Shad0wMazt3r/The-Scaffolding
GitHub: Shad0wMazt3r/The-Scaffolding
一个面向代理的自动化进攻编排框架,解决 CTF 与漏洞赏金研究中的上下文保持与噪声干扰问题。
Stars: 2 | Forks: 0
# The Scaffolding - Bug Bounty 与 CTF 框架
## 代理无关的攻击编排
The Scaffolding 是一个开源框架,用于自主解决 CTF 挑战和进行 Bug Bounty 研究。它通过将模型上下文协议 (MCP) 与持久化、自我改进的代理知识库相结合,将高层安全推理与确定性执行连接起来。
**将其插入任何 AI 代理:Claude Code、GitHub Copilot、Codex、Gemini、OpenCode 等,只需极少的配置。**
## 它的功能
大多数 AI 代理在执行攻击性安全任务时都会失败,因为它们缺乏结构化的侦察,会被噪音淹没,并在长会话中丢失上下文。The Scaffolding 通过提供以下功能解决了这个问题:
- **结构化技能加载**:代理仅加载与当前挑战类型相关的技能(web、pwn、crypto 等),保持上下文干净
- **LatticeMind 集成**:带置信度评分的自动化扫描,使代理能够基于信号而非噪音进行推理
- **Kali MCP 集成**:直接访问标准安全工具,无需手动设置
- **持久化笔记**:将会话状态外部化,防止长时间解题时的上下文衰退
- **自我改进的文档**:解题结果反馈到技能文件中,使框架随时间推移变得更好
## 演示
以下是一个代理使用 The Scaffolding 解决高难度 Web 挑战的演示。
https://github.com/user-attachments/assets/5774267e-0e5c-414b-99d3-1b9de2bc0444
## 架构
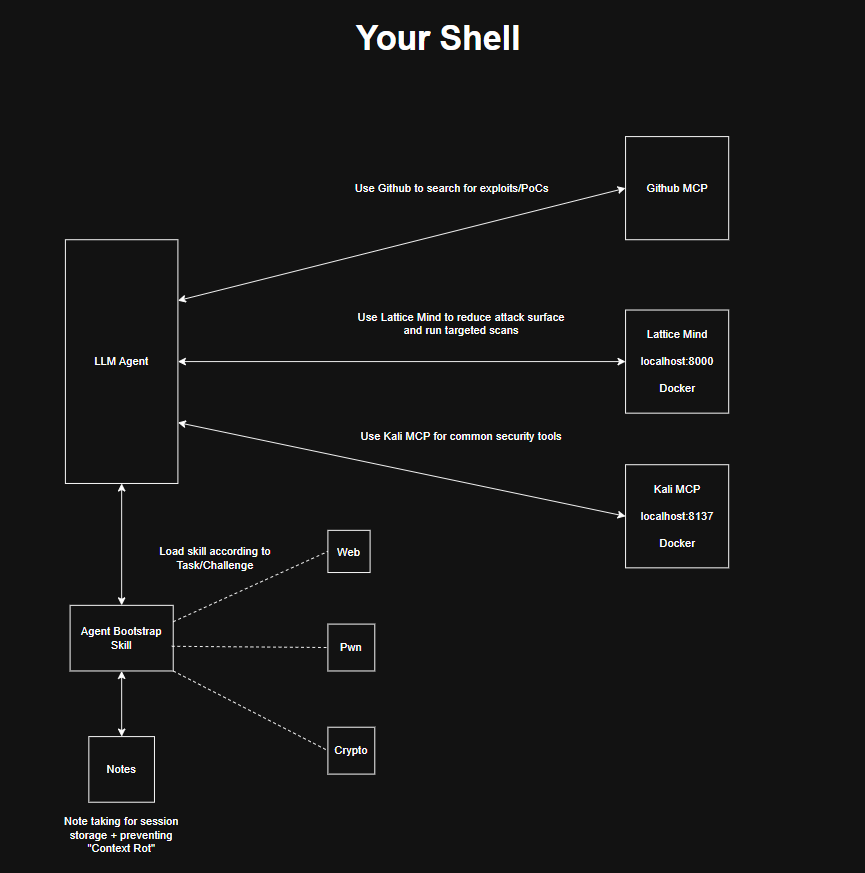 该代理位于三个工具层的中心:
- **LatticeMind** — 运行针对性扫描,按置信度对发现进行评分,为代理呈现需要推理的候选项
- **Kali MCP** — 按需执行标准安全工具
- **GitHub MCP** — 搜索漏洞利用、PoC 和参考实现
引导技能在会话开始时加载特定领域的知识。笔记会持久保存会话状态,并在每次解题后反馈到技能中。
## 开始使用
**前置条件**
- Docker
- 支持 MCP 的 AI 代理
**设置**
1. 克隆此仓库
2. 将 `.env.example` 复制为 `.env` 并填入您的 API 密钥/路径
3. 设置 MCP 并使用脚手架脚本启动您首选的代理:
pip install -r scaffold/requirements.txt
python scaffold.py
*交互式 TUI 将允许您配置 MCP、初始化项目并启动代理(Gemini、Cursor、OpenCode、Codex、Copilot、Claude、Antigravity)。*
## 项目结构
```
(root)/
├── .agents/ # Agent skill definitions
├── .cursor/ # Cursor IDE configuration
├── .gemini/ # Gemini CLI configuration
├── .github/ # GitHub integration
├── .opencode/ # OpenCode agent configuration
├── ctf-benchmarking/ # 5-challenge hard CTF benchmark manifests/templates
├── kali-mcp/ # Kali Linux MCP server integration
├── AGENTS.md # Shared agent instructions
├── HUMAN.md # Human-facing documentation
└── README.md
```
## 技能
代理会根据挑战类型加载特定领域的技能文件。每个技能都编码了从过去解题中总结出的侦察模式、攻击链和经验教训。
| 技能 | 覆盖范围 |
|---|---|
| `agent-setup` | 工具就绪状态和依赖项检查 |
| `agent-calibration` | 工作流优化和反馈 |
| `crypto` | 编码、RSA、椭圆曲线、哈希攻击 |
| `forensics` | 文件、内存、网络和多媒体分析 |
| `mobile` | 移动应用安全测试 |
| `network` | 侦察和网络评估 |
| `pwn` | 栈、堆和格式化字符串漏洞利用 |
| `recon` | 目标发现和侦察 |
| `reverse-engineering` | 二进制分析和 RE |
| `web` | Web 应用安全测试 |
## 技能契约与基准指标
为了保持不同代理间技能质量的一致性,此仓库包含:
- 规范契约:`.agents/standards/skill-contract.yaml`
- 机器可读契约:`.agents/standards/skill-contract.json`
- 质量门禁配置:`.agents/standards/quality-gate.json`
- Router 单一事实来源:`.agents/standards/router-spec.json`
- 可重现的基准生成器:`tools/skills/baseline_metrics.py`
- 验证器:`tools/skills/validate_skills.py`
- 归一化器:`tools/skills/normalize_skills.py`
- Router 生成器:`tools/skills/generate_router_wrappers.py`
- 冒烟评估门禁:`tools/skills/smoke_eval.py`
- 当前基准快照:`reports/skill-baseline.json`
常用命令:
```
# 生成 baseline
python tools/skills/baseline_metrics.py --output reports/skill-baseline.json
# 规范化已知的 markdown 问题
python tools/skills/normalize_skills.py --write --fix-footnotes
# 检查规范化漂移 (CI-safe)
python tools/skills/normalize_skills.py --check --fix-footnotes
# 对照 contract 进行验证
python tools/skills/validate_skills.py --report reports/skill-validation.json
# 根据单一 spec 重新生成所有 router wrappers
python tools/skills/generate_router_wrappers.py
# 运行端到端质量门禁
python tools/skills/smoke_eval.py --output reports/skill-smoke-eval.json
```
CI 强制执行位于 `.github/workflows/skills-quality.yml` 中。
### 低成本 Cursor 自动基准测试 (<=15 个任务)
使用阶段路由基准测试,以低成本对真实代理行为进行合理性检查:
所有基准测试运行器默认使用 `--model composer-2` 以确保进行一致的 A/B 比较。
```
python tools/benchmarks/run_cursor_phase_benchmark.py ^
--tasks tools/benchmarks/cursor_phase_tasks.json ^
--max-tasks 10 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-auto-phase-benchmark.json
```
任务集文件:`tools/benchmarks/cursor_phase_tasks.json`(默认为 10 个任务;硬性上限为 15 个)。
### 安全基准测试(目前仅限技能,MCP 比较将在稍后进行)
首先使用仅技能配置文件运行更丰富的安全基准测试:
```
python tools/benchmarks/run_cursor_security_benchmark.py ^
--profile skills-only ^
--tasks tools/benchmarks/cursor_security_tasks.json ^
--max-tasks 12 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-security-skills-only.json
```
稍后,在启用 Kali/Lattice MCP 后,运行:
```
python tools/benchmarks/run_cursor_security_benchmark.py ^
--profile mcp-enabled ^
--tasks tools/benchmarks/cursor_security_tasks.json ^
--max-tasks 12 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-security-mcp-enabled.json
```
然后进行比较:
```
python tools/benchmarks/compare_cursor_benchmarks.py ^
--baseline reports/benchmarks/cursor-security-skills-only.json ^
--candidate reports/benchmarks/cursor-security-mcp-enabled.json ^
--output reports/benchmarks/cursor-security-comparison.json
```
### 漏洞查找基准测试(真值质量)
运行高难度但低成本的漏洞查找基准测试(最多 20 个任务),包含严格的 JSON 发现结果和 TP/FP/FN 评分:
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile control ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-control.json
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile skills-only ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-skills-only.json
```
同时也支持自适应和轻量级框架配置文件:
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile adaptive ^
--model gpt-5.4-mini-high ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--output reports/benchmarks/cursor-vuln-adaptive.json
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile skills-lite ^
--model gemini-3-flash ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--verify-findings ^
--output reports/benchmarks/cursor-vuln-skills-lite.json
```
稍后(在启用 MCP 后):
