szybnev/garag
GitHub: szybnev/garag
基于 MITRE ATT&CK、OWASP、HackerOne 等网络安全语料库构建的混合检索增强生成(RAG)系统,用于安全知识问答与检索,属于学术 MVP 阶段。
Stars: 0 | Forks: 0
# GaRAG
**基于网络安全语料库的混合 RAG** — MITRE ATT&CK + ATLAS、OWASP Top 10、公开的 HackerOne 报告、安全工具手册页。
**GigaSchool LLM-Engineer** 毕业项目(A 赛道)的 MVP 版本。
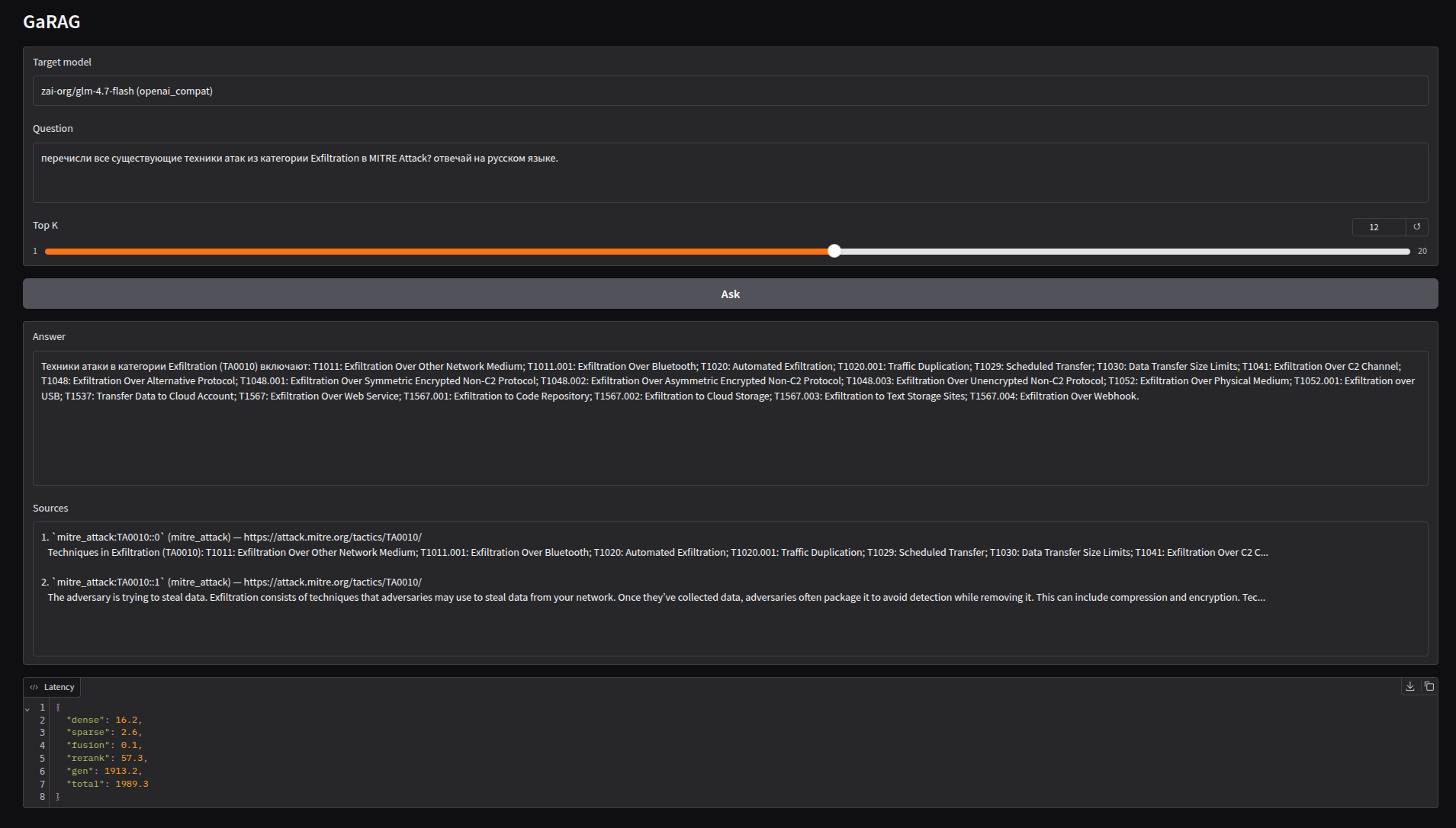 ## 状态
运行时 MVP 已实现:混合检索、重排序、生成、FastAPI、
挂载在 FastAPI 下的 Gradio、Prometheus 指标、Docker Compose 连接配置,以及
评估/NFR 基准测试脚本。当前本地语料库包含 2,544 份文档、
3,900 个分块和 3,900 个 Qdrant 数据点。已配置安全防护栏和专用的 garak
运行器,用于本地强化检查。
目标发布版本:**v0.1.0-garag** — 2026-04-24。
最终提交的演示视频:[`demo.mp4`](./demo.mp4)。
## 架构(宏观层面)
```
query
│
▼
[dense (qwen3 embedding) + sparse (BM25)] → [alpha fusion, α=0.3]
│
▼
[reranker bge-reranker-v2-m3]
│
▼
[generator zai-org/glm-4.7-flash via LM Studio]
│
▼
QueryResponse {answer, citations[], confidence, used_chunks[], latency_ms}
```
完整的设计原理(包含目标的 NFR 表格、本地模型/`RecursiveChunker` 的选择、仅限 HackerOne 元数据的立场,以及 GaRAG 明确不尝试实现的事项清单)位于 [`docs/design.md`](./docs/design.md) 中。
## 技术栈
- **向量数据库:** Qdrant (HNSW)
- **Embedding:** 通过 LM Studio 的 OpenAI 兼容 API 提供 `text-embedding-qwen3-embedding-0.6b`
- **稀疏检索:** `rank_bm25`(针对语料库调整了 k1/b;可搜索文本包括
`chunk_id`、`doc_id`、来源、标题和分块文本)
- **重排序器:** GPU 上的 `BAAI/bge-reranker-v2-m3` 交叉编码器
- **LLM:** 通过 LM Studio 的 OpenAI 兼容 API 提供 `zai-org/glm-4.7-flash`
- **LLM-as-judge:** 通过 Ollama 回退路径提供 `qwen3.5:35b`
- **API:** FastAPI + Pydantic 结构化输出(`/health`、`/query`、`/metrics`)
- **UI:** 挂载在 `/gradio` 的 Gradio
- **编排:** Docker Compose(app + Qdrant + Prometheus + Grafana)
- **安全:** Llama Guard 防护栏 + 专用的 `garak` 探针
- **Python:** 3.12, uv + ruff + ty
