xbtlin/ai-berkshire
GitHub: xbtlin/ai-berkshire
基于 Claude Code 的价值投资研究框架,融合四位投资大师方法论,通过多 Agent 并行对抗分析实现专业级投资决策。
Stars: 1473 | Forks: 263
[English](README_EN.md) | 中文
# AI Berkshire - AI 时代的价值投资研究框架
**AI Berkshire** 是一套基于 [Claude Code](https://claude.ai/code) 的投资研究 Skill 合集,将巴菲特、芒格、段永平、李录四位价值投资大师的方法论系统化、结构化,通过 AI Agent 实现专业级投资研究。
一个人 + Claude = 一个投研团队。
## Real Track Record
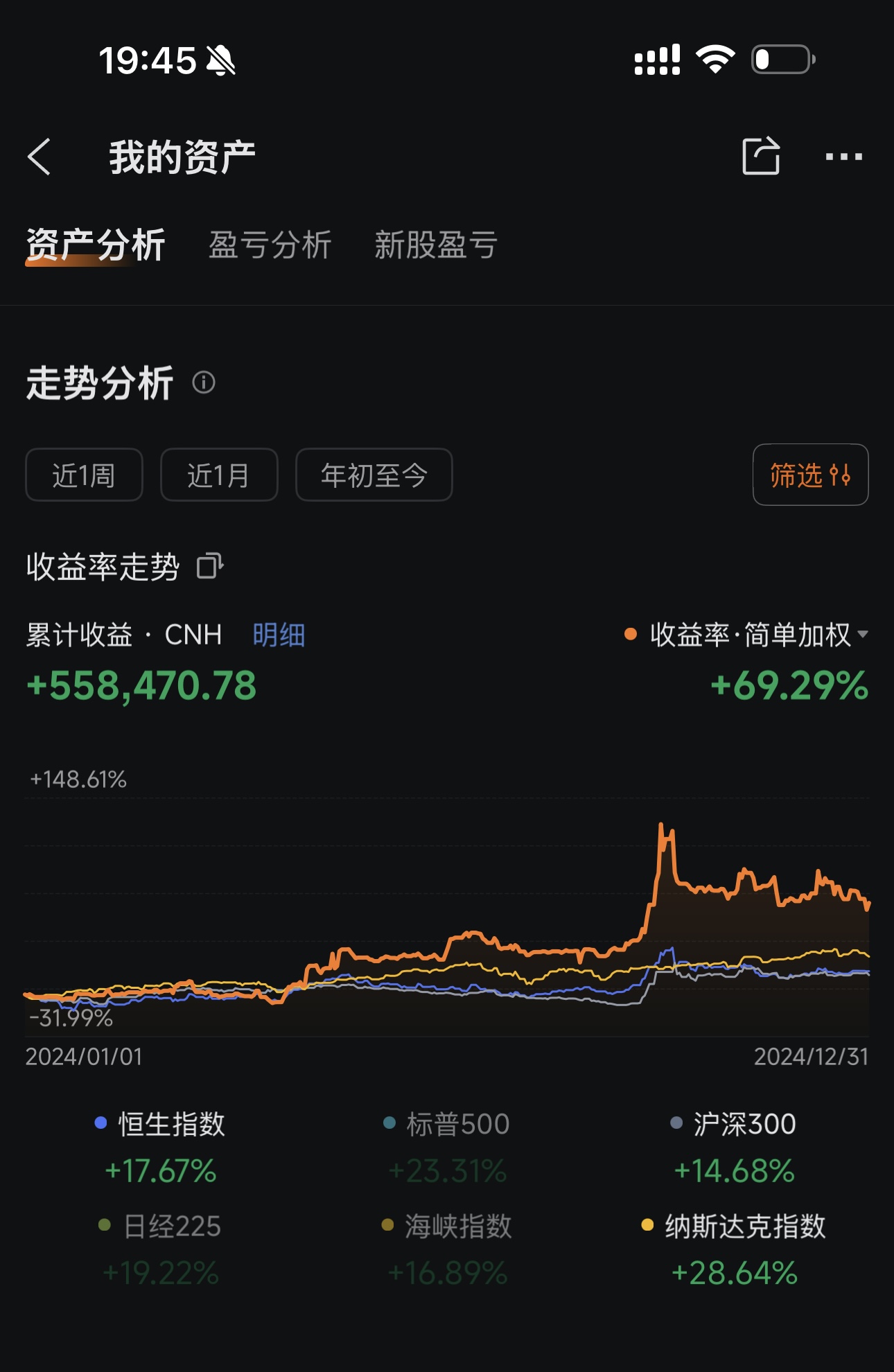
### 2024 全年收益:+69.29%
 ### 2025 年至今收益:+66.38%
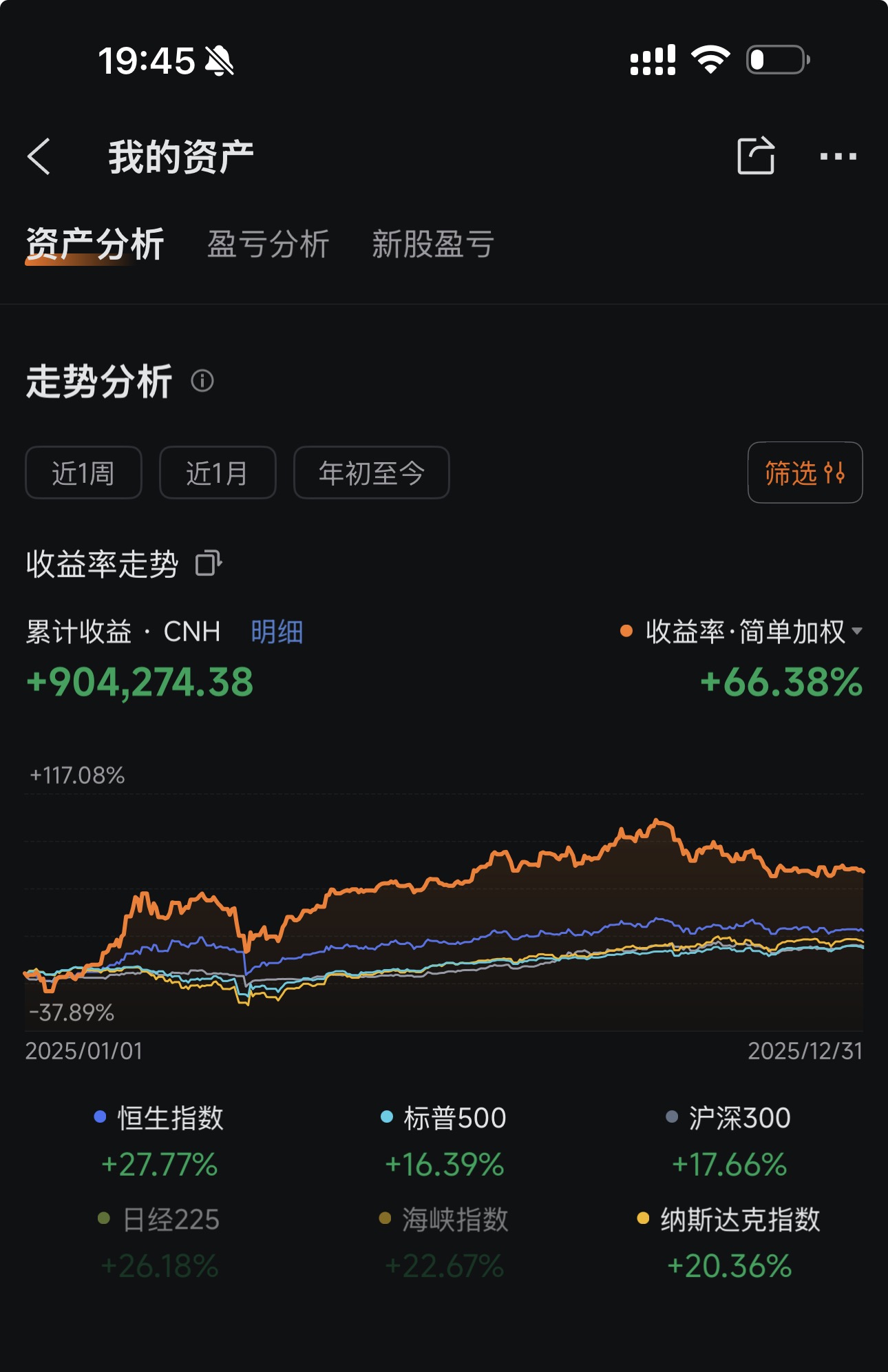
### 2025 年至今收益:+66.38%
 ### 与主要指数对比
| 指标 | 2024 全年 | 2025 至今 |
|------|----------|----------|
| **本框架实盘** | **+69.29%** | **+66.38%** |
| 恒生指数 | +17.67% | +27.77% |
| 标普500 | +23.31% | +16.39% |
| 沪深300 | +14.68% | +17.66% |
| 纳斯达克 | +28.64% | +20.36% |
**2024 年超额收益**:跑赢标普500 **46个百分点**,跑赢恒生指数 **52个百分点**
**2025 年超额收益**:跑赢标普500 **50个百分点**,跑赢恒生指数 **39个百分点**
**两年累计实盘收益超 146万元**,连续两年大幅跑赢全球主要指数。
## 为什么不能直接问 AI?
你当然可以直接问 Claude:"帮我分析拼多多值不值得买"。你会得到一篇"一方面...另一方面..."的平衡分析,最后以"投资有风险,请自行判断"收尾。
