Get setup help · Share your dubs · Vote on the roadmap · Early access to new engines
Get setup help · Share your dubs · Vote on the roadmap · Early access to new engines
## 功能
🎙️ 声音克隆
3 秒音频片段 → 镜像任何声音。
646 种语言,零样本。
|
🎨 声音设计
性别、年龄、口音、音调、语速、
情感、方言 — 随心调节。
|
🎬 视频配音
YouTube URL 或文件 → 转录 →
翻译 → 重新配音 → MP4。
|
⌨️ 听写小组件
在任何应用中按下 ⌘+⇧+Space。
自动转录、自动粘贴、然后自动隐藏。
|
🔊 人声分离
由 Demucs 驱动。将语音与
音乐分离,保留背景音。
|
👥 说话人分离
Pyannote + WhisperX。
自动识别谁说了什么。
|
📦 批量队列
拖入 50 个视频,然后放手不管。
每个任务都有进度条。
|
🤖 MCP 服务器
从 Claude、Cursor 或任何
MCP 客户端中使用 OmniVoice。
|
🛡️ AI 水印
AudioSeal (Meta)。不可见,
经受得住压缩处理。
|
🔐 100% 本地运行
无需密钥、无需云端、无需账号。
仅在你的设备上运行。
|
⚡ GPU 自动检测
CUDA · MPS · ROCm · CPU。
≤8 GB?自动卸载。
|
🧩 可扩展
继承 TTSBackend,
只需 ~50 行代码即可添加任何引擎。
|
## 快速开始
各操作系统的安装指南 — 选择你的系统并按照指南从头到尾操作:
- **macOS** — [docs/install/macos.md](docs/install/macos.md)
- **Windows** — [docs/install/windows.md](docs/install/windows.md)
- **Linux** — [docs/install/linux.md](docs/install/linux.md)