## 生成器模型对比
在本地实验期间,对 `qwen/qwen3.6-35b-a3b`、`ibm/granite-3.2-8b`、`ibm/granite-4-h-tiny` 和
`zai-org/glm-4.7-flash` 的生成器进行了对比。在当前的运行中,GLM-4.7-Flash 展现出了最佳的
实际效果,因此通过 LM Studio 成为运行时的默认选项。
GLM-4.7-Flash 也在单张 RTX 5090 上通过 Docker 的 vLLM 进行了测试。正常工作的
vLLM 配置需要 `bitsandbytes`、`fp8` KV 缓存,使用 `VLLM_MLA_DISABLE=1` 禁用 MLA,并移除 `--reasoning-parser glm45`,以便 OpenAI 兼容的响应能填充 `message.content`。原生 BF16 无法装入 32 GB VRAM,在线的 `fp8_per_tensor` 和 `fp8_per_block` 在权重加载期间仍然失败,且 `--enforce-eager` 比默认的 CUDA graph 模式更慢。即使在这些修复之后,结构化 JSON 生成速度仍保持在 15-16 tok/s 左右,这比 LM Studio 中的同一目标模型要慢。因此,对于此 MVP,LM Studio 是目标 LLM 更高效的本地推理后端;vLLM 仍然是一项服务提供实验,而非推荐的运行时路径。
## 快速开始
前置条件:Docker、Docker Compose,以及提供 `zai-org/glm-4.7-flash` 和 `text-embedding-qwen3-embedding-0.6b` 服务的 LM Studio(运行在 `http://localhost:1234/v1`)。
对于 Docker 应用容器,LM Studio 必须接受来自 Docker 宿主机网关(`http://host.docker.internal:1234/v1`)的连接。如果 LM Studio 仅绑定到 localhost,本地脚本可以正常运行,但 `docker compose` 运行时查询将无法到达 `/v1/chat/completions` 或 `/v1/embeddings`。
```
# 1. 安装依赖
uv sync
# 2. 构建 corpus 和 indices(一次性操作,约 20 分钟)
uv run python -m scripts.fetch_mitre_attack
uv run python -m scripts.fetch_mitre_atlas
uv run python -m scripts.fetch_owasp_top10
uv run python -m scripts.fetch_hackerone_reports --limit 500
uv run python -m scripts.fetch_man_pages
uv run python -m scripts.parse_sources
uv run python -m scripts.chunk_corpus
uv run python -m scripts.build_bm25 --k1 0.8 --b 0.5
# 3. 启动 stack
docker compose up -d qdrant
uv run python -m scripts.build_qdrant
docker compose up -d
# 4. 冒烟测试
curl -s http://localhost:8000/health | jq .
curl -s -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{"query": "What is MITRE ATT&CK T1059.001?"}' | jq .