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile mcp-enabled ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-mcp-enabled.json
```
比较两次漏洞运行结果:
```
python tools/benchmarks/compare_cursor_vuln_benchmarks.py ^
--baseline reports/benchmarks/cursor-vuln-control.json ^
--candidate reports/benchmarks/cursor-vuln-skills-only.json ^
--output reports/benchmarks/cursor-vuln-control-vs-skills.json
```
运行包含 2 次运行的实验(对照组对比仅技能组)并进行聚合:
```
python tools/benchmarks/run_cursor_vuln_experiment.py ^
--profiles control skills-only ^
--runs 2 ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-experiment-runs2.json
```
根据所有运行响应生成客观和主观评分:
```
python tools/benchmarks/grade_cursor_vuln_responses.py ^
--experiment reports/benchmarks/cursor-vuln-experiment-runs2.json ^
--output reports/benchmarks/cursor-vuln-manual-grade.json
```
生成整合的 runs3 排行榜(JSON + Markdown):
```
python tools/benchmarks/generate_vuln_leaderboard.py ^
--input-root reports/benchmarks/model-sweep ^
--output-json reports/benchmarks/model-sweep-leaderboard.json ^
--output-md reports/benchmarks/model-sweep-leaderboard.md
```
默认情况下,漏洞比较侧重于效能指标;仅在明确需要延迟/token 增量时才添加 `--include-cost`。
### Docker 化的高难度 CTF 基准测试(包含 5 个挑战的测试平台)
该仓库还包含一个 Docker 化的基准测试套件,每个类别(`web`、`pwn`、`crypto`、`forensics`、`reverse-engineering`)各有一个高难度挑战,并在运行结束时强制要求提供用于手动评分的 writeup。
获取源码:
```
python tools/benchmarks/fetch_ctf_sources.py ^
--manifest ctf-benchmarking/manifest.json ^
--source-root ctf-benchmarking/sources
```
运行基准测试:
```
python tools/benchmarks/run_cursor_ctf_benchmark.py ^
--manifest ctf-benchmarking/manifest.json ^
--source-root ctf-benchmarking/sources ^
--model composer-2 ^
--output-dir reports/benchmarks/ctf-run-01
```
生成评分工作表产物:
```
python tools/benchmarks/grade_cursor_ctf_writeups.py ^
--run-report reports/benchmarks/ctf-run-01/run-report.json ^
--rubric ctf-benchmarking/grading/rubric.json ^
--output reports/benchmarks/ctf-run-01/manual-grade.json ^
--worksheet-md reports/benchmarks/ctf-run-01/manual-grade.md
```
## 设计理念
The Scaffolding 在设计上具有高效的 token 使用率。技能会被选择性地加载,笔记将状态外部化而不是消耗上下文,而 LatticeMind 的置信度评分可防止代理对不相关的发现进行推理。根据您的设置,它可以完全在本地或云端基础设施上运行。
## 负责任的使用
本项目仅供安全研究和教育之用。请仅在获得授权的系统上使用。
### 致谢
- [k3nn3dy-ai](https://github.com/k3nn3dy-ai) 提供的 [Kali MCP](https://github.com/k3nn3dy-ai/kali-mcp) —
此框架的重要组成部分,它通过模型上下文协议提供对 Kali Linux 安全工具的直接访问。
该代理位于三个工具层的中心:
- **LatticeMind** — 运行针对性扫描,按置信度对发现进行评分,为代理呈现需要推理的候选项
- **Kali MCP** — 按需执行标准安全工具
- **GitHub MCP** — 搜索漏洞利用、PoC 和参考实现
引导技能在会话开始时加载特定领域的知识。笔记会持久保存会话状态,并在每次解题后反馈到技能中。
## 开始使用
**前置条件**
- Docker
- 支持 MCP 的 AI 代理
**设置**
1. 克隆此仓库
2. 将 `.env.example` 复制为 `.env` 并填入您的 API 密钥/路径
3. 设置 MCP 并使用脚手架脚本启动您首选的代理:
pip install -r scaffold/requirements.txt
python scaffold.py
