mkultraware/accuretta
GitHub: mkultraware/accuretta
一款完全本地化的零信任 AI 工作区,集成了聊天代理、代码编辑预览和安全分析工具链,所有数据和推理均在用户自己的机器上完成。
Stars: 26 | Forks: 2

# Accuretta
**完全本地化的 AI 工作区。你的模型,你的文件,你的机器。**
[](LICENSE)
[](https://www.python.org/downloads/)
[](https://github.com/ggerganov/llama.cpp)
[](#privacy)
[](#privacy)
[](#quick-start)
 点击上方图片观看演示(约 23 秒,1.9 MB)。
点击上方图片观看演示(约 23 秒,1.9 MB)。
## 它是什么
Accuretta 是一个小巧、友好的桌面 AI 工作区,完全在你的电脑上运行。你只需将一个 GGUF 模型文件放入文件夹中,将其指向二进制文件,就能获得一个带有真实工具使用能力的聊天 UI、一个实时的 HTML 预览窗格、一个 Python 语法检查器,以及一个允许模型读写你选定文件的工作区目录树。该桥接端通过 llama-server 与 llama.cpp 通信,因此你可以获得高速度和丰富的调节选项,而无需自己连接整个技术栈。
它由几个 HTML 文件、一个 CSS 文件、一个 JS 文件和一个 Python 文件构建而成。没有构建步骤,没有 npm,也没有 electron 包装器。你可以在一个下午读完每一行代码。
## 为什么我要开发它
这源于我个人的挫败感。我曾一直为云 AI 订阅付费,却眼睁睁看着规则每隔几周就变一次。一个服务削减了配额,另一个则在同名背后悄悄替换了模型。后来我尝试了 Google Antigravity,意识到我已经厌倦了租用那些随时可能在背后被更改的工具,于是我开始构建一个真正属于我自己的东西。
从第一天起就定下的两条规则:
1. 模型存在于我的硬盘上。除非我明确要求,否则任何东西都不会离开我的电脑。
2. 拒绝订阅。我的 GPU 已经付过钱了。
我刚从 Ollama 转过来时,以为 llama.cpp 只能算是个平替。但事实并非如此。相同的硬件,相同的模型文件,生成速度却明显更快,并且对 KV cache 量化、flash attention 和推测解码等参数有着干净的控制权。代价是你需要自己进行连接。Accuretta 部分扮演了这些连线的角色,并为你包装了一个真正可用的 UI。
## 看看 Agent 的实际操作
Agent 拥有实干的双手。它可以读取文件、写入文件、运行命令、抓取网页、截屏以及检查网络状态。任何破坏性操作(文件写入、shell 命令)都会受到批准卡片的限制,因此不会在无声无息中发生任何危险操作。像网页抓取这类读取操作,可以根据模型和你的设置自动运行。
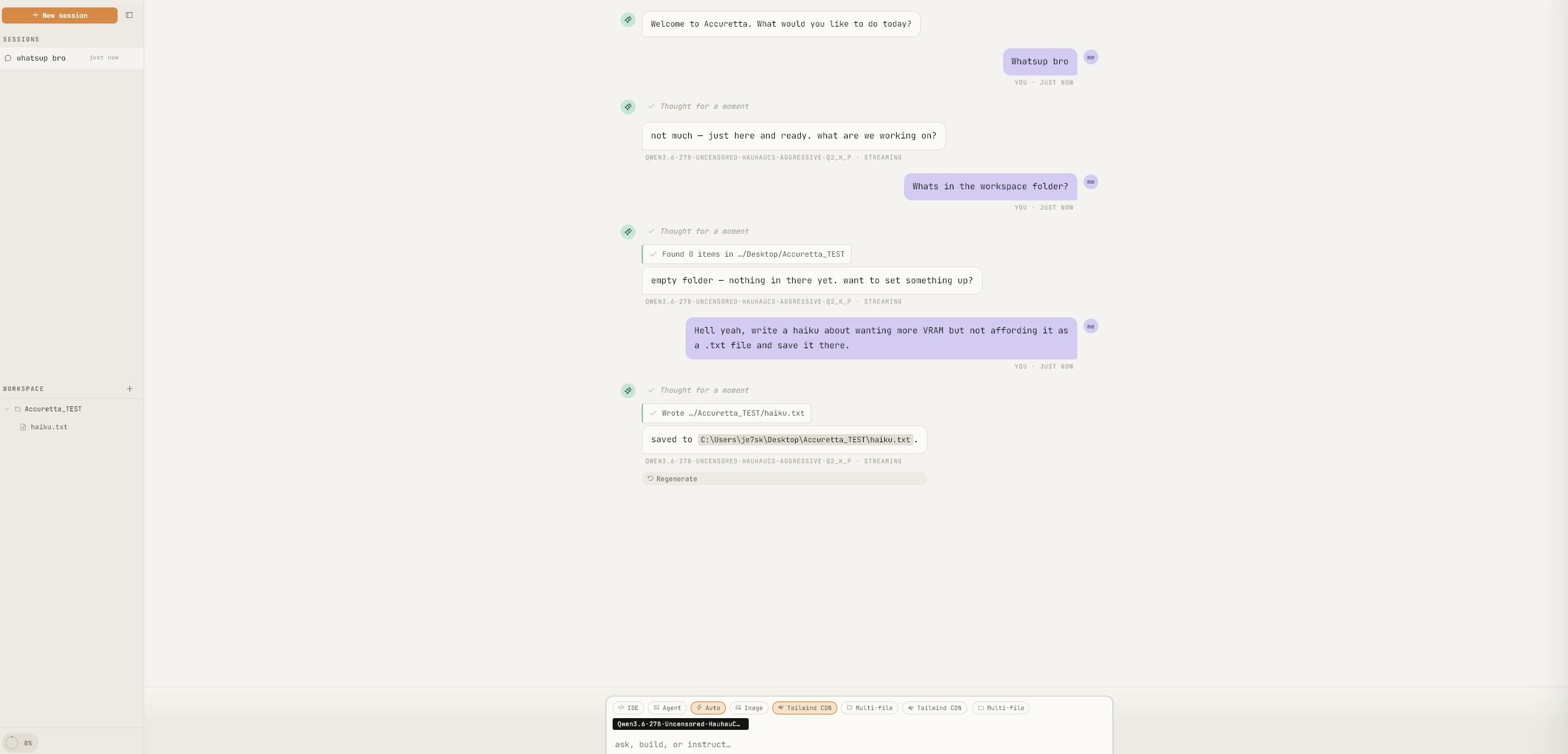
上图:模型发现工作区为空,决定将一首俳句写入 haiku.txt,随后文件便落到了磁盘上。会话、工作区和模型在同一处一目了然。
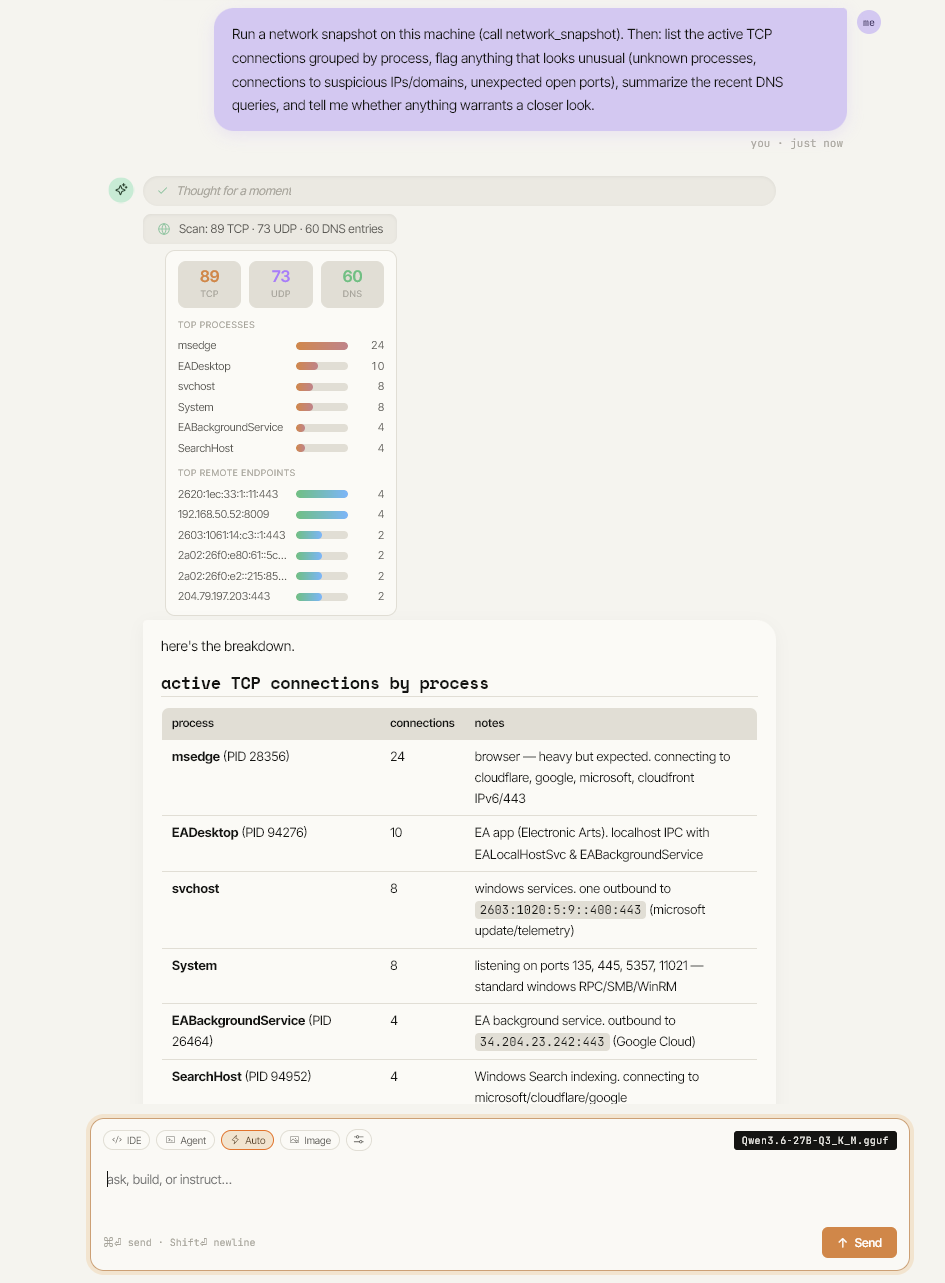