**这种分析看起来对,但没法拿来做决策。**
AI Berkshire 解决的不是"能不能分析"的问题,而是**分析质量和决策纪律**的问题。以下是核心差异:
### 1. 强制给结论,不打太极
直接问AI,你得到的是两面讨好的"分析"。AI Berkshire 强制输出:**通过/不通过/灰色地带**,带具体价格区间和分层建议。
### 2. 四大师视角对抗,而非单一分析
不是"用巴菲特方法分析一下"这么简单。四个视角会产生**真实的矛盾和张力**——
以拼多多为例:
- **段永平**(商业模式):好生意,C2M模式难以复制 → 评分 3.7/5
- **巴菲特**(财务估值):扣现金PE仅6.3x,印钞机 → 评分 4.4/5
- **芒格**(逆向思考):护城河比想象中浅,抖音3年做到4万亿GMV → 评分 3.5/5
- **李录**(长期确定性):管理层文化有隐患,10年后不确定 → 评分 2.0/5
**巴菲特说"真便宜",李录说"不确定就不买"**——这种冲突才是投资决策的真实状态。单一prompt无法制造这种多视角对抗,而这恰恰是避免盲点的关键。
### 3. 结构化反偏见机制
AI最危险的不是给错答案,而是给一个**看起来很对但经不起推敲**的答案。AI Berkshire 在流程中内置了多层"防骗"机制:
| 机制 | 解决什么问题 | 举例 |
|------|------------|------|
| **信息丰富度评级(A/B/C)** | 防止"资料多=确定性高"的幻觉 | 泡泡玛特评为B级:数据有限,推算指标标注置信度 |
| **芒格式逆向检验** | 强制思考失败场景 | "什么情况下拼多多会死?"→ 列出5大情景及概率 |
| **快速否决清单** | 8条红线一票否决 | 管理层诚信污点 → 直接否决,不管估值多便宜 |
| **反共识检查** | 避免和市场想法一样 | "聪明人为什么在做空?"→ 发现被忽视的风险 |
| **留白原则** | 宁可说"不知道" | 数据不足时标注"灰色地带",不用推测伪装确定性 |
### 4. 金融数据的精确性
LLM心算不可靠。PE算错一个小数点、市值单位搞混港币和人民币,就可能导致错误的投资决策。