*交互式 TUI 将允许您配置 MCP、初始化项目并启动代理(Gemini、Cursor、OpenCode、Codex、Copilot、Claude、Antigravity)。*
## 项目结构
```
(root)/
├── .agents/ # Agent skill definitions
├── .cursor/ # Cursor IDE configuration
├── .gemini/ # Gemini CLI configuration
├── .github/ # GitHub integration
├── .opencode/ # OpenCode agent configuration
├── ctf-benchmarking/ # 5-challenge hard CTF benchmark manifests/templates
├── kali-mcp/ # Kali Linux MCP server integration
├── AGENTS.md # Shared agent instructions
├── HUMAN.md # Human-facing documentation
└── README.md
```
## 技能
代理会根据挑战类型加载特定领域的技能文件。每个技能都编码了从过去解题中总结出的侦察模式、攻击链和经验教训。
| 技能 | 覆盖范围 |
|---|---|
| `agent-setup` | 工具就绪状态和依赖项检查 |
| `agent-calibration` | 工作流优化和反馈 |
| `crypto` | 编码、RSA、椭圆曲线、哈希攻击 |
| `forensics` | 文件、内存、网络和多媒体分析 |
| `mobile` | 移动应用安全测试 |
| `network` | 侦察和网络评估 |
| `pwn` | 栈、堆和格式化字符串漏洞利用 |
| `recon` | 目标发现和侦察 |
| `reverse-engineering` | 二进制分析和 RE |
| `web` | Web 应用安全测试 |
## 技能契约与基准指标
为了保持不同代理间技能质量的一致性,此仓库包含:
- 规范契约:`.agents/standards/skill-contract.yaml`
- 机器可读契约:`.agents/standards/skill-contract.json`
- 质量门禁配置:`.agents/standards/quality-gate.json`
- Router 单一事实来源:`.agents/standards/router-spec.json`
- 可重现的基准生成器:`tools/skills/baseline_metrics.py`
- 验证器:`tools/skills/validate_skills.py`
- 归一化器:`tools/skills/normalize_skills.py`
- Router 生成器:`tools/skills/generate_router_wrappers.py`
- 冒烟评估门禁:`tools/skills/smoke_eval.py`
- 当前基准快照:`reports/skill-baseline.json`
常用命令:
```
# 生成 baseline
python tools/skills/baseline_metrics.py --output reports/skill-baseline.json
# 规范化已知的 markdown 问题
python tools/skills/normalize_skills.py --write --fix-footnotes
# 检查规范化漂移 (CI-safe)
python tools/skills/normalize_skills.py --check --fix-footnotes
# 对照 contract 进行验证
python tools/skills/validate_skills.py --report reports/skill-validation.json
# 根据单一 spec 重新生成所有 router wrappers
python tools/skills/generate_router_wrappers.py
# 运行端到端质量门禁
python tools/skills/smoke_eval.py --output reports/skill-smoke-eval.json
```
CI 强制执行位于 `.github/workflows/skills-quality.yml` 中。
### 低成本 Cursor 自动基准测试 (<=15 个任务)
使用阶段路由基准测试,以低成本对真实代理行为进行合理性检查:
所有基准测试运行器默认使用 `--model composer-2` 以确保进行一致的 A/B 比较。
```
python tools/benchmarks/run_cursor_phase_benchmark.py ^
--tasks tools/benchmarks/cursor_phase_tasks.json ^
--max-tasks 10 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-auto-phase-benchmark.json
```
任务集文件:`tools/benchmarks/cursor_phase_tasks.json`(默认为 10 个任务;硬性上限为 15 个)。
### 安全基准测试(目前仅限技能,MCP 比较将在稍后进行)
首先使用仅技能配置文件运行更丰富的安全基准测试:
```
python tools/benchmarks/run_cursor_security_benchmark.py ^
--profile skills-only ^
--tasks tools/benchmarks/cursor_security_tasks.json ^
--max-tasks 12 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-security-skills-only.json
