LoseNine/ruyipage
GitHub: LoseNine/ruyipage
基于 WebDriver BiDi 协议的 Python 版 Firefox 自动化框架,专注于提供高层 API 和绕过自动化检测的浏览器控制能力。
Stars: 1720 | Forks: 203
# ruyiPage
[简体中文](./README.md) | [English](./README_EN.md)
## 项目定位
`ruyiPage` 是一个面向 **Firefox 浏览器自动化** 的 Python 库,底层协议来自:
- WebDriver BiDi: https://w3c.github.io/webdriver-bidi/
如果你想找的不是“又一个 CDP 自动化库”,而是:
- **新一代 Firefox 自动化框架**
- **基于 BiDi 协议,而不是 CDP 协议**
- **原生动作能实现大量 `isTrusted` 行为**
- **内置拟人化行为能力,适合高风控页面**
- **支持网络劫持、拦截、mock、collector 等能力**
- **更适合做长期维护的 Firefox 自动化体系**
那么 `ruyiPage` 就是为这个方向准备的。
你可以把它理解成:
它尤其强调四件事:
- **不依赖 CDP**,天然没有 CDP 路线的那层暴露面
- **原生动作链优先**,尽量让输入、拖拽、点击等行为保持 `isTrusted`
- **内置拟人行为能力**,更适合高风控页面的真实交互场景
- **高层 API 可直接上手**,更适合新手和团队统一维护
## 能力总览
在看详细文档前,你可以先看这张总表,快速了解 `ruyiPage` 现在已经能做什么。
| 能力大类 | 高层入口 | 典型能力 |
| --- | --- | --- |
| 页面导航 | `page.get()` / `page.back()` / `page.forward()` | 打开页面、刷新、前进后退 |
| 元素查找 | `page.ele()` / `page.eles()` / `ele.ele()` | CSS/XPath/Text 定位、容器内继续查找 |
| 元素交互 | `ele.click_self()` / `ele.input()` / `ele.attr()` / `ele.text` | 点击、输入、取属性、读文本 |
| 动作链 | `page.actions` | 键盘、鼠标、拖拽、滚轮、拟人动作 |
| 触摸输入 | `page.touch` | tap、long press 等触摸操作 |
| Cookies | `page.get_cookies()` / `page.set_cookies()` / `page.delete_cookies()` | 读取、设置、删除 Cookie |
| 下载 | `page.downloads` | 设置下载目录、等待下载事件、验证落盘 |
| PDF / 截图 | `page.save_pdf()` / `page.screenshot()` | 页面打印 PDF、保存截图 |
| 弹窗处理 | `page.wait_prompt()` / `page.accept_prompt()` / `page.set_prompt_handler()` | alert / confirm / prompt |
| 导航事件 | `page.navigation` | navigationStarted、load、historyUpdated 等 |
| 通用事件 | `page.events` | browsingContext / network / script / input / log 事件 |
| 网络控制 | `page.network` / `page.intercept` | 请求头、缓存控制、拦截、mock、fail、collector |
| 浏览上下文 | `page.contexts` | getTree、create tab/window、reload、viewport |
| 浏览器级能力 | `page.browser_tools` | user context、client window |
| 脚本能力 | `page.get_realms()` / `page.eval_handle()` / `page.disown_handles()` | realms、远程对象句柄、preload script |
| Emulation | `page.emulation` | UA、viewport、screen、orientation、JS 开关 |
| WebExtension | `page.extensions` | 安装目录扩展、安装 xpi、卸载 |
| 本地存储 | `page.local_storage` / `page.session_storage` | 读写本地存储和会话存储 |
## 关于 Firefox 内核与 webdriver 标志
如果你的目标站点对自动化非常敏感,需要特别注意:
这不是简单的页面级 JavaScript 覆盖就能解决的问题。
也就是说:
- 不能只在页面里改 `navigator.webdriver`
- 不能只靠 preload script 做表面覆盖
- 需要使用已经在 **Firefox 内核层** 处理过 webdriver 标志的浏览器版本
