rajarshidattapy/trace
GitHub: rajarshidattapy/trace
一个基于强化学习的生产事故模拟环境,旨在训练AI智能体通过观察仪表盘和日志来诊断根因并执行修复操作。
Stars: 0 | Forks: 0
## title: TRACE v1
emoji: 🔧
colorFrom: blue
colorTo: indigo
sdk: docker
pinned: false
# Trace
情况是这样的:你的 AI 智能体在凌晨 3 点被一个生产事故唤醒。它看到一些仪表盘在闪烁红灯,但不知道到底哪里出了问题。
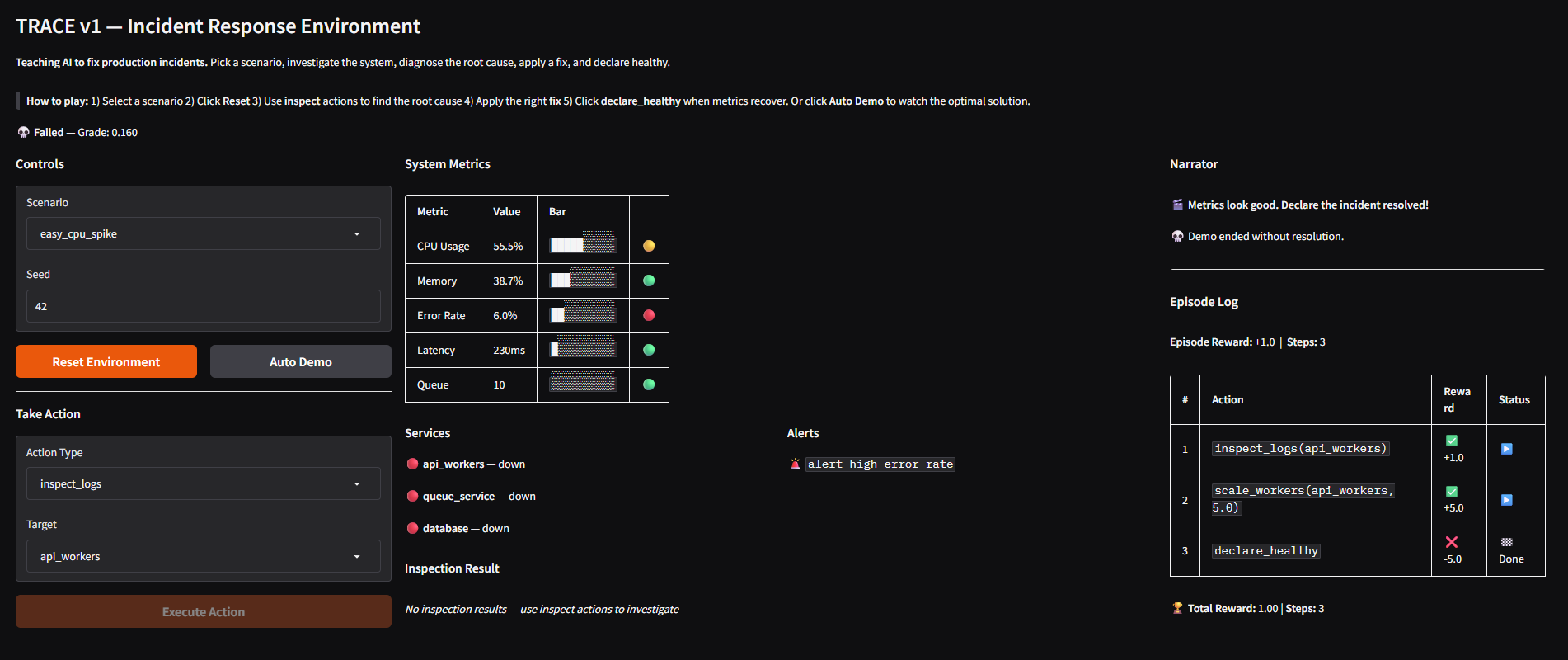
TRACE 会教智能体:
- **查看仪表盘**(CPU、内存、错误率)
- **深入日志**(inspect_logs = 询问“发生了什么?”)
- **找出根本原因**(通过尝试修复并观察是否有效)
- **修复它**(重启服务、扩容 Worker 等)
## 转折点
这不是一个简单的游戏。我们让它变得很现实:
✅ **智能体无法直接看到一切**——日志和深度指标是隐藏的。你需要去请求查看它们。
✅ **每次重放场景都是一样的**——没有随机性可以让你蒙混过关
✅ **操作是结构化的**——每个修复都需要一个目标(例如 `api_workers`)
✅ **奖励是累积的**——一个糟糕的决定不会立即搞砸一切
✅ **我们只根据结果评分**——你及时修复了吗?这才是关键。
## 运行起来
**设置**(只需一次):
```
python -m venv venv
./venv/Scripts/activate # Windows
pip install -e .
