JOBEBOLDER/aiOps_pilot
GitHub: JOBEBOLDER/aiOps_pilot
智能事件响应AIOps代理框架,自动化IT运营。
Stars: 0 | Forks: 0
# AIOps—试点
**智能事件响应** — 一个自主的AIOps代理框架,使用**计划-执行-重新计划**循环和**LangGraph**来自动化IT运营。代理不仅回答问题:它还像一个数字SRE,可以使用结构化推理和工具来诊断和排除故障。
## 系统架构(概述)
*端到端堆栈(从下到上):**知识来源**和**向量数据库**为**核心层**(文档加载/索引、检索、聊天模型、提示、工具、MCP)提供数据。**代理式应用程序**(对话聊天、AIOps诊断、RAG支持的知識使用)位于核心之上,并通过**API层**公开。
此存储库中典型的HTTP入口点包括**`POST /chat`**、**`POST /chat_stream`**、**`POST /upload`**(以及用于批量索引的**`POST /index_directory`**),以及用于诊断工作流程的**`POST /aiops`**。
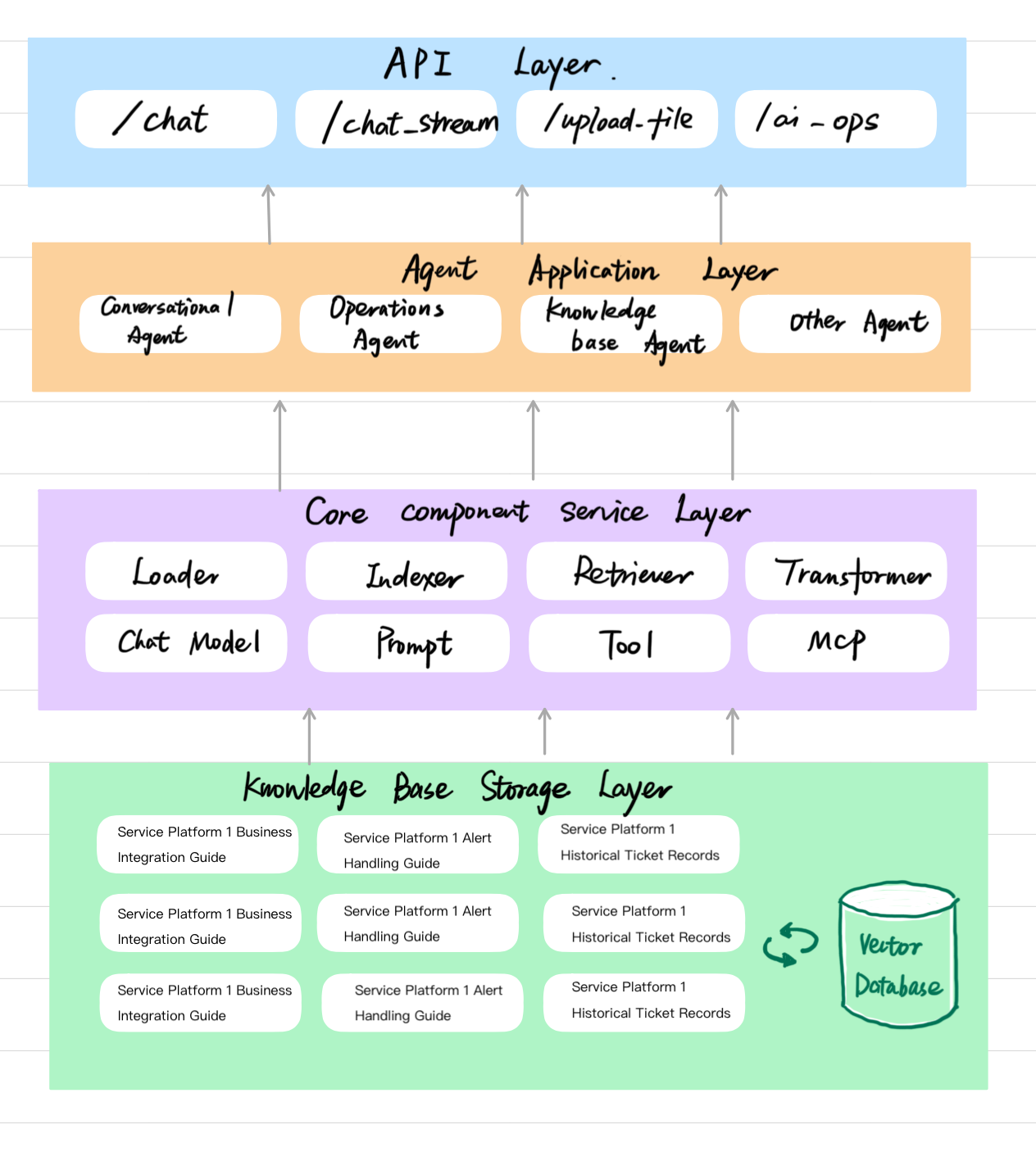
## 关键架构特性
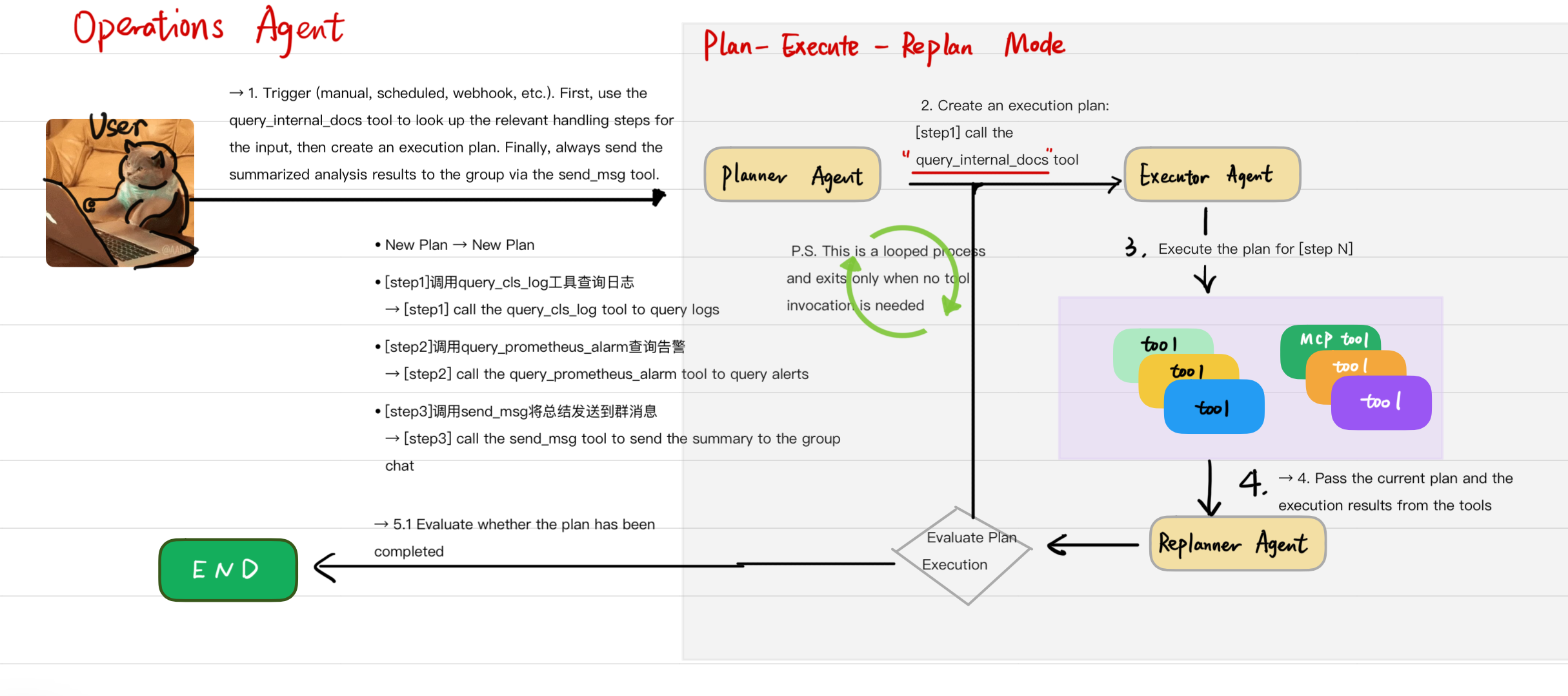
### 1. 认知架构:计划-执行-重新计划
与仅使用RAG的线性管道不同,此项目使用**有状态的循环图**。
- **战略规划** — `Planner`将模糊警报转换为可执行步骤的有序列表(一个结构化计划而不是单个自由形式的回复)。
- **自主执行** — `Executor`调用本地工具和**MCP(模型上下文协议)**客户端,以获取您的堆栈公开的实时信号(日志、指标、跟踪)。
- **自我纠正** — `Replanner`评估结果。如果步骤失败或观察结果不符合预期,则图可以**重新计划**而不是在第一个错误处停止。
*计划-执行-重新计划流程(Planner → Executor → 工具 → Replanner → 评估 → 循环或END):*