只有这样,很多站点的检测才能更完整地绕过。
### 推荐方式
你可以使用任意一个已经抹除 webdriver 标志的 Firefox 版本。
例如可以使用:
- https://github.com/LoseNine/firefox-fingerprintBrowser
这类浏览器的意义在于:
- 从 Firefox 底层实现上处理 webdriver 暴露
- 不是只做前端层伪装
- 更适合配合 `ruyiPage` 访问风控更强的网站
### 结论
`ruyiPage` 的定位是:
- 提供 Firefox + BiDi 的高层自动化能力
- 避开 CDP 检测面
但如果你访问的是高风控站点,仍然建议:
1. 使用已经抹除 webdriver 的 Firefox 版本
2. 再用 `ruyiPage` 做自动化控制
这样整体效果会更稳定。
## 为什么是 Firefox + BiDi
现在很多自动化库都大量依赖 CDP(Chrome DevTools Protocol)。
`ruyiPage` 的路线不同:
- 以 **Firefox** 为核心浏览器
- 以 **WebDriver BiDi** 为核心协议
- 不依赖 CDP
这意味着:
- 没有传统 CDP 自动化暴露面
- 更贴近 W3C 新一代浏览器自动化协议方向
- 更适合做 Firefox 专项自动化、输入行为模拟、事件监听、网络控制等能力
## 和其他框架怎么选
下面这个表不讨论“谁绝对更强”,只突出你最关心的几个点:
- 各自主要偏向什么浏览器
- 是否依赖 CDP
- CDP 暴露面强不强
- Firefox / BiDi 支持度怎么样
- 针对性被检测情况怎么样
| 框架 | 主要浏览器方向 | 底层协议 | CDP 暴露面 | Firefox / BiDi 支持度 | 针对性被检测 |
| --- | --- | --- | --- | --- | --- |
| `ruyiPage` | **Firefox** | **WebDriver BiDi** | **无 CDP 暴露面** | **高**,主路线就是 Firefox + BiDi | **低**,原生 BiDi + `isTrusted` 行为 + 拟人操作,更适合高风控场景;配合内核层抹除 webdriver 的 Firefox 更稳定 |
| Playwright | Chromium / Firefox / WebKit | 自有协议,很多能力仍偏 Chromium | 中到高 | 中,支持 Firefox,但不是以 Firefox BiDi 为核心设计 | 中到高,很多站点会优先针对主流自动化指纹做识别 |
| Selenium | 多浏览器 | WebDriver Classic + 部分 BiDi | 低到中 | 中,兼容广,但高层 BiDi 能力不算强 | 中,传统自动化特征和使用面都比较广 |
| Puppeteer | Chromium | CDP | **高** | 低,基本不是 Firefox 主战场 | **高**,CDP 路线暴露面更明显,也更容易被针对性检测 |
| DrissionPage | Chromium | 混合驱动思路,核心仍偏 Chromium | 中到高 | 低,Firefox 不是主方向 | 中到高,更偏 Chromium 自动化场景,同样容易落入主流检测面 |
### 一句话建议
- 你主做 **Firefox 自动化**:优先 `ruyiPage`
- 你要 **多浏览器统一自动化**:优先 Playwright / Selenium
- 你主做 **Chromium/CDP**:优先 Puppeteer / Playwright
- 你想要 **Firefox + 不依赖 CDP + BiDi 高层封装**:`ruyiPage` 是更对路的选择
## 实战展示
下面这些图放的是实际场景展示。为了在 GitHub 首页里更紧凑,我这里用两列表格展示。
## 安装
pip install ruyiPage --upgrade
如果你是首次安装,也可以直接用上面的命令获取最新版。
安装后建议先确认:
python -c "import ruyipage; print(ruyipage.__version__)"
## 基础配置
### 1. 最简单启动
from ruyipage import FirefoxPage
page = FirefoxPage()
page.get("https://www.example.com")
print(page.title)
page.quit()
### 2. 指定 Firefox 路径和 userdir
from ruyipage import FirefoxOptions, FirefoxPage
opts = FirefoxOptions()
opts.set_browser_path(r"D:\Firefox\firefox.exe")
opts.set_user_dir(r"D:\ruyipage_userdir")
page = FirefoxPage(opts)
page.get("https://www.example.com")
print(page.title)
page.quit()
### 3. 更适合新手的 launch
from ruyipage import launch