- **Docker** — [docs/install/docker.md](docs/install/docker.md) · [Docker Hub: `palashdeb/omnivoice-studio`](https://hub.docker.com/r/palashdeb/omnivoice-studio)
遇到问题了?首先运行内置的自检功能 — 在应用中点击 **Settings → About → "Run
self-check"**,或者在检出目录中运行 `uv run python backend/main.py --diagnose`
(`--deep` 还会测试加载当前活动的引擎)。然后查看
[docs/install/troubleshooting.md](docs/install/troubleshooting.md) 了解
排名前 10 的安装错误。当运行时出现问题时,应用内的错误 UI 会提供指向这些条目的深层链接,并且 **Settings → About → "Save diagnostic
bundle"** 会打包脱敏日志和自检报告,用于提交 Bug 报告。
关于 Hugging Face token 设置,请参阅
[docs/setup/huggingface-token.md](docs/setup/huggingface-token.md)。关于
特定于说话人分离的限制,请参阅
[docs/features/diarization.md](docs/features/diarization.md)。关于下载
速度、⚡ 快速下载 (Xet) 状态以及受限网络 / 镜像
选项,请参阅 [docs/downloading-models.md](docs/downloading-models.md)。
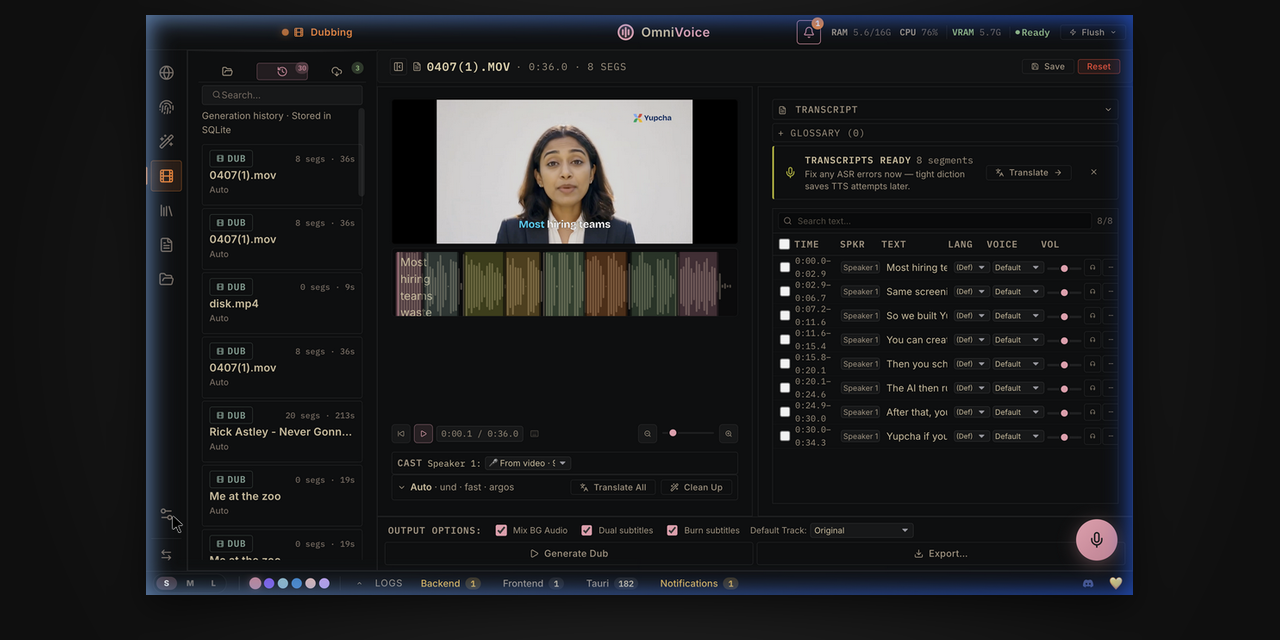
## 截图
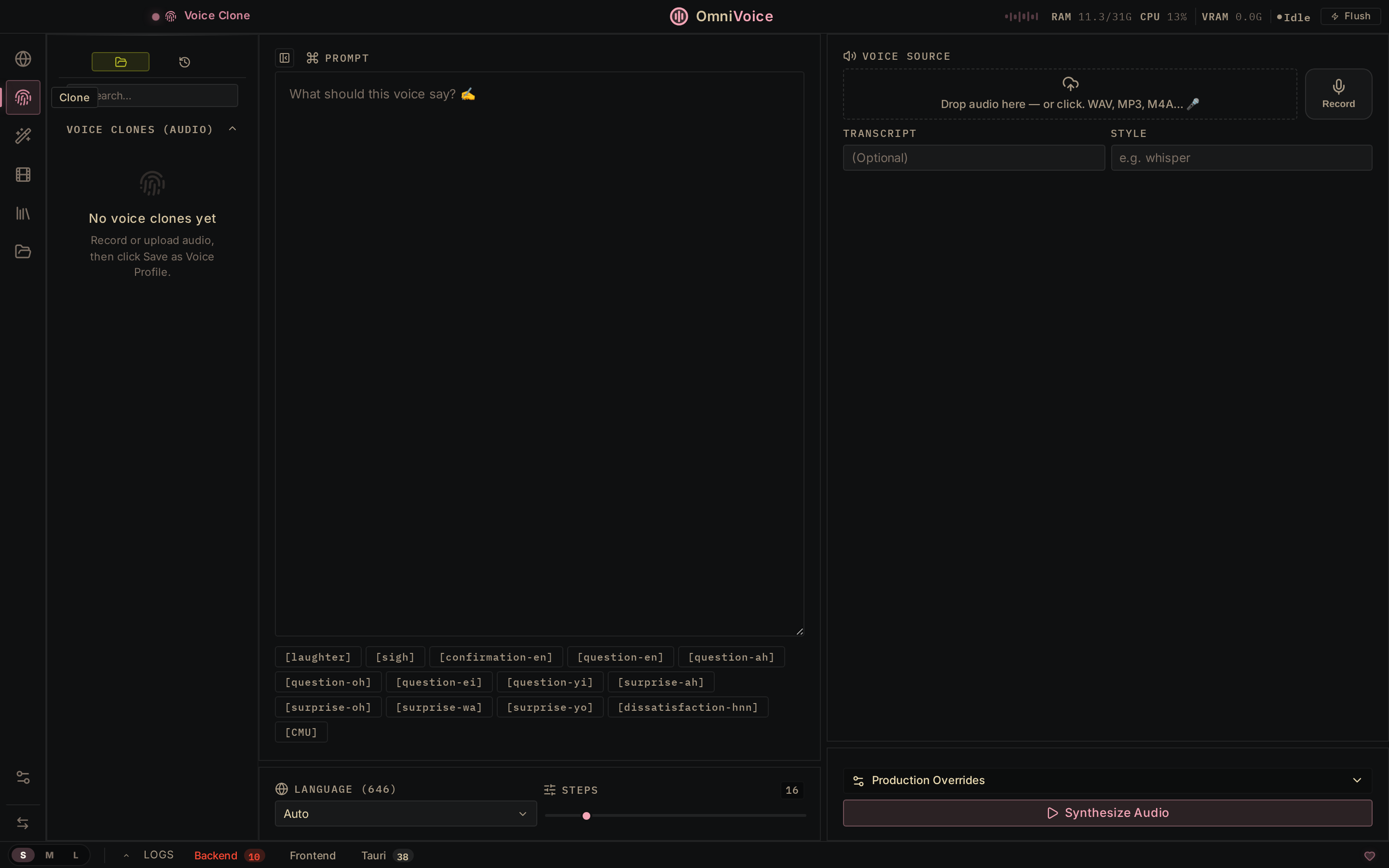
Voice Clone
Drop a 3-second clip → mirror any voice. 646 languages, zero-shot.
