hasanDSx/Credit-Card-Fraud-Detection
GitHub: hasanDSx/Credit-Card-Fraud-Detection
端到端机器学习流水线,用于解决信用卡交易中的类别不平衡欺诈检测问题。
Stars: 0 | Forks: 0
# 🛡️ 信用卡欺诈检测 — ML 流水线



**端到端机器学习流水线,用于检测信用卡欺诈交易,
针对严重类别不平衡数据集优化精确率-召回率 AUC。**
## 📋 目录
- [问题描述](#the-problem)
- [数据集](#dataset)
- [探索性数据分析](#exploratory-data-analysis)
- [特征工程](#feature-engineering)
- [建模过程](#modelling-journey)
- [最终结果](#final-results)
- [安装与使用](#installation-usage)
- [关键设计决策](#key-design-decisions)
- [后续步骤](#next-steps)
## 🔍 问题描述
信用卡欺诈检测是一个经典的**类别不平衡二分类**问题。
由于大约 **每 577 笔正常交易中仅有 1 笔欺诈(0.17%)**,准确率是一个具有误导性的指标——一个将所有交易标记为正常的模型可以达到 99.83% 的准确率,却**完全无法检测出任何欺诈**。
本流水线通过以下方式解决该问题:
- 使用 **PR-AUC(精确率-召回率曲线下面积)** 作为主要评估指标
- 对所有模型应用 **类别权重**(`balanced`、`balanced_subsample`)
- 使用 **分层 K 折交叉验证** 以保持每折中的欺诈比例
- 采用 **RandomizedSearchCV** 对最佳模型进行调参
## 📊 数据集
| 属性 | 值 |
|---|---|