```
稍后,在启用 Kali/Lattice MCP 后,运行:
```
python tools/benchmarks/run_cursor_security_benchmark.py ^
--profile mcp-enabled ^
--tasks tools/benchmarks/cursor_security_tasks.json ^
--max-tasks 12 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-security-mcp-enabled.json
```
然后进行比较:
```
python tools/benchmarks/compare_cursor_benchmarks.py ^
--baseline reports/benchmarks/cursor-security-skills-only.json ^
--candidate reports/benchmarks/cursor-security-mcp-enabled.json ^
--output reports/benchmarks/cursor-security-comparison.json
```
### 漏洞查找基准测试(真值质量)
运行高难度但低成本的漏洞查找基准测试(最多 20 个任务),包含严格的 JSON 发现结果和 TP/FP/FN 评分:
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile control ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-control.json
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile skills-only ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-skills-only.json
```
同时也支持自适应和轻量级框架配置文件:
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile adaptive ^
--model gpt-5.4-mini-high ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--output reports/benchmarks/cursor-vuln-adaptive.json
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile skills-lite ^
--model gemini-3-flash ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--verify-findings ^
--output reports/benchmarks/cursor-vuln-skills-lite.json
```
稍后(在启用 MCP 后):
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile mcp-enabled ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-mcp-enabled.json
```
比较两次漏洞运行结果:
```
python tools/benchmarks/compare_cursor_vuln_benchmarks.py ^
--baseline reports/benchmarks/cursor-vuln-control.json ^
--candidate reports/benchmarks/cursor-vuln-skills-only.json ^
--output reports/benchmarks/cursor-vuln-control-vs-skills.json
```
运行包含 2 次运行的实验(对照组对比仅技能组)并进行聚合:
```
python tools/benchmarks/run_cursor_vuln_experiment.py ^
--profiles control skills-only ^
--runs 2 ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-experiment-runs2.json
```
根据所有运行响应生成客观和主观评分:
```
python tools/benchmarks/grade_cursor_vuln_responses.py ^
--experiment reports/benchmarks/cursor-vuln-experiment-runs2.json ^
--output reports/benchmarks/cursor-vuln-manual-grade.json
```
生成整合的 runs3 排行榜(JSON + Markdown):
```
python tools/benchmarks/generate_vuln_leaderboard.py ^
--input-root reports/benchmarks/model-sweep ^
--output-json reports/benchmarks/model-sweep-leaderboard.json ^
--output-md reports/benchmarks/model-sweep-leaderboard.md
```
默认情况下,漏洞比较侧重于效能指标;仅在明确需要延迟/token 增量时才添加 `--include-cost`。
### Docker 化的高难度 CTF 基准测试(包含 5 个挑战的测试平台)
该仓库还包含一个 Docker 化的基准测试套件,每个类别(`web`、`pwn`、`crypto`、`forensics`、`reverse-engineering`)各有一个高难度挑战,并在运行结束时强制要求提供用于手动评分的 writeup。