|
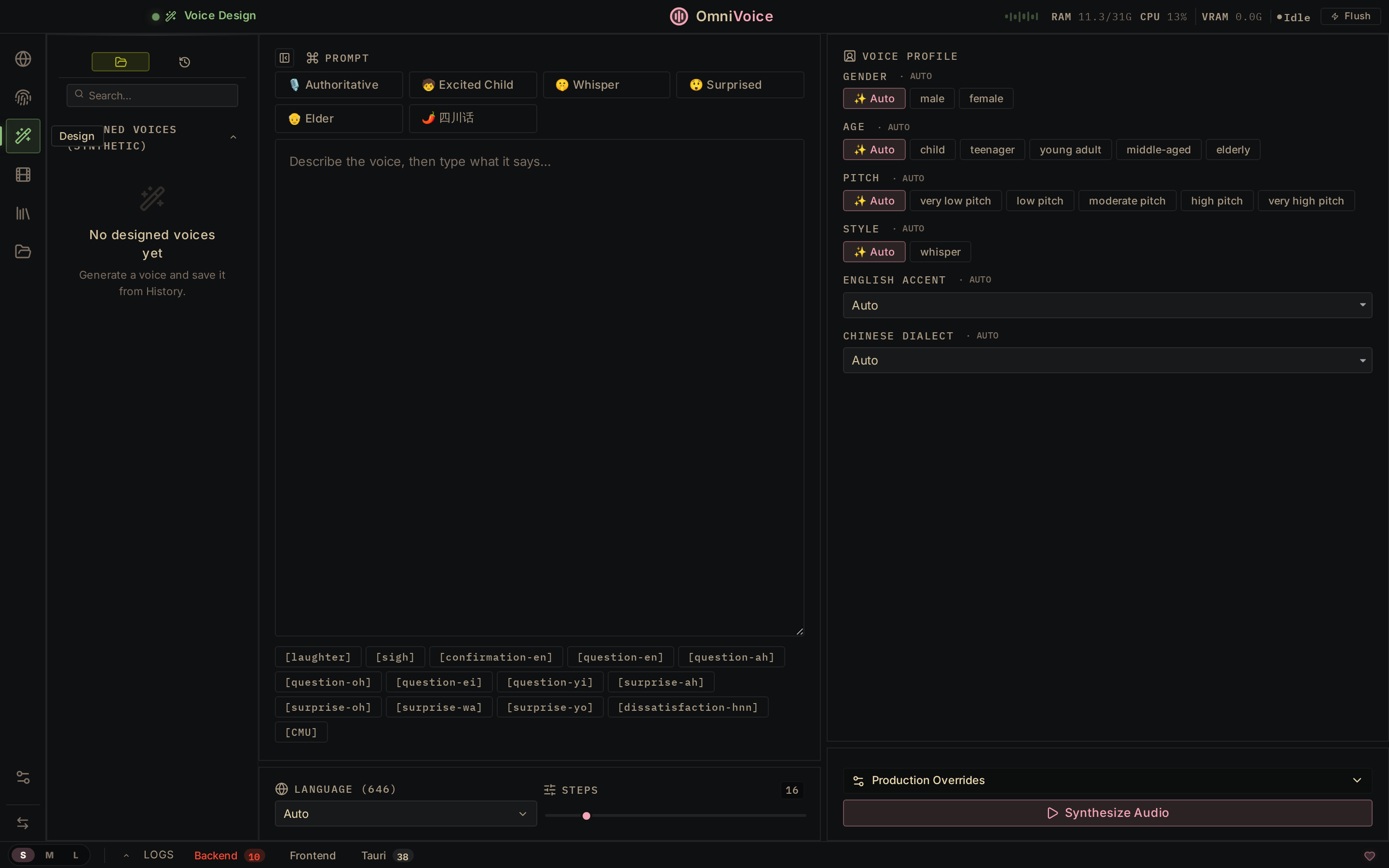
Voice Design
Build new voices from scratch — gender, age, accent, pitch, style.
|
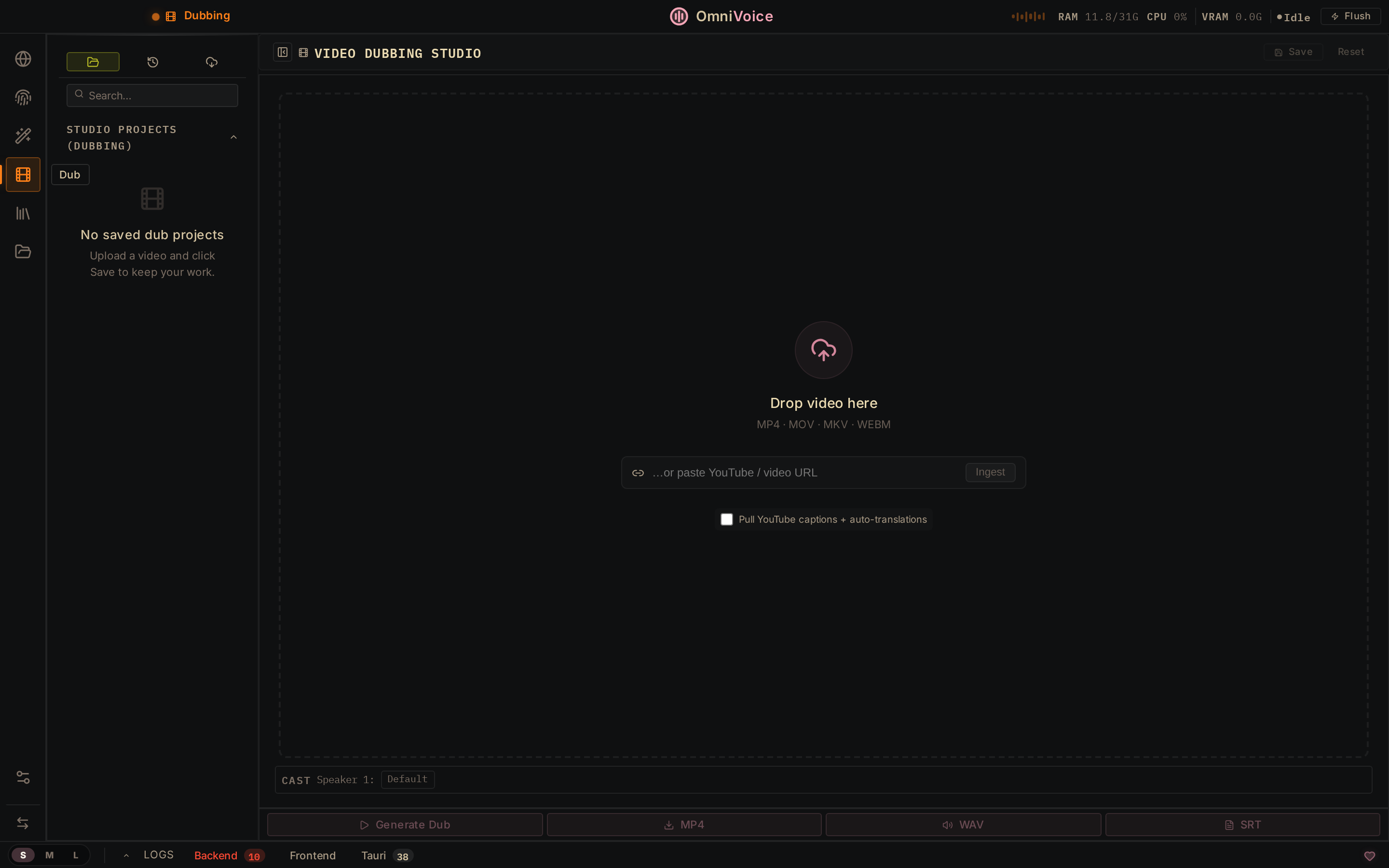
Video Dubbing
Upload or paste a YouTube URL. Transcribe, translate, re-voice, export.
