Kartvaya2008/fraud-detection-ml-accredian
GitHub: Kartvaya2008/fraud-detection-ml-accredian
这是一个基于PaySim大数据集,利用XGBoost模型和特征工程技术,端到端地检测移动支付欺诈并评估业务影响的机器学习项目。
Stars: 2 | Forks: 0
# 金融欺诈检测
**Accredian 数据科学与机器学习实习项目**
## 关于项目
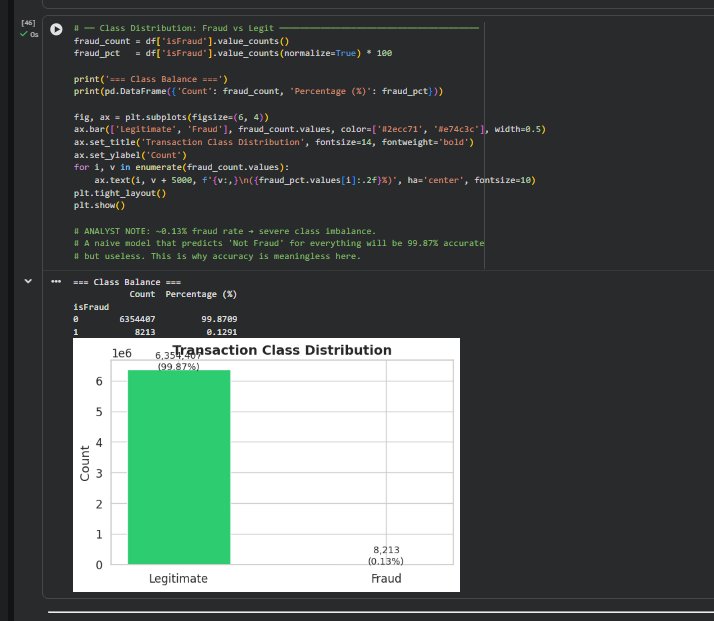