还有一个更有趣的例子。在下图中,模型被要求运行一次网络快照,按进程对活动的 TCP 连接进行分组,标记任何可疑情况,并总结近期的 DNS 活动。它调用了快照工具,获取了结构化的 payload,然后在一个真正的 markdown 表格中对其进行了推理。没有到云端的往返,没有 API 密钥,没有速率限制。
再来一个来自真实会话的例子。我要求 agent 帮助我使用 Peace Equalizer APO 调整我的入耳式监听耳机(Linsoul 7Hz x Crinacle Zero:2)。它搜索了音频评测网站、Reddit 帖子和 AutoEQ 测量数据库,选定了一个目标曲线(Harman In-Ear 2019),为这款特定的 IEM 生成了具有合适增益/Q值/频率的十个参数滤波器,并直接将一个完整的 `.peace` 配置文件写入了 EqualizerAPO 的配置文件夹——其中包括用于防止削波的 PreAmp 设置,以及关于其中一个增益异常激进的提醒。无需从论坛复制粘贴滤波器参数,无需手工将频率表翻译成配置语法。提出请求,批准写入,搞定。
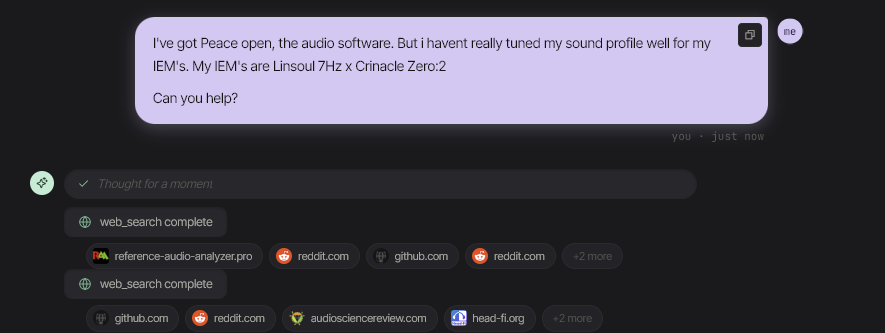
上图:agent 在 reference-audio-analyzer.pro、audiosciencereview.com、head-fi.org 和 Reddit 上搜索特定 IEM 的测量数据和推荐目标。
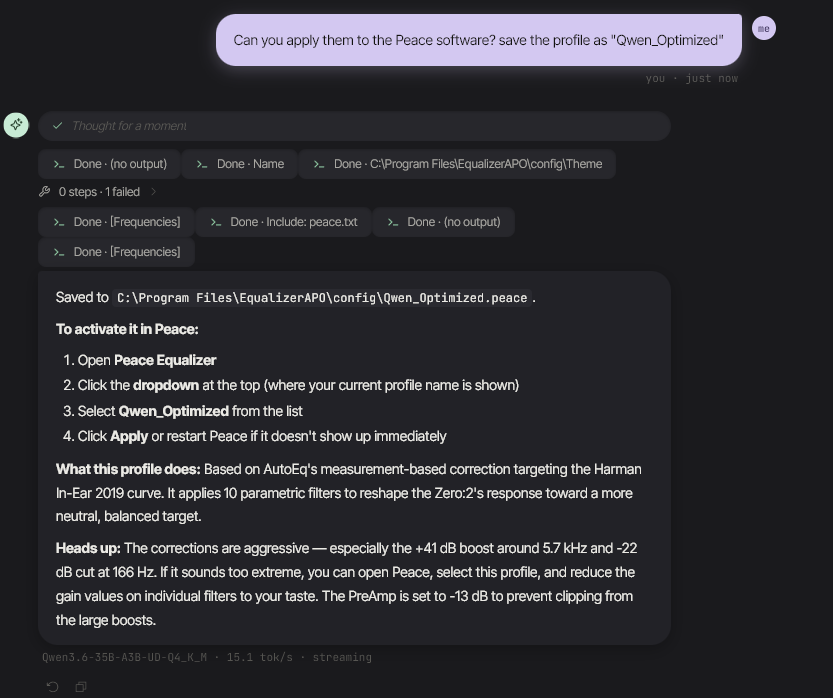
上图:十个参数滤波器被写入到 C:\Program Files\EqualizerAPO\config\Qwen_Optimized.peace,并附带了清晰的激活步骤和针对较激进修正的直白备注,以便我可以在需要时将其回调。
## 你能得到什么
* **带有真实工具使用的聊天。** 读取文件、写入文件、运行 shell 命令、抓取 URL、截屏、检查进程和网络状态。每一次破坏性调用都会经过批准卡片。
* **实时 HTML 预览。** 当模型编写网页时,你可以看到它在对话旁边渲染。一键切换渲染视图和源码。
* **从工作区打开现有的 HTML。** 点击工作区目录树中任何 `.html` 文件旁边的闪电图标,它就会连同其真实的 CSS、JS 和图像加载到预览窗格中。桥接端通过带有严格路径遍历检查的加固端点提供服务,因此 iframe 永远只能访问到你打开的文件夹内的文件。
* **Python 语法检查器。** 点击任何 `.py` 文件旁边的对勾,桥接端就会对其运行 `compile()`。如果解析通过你会看到一个绿色横幅,如果失败则显示带有行号、列号和信息的红色横幅。不会执行任何东西。不运行导入。没有任何风险。
* **针对所有破坏性操作的批准卡片。** 文件写入和 shell 命令总是会提示确认。当你信任模型时,像网页抓取这类读取操作可以自动运行。
* **磁盘上的对话历史。** 会话存放在你控制的文件夹中。分支、重命名、删除它们。没有任何东西被锁死在数据库里。
* **真正的设置抽屉。** 上下文窗口、采样器温度、top p、top k、KV cache 类型、GPU 层数、批次大小、思考预算、模型切换。所有这些都可以在快速重载的过程中即时更改。