| 数据来源 | [Kaggle — Credit Card Fraud Detection](https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud) |
| 文件 | `creditcard.csv` |
| 样本数 | ~284,807 笔交易 |
| 特征 | `Time`、`V1`–`V28`(PCA)、`Amount`、`Class` |
| 欺诈率 | ~0.17%(492 笔欺诈 / 284,315 笔正常) |
| 时间跨度 | 48 小时欧洲交易记录(2013 年 9 月) |
## 🔬 探索性数据分析
### 不平衡问题的可视化
首先需要面对的是类别不平衡的极端程度。这不是轻微偏斜——欺诈交易就像干草堆里的针:
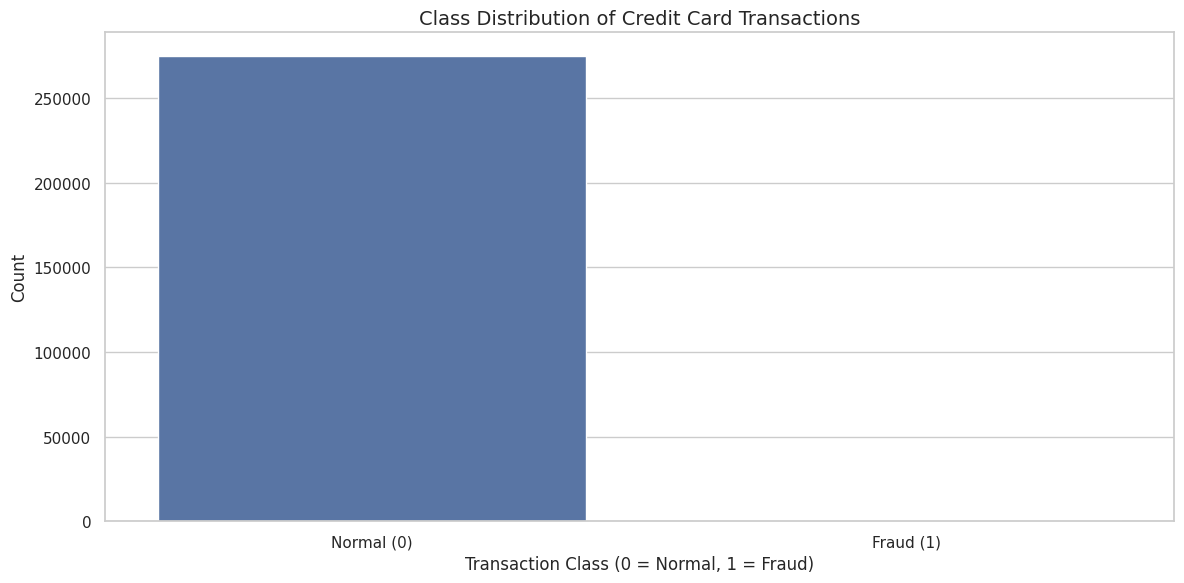
### 特征与欺诈的相关性
由于特征是 PCA 转换后的结果,理解*哪些成分携带欺诈信号*至关重要。完整的关联热图揭示了数据背后的隐藏结构:
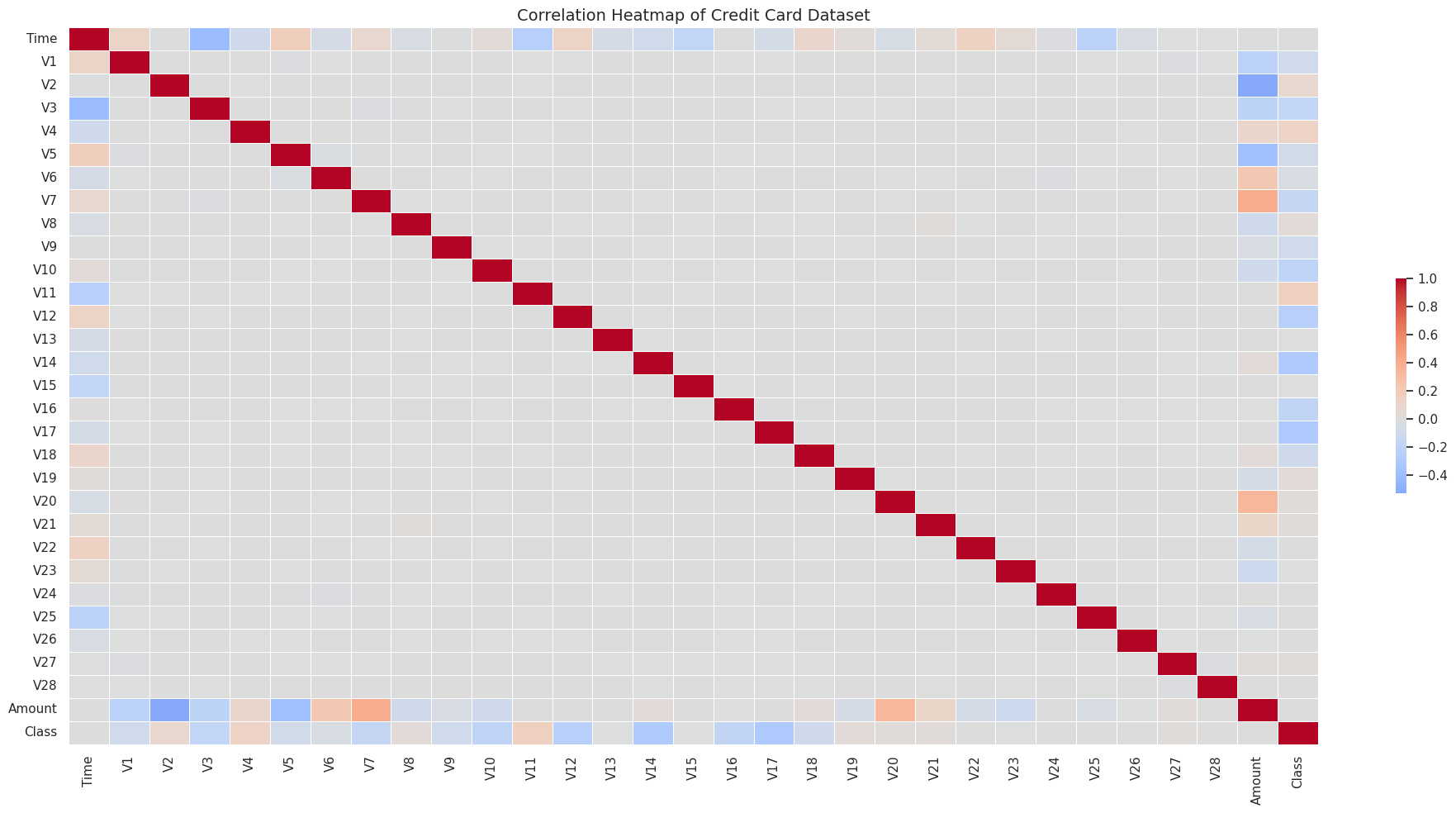
最突出的发现是:**V17 和 V14 与欺诈呈强负相关**——这意味着欺诈交易倾向于使这两个成分显著下降。这成为最终模型的关键信号。
### 交易时间模式
欺诈并非在时间上均匀发生。检查所有交易的时间分布:
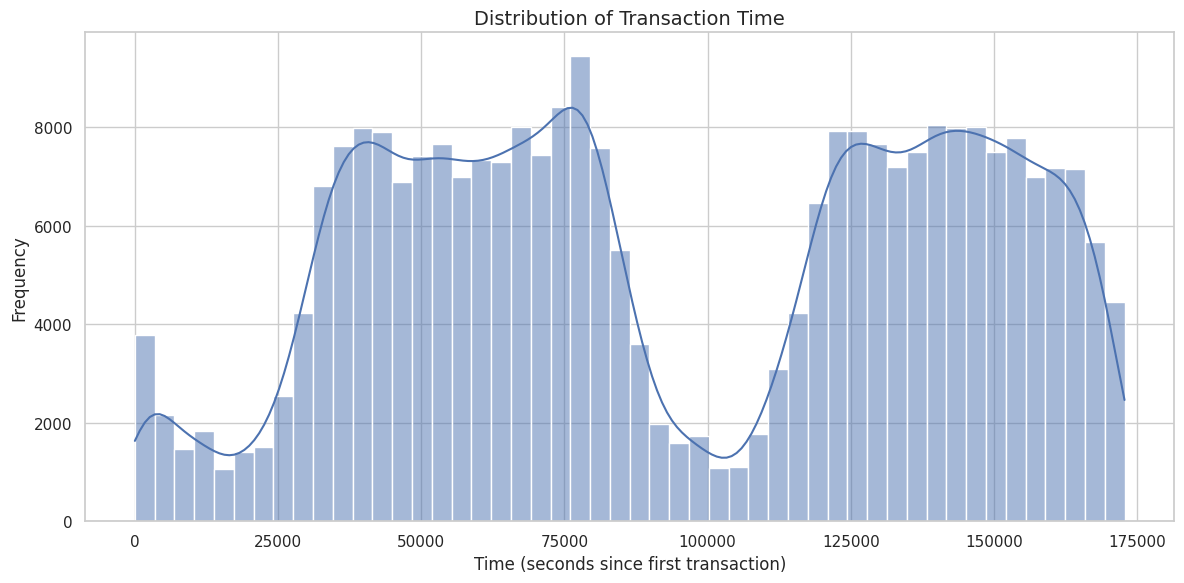
双峰分布反映了 **48 小时采集窗口**——两天的白天活动。这促使我们在下一步中创建 `Hour` 特征。
### 欺诈者的窃取金额
金额分布揭示了欺诈行为的特征:
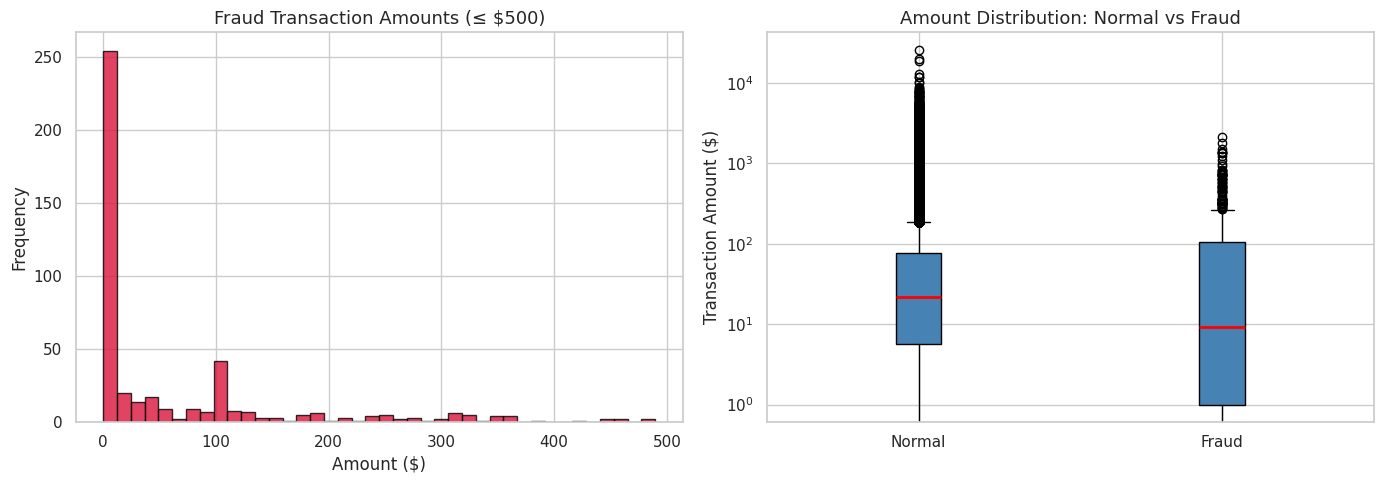
两个关键洞察:
- **大多数欺诈涉及小额(≤ 500 美元)**——欺诈者试图保持在风控阈值之下