获取源码:
```
python tools/benchmarks/fetch_ctf_sources.py ^
--manifest ctf-benchmarking/manifest.json ^
--source-root ctf-benchmarking/sources
```
运行基准测试:
```
python tools/benchmarks/run_cursor_ctf_benchmark.py ^
--manifest ctf-benchmarking/manifest.json ^
--source-root ctf-benchmarking/sources ^
--model composer-2 ^
--output-dir reports/benchmarks/ctf-run-01
```
生成评分工作表产物:
```
python tools/benchmarks/grade_cursor_ctf_writeups.py ^
--run-report reports/benchmarks/ctf-run-01/run-report.json ^
--rubric ctf-benchmarking/grading/rubric.json ^
--output reports/benchmarks/ctf-run-01/manual-grade.json ^
--worksheet-md reports/benchmarks/ctf-run-01/manual-grade.md
```
## 设计理念
The Scaffolding 在设计上具有高效的 token 使用率。技能会被选择性地加载,笔记将状态外部化而不是消耗上下文,而 LatticeMind 的置信度评分可防止代理对不相关的发现进行推理。根据您的设置,它可以完全在本地或云端基础设施上运行。
## 负责任的使用
本项目仅供安全研究和教育之用。请仅在获得授权的系统上使用。
### 致谢
- [k3nn3dy-ai](https://github.com/k3nn3dy-ai) 提供的 [Kali MCP](https://github.com/k3nn3dy-ai/kali-mcp) —
此框架的重要组成部分,它通过模型上下文协议提供对 Kali Linux 安全工具的直接访问。
该代理位于三个工具层的中心:
- **LatticeMind** — 运行针对性扫描,按置信度对发现进行评分,为代理呈现需要推理的候选项
- **Kali MCP** — 按需执行标准安全工具
- **GitHub MCP** — 搜索漏洞利用、PoC 和参考实现
引导技能在会话开始时加载特定领域的知识。笔记会持久保存会话状态,并在每次解题后反馈到技能中。
## 开始使用
**前置条件**
- Docker
- 支持 MCP 的 AI 代理
**设置**
1. 克隆此仓库
2. 将 `.env.example` 复制为 `.env` 并填入您的 API 密钥/路径
3. 设置 MCP 并使用脚手架脚本启动您首选的代理:
pip install -r scaffold/requirements.txt
python scaffold.py
*交互式 TUI 将允许您配置 MCP、初始化项目并启动代理(Gemini、Cursor、OpenCode、Codex、Copilot、Claude、Antigravity)。*
## 项目结构
```
(root)/
├── .agents/ # Agent skill definitions
├── .cursor/ # Cursor IDE configuration
├── .gemini/ # Gemini CLI configuration
├── .github/ # GitHub integration
├── .opencode/ # OpenCode agent configuration
├── ctf-benchmarking/ # 5-challenge hard CTF benchmark manifests/templates
├── kali-mcp/ # Kali Linux MCP server integration
├── AGENTS.md # Shared agent instructions
├── HUMAN.md # Human-facing documentation
└── README.md
```
## 技能
代理会根据挑战类型加载特定领域的技能文件。每个技能都编码了从过去解题中总结出的侦察模式、攻击链和经验教训。
| 技能 | 覆盖范围 |
|---|---|
| `agent-setup` | 工具就绪状态和依赖项检查 |
| `agent-calibration` | 工作流优化和反馈 |
| `crypto` | 编码、RSA、椭圆曲线、哈希攻击 |
| `forensics` | 文件、内存、网络和多媒体分析 |
| `mobile` | 移动应用安全测试 |
| `network` | 侦察和网络评估 |
| `pwn` | 栈、堆和格式化字符串漏洞利用 |
| `recon` | 目标发现和侦察 |
| `reverse-engineering` | 二进制分析和 RE |
| `web` | Web 应用安全测试 |
## 技能契约与基准指标
为了保持不同代理间技能质量的一致性,此仓库包含:
- 规范契约:`.agents/standards/skill-contract.yaml`
- 机器可读契约:`.agents/standards/skill-contract.json`
- 质量门禁配置:`.agents/standards/quality-gate.json`
- Router 单一事实来源:`.agents/standards/router-spec.json`
- 可重现的基准生成器:`tools/skills/baseline_metrics.py`
- 验证器:`tools/skills/validate_skills.py`