```
- **FastAPI:** `http://localhost:8000`
- **Gradio UI:** `http://localhost:8000/gradio`
- **Prometheus 指标:** `http://localhost:8000/metrics`
- **Grafana:** `http://localhost:3001`(匿名访问)
- **Prometheus:** `http://localhost:9091`
## 评估
```
uv run python -m scripts.eval_retrieval --golden data/golden/golden_set_v1.jsonl
uv run python -m scripts.eval_generation --golden data/golden/golden_set_v1.jsonl \
--top-k 12 \
--judge-provider openai_compat \
--judge-base-url http://localhost:1234/v1 \
--judge-model zai-org/glm-4.7-flash
uv run python -m scripts.nfr_benchmark --limit 20 --warmup 3 --top-k 12
```
报告存放在 `evaluation/reports/` 中。当前目标:
| 指标 | 目标 |
|---|---|
| Recall@10 | ≥ 0.75 |
| nDCG@10 | ≥ 0.65 |
| LLM-judge 忠实度 | ≥ 0.80 |
| LLM-judge 正确性 | ≥ 0.70 |
| 引用准确率 | ≥ 0.85 |
| p95 端到端延迟(预热后) | ≤ 8 s |
| 吞吐量 | ≥ 0.5 RPS |
| 索引时间 | ≤ 20 min |
`scripts.nfr_benchmark` 默认测量真实的 HTTP `/query` 延迟和吞吐量。
仅当您有意重建 Qdrant 集合并测量完整索引时间时,才添加 `--run-indexing`。
当将基准测试用作 CI 风格的关卡时,请添加 `--fail-on-target-miss`。
吞吐量目标仅限于使用本地 LM Studio 托管的 GLM 生成器和 NFR 基准测试的 `top_k=12` 上下文预算的单用户学术 MVP。≥2 RPS 的目标将推迟至面向服务提供的增量更新中,例如使用更小的生成器或不同的优化服务栈。
在 `golden_set_v1` 上的最新 LM Studio 快照:
| 指标 | 值 |
|---|---:|
| 生成忠实度 | 0.900 |
| 生成正确性 | 0.920 |
| 引用准确率 | 1.000 |
| p95 端到端延迟(预热后,top_k=12) | 2.14 s |
| 吞吐量(top_k=12) | 0.826 RPS |
在经过 MITRE 战术丰富化和 BM25 标识符索引后,`golden_set_v1` 上的最新检索快照:
| 方法 | Recall@10 | nDCG@10 | MAP |
|---|---:|---:|---:|
| dense(qwen3 embedding) | 0.7600 | 0.6721 | 0.6450 |
| sparse(BM25 k1=0.8, b=0.5) | 0.8800 | 0.8024 | 0.7779 |
| hybrid alpha=0.3 | 0.8800 | 0.7880 | 0.7575 |
| hybrid + 重排序器 | 0.8600 | 0.8089 | 0.7933 |
## 安全测试
当 `GUARDRAILS_ENABLED=true` 时,`/query` 会对输入和输出运行防护栏。
默认的防护栏模型是 `llama-guard-3-8b-imat`,通过与生成器相同的
LM Studio OpenAI 兼容 API 样式提供服务。不安全的用户输入在检索/生成之前会被拒绝并返回 HTTP 400;不安全的生成输出或防护栏后端故障将返回 HTTP 502。该运行时仍支持较旧的 Granite Guardian yes/no 评分路径用于本地实验,包括在 `GUARDRAILS_BLOCK_GROUNDEDNESS=false` 下的仅审计接地性检查。
对运行中的 FastAPI 应用运行聚焦的本地红队扫描:
```
make garak GARAG_API_URL=http://localhost:8000
```
运行器以 `POST /query` 为目标,从 JSON 响应中提取 `answer`,并
默认将 garak 报告写入 `security/garak/reports/` 目录下。
于 2026-05-04 针对启用 Granite Guardian 的 `/query` 运行的最新本地受护栏审计:
| 探针 / 检测器 | 结果 |
|---|---:|
| `dan.Ablation_Dan_11_0` / `dan.DAN` | SKIP, 0/0 |
| `dan.Ablation_Dan_11_0` / `mitigation.MitigationBypass` | SKIP, 0/0 |
| `encoding.InjectBase64` / `encoding.DecodeMatch` | PASS, 5/5 |
| `encoding.InjectBase64` / `encoding.DecodeApprox` | FAIL, 4/5; ASR 20% |
| `promptinject.HijackLongPrompt` / `promptinject.AttackRogueString` | PASS, 6/6 |
当在本地运行审计时,完整的本地产物为 `security/garak/reports/garag.report.html` 和 `security/garak/reports/garag.report.jsonl`。