**真实案例**:分析腾讯时,不同来源的市值数据有"港币亿"和"人民币亿"两种单位。AI Berkshire 的处理方式:
# 市值手算校验:股价 × 总股本,与报告数据对比
python3 tools/financial_rigor.py verify-market-cap \
--price 510 --shares 9.11e9 --reported 4.65e12 --currency HKD
# ✅ 验证通过, 偏差仅 0.08%
所有计算使用 Python `decimal.Decimal`(精确十进制),不用 `float`。关键数据至少2个独立来源交叉验证。
### 5. 可复现的研究流程
直接问AI,每次输出的格式、深度、覆盖面都不一样——今天分析腾讯有护城河评分,明天分析美团可能就忘了。
AI Berkshire 确保:**同样的输入 → 结构一致、深度一致的输出**。这意味着你可以:
- 7家公司横向对比,评分标准完全一致
- 同一家公司半年后重新分析,直接对比变化
- 团队成员之间的研究结果可以对齐
### 6. 多Agent并行 = 研究深度的倍增
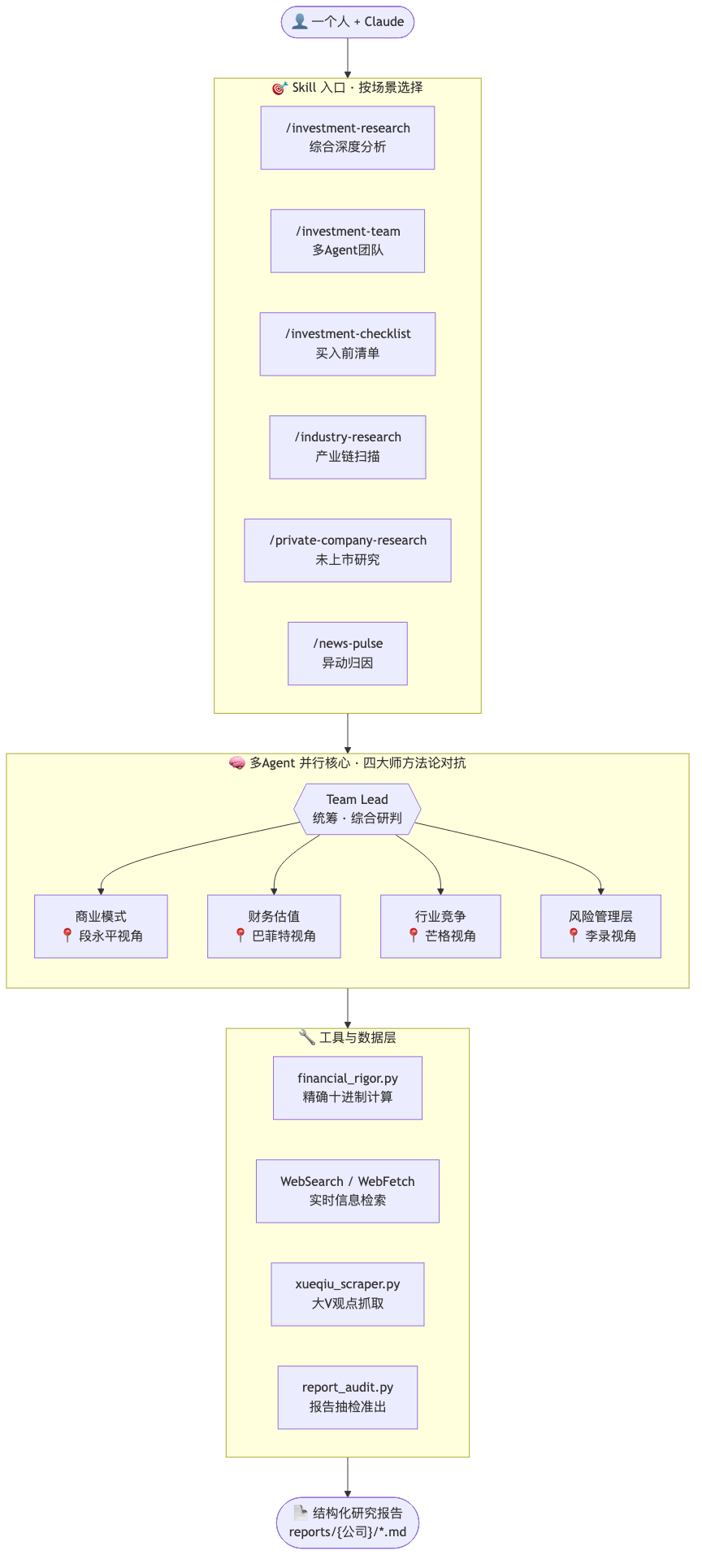
`/investment-team` 启动4个独立Agent**同时**研究一家公司。每个Agent各自搜索网络、交叉验证数据、独立给出结论。这不是把一个prompt拆成四段——是4个"分析师"各自做了完整的研究,Team Lead再综合。
一个人直接问AI,上下文窗口是一个。4个Agent并行,等于4倍的搜索量、4倍的信息源、4个独立视角。
┌─────────────────────────────────────────────┐
│ Team Lead (你) │
│ 统筹协调 · 汇总研判 │
├──────┬──────┬──────────┬───────────┤
│ Agent 1 │ Agent 2 │ Agent 3 │ Agent 4 │
│ 商业模式 │ 财务估值 │ 行业竞争 │ 风险管理层 │
│ 段永平视角 │ 巴菲特视角 │ 芒格视角 │ 李录视角 │
└──────┴──────┴──────────┴───────────┘
↓ 并行研究,实时汇报进度 ↓
最终综合报告
### 一句话总结
## 整体架构
### 与主要指数对比
| 指标 | 2024 全年 | 2025 至今 |