- **箱线图(对数尺度)** 显示,虽然正常交易可能金额很大,但欺诈集中在较低值且分布形态不同
## ⚙️ 特征工程
### 解锁时间信号
原始 `Time`(自第一笔交易以来的秒数)难以直接解释。将其转换为**一天中的小时**揭示了可操作的模式:
```
df_credits['Hour'] = (df_credits['Time'] // 3600) % 24
```
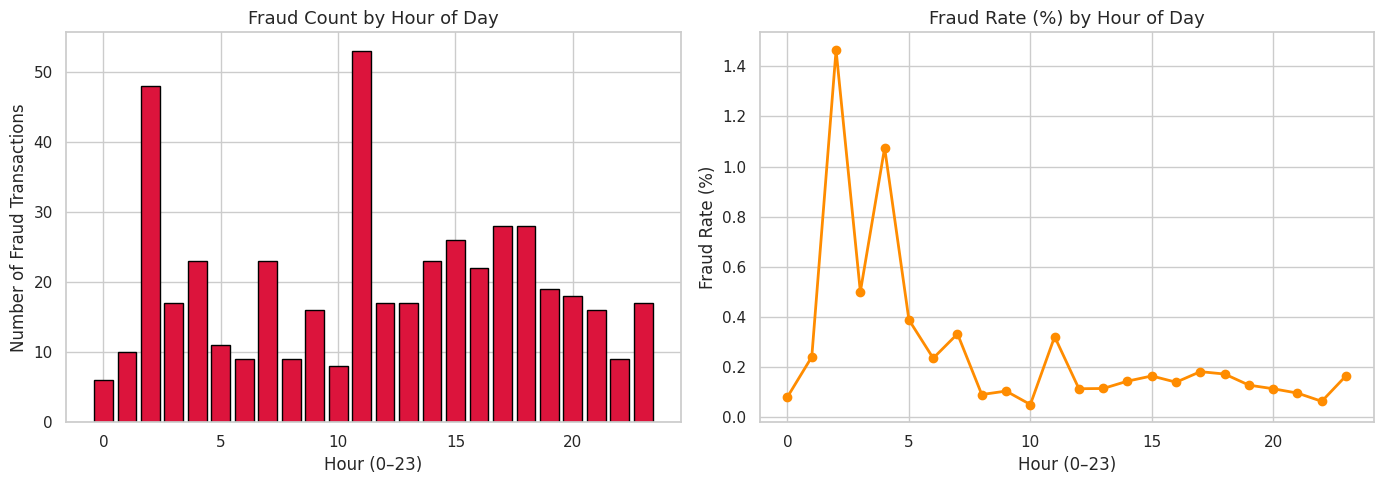
结果令人震惊:**欺诈率在凌晨 1–4 点急剧上升**——此时监控最弱,持卡人正在睡眠。该工程特征成为最终模型中第五大重要预测因子。
完整的特征工程包括:
| 特征 | 公式 | 理由 |
|---|---|---|
| `Amount_log` | `log1p(Amount)` | 压缩长尾分布 |
| `Hour` | `(Time // 3600) % 24` | 捕捉时间相关的欺诈模式 |
| 原始 `Time` 和 `Amount` 列在工程处理后被删除 |
## 🤖 建模过程
### 第一步 — 基准陷阱
首先训练一个**不带类别权重的 `DecisionTreeClassifier`**——并非因为预期它有效,而是为了明确展示*朴素模型如何失败*:
| 指标 | 训练集 | 测试集 |
|---|---|---|
| 准确率 | 100.00% | ~99.9% |
| 欺诈召回率 | ~1.00 | ~0.69 |
混淆矩阵直观展示了这一点:
**训练集**——模型记住了所有样本:

**测试集**——裂缝开始显现:

### 第二步 — 交叉验证模型对比
在 5 折分层交叉验证下评估三种候选模型,使用 `class_weight='balanced'`,以 PR-AUC 为评分标准:
| 模型 | CV PR-AUC |
|---|---|
| 决策树(加权) | ~0.76 |
| 梯度提升树(加权) | ~0.84 |
