FarzeanHassim/hybrid-fraud-detection-risk-scoring-engine
GitHub: FarzeanHassim/hybrid-fraud-detection-risk-scoring-engine
这是一个结合基于规则评分与机器学习的端到端混合欺诈检测系统,通过Streamlit仪表板实现交易监控、告警优先级排序及运营决策的可视化工作流。
Stars: 0 | Forks: 0
# 混合欺诈检测与风险评分引擎
本项目模拟了一个用于交易监控的端到端混合欺诈检测系统,结合了基于规则的控制与机器学习,以改进欺诈检测、告警优先级排序和决策。
它整合了:
- 基于规则的检测和评分
- 基于机器学习的欺诈概率预测
- 混合风险评分
- 运营决策(批准 / 审核 / 阻止)
- 通过 Streamlit 仪表板实现的分析师工作流可视化
这反映了银行和金融科技公司中的现代欺诈检测系统如何在可解释性、预测能力和运营可用性之间取得平衡。
## 💼 项目类型
端到端欺诈检测系统模拟(银行 / 金融科技用例)
## 📌 概述
本项目通过结合基于规则的评分和机器学习,模拟了金融机构中使用的真实世界欺诈检测系统。
它展示了混合风险评分如何改进欺诈检测,减少误报,并在交易监控工作流中实现更有效的告警优先级排序。
它反映了现代欺诈检测系统如何结合可解释的规则与概率机器学习模型,以优化检测准确性和运营效率。
本项目反映了生产环境中的欺诈系统如何将检测、评分和决策整合到单一运营工作流中。
### 主要成果
- 使用混合评分减少误报并改进告警优先级排序
- 在保持运营效率的同时实现了更强的欺诈检测召回率
## 端到端工作流覆盖
本项目演示了完整的欺诈检测生命周期:
- 检测 → 基于规则的评分
- 优化 → 机器学习优化
- 决策 → 混合评分与行动映射
- 运营 → 分析师仪表板与工作流
这与金融机构中使用的真实世界欺诈风险引擎相一致。