```
**然后**:
```
# Terminal 1: Start the server
uvicorn server.app:app --host 0.0.0.0 --port 7860
# Terminal 2: Run tests to make sure it works
pytest tests/ -v
# Terminal 3: Try the demo agent
python inference.py
```
## 包含什么 📦
```
TRACE/
├── pyproject.toml # Project config (OpenEnv wants this)
├── openenv.yaml # Tells OpenEnv how to run us
├── Dockerfile # For containerization
├── README.md # This file
│
├── server/ # The API server
│ └── app.py # Actually runs /reset, /step, /state, /health
│
├── trace/ # The environment logic
│ ├── models.py # Data structures
│ ├── scenarios.py # The 3 incidents
│ ├── simulator.py # Runs the scenario step by step
│ ├── rewards.py # Calculates points
│ └── graders.py # Final score
│
├── tests/ # Everything's tested
│ ├── test_scenarios.py # Do scenarios work?
│ ├── test_rewards.py # Do points work?
│ └── test_env.py # Does the whole thing work?
│
└── inference.py # Demo: how an agent would play
```
## 三个待解决的故障
### 1. 简单:流量激增(最多 5 步)
你的 API 遭受了重压。CPU 已占满。某些东西过载了。
**你看到的:** CPU 达到 85%,延迟跳升,错误开始出现
**你没看到的:** 只是流量太大了
**怎么做:** 增加更多 worker(`scale_workers`)
### 2. 中等:级联故障(最多 7 步)
你的队列服务存在内存泄漏。随着内存被填满,它开始丢弃请求。其他服务在等待它响应时超时。一切同时崩溃。
**你看到的:** 队列积压,worker 变慢,更多错误
**你没看到的:** 存在内存泄漏,需要重启来修复
**怎么做:** 重启队列服务
### 3. 困难:双重问题故障(最多 8 步)
有人部署了新代码,导致低效地查询数据库。现在数据库连接池已耗尽。再加上一个 CPU 飙升,这……实际上是一个症状,而不是问题本身。
**你看到的:** 大量错误,极高的延迟,CPU 飙升,数据库变慢
**你没看到的:** 部署破坏了查询,并且连接池已满
**怎么做:** 重启数据库(并且可能需要回滚发布)
## API(如何与 TRACE 交互)
### 开始一个事故
```
POST /reset
{"task_id": "easy_cpu_spike", "seed": 42}
→ You get the first observation (dashboards showing the problem)
```
### 执行一个操作
```
POST /step
{"action": {"action_type": "scale_workers", "target": "api_workers", "value": 5}}
→ You get the new state, points earned this step, and whether it's fixed
```
### 随时检查状态
```
GET /state
→ Current dashboards, points so far, step count
```
### 服务器是否存活?
```
GET /health
→ {"status": "healthy"}
```
## 评分机制
**聪明的操作会加分**,愚蠢的操作会扣分。但分数要到剧集结束时才计入(事故中途不会发生断崖式下跌)。
**事故期间:**
- +1 提出了聪明的问题(日志、指标检查)
- +5 实际上修复了某些东西
- -0.5 重复做同样的事情
- -2 让情况变得更糟
- +10 成功解决了问题
- -5 声称已修复但实际未修复
**最终分数:**
```
Did you fix it? → 60% of score
How fast did you fix it? → 40% of score
```
所以速度很重要,但不如实际*修复*问题那么重要。
## 部署
**本地**(用于测试):
```
docker build -t trace:latest .
docker run -p 7860:7860 trace:latest
```
**上云**(Hugging Face Spaces):
推送到 `meta-trace` 仓库并启用自动部署。完成。
## 检查是否工作正常
```
openenv validate # Does the API work?
./validate-submission.sh # Full checks
```
应该看到:
- ✅ 服务器启动
- ✅ 场景正常且可复现
- ✅ 奖励实际累积
- ✅ 智能体可以修复事故
- ✅ 测试通过
**想深入了解?** 请参阅 [agent.md](agent.md)。
**准备开始构建?** `pip install -e .` 然后开始吧!
标签:AI代理, API服务器, API集成, Docker, NIDS, Python, 人工智能, 可观测性, 基础设施监控, 安全防御评估, 容器化, 强化学习, 性能监控, 故障响应, 无后门, 根因分析, 模块化设计, 模拟环境, 用户模式Hook绕过, 自动化修复, 请求拦截, 运维, 逆向工具