|
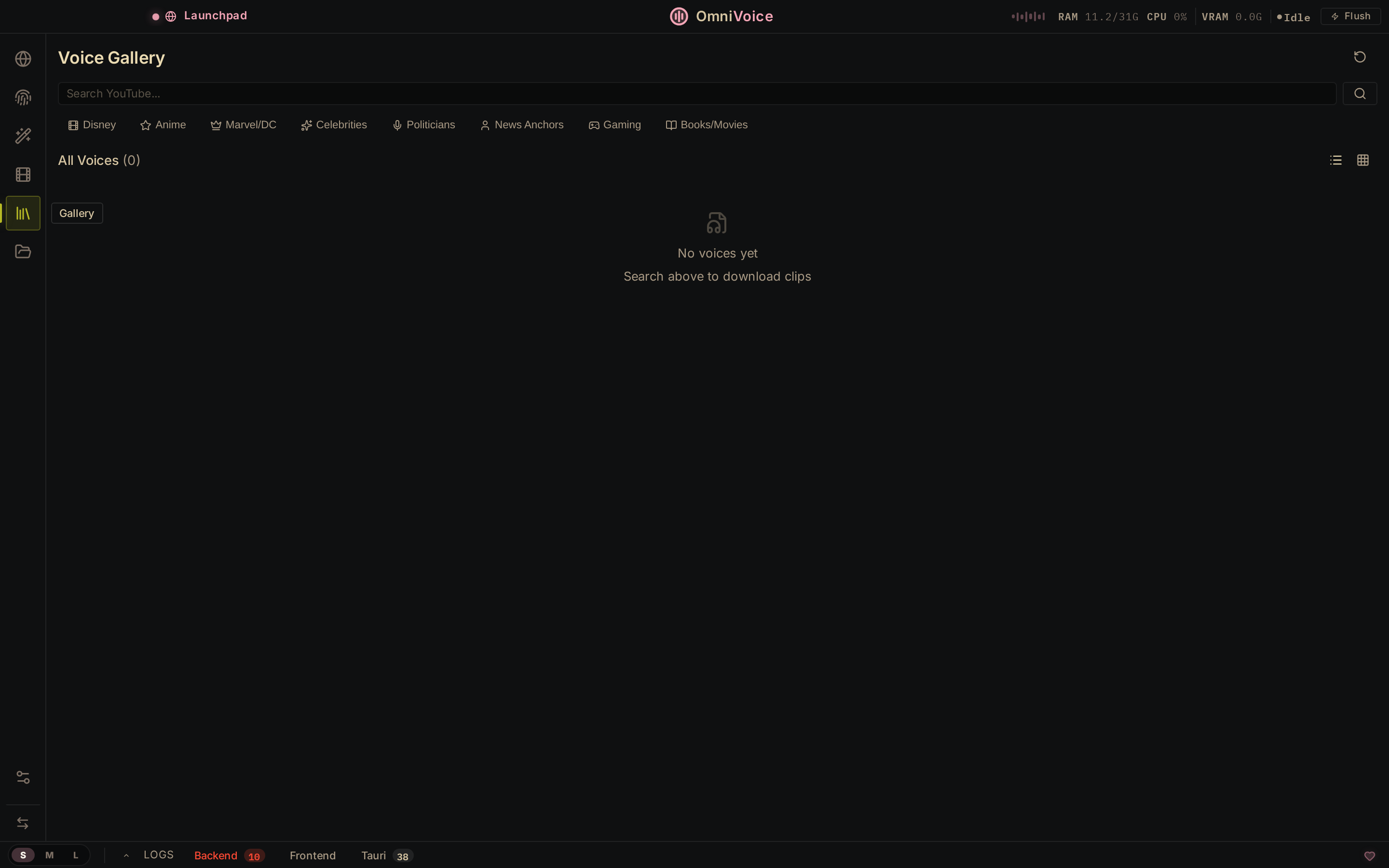
Voice Gallery
Search YouTube, browse categories, download clips, build your library.