* **感知移动端的 UI。** 整个程序可以在手机浏览器上运行。编写器、侧边栏、设置、从菜单滑动返回聊天。无需应用商店,无需安装,只需在同一网络上打开 localhost URL 即可。
* **极小的表面积。** 几个静态文件和一个 Python 脚本。一个下午即可完成审计。
## 一键自动调优
在“设置”中选择一个模型(并设置了 VRAM 等级)会自动运行一个调优器,该调优器会读取 GGUF 头部以获取模型的真实架构——层数、注意力配置、MoE 专家数量、KV 头维度——并计算出你的显卡所能支持的最大上下文窗口以及正确的 CPU/GPU 卸载分配。不再需要手动挑选 `--n-cpu-moe`、`--ctx-size` 或 `--batch-size`。它会帮你选好这些参数,应用它们,重新加载模型,然后你就可以开始聊天了。
* **基于 GGUF 的直接计算,而非凭经验估算。** 每个 token 的 KV cache 成本来自于模型实际的 `2 × n_layer × head_count_kv × head_dim × dtype_bytes`,而不是粗略的大小分级。因此,同一架构的 Q3 版本会比 Q4 版本获得*更多*的上下文,因为较小的权重文件为 KV cache 腾出了更多的 VRAM。
* **感知 MoE。** 当模型是混合专家模型时,调优器会计算出稠密层与专家层的分配,并仅将所需数量的专家层卸载到 CPU 以适应显存,当达到 70% 的层数上限时,它会建议你改用较小的量化版本。推测解码会被自动禁用,因为根据公开基准测试,它在 MoE 上是净负收益的。
* **仅针对上下文增长。** 如果自动调优返回的数字比你已经开始使用的数值要小,则采用较大的值。你保存的 ctx 绝不会在背后被缩小。
* **启动时自我修复。** 每次应用启动时,自动调优都会在后台静默重新运行,如果自你上次保存以来算法有所改进,它会更新标志。一个 toast 通知会告诉你发生了什么变化。
* **一次点击,一次加载。** 选择模型就意味着“为我的 GPU 上的这个模型做正确的事”。没有单独的建议步骤,没有保存步骤,没有手动重载。
## APK 静态分析
将一个 `.apk` 拖入工作区文件夹,模型就可以通过桥接端自带的两个工具直接对其进行审计。
* **`scan_apk(path)`** —— 纯 Python 分诊。无需外部工具,无需批准。返回一份结构化报告:包元数据、签名证书(主题/颁发者/sha256,无密钥字节)、所有请求的权限(并标记出危险权限)、导出组件、dex/本地库/资产清单,以及针对 DEX + `.so` 文件的正则驱动式秘密搜索。搜索范围涵盖 AWS 访问密钥、Google API 密钥、Firebase URL、JWT、GitHub PAT、Stripe 密钥、PEM 私钥块、硬编码的 HTTP 端点、IPv4 字面量以及通用的 `(api[_-]?key|secret|password|token)=…` 赋值模式。发现的结果会进行去重,过长的字面量会在中间进行打码,这样你既能看到足够的上下文来判断严重程度,又不会回显出真实的 token。顶部的 `risk_summary` 字段会展示最关键的信息(debuggable=true、allowBackup、明文流量、危险权限数量、导出组件数量、可能的秘密类型),以便模型能优先处理最重要的内容。