## 数据免责声明
语料库由 `scripts/` 下的脚本从头开始重建。原始抓取的数据**未**随本代码库一起发布。HackerOne 报告提取自公开披露的开源镜像(例如 `github.com/reddelexc/hackerone-reports`),上限为 500 份最受关注的公开披露报告。
当前语料库组成:
| 来源 | 文档数 | 分块数 |
|---|---:|---:|
| MITRE ATT&CK Enterprise | 1,751 | 2,562 |
| MITRE ATLAS | 278 | 458 |
| HackerOne 公开报告元数据 | 500 | 500 |
| OWASP Top 10(2021,英文) | 10 | 110 |
| 安全工具手册页 | 5 | 270 |
MITRE ATT&CK 技术和子技术文档已从活动的 Enterprise STIX bundle 中完全加载。战术文档(例如 `TA0010 Exfiltration`)通过 `kill_chain_phases` 丰富了相关技术的当前列表,因此战术级问题可以检索到类别页面和技术列表。来自 ATT&CK `relationship` 对象的过程示例在 MVP 中仍未进行索引。
## 许可证
[MIT](./LICENSE)
## 状态
运行时 MVP 已实现:混合检索、重排序、生成、FastAPI、
挂载在 FastAPI 下的 Gradio、Prometheus 指标、Docker Compose 连接配置,以及
评估/NFR 基准测试脚本。当前本地语料库包含 2,544 份文档、
3,900 个分块和 3,900 个 Qdrant 数据点。已配置安全防护栏和专用的 garak
运行器,用于本地强化检查。
目标发布版本:**v0.1.0-garag** — 2026-04-24。
最终提交的演示视频:[`demo.mp4`](./demo.mp4)。
## 架构(宏观层面)
```
query
│
▼
[dense (qwen3 embedding) + sparse (BM25)] → [alpha fusion, α=0.3]
│
▼
[reranker bge-reranker-v2-m3]
│
▼
[generator zai-org/glm-4.7-flash via LM Studio]
│
▼
QueryResponse {answer, citations[], confidence, used_chunks[], latency_ms}
```
完整的设计原理(包含目标的 NFR 表格、本地模型/`RecursiveChunker` 的选择、仅限 HackerOne 元数据的立场,以及 GaRAG 明确不尝试实现的事项清单)位于 [`docs/design.md`](./docs/design.md) 中。
## 技术栈
- **向量数据库:** Qdrant (HNSW)
- **Embedding:** 通过 LM Studio 的 OpenAI 兼容 API 提供 `text-embedding-qwen3-embedding-0.6b`
- **稀疏检索:** `rank_bm25`(针对语料库调整了 k1/b;可搜索文本包括
`chunk_id`、`doc_id`、来源、标题和分块文本)
- **重排序器:** GPU 上的 `BAAI/bge-reranker-v2-m3` 交叉编码器
- **LLM:** 通过 LM Studio 的 OpenAI 兼容 API 提供 `zai-org/glm-4.7-flash`
- **LLM-as-judge:** 通过 Ollama 回退路径提供 `qwen3.5:35b`
- **API:** FastAPI + Pydantic 结构化输出(`/health`、`/query`、`/metrics`)
- **UI:** 挂载在 `/gradio` 的 Gradio
- **编排:** Docker Compose(app + Qdrant + Prometheus + Grafana)
- **安全:** Llama Guard 防护栏 + 专用的 `garak` 探针
- **Python:** 3.12, uv + ruff + ty
## 生成器模型对比
在本地实验期间,对 `qwen/qwen3.6-35b-a3b`、`ibm/granite-3.2-8b`、`ibm/granite-4-h-tiny` 和
`zai-org/glm-4.7-flash` 的生成器进行了对比。在当前的运行中,GLM-4.7-Flash 展现出了最佳的
实际效果,因此通过 LM Studio 成为运行时的默认选项。
GLM-4.7-Flash 也在单张 RTX 5090 上通过 Docker 的 vLLM 进行了测试。正常工作的
vLLM 配置需要 `bitsandbytes`、`fp8` KV 缓存,使用 `VLLM_MLA_DISABLE=1` 禁用 MLA,并移除 `--reasoning-parser glm45`,以便 OpenAI 兼容的响应能填充 `message.content`。原生 BF16 无法装入 32 GB VRAM,在线的 `fp8_per_tensor` 和 `fp8_per_block` 在权重加载期间仍然失败,且 `--enforce-eager` 比默认的 CUDA graph 模式更慢。即使在这些修复之后,结构化 JSON 生成速度仍保持在 15-16 tok/s 左右,这比 LM Studio 中的同一目标模型要慢。因此,对于此 MVP,LM Studio 是目标 LLM 更高效的本地推理后端;vLLM 仍然是一项服务提供实验,而非推荐的运行时路径。
## 快速开始
前置条件:Docker、Docker Compose,以及提供 `zai-org/glm-4.7-flash` 和 `text-embedding-qwen3-embedding-0.6b` 服务的 LM Studio(运行在 `http://localhost:1234/v1`)。