|
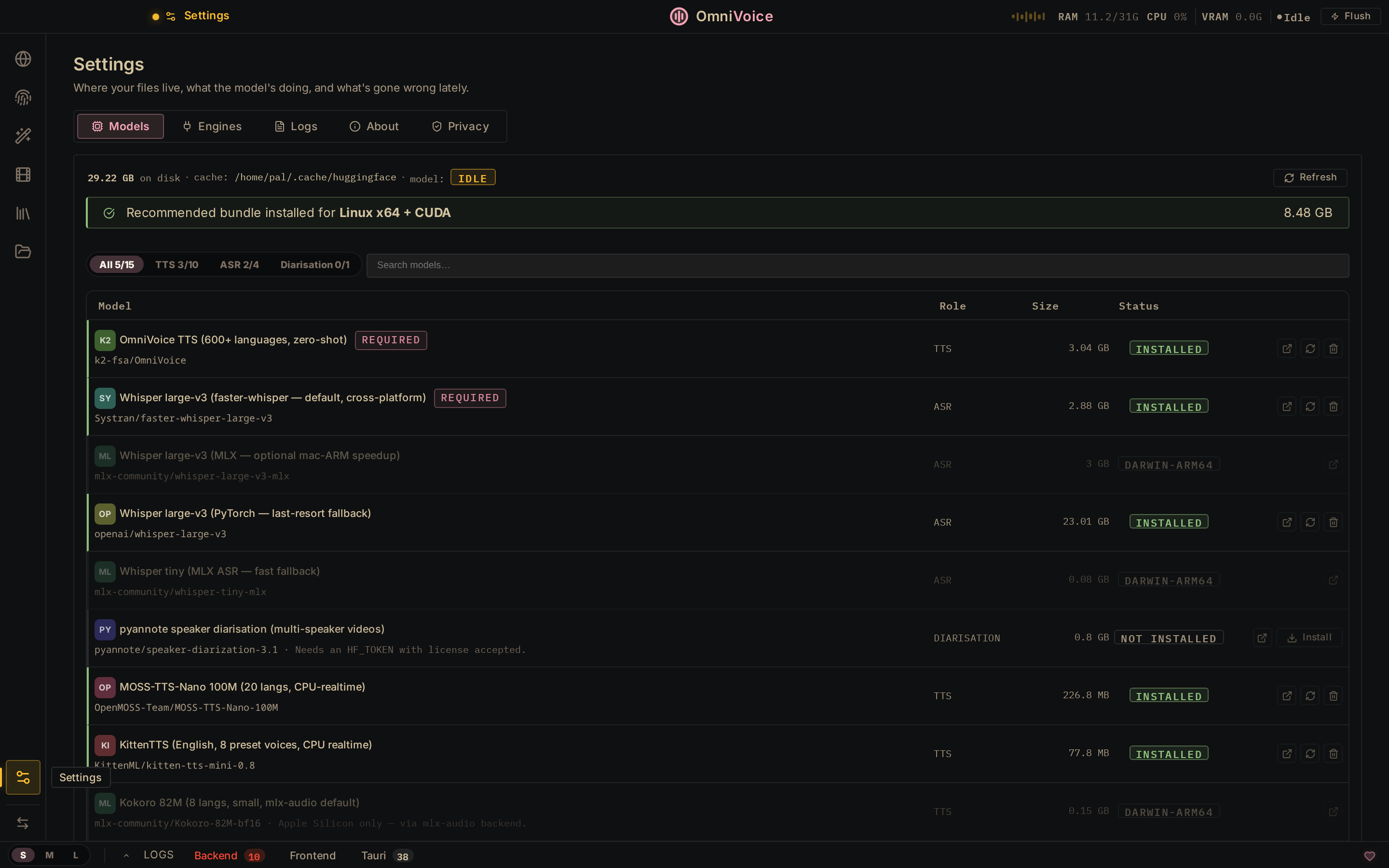
Settings → Models
15 models. One-click install. Auto-detects your platform (CUDA / MPS / CPU).
|
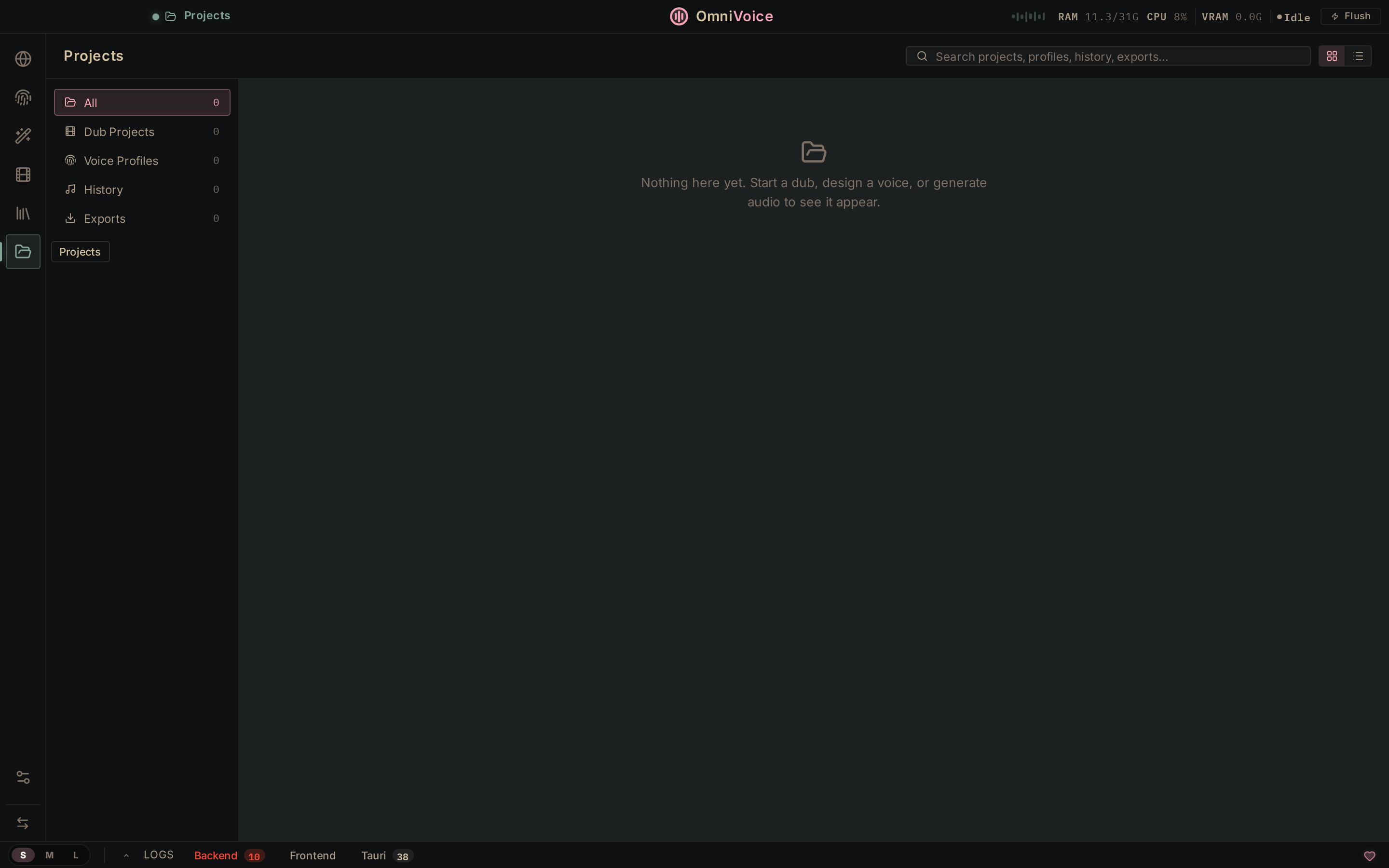
Projects
Dub projects, voice profiles, generation history, exports — all searchable.