### 2. 知识检索(RAG)
- **向量存储** — **Milvus**支持SOP、运行手册和事后分析的语义搜索。
- **摄取** — 上传区域下的文档被分割和索引;典型来源包括`.md`和`.txt`操作手册。
*RAG概述:摄取(块 → 嵌入 → 存储)和查询时检索(嵌入问题 → 搜索向量存储 → 增强LLM):*

### 3. 对话式代理、可观察性和流
该产品公开**两个互补的表面**:一个**由警报驱动的AIOps**工作流程(计划-执行-重新计划,见上文)和一个**对话式RAG代理**用于交互式Q&A。本节重点介绍**聊天代理**以及它是如何通过线进行观察的。
#### 对话式RAG代理 — 角色和功能
- **目的** — 一个**工具增强的聊天代理**(`RagAgentService`)在上下文中回答问题:它可以**检索**索引知识,调用**MCP支持**的功能,并保持每个客户端会话的**多轮**对话。
- **运行时** — 使用LangChain **`create_agent`**、**ChatQwen**和LangGraph **`MemorySaver`**检查点器构建。模型决定何时调用工具;答案通过**`retrieve_knowledge`**(Milvus)得到巩固,并通过在启动时加载的MCP工具扩展,以及如**`get_current_time`**之类的实用程序。
- **会话语义** — 客户端提供**`session_id`**;它映射到LangGraph的**`thread_id`**,因此每个会话都有**隔离**的检查点状态。助手在相同的检查点器之上公开**会话历史**和**clear-session**行为。
- **交付模式** — **`POST /chat`**返回一个包含完整回复的JSON有效负载。**`POST /chat_stream`**流式传输SSE,以便UI可以渲染**令牌级**输出和结构化事件类型(例如**内容**、**完成**、**错误**;API层还可以在流中转发**tool_call** / **search_results**-style事件,如果存在)。