* **`decompile_apk(path, classes?)`** —— 通过壳调用 [JADX](https://github.com/skylot/jadx)。将 Java 源代码和资源写入 APK 旁边的沙盒子目录中。属于破坏性操作(写入文件夹),受批准卡片限制。完成后,模型可以使用现有的 `read_file` 和 `grep_files` 工具浏览输出内容。传递 `classes='com.target.foo.*'` 可限定反编译范围,在处理大型 APK 时能更快完成。
**可选依赖项**(未安装时这些工具会优雅降级):
```
pip install androguard # full manifest / permissions / signing parse for scan_apk
# JADX 1.5+ -> https://github.com/skylot/jadx/releases (需要 Java 11+)
```
如果 JADX 不在 `PATH` 中,请在 `data/settings.json` 中将 `jadx_path` 设置为 `jadx.bat`(Windows)或 `jadx`(Linux/macOS)的完整路径。如果没有 androguard,`scan_apk` 将回退到纯 ZIP 模式——文件清单和秘密搜索仍然会运行,但清单/权限检查将被跳过,报告的 `notes` 字段会告诉你需要安装什么。
## 原生二进制分析
对于 JADX 无法处理的 APK 部分——即 `lib/` 中的 `.so` 文件——桥接端提供了一个 `ghidra_analyze` 工具,它通过 [pyghidra](https://pypi.org/project/pyghidra/) 在进程内运行 Ghidra。与 `scan_apk` 的思路相同:模型会获得一份结构化的 JSON 报告(格式、导入、导出、已定义字符串、函数列表、危险导入标志),以及可选的单个命名函数的类 C 反编译代码。它适用于任何原生二进制文件,而不仅仅是 `.so`——也支持 `.exe`、`.dll`、ELF、Mach-O 和原始固件。
* **`ghidra_analyze(path, function?, decompile?)`** —— 需批准后运行,返回报告。如果设置 `function='SSL_verify'` 和 `decompile=true`,你将获得该函数的伪代码。如果不指定 `function`,你将获得元数据和风险摘要,以便模型选择深入分析的位置。
**设置:**
```
pip install pyghidra
# Ghidra (CLI bundle) -> https://github.com/NationalSecurityAgency/ghidra/releases
# JDK 21+ (Temurin) -> https://adoptium.net
```