|------|----------|----------|
| **本框架实盘** | **+69.29%** | **+66.38%** |
| 恒生指数 | +17.67% | +27.77% |
| 标普500 | +23.31% | +16.39% |
| 沪深300 | +14.68% | +17.66% |
| 纳斯达克 | +28.64% | +20.36% |
**2024 年超额收益**:跑赢标普500 **46个百分点**,跑赢恒生指数 **52个百分点**
**2025 年超额收益**:跑赢标普500 **50个百分点**,跑赢恒生指数 **39个百分点**
**两年累计实盘收益超 146万元**,连续两年大幅跑赢全球主要指数。
## 为什么不能直接问 AI?
你当然可以直接问 Claude:"帮我分析拼多多值不值得买"。你会得到一篇"一方面...另一方面..."的平衡分析,最后以"投资有风险,请自行判断"收尾。
**这种分析看起来对,但没法拿来做决策。**
AI Berkshire 解决的不是"能不能分析"的问题,而是**分析质量和决策纪律**的问题。以下是核心差异:
### 1. 强制给结论,不打太极
直接问AI,你得到的是两面讨好的"分析"。AI Berkshire 强制输出:**通过/不通过/灰色地带**,带具体价格区间和分层建议。
### 2. 四大师视角对抗,而非单一分析
不是"用巴菲特方法分析一下"这么简单。四个视角会产生**真实的矛盾和张力**——
以拼多多为例:
- **段永平**(商业模式):好生意,C2M模式难以复制 → 评分 3.7/5
- **巴菲特**(财务估值):扣现金PE仅6.3x,印钞机 → 评分 4.4/5
- **芒格**(逆向思考):护城河比想象中浅,抖音3年做到4万亿GMV → 评分 3.5/5
- **李录**(长期确定性):管理层文化有隐患,10年后不确定 → 评分 2.0/5
**巴菲特说"真便宜",李录说"不确定就不买"**——这种冲突才是投资决策的真实状态。单一prompt无法制造这种多视角对抗,而这恰恰是避免盲点的关键。
### 3. 结构化反偏见机制
AI最危险的不是给错答案,而是给一个**看起来很对但经不起推敲**的答案。AI Berkshire 在流程中内置了多层"防骗"机制:
| 机制 | 解决什么问题 | 举例 |
|------|------------|------|
| **信息丰富度评级(A/B/C)** | 防止"资料多=确定性高"的幻觉 | 泡泡玛特评为B级:数据有限,推算指标标注置信度 |
| **芒格式逆向检验** | 强制思考失败场景 | "什么情况下拼多多会死?"→ 列出5大情景及概率 |
| **快速否决清单** | 8条红线一票否决 | 管理层诚信污点 → 直接否决,不管估值多便宜 |
| **反共识检查** | 避免和市场想法一样 | "聪明人为什么在做空?"→ 发现被忽视的风险 |
| **留白原则** | 宁可说"不知道" | 数据不足时标注"灰色地带",不用推测伪装确定性 |
### 4. 金融数据的精确性
LLM心算不可靠。PE算错一个小数点、市值单位搞混港币和人民币,就可能导致错误的投资决策。
**真实案例**:分析腾讯时,不同来源的市值数据有"港币亿"和"人民币亿"两种单位。AI Berkshire 的处理方式:
# 市值手算校验:股价 × 总股本,与报告数据对比
python3 tools/financial_rigor.py verify-market-cap \
--price 510 --shares 9.11e9 --reported 4.65e12 --currency HKD
# ✅ 验证通过, 偏差仅 0.08%
所有计算使用 Python `decimal.Decimal`(精确十进制),不用 `float`。关键数据至少2个独立来源交叉验证。
### 5. 可复现的研究流程
直接问AI,每次输出的格式、深度、覆盖面都不一样——今天分析腾讯有护城河评分,明天分析美团可能就忘了。
AI Berkshire 确保:**同样的输入 → 结构一致、深度一致的输出**。这意味着你可以:
- 7家公司横向对比,评分标准完全一致
- 同一家公司半年后重新分析,直接对比变化
- 团队成员之间的研究结果可以对齐
### 6. 多Agent并行 = 研究深度的倍增
`/investment-team` 启动4个独立Agent**同时**研究一家公司。每个Agent各自搜索网络、交叉验证数据、独立给出结论。这不是把一个prompt拆成四段——是4个"分析师"各自做了完整的研究,Team Lead再综合。