page = launch(
browser_path=r"D:\Firefox\firefox.exe",
user_dir=r"D:\ruyipage_userdir",
headless=False,
port=9222,
)
page.get("https://www.example.com")
print(page.title)
page.quit()
### 浏览器路径和 userdir 是什么
#### `browser_path`
Firefox 可执行文件路径。
适合这些情况:
- Firefox 不在默认安装目录
- 你有多个 Firefox 版本
- 你用便携版 Firefox
#### `user_dir`
也就是 Firefox 的 profile / 用户目录。
适合这些情况:
- 想复用登录状态
- 想保留 Cookie / 本地存储
- 想复用扩展、证书、首选项
如果不设置:
- `ruyiPage` 会自动创建临时 profile
- 适合一次性测试
- 关闭后通常会被清理
## 根目录快速开始示例
### 1. Bing 搜索示例
文件:`quickstart_bing_search.py`
它会:
- 打开 Bing
- 输入关键词
- 回车搜索
- 抓取前 3 页结果
- 打印标题、URL、摘要
核心写法:
from ruyipage import FirefoxOptions, FirefoxPage, Keys
opts = FirefoxOptions()
page = FirefoxPage(opts)
page.get("https://cn.bing.com/")
page.ele("#sb_form_q").input("小肩膀教育")
page.actions.press(Keys.ENTER).perform()
for item in page.eles("css:#b_results > li.b_algo"):
title_ele = item.ele("css:h2 a")
title = title_ele.text
url = title_ele.attr("href")
### 2. Cloudflare / Copilot 示例
文件:`quickstart_cloudfare.py`
它会:
- 打开 Copilot
- 尝试寻找输入框并发问
- 自动尝试处理 Cloudflare
- 最后打印完整 Cookie
这个示例更适合你理解:
- `page.handle_cloudflare_challenge()`
- `page.get_cookies(all_info=True)`
- `FirefoxOptions` 如何写进新手脚本
### 3. 指纹浏览器示例
文件:`quickstart_fingerprint_browser.py`
它会:
- 启动已抹除 webdriver 的 Firefox 指纹浏览器
- 通过 `--fpfile=...` 加载指纹文件
- 打开 `browserscan` 检查指纹结果
- 叠加地理位置、时区、语言、请求头、屏幕尺寸模拟
核心写法:
from ruyipage import FirefoxOptions, FirefoxPage
opts = FirefoxOptions()
opts.set_browser_path(r"C:\Program Files\Mozilla Firefox\firefox.exe")
opts.set_fpfile(r"C:\fingerprints\profile1.txt")
page = FirefoxPage(opts)
page.get("https://www.browserscan.net/zh")
page.emulation.set_geolocation(39.9042, 116.4074, accuracy=100)
page.emulation.set_timezone("Asia/Tokyo")
page.emulation.set_locale(["ja-JP", "ja"])
page.network.set_extra_headers({
"Accept-Language": "ja-JP,ja;q=0.9"
})
page.emulation.set_screen_size(1366, 768, device_pixel_ratio=2.0)
page.refresh()
适用场景:
- 需要把 Firefox 指纹浏览器和 `ruyiPage` 配合使用
- 希望把指纹文件、语言、请求头、屏幕参数一起带上
- 想直接验证 `browserscan` 等站点上的指纹表现
## 最常用 API 文档
下面不是底层 BiDi 命令表,而是 **新手最常直接用到的高层 API**。
阅读建议:
1. 先看 `FirefoxPage`
- 这是最核心的页面对象,绝大多数操作都从这里开始。
2. 再看 `ele()` / `eles()`
- 元素定位是最常用的基础能力。
3. 再看 `actions / downloads / network / events`
- 这些是自动化中最常扩展的高级能力。
文档风格说明:
- 这里优先写 **最常用、最实用** 的高层接口。
- 不会把底层 BiDi 命令原样堆出来让新手自己拼参数。
- 每个能力尽量说明:
- 它是做什么的
- 什么时候该用
- 最常见的写法是什么