然后在 `data/settings.json` 中将你的 Ghidra 安装根目录指向桥接端:
```
"ghidra_path": "C:\\Program Files\\ghidra_12.0.4_PUBLIC"
```
(或者设置 `$GHIDRA_INSTALL_DIR`。如果两者都未设置,将自动检测常见的 Windows 安装模式。)
**性能。** 首次调用会启动 JVM(约 10 秒),然后运行 Ghidra 自动分析(在典型的 `.so` 文件上约需 30 秒)。JVM 在桥接端进程的整个生命周期内保持加载状态,因此第 2 次到第 N 次调用会复用它——分析小文件通常在 5 秒内完成。内存消耗:一旦启动,无论你分析多少个二进制文件,常驻内存约为 600 MB。如果你不打算使用它,请不要安装 `pyghidra`,其导入将是一个空操作。
## 快速分诊 (binary_inspect) 和模式匹配 (yara_scan)
Ghidra 是“显示此函数的伪代码”的合适工具——但“这个 exe 是否值得一看”的正确工具。两个较轻量的工具填补了这一空白,它们能在几毫秒内运行完毕,而不是半分钟,因此模型可以将它们作为默认的起点,只有在分诊结果看起来有趣时才进一步深入分析。
* **`binary_inspect(path)`** —— 通过 [pefile](https://pypi.org/project/pefile/) 和 [pyelftools](https://pypi.org/project/pyelftools/) 进行纯 Python 的 PE/ELF/Mach-O 分诊。返回格式、架构、节(带有 R/W/X 标志和每节的 Shannon 熵)、按 DLL 分组的完整导入表、导出表、Authenticode 签名存在情况、imphash 和加壳提示(`.upx`、`.vmp`、`.themida`、`.aspack` 等)——外加一个结合了危险导入 + 高熵节 + 未签名 PE 的 `risk_summary` 单一短列表。无需批准,在典型的 exe 上约需 50 毫秒。模型借此决定是否值得花费约 30 秒运行 `ghidra_analyze`。
* **`yara_scan(path, rules?, recursive?)`** —— 使用 [yara-python](https://pypi.org/project/yara-python/) 对文件或目录进行模式匹配。内置了一小组捆绑规则,涵盖常见的恶意软件特征(自动运行注册表键、进程注入 API 组合、`mimikatz` 字符串、base64 编码的 MZ 头、编码的 PowerShell、可疑的 paste/discord/ngrok URL)。传递 `rules='C:\\path\\to\\my.yar'` 可指向自定义规则文件,或传递内联规则源字符串进行临时查询。无需批准,单文件扫描在几十毫秒内完成。
**设置:**
```
pip install pefile pyelftools yara-python
```