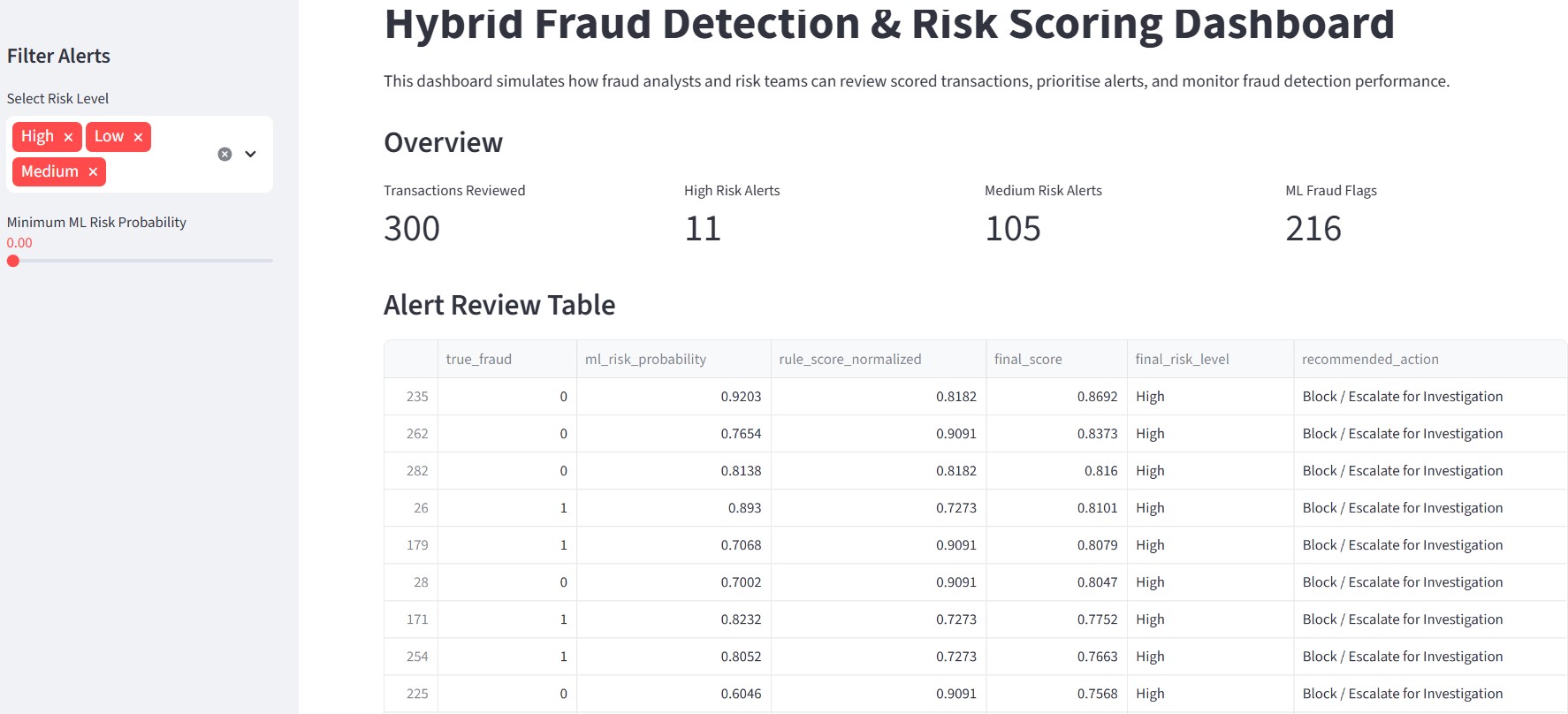
## 📊 仪表板预览
### 🔹 概述仪表板
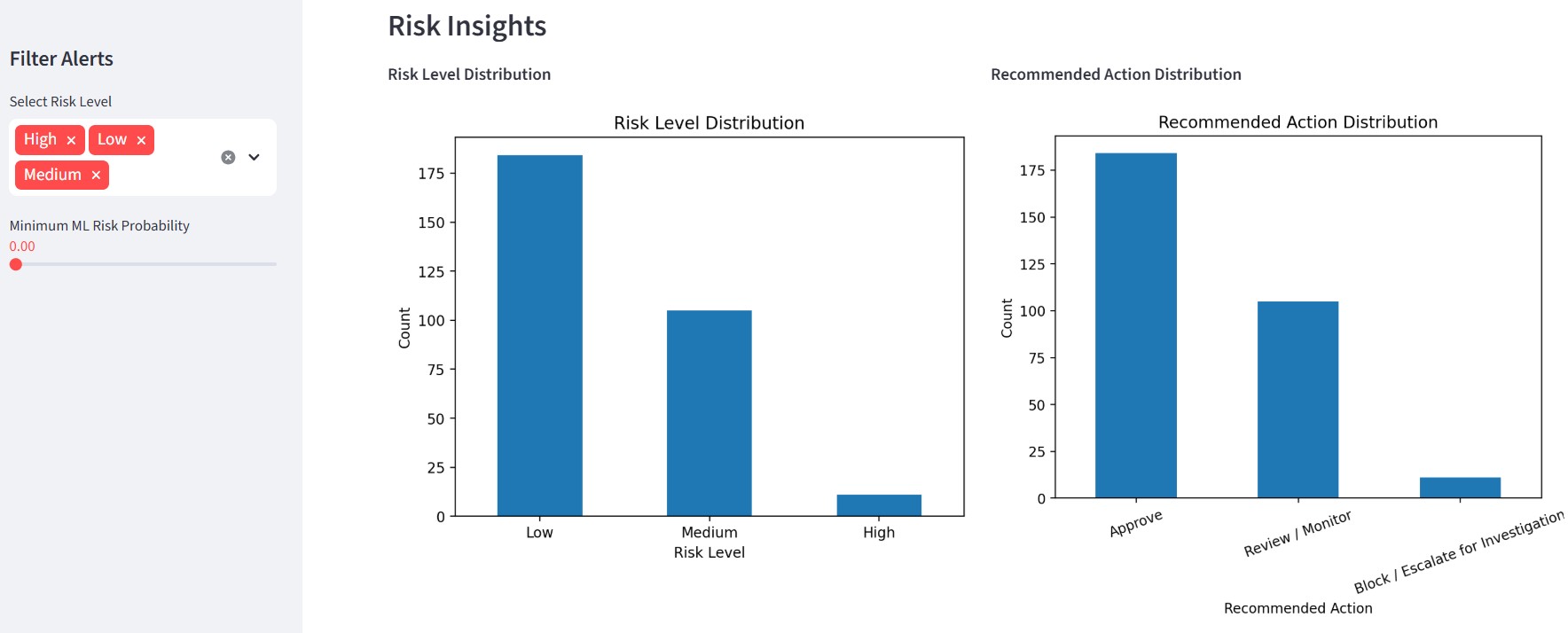
### 🔹 风险洞察
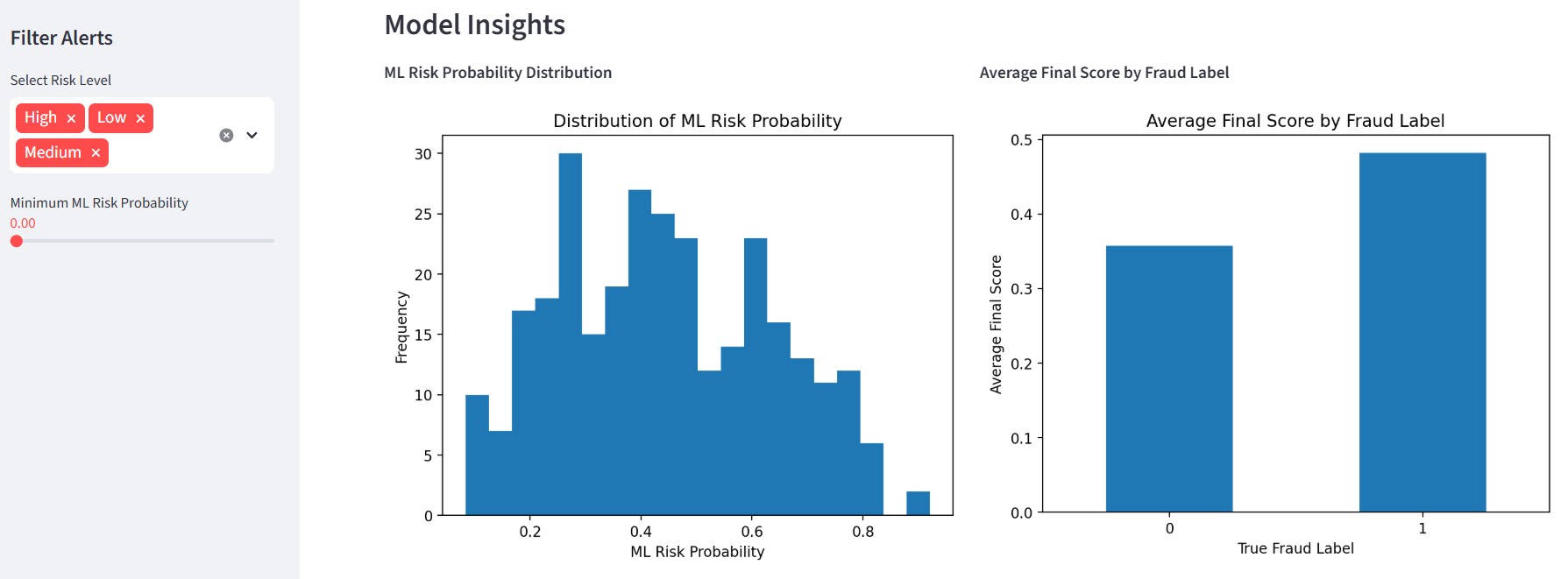
### 🔹 模型洞察
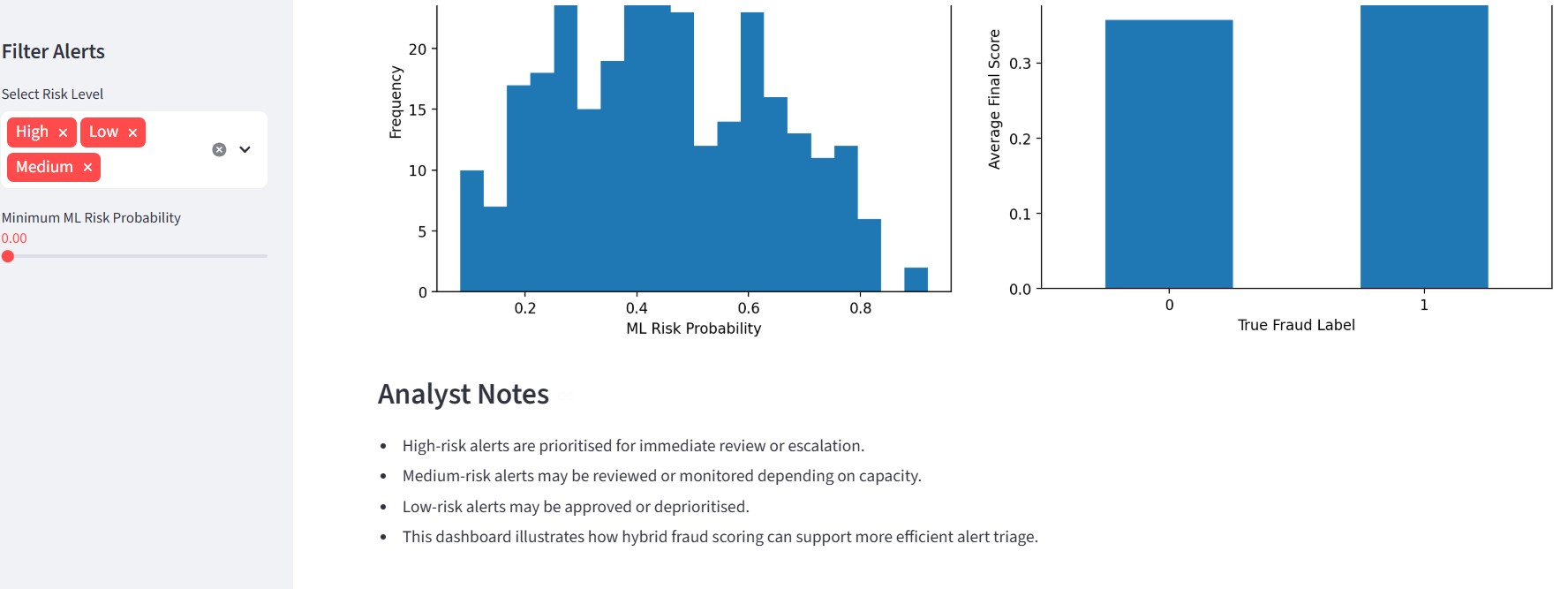
### 🔹 分析师工作流
## 📂 访问项目文件
- 📓 **Notebook(完整工作流)**
👉 [查看 Notebook](./real_time_fraud_detection_engine.ipynb)
- 📊 **示例数据集**
👉 [查看数据集](./sample_transactions.csv)
- 📈 **评分结果输出**
👉 [查看结果](./df_test_results.csv)
- 📊 **仪表板代码(Streamlit 应用)**
👉 [查看应用](./app.py)
## ▶️ 本地运行
```
pip install -r requirements.txt
streamlit run app.py
```
## 🏗️ 系统架构
该架构反映了现代欺诈检测系统如何集成基于规则的控制与机器学习模型,以支持可扩展且基于风险的决策制定。
```
Transaction Data
↓
Rules-Based Engine
↓
Machine Learning Model
↓
Hybrid Risk Scoring
↓
Risk Classification (High / Medium / Low)
↓
Recommended Action (Block / Review / Approve)
```
## 🎯 目标
- 使用交易级行为数据模拟欺诈检测工作流
- 实施基于规则的风险评分
