证的答案时,概念上的目标就已经实现了。如果继续深入,相对于我最初想学到的知识而言,只会产生边际效益递减的效果。
**2026 年 6 月更新:** OpenAI 此前已宣布将逐步关闭 Agent Builder(连同 Evals 一起),计划于 2026 年 11 月 30 日关停;现在它将生产环境的工作流指向了 [Agents SDK](https://github.com/openai/openai-agents-python)。这进一步印证了上述观点——Agent Builder 是*学习*这些概念的理想环境,但并非用于部署。我所总结的经验(RAG、分类、guardrails)是与技术栈无关的,完全可以迁移到该 SDK 或任何其他编排层中。
## 🔧 技术栈
| 工具 | 用途 |
|------|---------|
| ChatGPT Agent Builder | 工作流设计与编排 |
| Vector stores (×6) | 针对特定类别的语义搜索 |
| Markdown | 产品目录格式 |
## 📁 代码库
```
scarpa-rag-agent/
├── README.md
├── data/ # Six markdown product catalogs
└── assets/
├── workflow.png # Agent Builder screenshot
└── scarpa_agent_architecture.svg # Conceptual flow diagram
```
## 📄 免责声明
这是一个个人学习项目,旨在探索 RAG 和 agent 工作流概念。它不隶属于 SCARPA,也未获得 SCARPA 的认可或赞助。
`data/` 中的产品名称、描述和规格均为 SCARPA S.p.A. 的知识产权,此处包含它们仅出于教育和作品集展示的目的。这些产品数据未获授权进行重新分发或商业使用。
工作流设计、架构及相关文档均为我个人独立完成的工作。
标签:ChatGPT, DLL 劫持, Promptflow, RAG, 人工智能, 大语言模型, 提示词工程, 用户模式Hook绕过, 策略决策点, 防御加固