- 归一化器:`tools/skills/normalize_skills.py`
- Router 生成器:`tools/skills/generate_router_wrappers.py`
- 冒烟评估门禁:`tools/skills/smoke_eval.py`
- 当前基准快照:`reports/skill-baseline.json`
常用命令:
```
# 生成 baseline
python tools/skills/baseline_metrics.py --output reports/skill-baseline.json
# 规范化已知的 markdown 问题
python tools/skills/normalize_skills.py --write --fix-footnotes
# 检查规范化漂移 (CI-safe)
python tools/skills/normalize_skills.py --check --fix-footnotes
# 对照 contract 进行验证
python tools/skills/validate_skills.py --report reports/skill-validation.json
# 根据单一 spec 重新生成所有 router wrappers
python tools/skills/generate_router_wrappers.py
# 运行端到端质量门禁
python tools/skills/smoke_eval.py --output reports/skill-smoke-eval.json
```
CI 强制执行位于 `.github/workflows/skills-quality.yml` 中。
### 低成本 Cursor 自动基准测试 (<=15 个任务)
使用阶段路由基准测试,以低成本对真实代理行为进行合理性检查:
所有基准测试运行器默认使用 `--model composer-2` 以确保进行一致的 A/B 比较。
```
python tools/benchmarks/run_cursor_phase_benchmark.py ^
--tasks tools/benchmarks/cursor_phase_tasks.json ^
--max-tasks 10 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-auto-phase-benchmark.json
```
任务集文件:`tools/benchmarks/cursor_phase_tasks.json`(默认为 10 个任务;硬性上限为 15 个)。
### 安全基准测试(目前仅限技能,MCP 比较将在稍后进行)
首先使用仅技能配置文件运行更丰富的安全基准测试:
```
python tools/benchmarks/run_cursor_security_benchmark.py ^
--profile skills-only ^
--tasks tools/benchmarks/cursor_security_tasks.json ^
--max-tasks 12 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-security-skills-only.json
```
稍后,在启用 Kali/Lattice MCP 后,运行:
```
python tools/benchmarks/run_cursor_security_benchmark.py ^
--profile mcp-enabled ^
--tasks tools/benchmarks/cursor_security_tasks.json ^
--max-tasks 12 ^
--timeout-sec 20 ^
--output reports/benchmarks/cursor-security-mcp-enabled.json
```
然后进行比较:
```
python tools/benchmarks/compare_cursor_benchmarks.py ^
--baseline reports/benchmarks/cursor-security-skills-only.json ^
--candidate reports/benchmarks/cursor-security-mcp-enabled.json ^
--output reports/benchmarks/cursor-security-comparison.json
```
### 漏洞查找基准测试(真值质量)
运行高难度但低成本的漏洞查找基准测试(最多 20 个任务),包含严格的 JSON 发现结果和 TP/FP/FN 评分:
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile control ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-control.json
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile skills-only ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-skills-only.json
```
同时也支持自适应和轻量级框架配置文件:
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile adaptive ^
--model gpt-5.4-mini-high ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--output reports/benchmarks/cursor-vuln-adaptive.json
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile skills-lite ^