- 构建机器学习模型以预测欺诈
- 将两种方法结合到混合评分引擎中
- 使用风险级别和建议的操作对告警进行优先级排序
- 提供交互式仪表板以支持分析师分流和决策制定
## 🧠 混合评分逻辑
该引擎结合了:
- 基于规则的评分,用于可解释的欺诈指标
- 机器学习欺诈概率,用于预测性风险评估
这些被组合成最终的混合评分,用于分配:
- 最终风险级别
- 建议操作
- 分析师审核优先级
这种方法通过将检测信号转换为可直接用于决策的输出,提高了运营可用性。
## 💼 业务影响
本项目展示了金融机构如何:
- 减少交易监控系统中的误报
- 改进调查人员的告警优先级排序
- 在保持运营效率的同时增强欺诈检测召回率
- 使用混合评分模型支持基于风险的决策制定
- 弥合检测模型与运营决策层之间的差距
- 与受监管的 AML/CFT 和欺诈框架中预期的基于风险的方法相一致
该方法反映了银行、支付平台和金融科技公司中使用的真实世界欺诈风险引擎,在这些场景中,混合评分模型对于平衡检测准确性和运营效率至关重要。
## ⭐ 主要功能
- 混合基于规则和机器学习的欺诈检测
- 风险评分与告警优先级排序引擎
- 带有阈值优化的逻辑回归模型
- 模拟分析师工作流的 Streamlit 仪表板
- 用于模型性能和风险分布的可视化分析
## 使用的关键功能
该模型结合了行为和基于风险的指标,包括:
- 交易金额
- 交易频度(1小时 / 24小时)
- 新收款人指标
- 卡片在场指标
- 账户年龄
- 撤销历史
- 历史告警
- 商户类别和商户风险级别
- 交易与 IP 之间的国家不匹配
## 决策框架
系统将混合风险分数转换为运营决策:
- 高风险 → 阻止 / 升级以进行调查
- 中风险 → 审核 / 监控
- 低风险 → 批准
这模拟了欺诈引擎如何支持下游的分析师和运营工作流。
## ⚡ 技术栈
- **语言:** Python
- **数据处理:** Pandas, NumPy