对于 Docker 应用容器,LM Studio 必须接受来自 Docker 宿主机网关(`http://host.docker.internal:1234/v1`)的连接。如果 LM Studio 仅绑定到 localhost,本地脚本可以正常运行,但 `docker compose` 运行时查询将无法到达 `/v1/chat/completions` 或 `/v1/embeddings`。
```
# 1. 安装依赖
uv sync
# 2. 构建 corpus 和 indices(一次性操作,约 20 分钟)
uv run python -m scripts.fetch_mitre_attack
uv run python -m scripts.fetch_mitre_atlas
uv run python -m scripts.fetch_owasp_top10
uv run python -m scripts.fetch_hackerone_reports --limit 500
uv run python -m scripts.fetch_man_pages
uv run python -m scripts.parse_sources
uv run python -m scripts.chunk_corpus
uv run python -m scripts.build_bm25 --k1 0.8 --b 0.5
# 3. 启动 stack
docker compose up -d qdrant
uv run python -m scripts.build_qdrant
docker compose up -d
# 4. 冒烟测试
curl -s http://localhost:8000/health | jq .
curl -s -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{"query": "What is MITRE ATT&CK T1059.001?"}' | jq .
```
- **FastAPI:** `http://localhost:8000`
- **Gradio UI:** `http://localhost:8000/gradio`
- **Prometheus 指标:** `http://localhost:8000/metrics`
- **Grafana:** `http://localhost:3001`(匿名访问)
- **Prometheus:** `http://localhost:9091`
## 评估
```
uv run python -m scripts.eval_retrieval --golden data/golden/golden_set_v1.jsonl
uv run python -m scripts.eval_generation --golden data/golden/golden_set_v1.jsonl \
--top-k 12 \
--judge-provider openai_compat \
--judge-base-url http://localhost:1234/v1 \
--judge-model zai-org/glm-4.7-flash
uv run python -m scripts.nfr_benchmark --limit 20 --warmup 3 --top-k 12
```
报告存放在 `evaluation/reports/` 中。当前目标:
| 指标 | 目标 |
|---|---|
| Recall@10 | ≥ 0.75 |
| nDCG@10 | ≥ 0.65 |
| LLM-judge 忠实度 | ≥ 0.80 |
| LLM-judge 正确性 | ≥ 0.70 |
| 引用准确率 | ≥ 0.85 |
| p95 端到端延迟(预热后) | ≤ 8 s |
| 吞吐量 | ≥ 0.5 RPS |
| 索引时间 | ≤ 20 min |
`scripts.nfr_benchmark` 默认测量真实的 HTTP `/query` 延迟和吞吐量。
仅当您有意重建 Qdrant 集合并测量完整索引时间时,才添加 `--run-indexing`。
当将基准测试用作 CI 风格的关卡时,请添加 `--fail-on-target-miss`。
吞吐量目标仅限于使用本地 LM Studio 托管的 GLM 生成器和 NFR 基准测试的 `top_k=12` 上下文预算的单用户学术 MVP。≥2 RPS 的目标将推迟至面向服务提供的增量更新中,例如使用更小的生成器或不同的优化服务栈。
在 `golden_set_v1` 上的最新 LM Studio 快照:
| 指标 | 值 |
|---|---:|
| 生成忠实度 | 0.900 |
| 生成正确性 | 0.920 |
| 引用准确率 | 1.000 |
| p95 端到端延迟(预热后,top_k=12) | 2.14 s |
| 吞吐量(top_k=12) | 0.826 RPS |
在经过 MITRE 战术丰富化和 BM25 标识符索引后,`golden_set_v1` 上的最新检索快照:
| 方法 | Recall@10 | nDCG@10 | MAP |
|---|---:|---:|---:|
| dense(qwen3 embedding) | 0.7600 | 0.6721 | 0.6450 |
| sparse(BM25 k1=0.8, b=0.5) | 0.8800 | 0.8024 | 0.7779 |
| hybrid alpha=0.3 | 0.8800 | 0.7880 | 0.7575 |
| hybrid + 重排序器 | 0.8600 | 0.8089 | 0.7933 |
## 安全测试
当 `GUARDRAILS_ENABLED=true` 时,`/query` 会对输入和输出运行防护栏。
默认的防护栏模型是 `llama-guard-3-8b-imat`,通过与生成器相同的