#### 产品中的流
- **聊天** — SSE为长答案提供**低延迟**反馈,并保持通道开启以进行结构化事件和原始文本。
- **AIOps** — **`POST /aiops`**使用SSE推送**诊断生命周期**更新(例如状态、计划、步骤完成、最终摘要),在精神上类似于聊天流,但与诊断图相关联,而不是自由形式的对话。
#### 架构(对话路径)
*高级流程:用户输入和**RAG检索**(向量存储)为**提示构建**提供数据;LLM在**ReAct**循环中运行—**推理**,可选**调用工具**(本地 + MCP),将**工具结果**反馈到模型,并在不需要进一步工具调用时**退出**,然后返回最终消息。
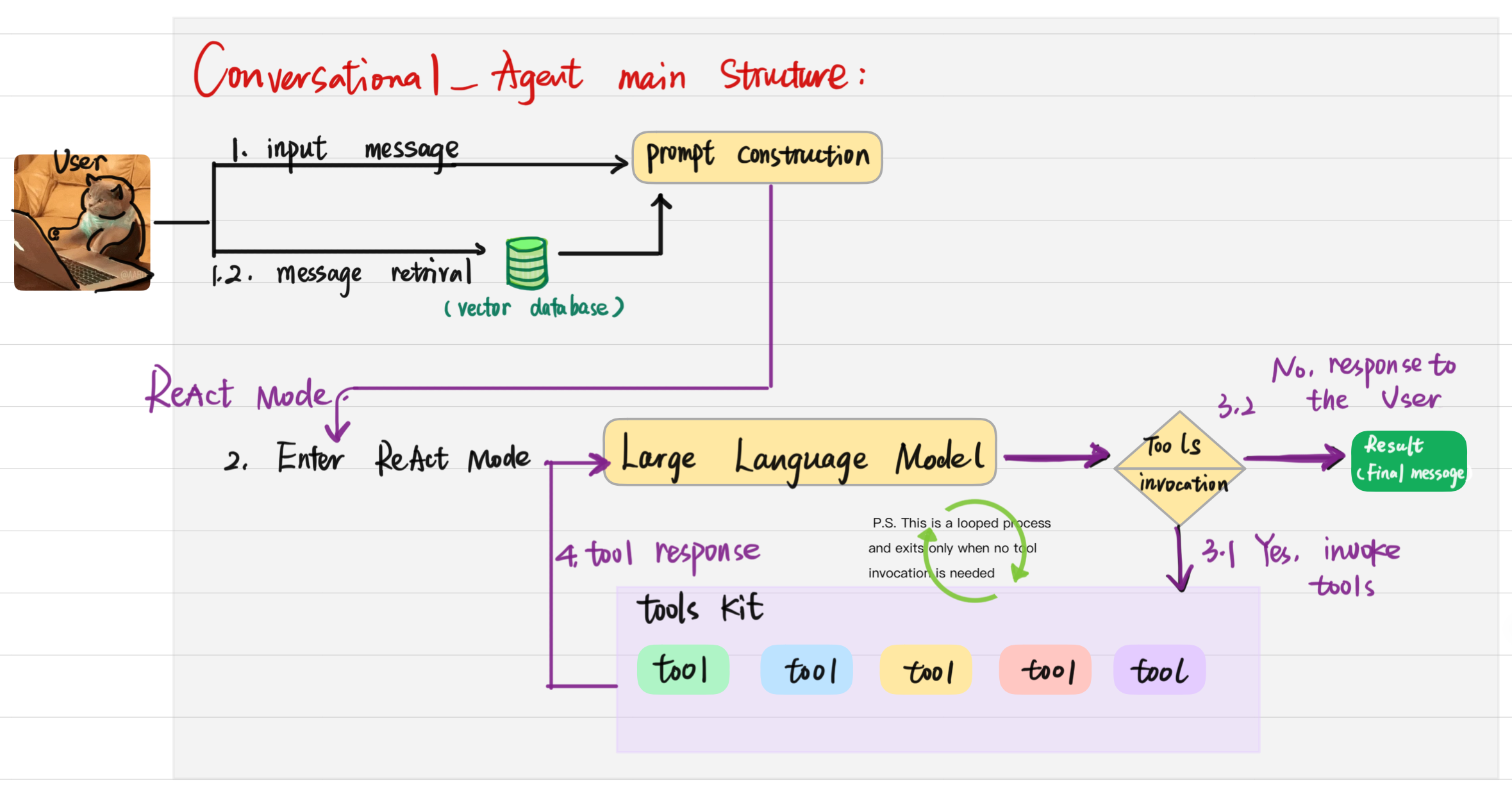
*服务连接(FastAPI会话 → 代理 → 检查点器 → 工具 → Milvus):
```
flowchart LR
Client[Client · session_id]
API[FastAPI · /chat · /chat_stream]
Agent[create_agent + ChatQwen]
CP[(MemorySaver · thread_id)]
Tools[retrieve_knowledge · MCP · get_current_time]
DB[(Milvus)]
Client --> API --> Agent
Agent --> CP
Agent --> Tools
Tools --> DB
```
## 技术堆栈
| 区域 | 技术 |
| :--- | :--- |
| **LLM编排** | LangGraph, LangChain |
| **LLM** | Qwen(通过阿里巴巴云DashScope / `langchain-qwq`) |
| **向量存储** | Milvus |
| **API** | FastAPI, SSE-Starlette |
| **工具协议** | MCP(模型上下文协议) |
| **日志** | Loguru |
## 项目布局
```
├── app/
│ ├── agent/