--model gemini-3-flash ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--verify-findings ^
--output reports/benchmarks/cursor-vuln-skills-lite.json
```
稍后(在启用 MCP 后):
```
python tools/benchmarks/run_cursor_vuln_benchmark.py ^
--profile mcp-enabled ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-mcp-enabled.json
```
比较两次漏洞运行结果:
```
python tools/benchmarks/compare_cursor_vuln_benchmarks.py ^
--baseline reports/benchmarks/cursor-vuln-control.json ^
--candidate reports/benchmarks/cursor-vuln-skills-only.json ^
--output reports/benchmarks/cursor-vuln-control-vs-skills.json
```
运行包含 2 次运行的实验(对照组对比仅技能组)并进行聚合:
```
python tools/benchmarks/run_cursor_vuln_experiment.py ^
--profiles control skills-only ^
--runs 2 ^
--model composer-2 ^
--tasks tools/benchmarks/cursor_vuln_tasks.json ^
--max-tasks 20 ^
--timeout-sec 120 ^
--store-raw-output ^
--output reports/benchmarks/cursor-vuln-experiment-runs2.json
```
根据所有运行响应生成客观和主观评分:
```
python tools/benchmarks/grade_cursor_vuln_responses.py ^
--experiment reports/benchmarks/cursor-vuln-experiment-runs2.json ^
--output reports/benchmarks/cursor-vuln-manual-grade.json
```
生成整合的 runs3 排行榜(JSON + Markdown):
```
python tools/benchmarks/generate_vuln_leaderboard.py ^
--input-root reports/benchmarks/model-sweep ^
--output-json reports/benchmarks/model-sweep-leaderboard.json ^
--output-md reports/benchmarks/model-sweep-leaderboard.md
```
默认情况下,漏洞比较侧重于效能指标;仅在明确需要延迟/token 增量时才添加 `--include-cost`。
### Docker 化的高难度 CTF 基准测试(包含 5 个挑战的测试平台)
该仓库还包含一个 Docker 化的基准测试套件,每个类别(`web`、`pwn`、`crypto`、`forensics`、`reverse-engineering`)各有一个高难度挑战,并在运行结束时强制要求提供用于手动评分的 writeup。
获取源码:
```
python tools/benchmarks/fetch_ctf_sources.py ^
--manifest ctf-benchmarking/manifest.json ^
--source-root ctf-benchmarking/sources
```
运行基准测试:
```
python tools/benchmarks/run_cursor_ctf_benchmark.py ^
--manifest ctf-benchmarking/manifest.json ^
--source-root ctf-benchmarking/sources ^
--model composer-2 ^
--output-dir reports/benchmarks/ctf-run-01
```
生成评分工作表产物:
```
python tools/benchmarks/grade_cursor_ctf_writeups.py ^
--run-report reports/benchmarks/ctf-run-01/run-report.json ^
--rubric ctf-benchmarking/grading/rubric.json ^
--output reports/benchmarks/ctf-run-01/manual-grade.json ^
--worksheet-md reports/benchmarks/ctf-run-01/manual-grade.md
```
## 设计理念
The Scaffolding 在设计上具有高效的 token 使用率。技能会被选择性地加载,笔记将状态外部化而不是消耗上下文,而 LatticeMind 的置信度评分可防止代理对不相关的发现进行推理。根据您的设置,它可以完全在本地或云端基础设施上运行。
## 负责任的使用
本项目仅供安全研究和教育之用。请仅在获得授权的系统上使用。
### 致谢
- [k3nn3dy-ai](https://github.com/k3nn3dy-ai) 提供的 [Kali MCP](https://github.com/k3nn3dy-ai/kali-mcp) —
此框架的重要组成部分,它通过模型上下文协议提供对 Kali Linux 安全工具的直接访问。标签:AI自动化, CISA项目, CTF, LLM代理, MCP协议, 安全工具, 漏洞挖掘, 红队工具