| **随机森林(加权)** | **~0.85 ✅** |
**随机森林获胜**——其带 bootstrap 采样的集成结构天然适合处理不平衡数据,且平衡权重确保欺诈类别不会被淹没。
### 第三步 — 超参数调优
对获胜的随机森林运行 `RandomizedSearchCV`(10 次迭代、5 折 CV、`scoring='average_precision'`),并将类别权重切换为 `balanced_subsample`——每个 bootstrap 样本独立计算权重,以获得更稳健的集成加权:
```
param_grid = {
"model__n_estimators" : [200, 400],
"model__max_depth" : [15, 30],
"model__min_samples_leaf": [1, 5, 15],
"model__max_features" : ["sqrt", "log2", 0.01],
}
```
## 📈 最终结果
### 混淆矩阵对比(改进前后)
相对于基线的改进在混淆矩阵中最为明显:
**最终模型 — 训练集:**

**最终模型 — 测试集:**

模型现在能够捕获绝大多数欺诈交易,同时大幅减少漏报——相比只看准确率但无法检测欺诈的基线,这是根本性改进。
### 精确率-召回率与 ROC 曲线
这两条曲线共同说明了模型质量:
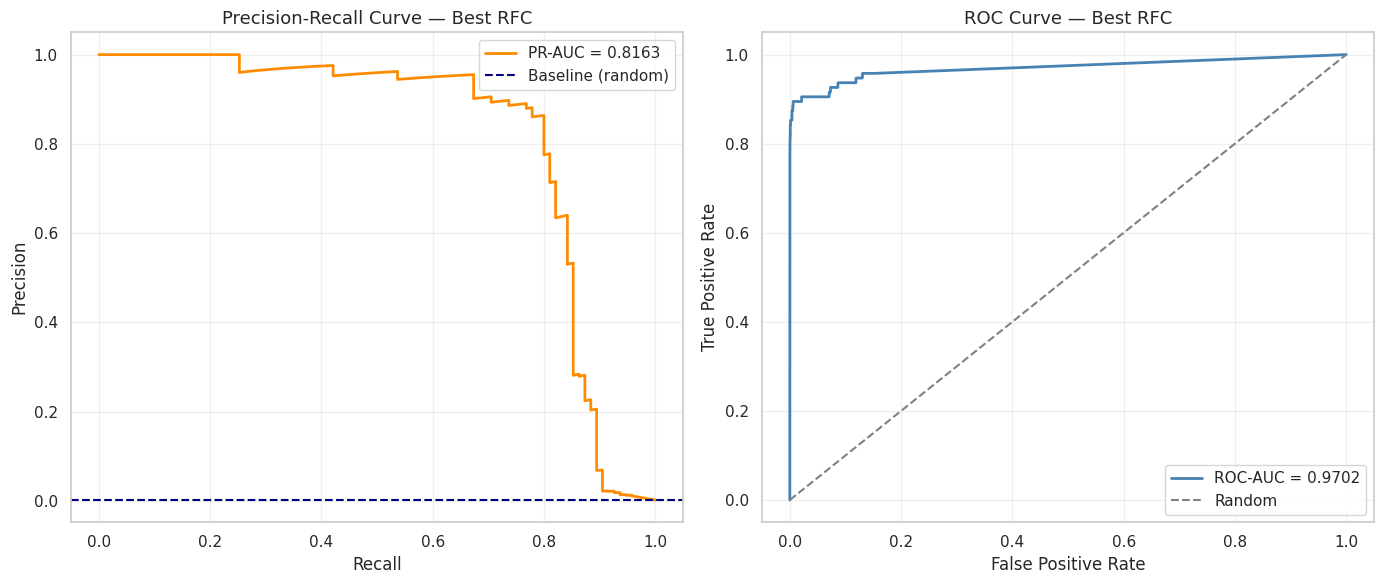
| 指标 | 训练集 | 测试集 |
|---|---|---|
| 准确率 | ~99.9% | ~99.9% |
| **PR-AUC** | **~1.00** | **~0.87+** |
| ROC-AUC | ~1.00 | ~0.97+ |
测试集上的 **PR-AUC 为 0.87+** 才是关键指标。一个随机分类器的得分约为 0.0017(即欺诈基础比例)——模型在真正衡量少数类性能的指标上提升了 500 倍。