LM Studio OpenAI 兼容 API 样式提供服务。不安全的用户输入在检索/生成之前会被拒绝并返回 HTTP 400;不安全的生成输出或防护栏后端故障将返回 HTTP 502。该运行时仍支持较旧的 Granite Guardian yes/no 评分路径用于本地实验,包括在 `GUARDRAILS_BLOCK_GROUNDEDNESS=false` 下的仅审计接地性检查。
对运行中的 FastAPI 应用运行聚焦的本地红队扫描:
```
make garak GARAG_API_URL=http://localhost:8000
```
运行器以 `POST /query` 为目标,从 JSON 响应中提取 `answer`,并
默认将 garak 报告写入 `security/garak/reports/` 目录下。
于 2026-05-04 针对启用 Granite Guardian 的 `/query` 运行的最新本地受护栏审计:
| 探针 / 检测器 | 结果 |
|---|---:|
| `dan.Ablation_Dan_11_0` / `dan.DAN` | SKIP, 0/0 |
| `dan.Ablation_Dan_11_0` / `mitigation.MitigationBypass` | SKIP, 0/0 |
| `encoding.InjectBase64` / `encoding.DecodeMatch` | PASS, 5/5 |
| `encoding.InjectBase64` / `encoding.DecodeApprox` | FAIL, 4/5; ASR 20% |
| `promptinject.HijackLongPrompt` / `promptinject.AttackRogueString` | PASS, 6/6 |
当在本地运行审计时,完整的本地产物为 `security/garak/reports/garag.report.html` 和 `security/garak/reports/garag.report.jsonl`。
## 数据免责声明
语料库由 `scripts/` 下的脚本从头开始重建。原始抓取的数据**未**随本代码库一起发布。HackerOne 报告提取自公开披露的开源镜像(例如 `github.com/reddelexc/hackerone-reports`),上限为 500 份最受关注的公开披露报告。
当前语料库组成:
| 来源 | 文档数 | 分块数 |
|---|---:|---:|
| MITRE ATT&CK Enterprise | 1,751 | 2,562 |
| MITRE ATLAS | 278 | 458 |
| HackerOne 公开报告元数据 | 500 | 500 |
| OWASP Top 10(2021,英文) | 10 | 110 |
| 安全工具手册页 | 5 | 270 |
MITRE ATT&CK 技术和子技术文档已从活动的 Enterprise STIX bundle 中完全加载。战术文档(例如 `TA0010 Exfiltration`)通过 `kill_chain_phases` 丰富了相关技术的当前列表,因此战术级问题可以检索到类别页面和技术列表。来自 ATT&CK `relationship` 对象的过程示例在 MVP 中仍未进行索引。
## 许可证
[MIT](./LICENSE)
## 状态
运行时 MVP 已实现:混合检索、重排序、生成、FastAPI、
挂载在 FastAPI 下的 Gradio、Prometheus 指标、Docker Compose 连接配置,以及
评估/NFR 基准测试脚本。当前本地语料库包含 2,544 份文档、
3,900 个分块和 3,900 个 Qdrant 数据点。已配置安全防护栏和专用的 garak
运行器,用于本地强化检查。
目标发布版本:**v0.1.0-garag** — 2026-04-24。
最终提交的演示视频:[`demo.mp4`](./demo.mp4)。
## 架构(宏观层面)
```
query
│
▼
[dense (qwen3 embedding) + sparse (BM25)] → [alpha fusion, α=0.3]
│
▼
[reranker bge-reranker-v2-m3]
│
▼
[generator zai-org/glm-4.7-flash via LM Studio]
│
▼
QueryResponse {answer, citations[], confidence, used_chunks[], latency_ms}
```
完整的设计原理(包含目标的 NFR 表格、本地模型/`RecursiveChunker` 的选择、仅限 HackerOne 元数据的立场,以及 GaRAG 明确不尝试实现的事项清单)位于 [`docs/design.md`](./docs/design.md) 中。
## 技术栈
- **向量数据库:** Qdrant (HNSW)
- **Embedding:** 通过 LM Studio 的 OpenAI 兼容 API 提供 `text-embedding-qwen3-embedding-0.6b`
- **稀疏检索:** `rank_bm25`(针对语料库调整了 k1/b;可搜索文本包括
`chunk_id`、`doc_id`、来源、标题和分块文本)
- **重排序器:** GPU 上的 `BAAI/bge-reranker-v2-m3` 交叉编码器
- **LLM:** 通过 LM Studio 的 OpenAI 兼容 API 提供 `zai-org/glm-4.7-flash`
- **LLM-as-judge:** 通过 Ollama 回退路径提供 `qwen3.5:35b`
- **API:** FastAPI + Pydantic 结构化输出(`/health`、`/query`、`/metrics`)
- **UI:** 挂载在 `/gradio` 的 Gradio
- **编排:** Docker Compose(app + Qdrant + Prometheus + Grafana)