|
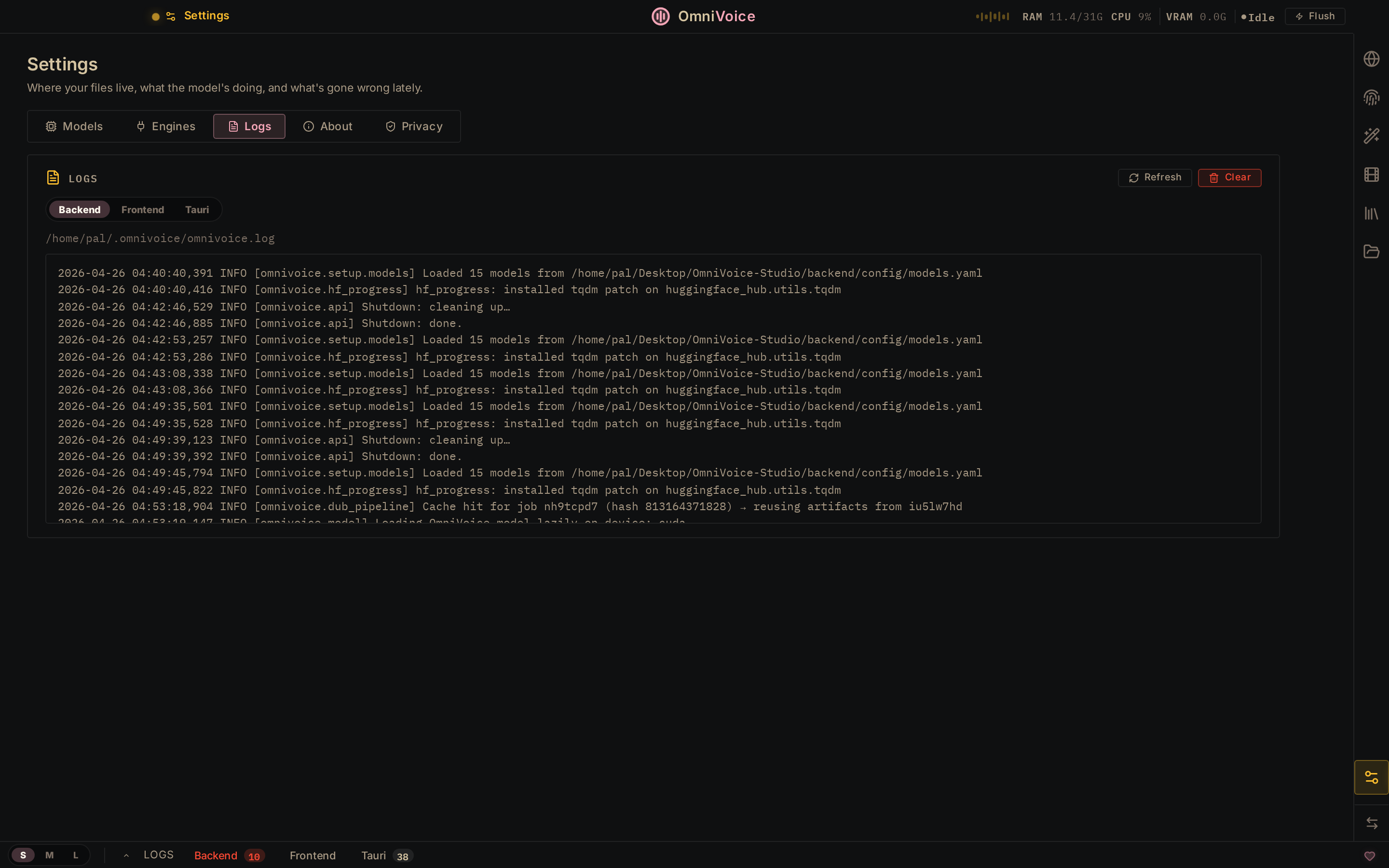
Settings → Logs
Live backend, frontend, and Tauri runtime logs. Filter, refresh, clear.
|
## 为什么选择 OmniVoice Studio?
ElevenLabs 每月收取 **$5–$330**,并在他们的服务器上处理你的音频。OmniVoice Studio 运行在**你自己的硬件上,没有任何使用限制!**
| | **ElevenLabs** | **OmniVoice Studio** |
|---|---|---|
| **定价** | $5–$330/月,按字符数计费 | 免费且开源 (AGPL-3.0) · 专有用途需 [商业许可](#license) |
| **声音克隆** | ✅ 3秒片段 | ✅ 3秒片段,零样本 |
| **声音设计** | ✅ 性别、年龄 | ✅ 性别、年龄、口音、音调、风格、方言 |
| **语言** | 32 | **646** |
| **视频配音** | ✅ 仅限云端 | ✅ 完全本地化 |
| **数据隐私** | 音频发送至云端 | **数据绝不离开你的设备** |
| **API 密钥** | 必需 | 无需 |
| **GPU 支持** | N/A (云端) | CUDA · Apple Silicon · ROCm · CPU |
| **桌面应用** | ❌ | ✅ macOS · Windows · Linux |
| **可定制性** | ❌ 闭源 | ✅ 尽情 Fork、扩展和发布 |
OmniVoice Studio 为你提供专业级的 AI 工具,无需订阅,也无需依赖云端。
Convinced? Come build with us.