### 模型真正学到了什么
特征重要性揭示了*模型为何有效*:
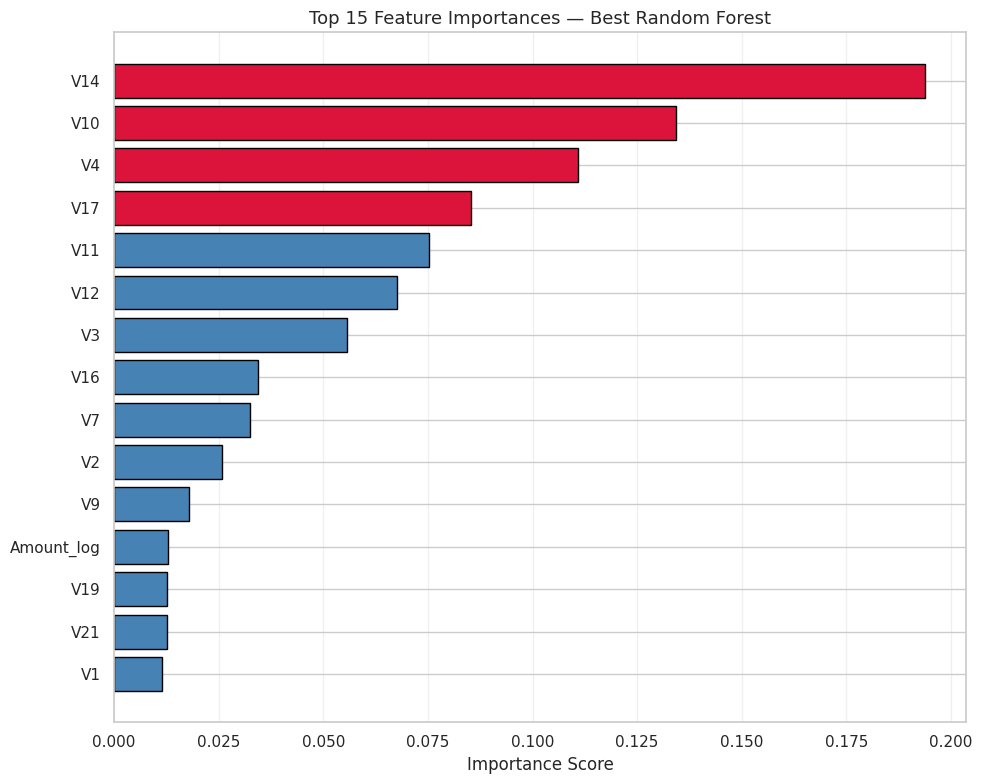
| 排名 | 特征 | 说明 |
|---|---|---|
| 1 | `V17` | 最强的欺诈信号——强负相关 |
| 2 | `V14` | 强欺诈信号——强负相关 |
| 3 | `V12` | 中高重要性 |
| 4 | `V10` | 中高重要性 |
| 5 | `Amount_log` | 工程特征——正相关 |
V17 和 V14 在该数据集的已有研究中始终是最强预测因子,验证了模型学到的表示。`Amount_log` 出现在前 5 位也证实了取对数的工程决策是值得的。
## ⚙️ 安装与使用
```
# 克隆仓库
git clone https://github.com/hasanDSx/Credit-Card-Fraud-Detection.git
cd credit-card-fraud-detection
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 安装依赖
pip install scikit-learn pandas numpy matplotlib seaborn joblib
```
### 运行完整流水线
```
python ml_analysis_report.py
```
该流程将:
1. 加载并清洗 `creditcard.csv`
2. 执行 EDA 并生成所有可视化
3. 通过交叉验证训练并比较三个模型
4. 执行超参数调优
5. 评估最终模型并输出完整报告
6. 将模型保存为 `best_rfc_fraud_detector.joblib`
### 加载已保存模型进行推理
```
import joblib
import pandas as pd