这三个都是纯 Python wheel 包,在 PyPI 上有预编译的二进制文件——无需折腾编译器,无需 JDK,无需额外配置。如果缺少其中任何一个,工具将返回友好的“install with: pip install …”消息,而不会导致桥接端崩溃。
## 这适合谁
* 想要 Cursor 或 Antigravity 风格体验但不想支付订阅费的人
* 已经拥有不错的 GPU 并宁愿使用它也不愿通过 API 租用的人
* 喜欢折腾、想要频繁切换模型(Qwen、GLM、Llama、Gemma,任何 llama.cpp 支持的模型)并找出最适合自己机器的模型的人
* 注重隐私、不希望他们的草稿、代码或思考被发送到某个服务器上的人
* 任何已经厌倦了看着大型 AI 公司每周决定他们的工具被允许做什么的人
## 它不是什么
* 它不是一个精美的商业产品。存在粗糙的边缘,文档主要就是这个 README。
* 在运行于笔记本电脑上的 24B 模型上,它不会击败 Claude Sonnet 或 GPT 5。本地就是本地。请为任务选择合适的工具。
* 它不是 llama.cpp 的替代品。它是一个位于 llama-server 之上的友好前端。
* 它不试图成为一个代码编辑器。它是一个碰巧能渲染代码、预览 HTML 和检查 Python 语法的聊天工作区。
## 隐私
关于你、你的提示词或你的文件的任何信息都不会离开你的电脑。桥接端只与 localhost 上的两样东西通信:你的 llama-server 实例和你的浏览器。仅此而已。没有遥测,没有分析,没有匿名账户,没有云同步,没有选择退出的屏幕,因为根本没有什么需要退出的。
唯一的出站通道是 agent 自身的网页抓取工具。当模型要求读取 URL 时,该请求会从你的机器发送到该站点,与你的浏览器访问方式相同。有些模型会先通过批准卡片询问,其他的则会作为回答问题的一部分直接执行。无论哪种情况,除非模型认为为了完成你交给它的任务需要从开放网络获取信息,否则不会发送任何内容。
如果你比较多疑(你也应该如此),可以在它旁边运行 Wireshark。你会看到的唯一出站流量就是 agent 抓取的内容。想要完全静默?在断开网络的情况下运行或在防火墙处阻止桥接端进程。模型一旦加载就可以完全离线运行,因此你可以在完全没有互联网的情况下聊上一整天。
## 快速开始
1. 安装 Python 3.10 或更新版本。
2. 安装依赖项:`pip install -r requirements.txt`
3. 在磁盘上准备好 `llama-server`(或在 Windows 上为 `llama-server.exe`)。NVIDIA 显卡请使用 CUDA 版本,其他显卡请使用 Vulkan 版本,如果你胆子够大,请使用 CPU 版本。
4. 在磁盘上准备至少一个 GGUF 模型文件。任何 llama.cpp 可以加载的模型均可。在消费级硬件上,GLM 4.7 系列的 23B Q4 版本或 7B 到 32B 范围内的 Qwen 3 系列指令模型是一个不错的起点。
5. 双击 `start.bat`(Windows)或从仓库根目录运行 `python bridge.py`。
6. 在浏览器中打开打印出的 URL。默认为 `http://localhost:8787`。