## 系统要求
| | **最低配置** | **推荐配置** |
|---|---|---|
| **操作系统** | Windows 10, macOS 12+, Ubuntu 20.04+ | 任何现代的 64 位操作系统 |
| **内存 (RAM)** | 8 GB | 16 GB+ |
| **显存 (VRAM) (GPU)** | 4 GB (自动将 TTS 卸载到 CPU) | 8 GB+ (NVIDIA RTX 3060+) |
| **硬盘** | 10 GB 可用空间(模型 + 缓存) | 20 GB+ SSD |
| **Python** | 3.10+ (由 `uv` 管理) | 3.11–3.12 |
| **GPU** | 可选 — 仅用 CPU 也可运行 | NVIDIA CUDA · Apple Silicon MPS · AMD ROCm |
### TTS 引擎
OmniVoice 提供了一个多引擎 TTS 后端。默认引擎 是始终可用的;其他引擎是可选的,并支持自动检测。你可以在 **Settings → TTS Engine** 中或通过 `OMNIVOICE_TTS_BACKEND` 环境变量切换引擎。
| 引擎 | 语言 | 克隆 | 指令控制 | Linux | macOS ARM | Windows | 许可证 |
|--------|:---------:|:-----:|:--------:|:-----:|:---------:|:-------:|:-------:|
| **OmniVoice** (默认) | 600+ | ✅ | ✅ | ✅ CUDA/CPU | ✅ MPS | ✅ CUDA/CPU | 内置 |
| **CosyVoice 3** | 9 + 18 种方言 | ✅ | ✅ | ✅ CUDA/CPU | ✅ MPS | ✅ CUDA/CPU | Apache-2.0 |
| **MLX-Audio** (Kokoro, Qwen3-TTS, CSM, Dia, …) | 多语言 | 视情况而定 | 视情况而定 | ❌ | ✅ 原生 | ❌ | 视情况而定 |
| **VoxCPM2** | 30 | ✅ | ✅ | ✅ CUDA/CPU | ✅ MPS | ✅ CUDA/CPU | Apache-2.0 |
| **MOSS-TTS-Nano** | 20 | ✅ | ❌ | ✅ CUDA/CPU | ✅ CPU | ✅ CUDA/CPU | Apache-2.0 |
| **KittenTTS** | 英语 | ❌ | ❌ | ✅ CPU | ✅ CPU | ✅ CPU | MIT |
### ASR 引擎
OmniVoice 提供了一个多引擎 ASR(语音转文本)后端,支持听写、视频配音和字幕生成 — 全部在本地完成。**WhisperX** 是跨平台的默认引擎;其余均为可选,并支持自动检测。你可以在 **Settings → ASR Engine** 中或通过 `OMNIVOICE_ASR_BACKEND` 环境变量进行切换。
| 引擎 | `OMNIVOICE_ASR_BACKEND` | 语言 | 最适合 |
|--------|-------------------------|:---------:|----------|
| **WhisperX** (默认) | `whisperx` | ~100 | 配音和字幕 — 通过 wav2vec2 强制对齐实现词级时间戳 |
| **Faster-Whisper** | `faster-whisper` | ~100 | 在 Linux / macOS / Windows 上实现快速转录 (CTranslate2) |
| **MLX Whisper** | `mlx-whisper` | ~100 | Apple Silicon 原生速度 (Apple MLX / Metal) |
| **PyTorch Whisper** | `pytorch-whisper` | ~100 | 通过 🤗 Transformers 实现 CUDA / CPU 回退 |
| **Parakeet TDT** | `nemo-parakeet` | 英语 + 25 种欧洲语言 | 业界顶尖 (SOTA) 的英语准确度,自动语言检测 (NVIDIA NeMo,仅限 GPU) |
| **Moonshine** | `moonshine` | 英语 | 边缘计算 / 低延迟,ONNX |
| **FunASR** | `funasr` | 50+ | 多语言一体化 — 内置 VAD + 内联说话人分离 (SenseVoice) |
## 架构
```
┌─────────────────────────────────────────────────┐
│ Frontend (React) │
│ DubTab · VoicePreview · BatchQueue · Gallery │
├─────────────────────────────────────────────────┤
│ Backend (FastAPI) │
│ 97 API endpoints · SSE streaming · SQLite │
├──────────┬──────────┬──────────┬────────────────┤
│ WhisperX │ Demucs │OmniVoice │ Pyannote │
│ ASR │ Source │ TTS │ Diarization │
│ │ Sep. │ │ │
└──────────┴──────────┴──────────┴────────────────┘
CUDA / MPS / ROCm / CPU (auto-detected)
```
## 路线图
### ✅ 已发布
| 类别 | 功能 |
|----------|----------|
| **配音** | 完整的流水线 (转录→翻译→合成→混流),场景感知分割,唇形同步评分,流式 TTS |