- **机器学习:** Scikit-learn (Logistic Regression)
- **可视化:** Matplotlib
- **仪表板:** Streamlit
## ⚙️ 方法论
### 1. 数据模拟
代表以下内容的合成数据集:
- 交易金额
- 商户类别风险
- 国家不匹配
- 频度模式
- 行为指标
### 2. 基于规则的检测
- 定义了欺诈规则(金额、频度、国家不匹配等)
- 生成了可解释的分数
- 捕获了触发的规则
### 3. 机器学习模型
- 逻辑回归
- 处理类别不平衡
- 阈值调整(优先考虑召回率)
### 4. 混合风险评分引擎
- 结合了:
- 标准化的规则分数
- 机器学习欺诈概率
- 生成:
- 最终风险分数
- 风险分类
- 建议操作
## 为什么混合很重要
基于规则的系统是透明的,但可能产生高误报。
机器学习改进了检测,但直接可解释性较差。
混合模型结合了两者的优势:
- 更好的欺诈检测
- 更实用的告警优先级排序
- 更清晰的运营操作
- 更适用于受监管的环境
## 📊 结果与对比
| 方法 | 优势 | 局限 |
|----------|----------|------------|
| 基于规则 | 可解释 | 误报高 |
| 机器学习 | 检测效果更好 | 可解释性较差 |
| 混合模型 | 性能均衡 | 需要校准 |
### 主要结果
- 改进了欺诈检测(更高的召回率)
- 结构化的告警优先级排序
- 与真实世界欺诈工作流更好地一致
## 示例输出
评分输出包括:
- 机器学习欺诈概率
- 标准化的规则分数
- 最终混合分数
- 最终风险级别
- 建议操作
运营输出示例:
- 低 → 批准
- 中 → 审核 / 监控
- 高 → 阻止 / 升级以进行调查
## 📈 模型评估
- 使用精确率、召回率和 F1 分数进行性能评估