一个人直接问AI,上下文窗口是一个。4个Agent并行,等于4倍的搜索量、4倍的信息源、4个独立视角。
┌─────────────────────────────────────────────┐
│ Team Lead (你) │
│ 统筹协调 · 汇总研判 │
├──────┬──────┬──────────┬───────────┤
│ Agent 1 │ Agent 2 │ Agent 3 │ Agent 4 │
│ 商业模式 │ 财务估值 │ 行业竞争 │ 风险管理层 │
│ 段永平视角 │ 巴菲特视角 │ 芒格视角 │ 李录视角 │
└──────┴──────┴──────────┴───────────┘
↓ 并行研究,实时汇报进度 ↓
最终综合报告
### 一句话总结
## 整体架构
### 2025 年至今收益:+66.38%
### 与主要指数对比
| 指标 | 2024 全年 | 2025 至今 |
|------|----------|----------|
| **本框架实盘** | **+69.29%** | **+66.38%** |
| 恒生指数 | +17.67% | +27.77% |
| 标普500 | +23.31% | +16.39% |
| 沪深300 | +14.68% | +17.66% |
| 纳斯达克 | +28.64% | +20.36% |
**2024 年超额收益**:跑赢标普500 **46个百分点**,跑赢恒生指数 **52个百分点**
**2025 年超额收益**:跑赢标普500 **50个百分点**,跑赢恒生指数 **39个百分点**
**两年累计实盘收益超 146万元**,连续两年大幅跑赢全球主要指数。
## 为什么不能直接问 AI?
你当然可以直接问 Claude:"帮我分析拼多多值不值得买"。你会得到一篇"一方面...另一方面..."的平衡分析,最后以"投资有风险,请自行判断"收尾。
**这种分析看起来对,但没法拿来做决策。**
AI Berkshire 解决的不是"能不能分析"的问题,而是**分析质量和决策纪律**的问题。以下是核心差异:
### 1. 强制给结论,不打太极
直接问AI,你得到的是两面讨好的"分析"。AI Berkshire 强制输出:**通过/不通过/灰色地带**,带具体价格区间和分层建议。
### 2. 四大师视角对抗,而非单一分析
不是"用巴菲特方法分析一下"这么简单。四个视角会产生**真实的矛盾和张力**——
以拼多多为例:
- **段永平**(商业模式):好生意,C2M模式难以复制 → 评分 3.7/5
- **巴菲特**(财务估值):扣现金PE仅6.3x,印钞机 → 评分 4.4/5
- **芒格**(逆向思考):护城河比想象中浅,抖音3年做到4万亿GMV → 评分 3.5/5
- **李录**(长期确定性):管理层文化有隐患,10年后不确定 → 评分 2.0/5
**巴菲特说"真便宜",李录说"不确定就不买"**——这种冲突才是投资决策的真实状态。单一prompt无法制造这种多视角对抗,而这恰恰是避免盲点的关键。
### 3. 结构化反偏见机制
AI最危险的不是给错答案,而是给一个**看起来很对但经不起推敲**的答案。AI Berkshire 在流程中内置了多层"防骗"机制:
| 机制 | 解决什么问题 | 举例 |
|------|------------|------|
| **信息丰富度评级(A/B/C)** | 防止"资料多=确定性高"的幻觉 | 泡泡玛特评为B级:数据有限,推算指标标注置信度 |
| **芒格式逆向检验** | 强制思考失败场景 | "什么情况下拼多多会死?"→ 列出5大情景及概率 |
| **快速否决清单** | 8条红线一票否决 | 管理层诚信污点 → 直接否决,不管估值多便宜 |
| **反共识检查** | 避免和市场想法一样 | "聪明人为什么在做空?"→ 发现被忽视的风险 |
| **留白原则** | 宁可说"不知道" | 数据不足时标注"灰色地带",不用推测伪装确定性 |
### 4. 金融数据的精确性
LLM心算不可靠。PE算错一个小数点、市值单位搞混港币和人民币,就可能导致错误的投资决策。
**真实案例**:分析腾讯时,不同来源的市值数据有"港币亿"和"人民币亿"两种单位。AI Berkshire 的处理方式:
# 市值手算校验:股价 × 总股本,与报告数据对比
python3 tools/financial_rigor.py verify-market-cap \
--price 510 --shares 9.11e9 --reported 4.65e12 --currency HKD
# ✅ 验证通过, 偏差仅 0.08%
所有计算使用 Python `decimal.Decimal`(精确十进制),不用 `float`。关键数据至少2个独立来源交叉验证。
### 5. 可复现的研究流程
直接问AI,每次输出的格式、深度、覆盖面都不一样——今天分析腾讯有护城河评分,明天分析美团可能就忘了。
AI Berkshire 确保:**同样的输入 → 结构一致、深度一致的输出**。这意味着你可以:
- 7家公司横向对比,评分标准完全一致
- 同一家公司半年后重新分析,直接对比变化
- 团队成员之间的研究结果可以对齐
### 6. 多Agent并行 = 研究深度的倍增
`/investment-team` 启动4个独立Agent**同时**研究一家公司。每个Agent各自搜索网络、交叉验证数据、独立给出结论。这不是把一个prompt拆成四段——是4个"分析师"各自做了完整的研究,Team Lead再综合。
一个人直接问AI,上下文窗口是一个。4个Agent并行,等于4倍的搜索量、4倍的信息源、4个独立视角。
┌─────────────────────────────────────────────┐
│ Team Lead (你) │
│ 统筹协调 · 汇总研判 │
├──────┬──────┬──────────┬───────────┤
│ Agent 1 │ Agent 2 │ Agent 3 │ Agent 4 │
│ 商业模式 │ 财务估值 │ 行业竞争 │ 风险管理层 │
│ 段永平视角 │ 巴菲特视角 │ 芒格视角 │ 李录视角 │
└──────┴──────┴──────────┴───────────┘
↓ 并行研究,实时汇报进度 ↓
最终综合报告
### 一句话总结
## 整体架构
标签:Claude Code, PyRIT, 价值投资, 多智能体系统, 逆向工具, 量化投研, 金融科技, 防御加固