- 返回值你能继续怎么用
## 1. 页面对象:`FirefoxPage`
### 创建页面
from ruyipage import FirefoxPage, FirefoxOptions
page = FirefoxPage()
opts = FirefoxOptions()
page = FirefoxPage(opts)
### 常用属性
| API | 说明 | 返回值 |
| --- | --- | --- |
| `page.title` | 当前页面标题 | `str` |
| `page.url` | 当前页面 URL | `str` |
| `page.html` | 当前页面 HTML | `str` |
| `page.tab_id` | 当前 tab 的 browsingContext ID | `str` |
| `page.cookies` | 当前页面可见 Cookie 列表 | `list[CookieInfo]` |
### 常用导航
page.get("https://www.example.com")
page.refresh()
page.back()
page.forward()
page.quit()
#### `page.get(url, wait='complete')`
打开一个页面。
page.get("https://www.example.com")
page.get("https://www.example.com", wait="interactive")
参数说明:
- `url`
- 要访问的地址
- 常见值:`https://...`、`file:///...`、`data:text/html,...`
- `wait`
- 页面等待策略
- 常见值:
- `complete`:等页面完全加载
- `interactive`:等 DOMContentLoaded
- `none`:发出导航后立即返回
适用场景:
- 日常页面打开:用默认 `complete`
- 页面很慢但你只想先拿 DOM:用 `interactive`
- 你后面会自己监听事件或手动等:用 `none`
#### `page.back()` / `page.forward()` / `page.refresh()`
这些分别用于:
- 后退
- 前进
- 刷新
page.back()
page.forward()
page.refresh()
如果你需要验证导航事件,建议和 `page.navigation` 配合使用。
## 2. 元素查找:`ele()` / `eles()`
### `page.ele(locator)`
查找一个元素。
最常用写法:
page.ele("#kw")
page.ele("css:.item")
page.ele("css:div.card > a")
page.ele("xpath://button[text()='登录']")
page.ele("tag:input")
page.ele("text:登录")
新手建议优先顺序:
1. `#id`
2. `css:...`
3. `xpath:...`
### `page.eles(locator)`
查找所有匹配元素。
items = page.eles("css:.card")
rows = page.eles("css:table tbody tr")
links = page.eles("tag:a")
### 在元素内部继续查找
card = page.ele("css:.card")
title = card.ele("css:h2 a")
desc = card.ele("css:.desc")
### 常用元素 API
| API | 说明 | 返回值 |
| --- | --- | --- |
| `ele.text` | 元素文本 | `str` |
| `ele.html` | outerHTML | `str` |
| `ele.value` | 表单值 | `str | None` |
| `ele.attr("href")` | 属性值 | `str` |
| `ele.click_self()` | 直接点击元素 | `self` |
| `ele.input("abc")` | 输入文本 | `self` |
| `ele.clear()` | 清空内容 | `self` |
| `ele.hover()` | 鼠标悬停 | `self` |
| `ele.drag_to(target)` | 拖到目标 | `self` |
#### `ele.text`
读取元素文本。
title = page.ele("css:h1").text
适合读取:
- 标题
- 按钮文案
- 搜索结果摘要
#### `ele.attr(name)`
读取元素属性。
url = page.ele("css:a").attr("href")
src = page.ele("css:img").attr("src")
常见属性:
- `href`
- `src`
- `value`
- `placeholder`
- `class`
- `id`
#### `ele.click_self()`
直接点击元素。
page.ele("text:登录").click_self()
这是最推荐新手使用的点击方法。