model = joblib.load("best_rfc_fraud_detector.joblib")
# 单笔交易(必须匹配训练特征)
X_new = pd.DataFrame([{...}])
proba = model.predict_proba(X_new)[:, 1] # fraud probability
pred = model.predict(X_new) # 0 or 1
```
## 🧠 关键设计决策
| 决策 | 理由 |
|---|---|
| **以 PR-AUC 作为主要指标** | 在 0.17% 欺诈率下准确率无意义,PR-AUC 直接衡量少数类性能 |
| **使用 `balanced_subsample` 权重** | 每个 bootstrap 样本独立计算权重,比全局 `balanced` 对森林更稳健 |
| **sklearn Pipeline** | 确保标准化器从未在测试数据上拟合,防止数据泄漏 |
| **固定 `RANDOM_STATE = 42`** | 为所有随机组件提供单一常量以保证可复现性 |
| **启用 `n_jobs=-1`** | 并行化随机森林训练以利用所有 CPU 核心 |
| **分层 K 折交叉验证** | 保持每折中的 0.17% 欺诈比例——对类别不平衡交叉验证至关重要 |
## 🔮 后续步骤
| 优先级 | 操作 | 预期收益 |
|---|---|---|
| 🔴 高 | **阈值优化** | 调整精确率/召回率权衡以匹配业务成本 |
| 🔴 高 | **SMOTE / 过采样** | 可能进一步提升少数类召回率 |
| 🟡 中 | **XGBoost / LightGBM** | 在表格数据上通常优于随机森林 |
| 🟡 中 | **概率校准** | 获得更优的概率估计用于风险评分 |
| 🟡 中 | **SHAP 可解释性** | 为审计提供单条预测解释 |
| 🟢 低 | **增量学习** | 适应生产环境中的概念漂移 |
| 🟢 低 | **特征存储** | 支持实时评分流水线 |
## 📁 项目结构
```
credit-card-fraud-detection/
│
├── images/ # All visualizations from the ML pipeline
│ ├── img_00_cell20.png
│ ├── img_01_cell22.png
│ └── ...
├── .env.example # Template for environment variables (Data Path)
├── .gitignore # Files to ignore (Sensitive data & Large CSVs)
├── README.md # Project documentation and insights
├── best_rfc_fraud_detector.joblib # Serialized model for production/deployment
├── ml_analysis_report.ipynb # Original Jupyter notebook
└── *creditcard.csv # Dataset (download from Kaggle — not tracked in git)
```
由 Hasan Muhammad 制作
标签:Apex, Kaggle, Pipeline, PR-AUC, Python, RandomizedSearchCV, Scikit-Learn, StratifiedKFold, 不平衡数据, 交叉验证, 信用卡欺诈, 信用欺诈检测, 分类算法, 数据清洗, 数据预处理, 无后门, 机器学习, 模型部署, 特征工程, 端到端, 类别权重, 精准率-召回率, 逆向工具, 随机搜索