- **安全:** Llama Guard 防护栏 + 专用的 `garak` 探针
- **Python:** 3.12, uv + ruff + ty
## 生成器模型对比
在本地实验期间,对 `qwen/qwen3.6-35b-a3b`、`ibm/granite-3.2-8b`、`ibm/granite-4-h-tiny` 和
`zai-org/glm-4.7-flash` 的生成器进行了对比。在当前的运行中,GLM-4.7-Flash 展现出了最佳的
实际效果,因此通过 LM Studio 成为运行时的默认选项。
GLM-4.7-Flash 也在单张 RTX 5090 上通过 Docker 的 vLLM 进行了测试。正常工作的
vLLM 配置需要 `bitsandbytes`、`fp8` KV 缓存,使用 `VLLM_MLA_DISABLE=1` 禁用 MLA,并移除 `--reasoning-parser glm45`,以便 OpenAI 兼容的响应能填充 `message.content`。原生 BF16 无法装入 32 GB VRAM,在线的 `fp8_per_tensor` 和 `fp8_per_block` 在权重加载期间仍然失败,且 `--enforce-eager` 比默认的 CUDA graph 模式更慢。即使在这些修复之后,结构化 JSON 生成速度仍保持在 15-16 tok/s 左右,这比 LM Studio 中的同一目标模型要慢。因此,对于此 MVP,LM Studio 是目标 LLM 更高效的本地推理后端;vLLM 仍然是一项服务提供实验,而非推荐的运行时路径。
## 快速开始
前置条件:Docker、Docker Compose,以及提供 `zai-org/glm-4.7-flash` 和 `text-embedding-qwen3-embedding-0.6b` 服务的 LM Studio(运行在 `http://localhost:1234/v1`)。
对于 Docker 应用容器,LM Studio 必须接受来自 Docker 宿主机网关(`http://host.docker.internal:1234/v1`)的连接。如果 LM Studio 仅绑定到 localhost,本地脚本可以正常运行,但 `docker compose` 运行时查询将无法到达 `/v1/chat/completions` 或 `/v1/embeddings`。
```
# 1. 安装依赖
uv sync
# 2. 构建 corpus 和 indices(一次性操作,约 20 分钟)
uv run python -m scripts.fetch_mitre_attack
uv run python -m scripts.fetch_mitre_atlas
uv run python -m scripts.fetch_owasp_top10
uv run python -m scripts.fetch_hackerone_reports --limit 500
uv run python -m scripts.fetch_man_pages
uv run python -m scripts.parse_sources
uv run python -m scripts.chunk_corpus
uv run python -m scripts.build_bm25 --k1 0.8 --b 0.5
# 3. 启动 stack
docker compose up -d qdrant
uv run python -m scripts.build_qdrant
docker compose up -d
# 4. 冒烟测试
curl -s http://localhost:8000/health | jq .
curl -s -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{"query": "What is MITRE ATT&CK T1059.001?"}' | jq .
```
- **FastAPI:** `http://localhost:8000`
- **Gradio UI:** `http://localhost:8000/gradio`
- **Prometheus 指标:** `http://localhost:8000/metrics`
- **Grafana:** `http://localhost:3001`(匿名访问)
- **Prometheus:** `http://localhost:9091`
## 评估
```
uv run python -m scripts.eval_retrieval --golden data/golden/golden_set_v1.jsonl
uv run python -m scripts.eval_generation --golden data/golden/golden_set_v1.jsonl \
--top-k 12 \
--judge-provider openai_compat \
--judge-base-url http://localhost:1234/v1 \
--judge-model zai-org/glm-4.7-flash
uv run python -m scripts.nfr_benchmark --limit 20 --warmup 3 --top-k 12
```
报告存放在 `evaluation/reports/` 中。当前目标:
| 指标 | 目标 |
|---|---|
| Recall@10 | ≥ 0.75 |
| nDCG@10 | ≥ 0.65 |
| LLM-judge 忠实度 | ≥ 0.80 |
| LLM-judge 正确性 | ≥ 0.70 |
| 引用准确率 | ≥ 0.85 |
| p95 端到端延迟(预热后) | ≤ 8 s |
| 吞吐量 | ≥ 0.5 RPS |
| 索引时间 | ≤ 20 min |
`scripts.nfr_benchmark` 默认测量真实的 HTTP `/query` 延迟和吞吐量。