#### `ele.input(text, clear=True)`
给输入框输入内容。
page.ele("#kw").input("ruyiPage")
page.ele("#kw").input("ruyiPage", clear=True)
适用场景:
- 文本输入
- 搜索框输入
- 文件输入框上传文件
如果元素本身是 ``,传文件路径即可:
page.ele("#upload").input(r"D:\test.txt")
page.ele("#upload").input([r"D:\1.txt", r"D:\2.txt"])
## 3. 动作链:`page.actions`
用于原生 BiDi 输入动作。
page.actions.press(Keys.ENTER).perform()
page.actions.move_to(page.ele("#btn")).click().perform()
page.actions.drag(page.ele("#a"), page.ele("#b")).perform()
page.actions.release()
常见用途:
- 键盘输入
- 鼠标点击
- 拖拽
- 滚轮滚动
- 拟人化移动和点击
### 常见写法
#### 回车
from ruyipage import Keys
page.actions.press(Keys.ENTER).perform()
#### 点击某个元素
page.actions.move_to(page.ele("#btn")).click().perform()
#### 拖拽
page.actions.drag(page.ele("#source"), page.ele("#target")).perform()
page.actions.release()
### 为什么推荐 `page.actions`
因为这条链更接近原生 BiDi 输入模型,很多动作事件能保持更真实的浏览器输入行为。
## 4. Cookies
### 获取 Cookie
cookies = page.get_cookies()
for cookie in cookies:
print(cookie.name, cookie.value)
返回对象通常是 `CookieInfo`,常用字段:
- `cookie.name`
- `cookie.value`
- `cookie.domain`
- `cookie.path`
- `cookie.http_only`
- `cookie.secure`
- `cookie.same_site`
- `cookie.expiry`
### 按条件过滤 Cookie
cookies = page.get_cookies_filtered(name="session_id", all_info=True)
### 设置 Cookie
page.set_cookies({
"name": "token",
"value": "abc",
"domain": "127.0.0.1",
"path": "/",
})
也可以一次传多个:
page.set_cookies([
{"name": "a", "value": "1", "domain": "127.0.0.1", "path": "/"},
{"name": "b", "value": "2", "domain": "127.0.0.1", "path": "/"},
])
### 删除 Cookie
page.delete_cookies(name="token")
page.delete_cookies()
## 5. 下载
高层入口:`page.downloads`
page.downloads.set_behavior("allow", path=r"D:\downloads")
page.downloads.start()
page.ele("#download").click_self()
event = page.downloads.wait("browsingContext.downloadEnd", timeout=5)
print(event.status)
常用方法:
- `set_behavior()`
- `set_path()`
- `start()`
- `stop()`
- `wait()`
- `wait_chain()`
- `wait_file()`
### 典型下载流程
page.downloads.set_behavior("allow", path=r"D:\downloads")
page.downloads.start()
page.ele("#download").click_self()
begin = page.downloads.wait("browsingContext.downloadWillBegin", timeout=5)
end = page.downloads.wait("browsingContext.downloadEnd", timeout=5)
print(begin.suggested_filename)
print(end.status)
## 6. 导航事件
高层入口:`page.navigation`
page.navigation.start()
page.get("https://www.example.com")