| **语音** | 零样本克隆,声音设计,A/B 比较,声音预览小组件,带收藏/标签的图库 |
| **音频** | Demucs 人声分离,分段增益,选择性音轨导出,stem/SRT/VTT/MP3 导出 |
| **多语言** | 多语言批量选择器,支持顺序 GPU 执行的批量配音队列 |
| **说话人分离** | Pyannote ML 说话人分离,自动说话人克隆提取,按说话人分配声音 |
| **基础设施** | Docker 部署,CUDA/MPS/ROCm 自动检测,cuDNN 8 兼容,感知 VRAM 的模型卸载 |
| **AI 来源追踪** | AudioSeal 不可见水印 (类似 SynthID),视频 Logo 叠加,水印检测 API |
| **用户体验** | 撤销/重做,键盘快捷键,拖拽,会话持久化,毛玻璃效果设计系统 |
| **实时事件** | WebSocket 事件总线 — 数据变更时即时侧边栏刷新,指数退避重连 |
| **状态管理** | Zustand store 迁移 — `uiSlice`, `pillSlice`, `dubSlice`, `generateSlice`, `prefsSlice`, `glossarySlice` |
| **桌面端** | 跨平台 Tauri 安装程序 (OS DMG, Windows MSI, Linux deb/AppImage),自动更新基础设施 |
| **Windows 强化** | 跨平台日志路径,Triton 变通方案,HF 符号链接绕过,300 秒健康检查超时 |
| **听写** | 全局系统级热键 (`⌘+⇧+Space`),无边框悬浮小组件,通过 WebSocket 实现流式 ASR,自动粘贴 |
| **批处理流水线** | 完整的批量 TTS:提取 → 转录 → 翻译 → 生成 → 混合 → 导出,并带有实时进度跟踪 |
### 🔜 接下来
- 🎬 **唇形同步 v2** — 结合 wav2lip 的视觉语音时间调整
- 📖 **有声书编辑器** — 支持章节感知的长篇解说
- 🌐 **在线托管 Demo** — 无需安装即可试用 OmniVoice
- 🔌 **插件市场** — 社区贡献的 TTS 引擎和音效
## 常见问题
它真的和 ElevenLabs 一样好吗?
在声音克隆和配音方面,确实如此 — OmniVoice 使用了最先进的 (SOTA) 扩散 TTS 模型,支持 646 种语言(ElevenLabs 仅支持 32 种)。对于大多数用例,质量不相上下。ElevenLabs 的优势在于其打磨精良的云端 API 和预制声音库。而 OmniVoice 的优势在于隐私、成本、语言覆盖范围和可定制性。
它能在 Apple Silicon (M1/M2/M3/M4) 上运行吗?
可以。MPS 加速会被自动检测。针对 Apple 硬件,我们还提供了经过 MLX 优化的 Whisper 模型,以实现更快的转录速度。
我需要多少 VRAM?
最低 4 GB。如果 ≤8 GB,在转录期间 TTS 模型会自动卸载到 CPU。如果 8 GB 以上,所有任务都可以同时在 GPU 上运行。完全没有 GPU?CPU 模式也能工作 — 只是速度较慢(TTS 速度约为原来的 1/3)。
我可以将其用于商业用途吗?
可以 — 商业用途是免费的。OmniVoice Studio 是基于 GNU AGPL-3.0 协议的开源免费软件。因此,个人、教育、研究以及商业/企业用途全部免费:运行它,销售使用它制作的音频,为你自己或客户的视频配音,在你的团队中部署它。由于 AGPL 是一项网络 Copyleft 许可证,如果你修改了 OmniVoice Studio 并通过网络向他人提供该修改版本,你必须根据相同的 AGPL 条款向这些用户提供你修改版本的源代码。想要在闭源或专有产品中嵌入 OmniVoice 而不受这些义务约束?我们提供商业许可证 — 请参阅 许可证。
支持哪些语言?
通过 OmniVoice 模型,TTS 支持 646 种语言。转录 支持 99 种语言。翻译的覆盖范围取决于目标语言对。
我可以添加自己的 TTS 引擎吗?
可以。OmniVoice 使用了一个内置的后端注册表。只需大约 50 行代码即可添加一个引擎:继承 backend/services/tts_backend.py 中的 TTSBackend,并将其添加到底部的 _REGISTRY 字典中。目前内置了六个引擎:OmniVoice, CosyVoice, MLX-Audio (14+ 个子引擎), VoxCPM2, MOSS-TTS-Nano, 和 KittenTTS。详情请参阅 TTS 引擎部分。
## 许可证
OmniVoice Studio 是基于 [**GNU Affero General Public License v3.0 (AGPL-3.0)**](https://www.gnu.org/licenses/agpl-3.0.html) 协议的免费开源软件。
**任何用途均免费 — 包括商业和内部企业用途。** 运行它,销售用它制作的音频,为你自己或客户的视频配音,在你的团队中推广使用 — 全部免费,无需任何许可证。作为一项**网络 Copyleft** 许可证,AGPL 增加了一项义务:如果你**修改**了 OmniVoice Studio 并通过网络将该修改版本提供给他人,你必须根据相同的 AGPL-3.0 条款,向他们公开你修改版本的完整对应源代码。
对于希望在不承担 AGPL-3.0 Copyleft 义务的情况下,将 OmniVoice Studio 嵌入**闭源或专有**产品或服务中的组织,我们提供**商业许可证**。**定价层级即将推出。** 咨询请联系:**OmniVoice@palash.dev**。
由 Han Zhu 开发的内置 `omnivoice/` TTS 模型在上游保持 Apache-2.0 协议。完整的约束性条款请参阅 [`LICENSE`](LICENSE)。