│ │ ├── aiops/ # LangGraph nodes: planner, executor, replanner, state
│ │ └── mcp_client.py # MCP integration
│ ├── services/ # Orchestration, RAG agent, embeddings, indexing pipeline
│ ├── api/ # REST and SSE endpoints
│ ├── core/ # Shared infrastructure (e.g. Milvus client)
│ ├── models/ # Pydantic request/response models
│ ├── vector_index_service.py # Manual / directory indexing entrypoints
│ ├── vector_search_service.py
│ └── rag_agent_service.py
├── uploads/ # Ops manuals and docs for RAG ingestion
└── main.py # Application entrypoint (if present in your deployment)
```
根据您的分支将服务移动到不同的包布局时,请调整路径。
## 入门
### 先决条件
- Python 3.10+
- Docker(推荐用于Milvus独立)
### 安装
1. **克隆存储库**
git clone https://github.com/your-username/aiops-pilot.git
cd aiops-pilot
2. **环境**
创建一个`.env`文件(名称可能不同;与您的树中的`app.config`对齐):
DASHSCOPE_API_KEY=your_key_here
MILVUS_HOST=localhost
MILVUS_PORT=19530
3. **安装依赖项并运行**
pip install -r requirements.txt
python main.py
如果您直接使用Uvicorn,请将其指向您的FastAPI应用程序模块,如您的项目中所定义。