event = page.navigation.wait("browsingContext.load", timeout=5)
print(event.url)
page.navigation.stop()
适合验证:
- `navigationStarted`
- `domContentLoaded`
- `load`
- `historyUpdated`
- `navigationCommitted`
## 7. 通用事件监听
高层入口:`page.events`
page.events.start(["network.beforeRequestSent"], contexts=[page.tab_id])
event = page.events.wait("network.beforeRequestSent", timeout=5)
page.events.stop()
适合统一承接:
- `browsingContext.*`
- `network.*`
- `script.*`
- `input.*`
- `log.*`
返回对象:`BidiEvent`
常用字段:
- `method`
- `context`
- `url`
- `request`
- `response`
- `error_text`
- `channel`
- `data`
- `multiple`
- `message`
### 什么时候用 `page.events`
当你想直接监听协议事件,而不是只关心页面最终状态时,用它最合适。
例如:
- 监听 `network.beforeRequestSent`
- 监听 `browsingContext.contextCreated`
- 监听 `script.message`
- 监听 `input.fileDialogOpened`
## 8. 网络能力
高层入口:`page.network`
### 设置额外请求头
page.network.set_extra_headers({"X-Test": "yes"})
这通常用于:
- 给接口加测试请求头
- 做环境标记
- 配合拦截验证请求头是否真的发出
### 设置缓存行为
page.network.set_cache_behavior("bypass")
其中:
- `default`: 浏览器默认缓存策略,命中缓存时可能不再发真实请求
- `bypass`: 尽量绕过缓存,强制重新请求资源
### Data Collector
collector = page.network.add_data_collector(
["responseCompleted"],
data_types=["response"],
)
data = collector.get(request_id, data_type="response")
collector.disown(request_id, data_type="response")
collector.remove()
其中:
- `events`
- `beforeRequestSent`:在请求发出阶段采集
- `responseCompleted`:在响应完成阶段采集
- `data_types`
- `request`:收集请求体
- `response`:收集响应体
## 9. 浏览上下文
高层入口:`page.contexts`
tree = page.contexts.get_tree()
print(len(tree.contexts))
tab_id = page.contexts.create_tab()
page.contexts.close(tab_id)
page.contexts.reload()
page.contexts.set_viewport(800, 600)
常用方法:
- `get_tree()`
- `create_tab()`
- `create_window()`
- `close()`
- `reload()`
- `set_viewport()`
- `set_bypass_csp()`
### `tree = page.contexts.get_tree()`
返回的不是裸 dict,而是高层结果对象。
tree = page.contexts.get_tree()
print(len(tree.contexts))
first = tree.contexts[0]
print(first.context)
print(first.url)
## 10. 浏览器级能力
高层入口:`page.browser_tools`
user_context = page.browser_tools.create_user_context()
contexts = page.browser_tools.get_user_contexts()
page.browser_tools.remove_user_context(user_context)
windows = page.browser_tools.get_client_windows()
page.browser_tools.set_window_state(windows[0]["clientWindow"], state="maximized")
适合做:
- user context 管理
- client window 管理