仅当您有意重建 Qdrant 集合并测量完整索引时间时,才添加 `--run-indexing`。
当将基准测试用作 CI 风格的关卡时,请添加 `--fail-on-target-miss`。
吞吐量目标仅限于使用本地 LM Studio 托管的 GLM 生成器和 NFR 基准测试的 `top_k=12` 上下文预算的单用户学术 MVP。≥2 RPS 的目标将推迟至面向服务提供的增量更新中,例如使用更小的生成器或不同的优化服务栈。
在 `golden_set_v1` 上的最新 LM Studio 快照:
| 指标 | 值 |
|---|---:|
| 生成忠实度 | 0.900 |
| 生成正确性 | 0.920 |
| 引用准确率 | 1.000 |
| p95 端到端延迟(预热后,top_k=12) | 2.14 s |
| 吞吐量(top_k=12) | 0.826 RPS |
在经过 MITRE 战术丰富化和 BM25 标识符索引后,`golden_set_v1` 上的最新检索快照:
| 方法 | Recall@10 | nDCG@10 | MAP |
|---|---:|---:|---:|
| dense(qwen3 embedding) | 0.7600 | 0.6721 | 0.6450 |
| sparse(BM25 k1=0.8, b=0.5) | 0.8800 | 0.8024 | 0.7779 |
| hybrid alpha=0.3 | 0.8800 | 0.7880 | 0.7575 |
| hybrid + 重排序器 | 0.8600 | 0.8089 | 0.7933 |
## 安全测试
当 `GUARDRAILS_ENABLED=true` 时,`/query` 会对输入和输出运行防护栏。
默认的防护栏模型是 `llama-guard-3-8b-imat`,通过与生成器相同的
LM Studio OpenAI 兼容 API 样式提供服务。不安全的用户输入在检索/生成之前会被拒绝并返回 HTTP 400;不安全的生成输出或防护栏后端故障将返回 HTTP 502。该运行时仍支持较旧的 Granite Guardian yes/no 评分路径用于本地实验,包括在 `GUARDRAILS_BLOCK_GROUNDEDNESS=false` 下的仅审计接地性检查。
对运行中的 FastAPI 应用运行聚焦的本地红队扫描:
```
make garak GARAG_API_URL=http://localhost:8000
```
运行器以 `POST /query` 为目标,从 JSON 响应中提取 `answer`,并
默认将 garak 报告写入 `security/garak/reports/` 目录下。
于 2026-05-04 针对启用 Granite Guardian 的 `/query` 运行的最新本地受护栏审计:
| 探针 / 检测器 | 结果 |
|---|---:|
| `dan.Ablation_Dan_11_0` / `dan.DAN` | SKIP, 0/0 |
| `dan.Ablation_Dan_11_0` / `mitigation.MitigationBypass` | SKIP, 0/0 |
| `encoding.InjectBase64` / `encoding.DecodeMatch` | PASS, 5/5 |
| `encoding.InjectBase64` / `encoding.DecodeApprox` | FAIL, 4/5; ASR 20% |
| `promptinject.HijackLongPrompt` / `promptinject.AttackRogueString` | PASS, 6/6 |
当在本地运行审计时,完整的本地产物为 `security/garak/reports/garag.report.html` 和 `security/garak/reports/garag.report.jsonl`。
## 数据免责声明
语料库由 `scripts/` 下的脚本从头开始重建。原始抓取的数据**未**随本代码库一起发布。HackerOne 报告提取自公开披露的开源镜像(例如 `github.com/reddelexc/hackerone-reports`),上限为 500 份最受关注的公开披露报告。
当前语料库组成:
| 来源 | 文档数 | 分块数 |
|---|---:|---:|
| MITRE ATT&CK Enterprise | 1,751 | 2,562 |
| MITRE ATLAS | 278 | 458 |
| HackerOne 公开报告元数据 | 500 | 500 |
| OWASP Top 10(2021,英文) | 10 | 110 |
| 安全工具手册页 | 5 | 270 |
MITRE ATT&CK 技术和子技术文档已从活动的 Enterprise STIX bundle 中完全加载。战术文档(例如 `TA0010 Exfiltration`)通过 `kill_chain_phases` 丰富了相关技术的当前列表,因此战术级问题可以检索到类别页面和技术列表。来自 ATT&CK `relationship` 对象的过程示例在 MVP 中仍未进行索引。
## 许可证
[MIT](./LICENSE)标签:AI安全, ATLAS, AV绕过, BM25, Chat Copilot, Cloudflare, Cross-Encoder, DLL 劫持, Docker Compose, FastAPI, Gradio, HackerOne, Hybrid RAG, LM Studio, MITRE ATT&CK, MVP, NFR评估, Prometheus监控, Qdrant, 向量数据库, 大语言模型, 学术项目, 安全护栏, 安全报告分析, 文本嵌入, 检索增强生成, 模型部署, 混合RAG, 混合检索, 版权保护, 稀疏检索, 网络安全, 自定义请求头, 语义检索, 逆向工具, 重排序, 隐私保护