## 示例场景
1. **触发器** — 一个警报到达:*DB-01的CPU使用率过高*。
2. **检索** — 代理查询向量索引以查找匹配“高CPU数据库”的运行手册。
3. **计划** — 规划器发出以下步骤:检查顶级进程 → 检查慢查询 → 检查连接池。
4. **执行** — 执行器运行工具(例如,通过MCP或本地适配器进行日志或指标查询)。
5. **重新计划** — 如果出现新证据(例如,死锁),重新规划器会更新计划(例如,针对特定进程或会话的操作)。
6. **报告** — 为操作员生成一个简洁的根本原因和修复摘要。
## 系统设计注意事项
这些选择是有意为之的权衡,而不是偶然的默认值。
### 为什么在Milvus中使用L2(欧几里得)距离?
搜索配置为在嵌入向量上使用**L2**。对于使用余弦式几何训练的密集嵌入,**标准化**向量的L2与角度距离密切相关;Milvus优化了包括L2在内的常见度量类型的ANN搜索。返回的分数是距离——**越低越相似**——这保持了排名语义的简单性,便于调试以及在操作工作流程中进行阈值设置。
### 为什么规划器使用结构化输出(Pydantic)?
规划器的计划被建模为**类型化模式**(例如步骤列表)而不是无约束的散文。这会产生:
- **确定性下游行为** — 执行器消费步骤列表,而不是必须重新解析的文本blob。
- **边界验证** — 无效或空的计划快速失败,而不是损坏图状态。
- **更容易测试** — 您可以在单元和集成测试中断言结构化计划。
固定检索指标和结构化规划输出使代理在生产中比完全自由形式的“感觉-only”链更容易推理。
## 许可证
在MIT许可证下分发。请参阅存储库中的`LICENSE`文件以获取全文。
标签:AIOps, API, HTTP接口, IT运营, LangGraph, Milvus, Plan-Execute-Replan, SOP, SRE, 事后分析, 偏差过滤, 向量数据库, 工具使用, 恶意软件库, 故障诊断, 智能运维, 知识检索, 结构化推理, 自动化运维, 诊断工作流, 语义搜索, 运行手册, 逆向工具, 问题解决