### 典型用法
ctx = page.browser_tools.create_user_context()
tab_id = page.browser_tools.create_tab(user_context=ctx)
page.contexts.close(tab_id)
page.browser_tools.remove_user_context(ctx)
## 11. Script 能力
### 获取 realms
realms = page.get_realms()
for realm in realms:
print(realm.type, realm.context)
### 执行脚本并拿 handle
result = page.eval_handle("({a: 1, b: 2})")
print(result.success)
print(result.result.handle)
page.disown_handles([result.result.handle])
这个流程适合:
- 需要拿远程 JS 对象句柄
- 用完后再手动释放 handle
### preload script
preload = page.add_preload_script("""
() => {
window.__ready = 'ok';
}
""")
page.get("https://www.example.com")
print(page.run_js("return window.__ready"))
page.remove_preload_script(preload)
适用场景:
- 在页面脚本执行前先注入一段初始化逻辑
- 给页面预先挂钩子、打标记、注入辅助函数
## 12. 弹窗
高层入口:
- `page.wait_prompt()`
- `page.accept_prompt()`
- `page.dismiss_prompt()`
- `page.input_prompt(text)`
- `page.set_prompt_handler(...)`
- `page.clear_prompt_handler()`
### 典型写法
#### 等待后手动处理
page.run_js("alert('hello')", as_expr=False)
prompt = page.wait_prompt(timeout=3)
page.accept_prompt()
#### 自动处理 prompt
page.set_prompt_handler(prompt="ignore", prompt_text="张三")
page.run_js("prompt('请输入姓名')", as_expr=False)
page.clear_prompt_handler()
page.set_prompt_handler(prompt="ignore", prompt_text="张三")
page.run_js("prompt('请输入姓名')", as_expr=False)
page.clear_prompt_handler()
## 13. Emulation
高层入口:`page.emulation`
page.emulation.set_network_offline(True)
page.emulation.set_javascript_enabled(False)
page.emulation.set_scrollbar_type("overlay")
page.emulation.apply_mobile_preset(
width=390,
height=844,
device_pixel_ratio=3,
user_agent="...",
)
注意:
- 某些 emulation 命令在当前 Firefox 版本中可能未实现
- 示例里会区分“成功”和“不支持”
### 典型用法
page.emulation.apply_mobile_preset(
width=390,
height=844,
device_pixel_ratio=3,
user_agent="Mozilla/5.0 ...",
)
## 14. WebExtension
高层入口:`page.extensions`
ext_id = page.extensions.install_dir(r"D:\my_extension")
page.extensions.uninstall(ext_id)
适用场景:
- 验证 content script 是否生效
- 测试目录扩展和 xpi 安装流程
## 15. 代表性示例
仓库里已经包含大量示例,建议按编号学习。
推荐顺序:
### 入门
- `01_basic_navigation.py`
- `02_element_finding.py`
- `03_element_interaction.py`
- `05_actions_chain.py`
- `06_screenshot.py`
### 页面与脚本
- `07_javascript.py`
- `08_cookies.py`
- `09_tabs.py`
- `13_iframe.py`
- `14_shadow_dom.py`
### 高级能力
- `17_user_prompts.py`
- `18_advanced_network.py`
- `19_pdf_printing.py`