- 优先考虑召回率以最大程度减少遗漏的欺诈案例
- 应用阈值调整以平衡检测与误报
## 📊 仪表板
模拟欺诈分析师工作流的交互式仪表板。
### 功能
- 按风险级别筛选告警
- 风险指标概述
- 告警审核表
- 风险分布图表
- 机器学习概率洞察
## 🧠 关键洞察
- 在欺诈检测中仅靠准确率是不够的
- 召回率对于最大程度减少遗漏欺诈至关重要
- 规则和机器学习扮演互补角色
- 混合模型同时改进了检测和可用性
## 🏦 真实世界应用
- 银行交易监控系统
- 金融科技支付风险引擎
- 欺诈检测平台
- 合规与 AML 工作流
## 🛠️ 使用的工具
- Python
- Pandas / NumPy
- Scikit-learn
- Matplotlib
- Streamlit
## 🚀 未来改进
- 实时评分流水线
- 高级机器学习模型(XGBoost, Random Forest)
- SHAP 可解释性
- AI 辅助的告警叙述
- 与外部数据源集成
## ⚠️ 局限性
- 合成数据集可能无法反映真实世界的复杂性
- 模型性能在真实生产数据上可能有所不同
- 需要使用更大的数据集进行进一步验证
## 🎯 目标用户
- 欺诈分析师和调查人员
- AML / 交易监控团队
- 风险与合规专业人员
- 金融科技和支付风险团队
## 如何使用本项目
- 探索 Notebook 以了解模型逻辑和评分方法论
- 查看评分数据集以查看最终风险输出
- 运行 Streamlit 应用以模拟分析师工作流和告警优先级排序
## 👤 作者
Farzean Hassim
标签:Apex, Kubernetes, Streamlit, 云计算, 交易监控, 信用评分, 决策引擎, 分析师工作流, 反欺诈, 报警优先级, 机器学习, 欺诈检测, 混合检测, 端到端, 规则引擎, 访问控制, 误报率降低, 逆向工具, 金融科技, 银行安全, 风控策略, 风控系统, 风险评分