7. 打开“设置”,将其指向你的模型文件夹和 llama-server 二进制文件,选择一个模型,然后开始聊天。
第一次会话会在 `bridge.py` 旁边创建一个 `data/` 文件夹,用于保存你的聊天记录、设置、工作区指针和记忆。如果你在意这些内容,请备份它。如果你想从零开始,删除它即可。
## 通过 Tailscale 进行远程访问
桥接端默认监听你的局域网,因此同一网络上的任何设备都可以通过 `http://
:8787` 访问它。将其与 [Tailscale](https://tailscale.com) 配对,你就拥有了自己专属的私人 AI 服务器,可以从任何地方访问——咖啡店里的笔记本电脑、蜂窝网络上的手机、朋友家的沙发上。相同的 UI、相同的模型、相同的对话历史。任何数据都不会离开你的 tailnet。
无需云中继,无需端口转发,无需将你的机器暴露在开放的互联网上。在运行 Accuretta 的机器上和你想要聊天的设备上安装 Tailscale,URL `http://:8787`(或 tailnet IP)就可以直接工作。移动端 UI 正是为这种使用场景构建的——手机浏览器,无需应用商店,无需安装。打开 URL 即可开始使用。
一个不错的副作用是:你的对话和模型永远不会经过别人的数据中心往返。即使你不在家,隐私保护依然有效。
## 仓库布局
```
accuretta/
bridge.py the Python bridge (model launcher, tool runtime, HTTP server)
index.html the UI shell
app.js all UI logic
app.css main stylesheet
colors_and_type.css theme tokens
logo-mark.png the orbital A logo
start.bat minimal Windows launcher
requirements.txt Python dependencies
data/ runtime state, created on first run
media/ readme assets (screenshots, demo video)
```
## 状态
这是一个个人项目。我有心情的时候就会写写代码。欢迎大家提交 Pull requests,但我不会制定路线图或追逐 star。如果你 fork 了它并使其成为你自己的东西,那这就是全部的意义所在。
## 许可证
MIT。参见 [LICENSE](LICENSE)。免费供个人使用。使用它,修改它,发布它。我唯一的请求是,不要把你没写的部分说成是你自己写的。标签:100%本地运行, AI代理, AI编程助手, GGUF模型, HTML/CSS/JS, HTML预览, JSONLines, llama.cpp, llama-server, MIT协议, ntdll.dll, Python 3.10, Python语法检查, 代码编辑器, 安全AI, 工具调用, 开源, 微IDE, 文件管理, 无遥测, 本地AI, 本地大语言模型, 本地文件读写, 桌面AI工作区, 离线AI, 网络安全, 聊天UI, 轻量级工具, 逆向工具, 隐私保护, 零信任