- `20_advanced_input.py`
- `21_emulation.py`
### 严格结果版示例
- `23_download.py`
- `24_navigation_events.py`
- `25_browser_user_context.py`
- `26_browsing_context_advanced.py`
- `27_emulation_advanced.py`
- `28_network_data_collector.py`
- `29_script_input_advanced.py`
- `30_browsing_context_events.py`
- `31_network_events.py`
- `32_script_events.py`
- `33_log_input_events.py`
- `34_remaining_commands.py`
- `35_native_bidi_drag.py`
- `36_native_bidi_select.py`
## 协议来源
`ruyiPage` 的底层核心能力对照并基于:
- WebDriver BiDi: https://w3c.github.io/webdriver-bidi/
这也是本项目很多高层 API 的设计来源,例如:
- `browsingContext.*`
- `network.*`
- `script.*`
- `input.*`
- `browser.*`
- `emulation.*`
## Star History
[](https://www.star-history.com/?repos=LoseNine%2Fruyipage&type=date&legend=top-left)
## 最后说明
`ruyiPage` 的核心方向不是“把所有底层 BiDi 命令原样裸露给用户”,而是:
- 对 Firefox 自动化足够友好
- 对新手足够直观
- 对编辑器跳转足够友好
- 对高级用户保留足够的 BiDi 能力空间
如果你主要使用 **Firefox** 做自动化,并且希望尽量避开 CDP 检测面,
同时又想要比直接写底层协议更好理解的 API,`ruyiPage` 就是为这个方向准备的。
## 使用声明与免责声明
本项目仅用于:
- 探索下一代自动化框架
- 学习 Firefox 自动化能力
- 学习 WebDriver BiDi 协议
- 学习浏览器自动化高层 API 设计
- 合法、合规、非盈利的个人研究与技术交流
### 授权范围
允许任何人以个人身份使用或分发本项目源代码,但仅限于:
- 学习目的
- 技术研究目的
- 合法、合规、非盈利目的
个人或组织如未获得版权持有人授权,不得将本项目以源代码或二进制形式用于商业行为。
### 使用条款
使用本项目需满足以下条款,如使用过程中出现违反任意一项条款的情形,授权自动失效。
- 禁止将 `ruyiPage` 应用于任何可能违反当地法律规定和道德约束的项目中
- 禁止将 `ruyiPage` 用于任何可能有损他人利益的项目中
- 禁止将 `ruyiPage` 用于攻击、骚扰、批量滥用、恶意注册、撞库、刷量等行为
- 禁止将 `ruyiPage` 用于规避平台安全机制后实施违法行为
- 使用者应遵守目标网站或系统的 Robots、服务条款及当地法律法规
- 禁止将 `ruyiPage` 用于采集法律、条款或 Robots 协议明确不允许的数据
### 风险与责任
使用 `ruyiPage` 发生的一切行为,均由使用人自行负责。
因使用 `ruyiPage` 进行任何行为所产生的一切纠纷及后果,均与版权持有人无关。
版权持有人不承担任何因使用 `ruyiPage` 带来的风险、损失、封号、限制、数据问题、法律后果或间接损失。
版权持有人也不对 `ruyiPage` 可能存在的缺陷、兼容性问题、误操作风险或目标网站策略变化导致的任何损失承担责任。
### 特别说明
本项目强调:
- Firefox 自动化
- BiDi 协议能力
- `isTrusted` 行为
- 拟人化行为能力
- 高风控场景适配
但这些能力仅限于**合法、合规、正当**的技术研究和自动化应用场景。
## 请我喝咖啡
如果这个项目对你有帮助,欢迎请我喝杯咖啡,支持我继续完善 `ruyiPage`。

可直接通过 Cloudflare 5s 盾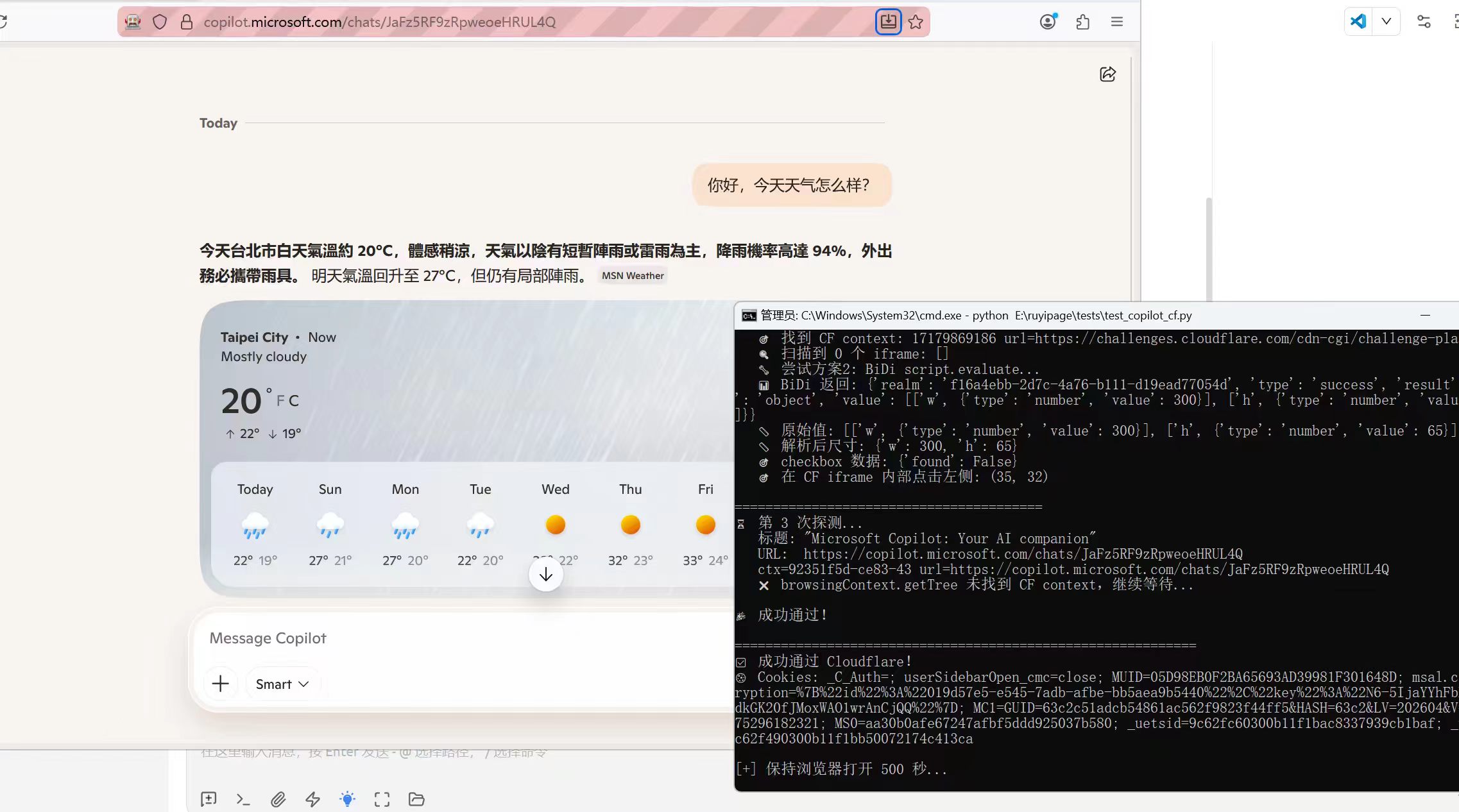 |
可直接通过 hCaptcha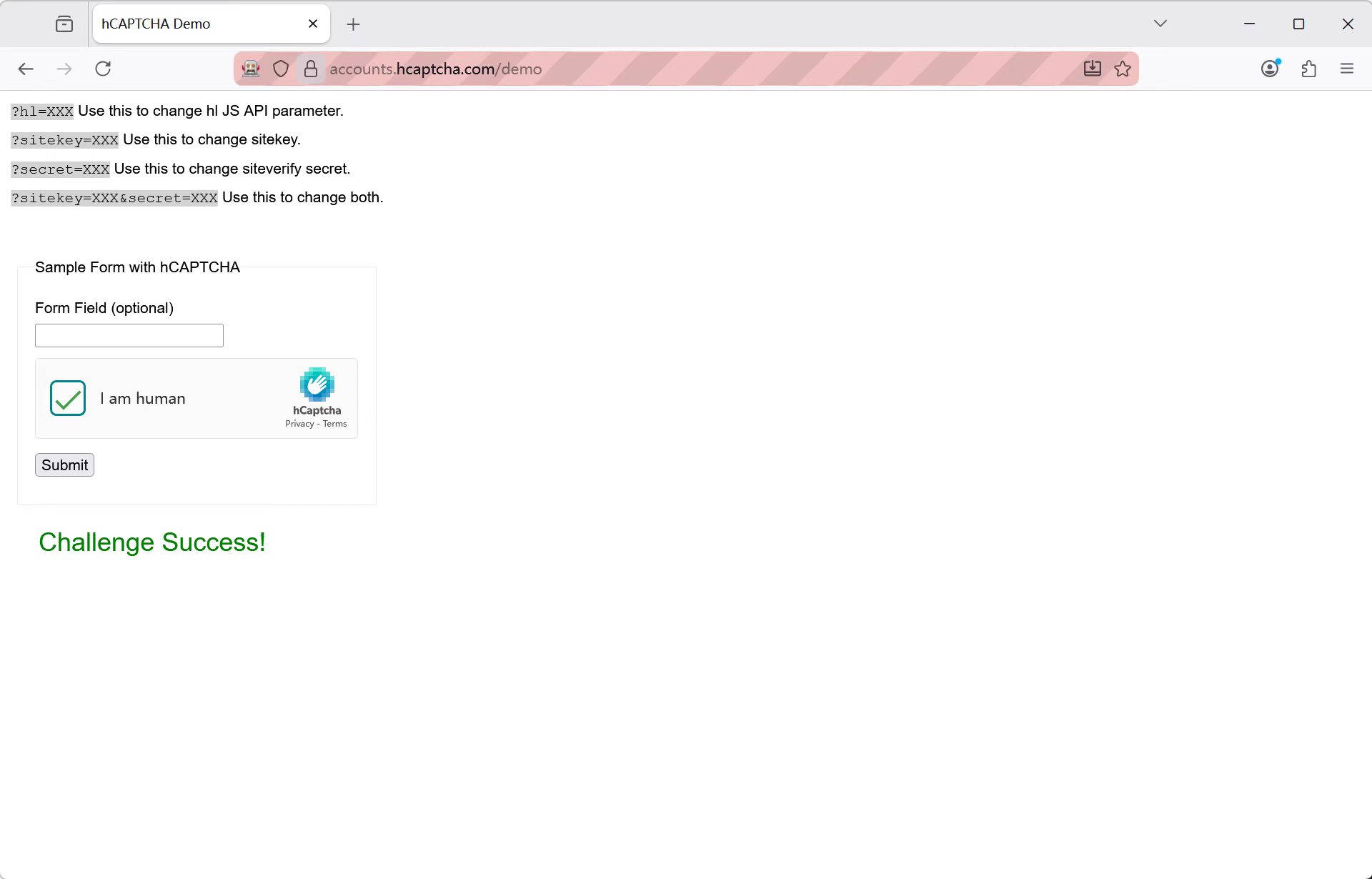 |
可直接通过 DataDome |
可直接进入 Outlook Mail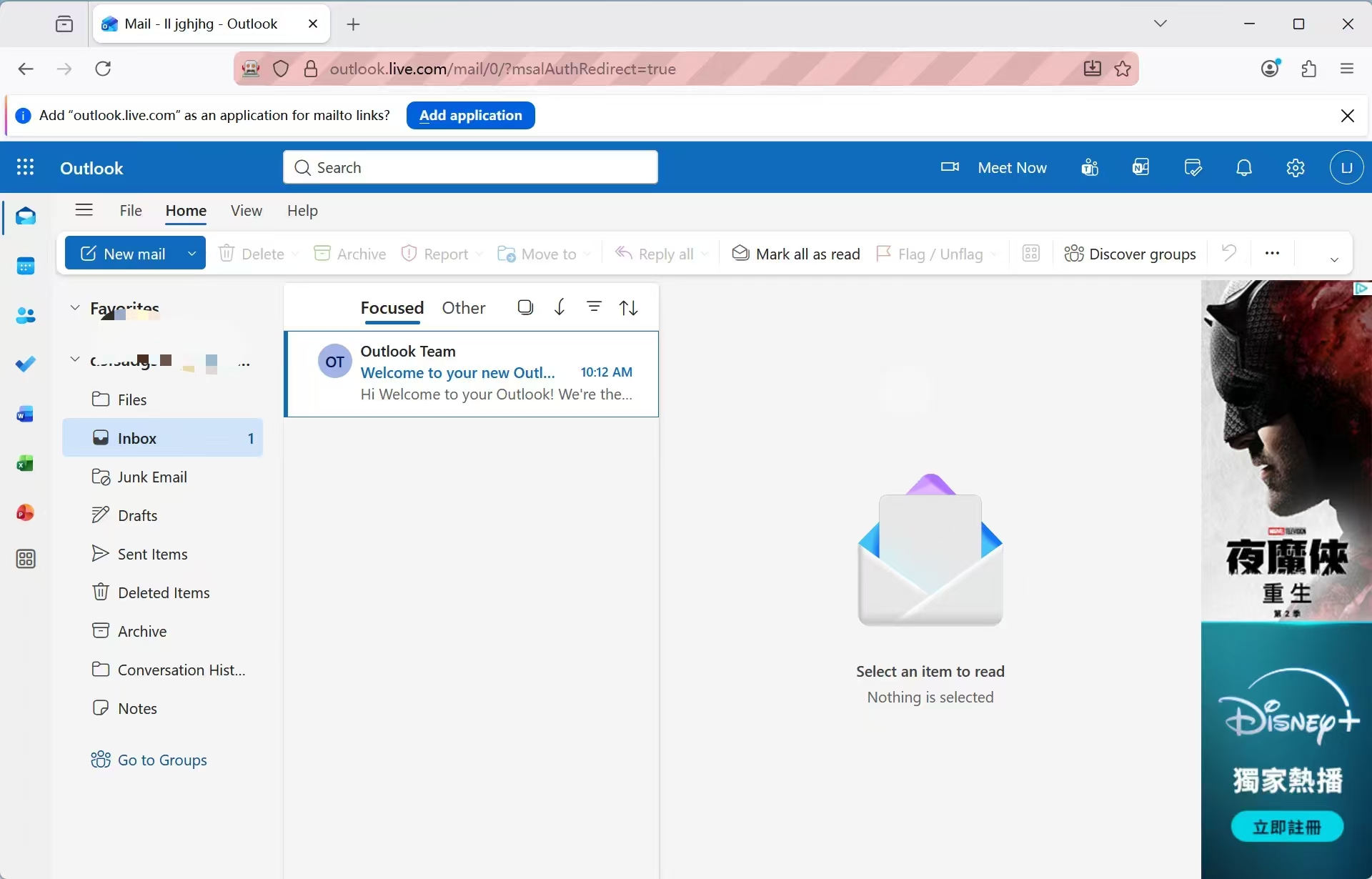 |
可直接进入 Google Mail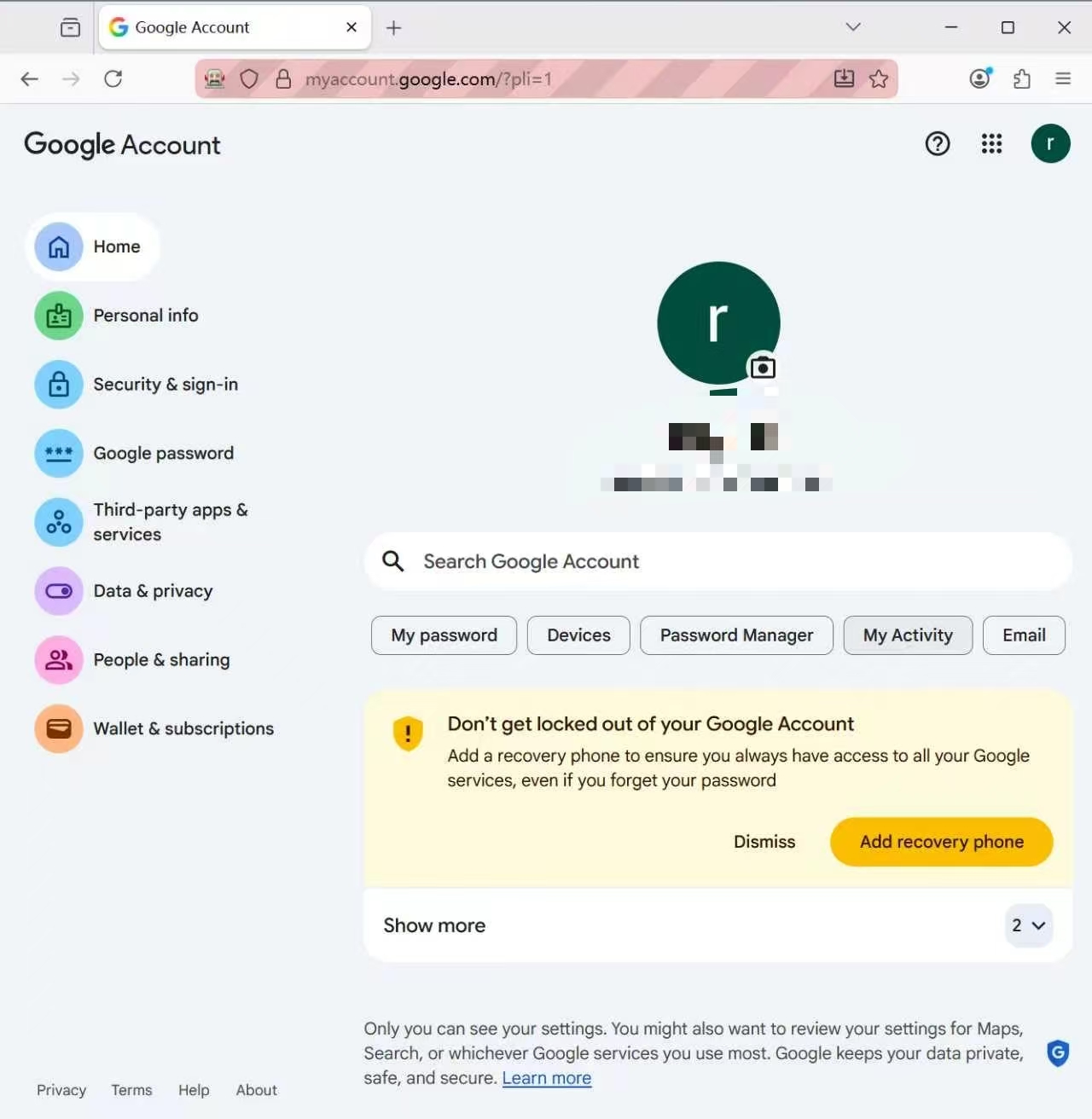 |
指纹浏览器指纹页展示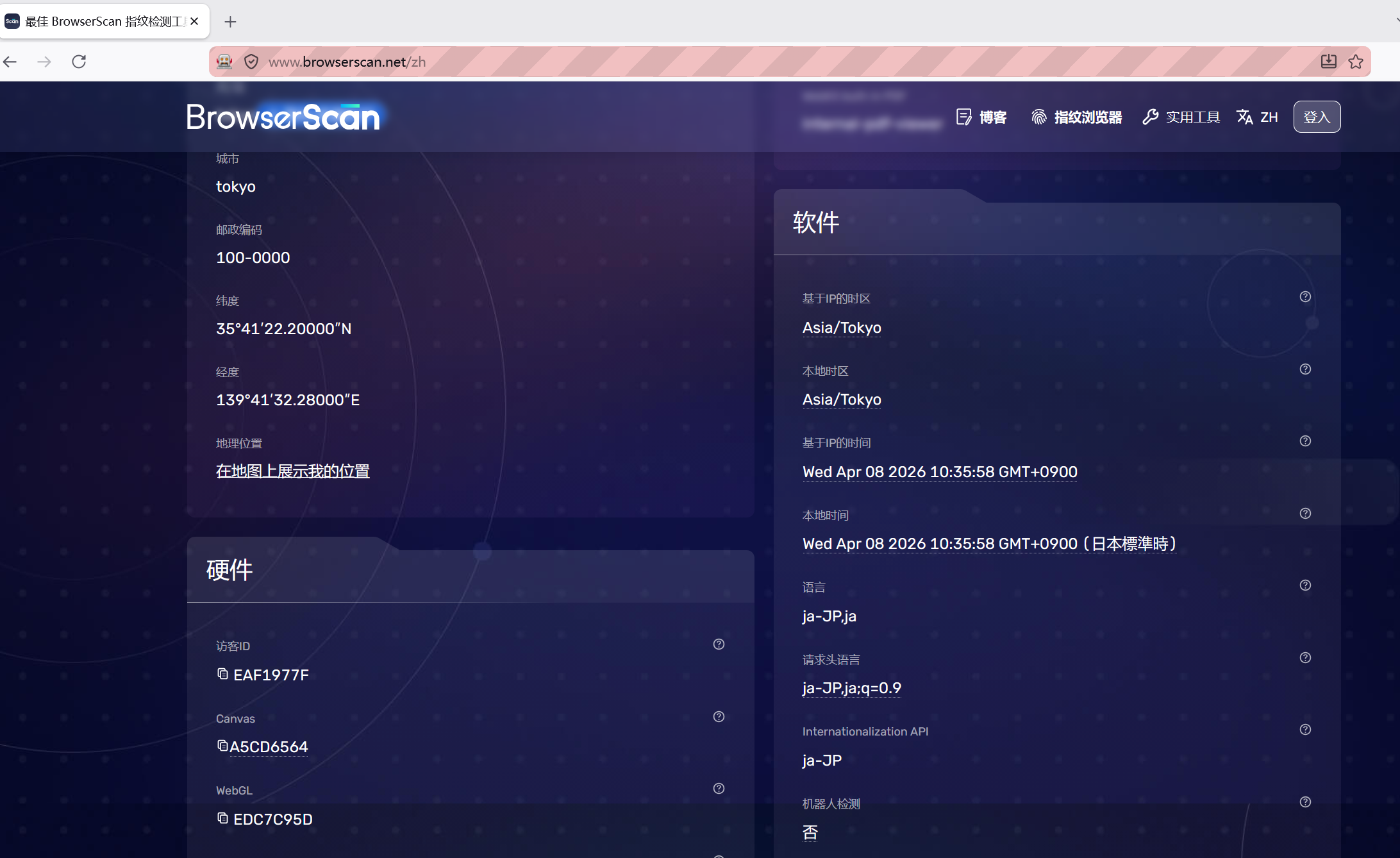 |
公众号
|
QQ 社群
|
联系我 / 个人微信
|
请我喝咖啡
|
标签:CDP替代方案, Firefox自动化, Python爬虫, Selenium, WebDriver BiDi, Web测试, Web自动化, 元素定位, 动作链, 反检测, 拟人化操作, 浏览器自动化, 爬虫框架, 网络mock, 网络拦截, 逆向工具, 高风控页面