本项目构建了一个机器学习流水线,用于在大约 630 万条记录的数据集上检测欺诈性的移动支付交易。目标不是最大化准确率——一个将所有交易都判定为合法的模型已经可以达到 99.87% 的准确率,但完全无用。真正的目标是在资金离开系统之前捕获欺诈,这意味着要优化召回率(recall),同时将误报控制在可管理的范围内。
该数据集基于 PaySim,这是一个模拟真实移动支付行为(类似 M-Pesa 或 PayTM)的金融交易模拟器。在此数据集中,欺诈仅出现在两种交易类型中:TRANSFER 和 CASH_OUT。这唯一的观察结果几乎决定了本 Notebook 中做出的每一个决策。
## 截图
### 数据加载与初览
### 类别分布
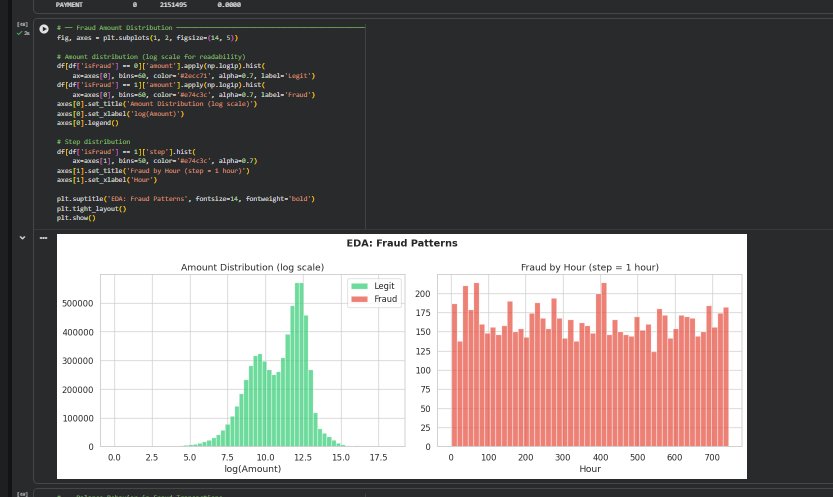
### 欺诈模式 (EDA)
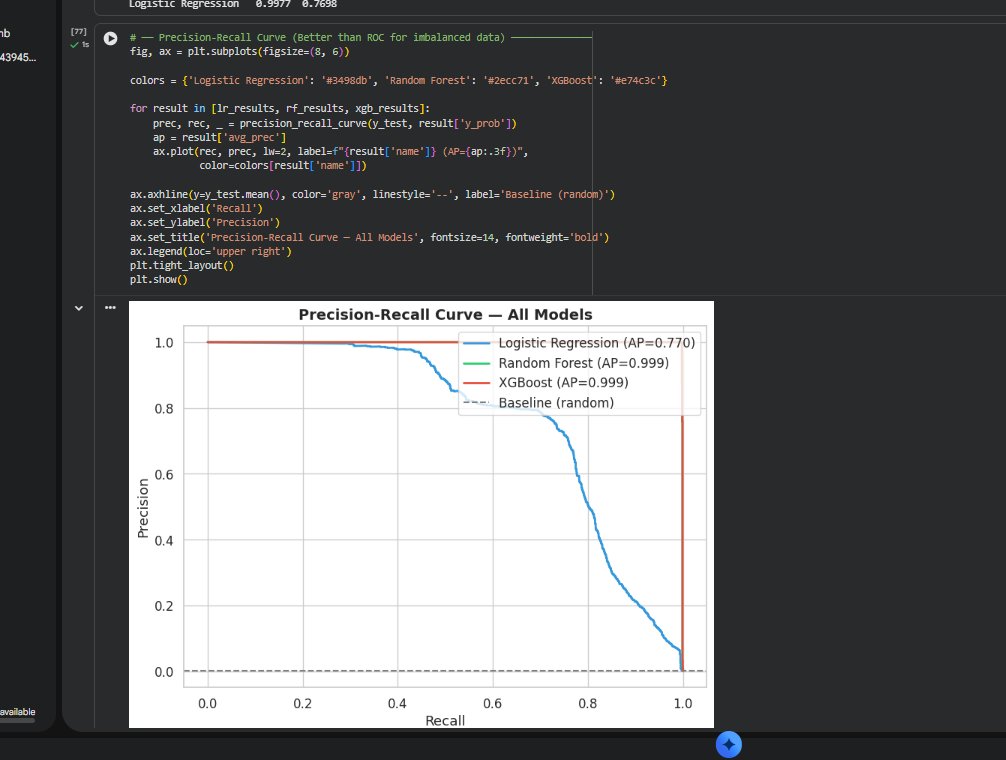
### 精确率-召回率曲线 — 所有模型
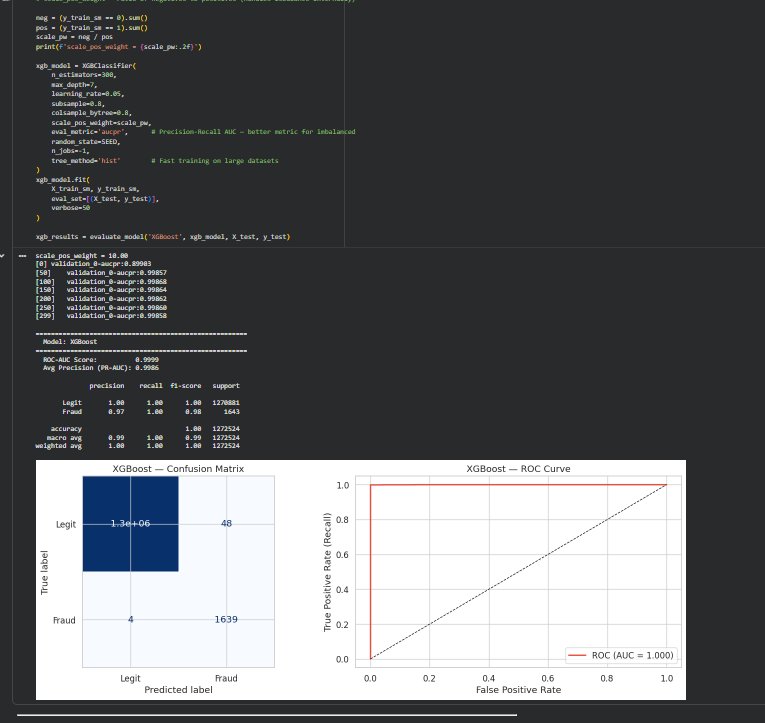
### XGBoost 结果
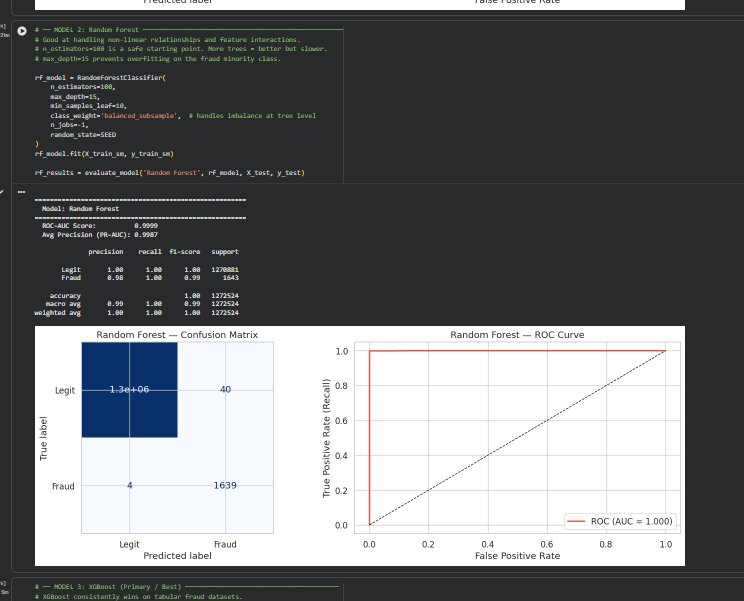
### 随机森林结果
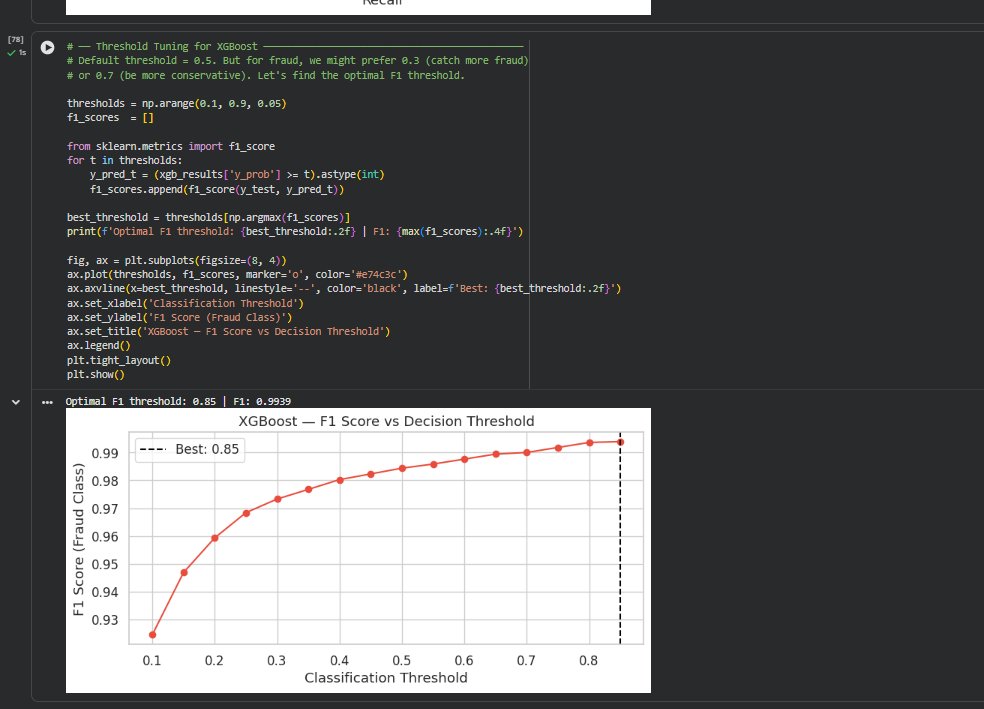
### 阈值调优
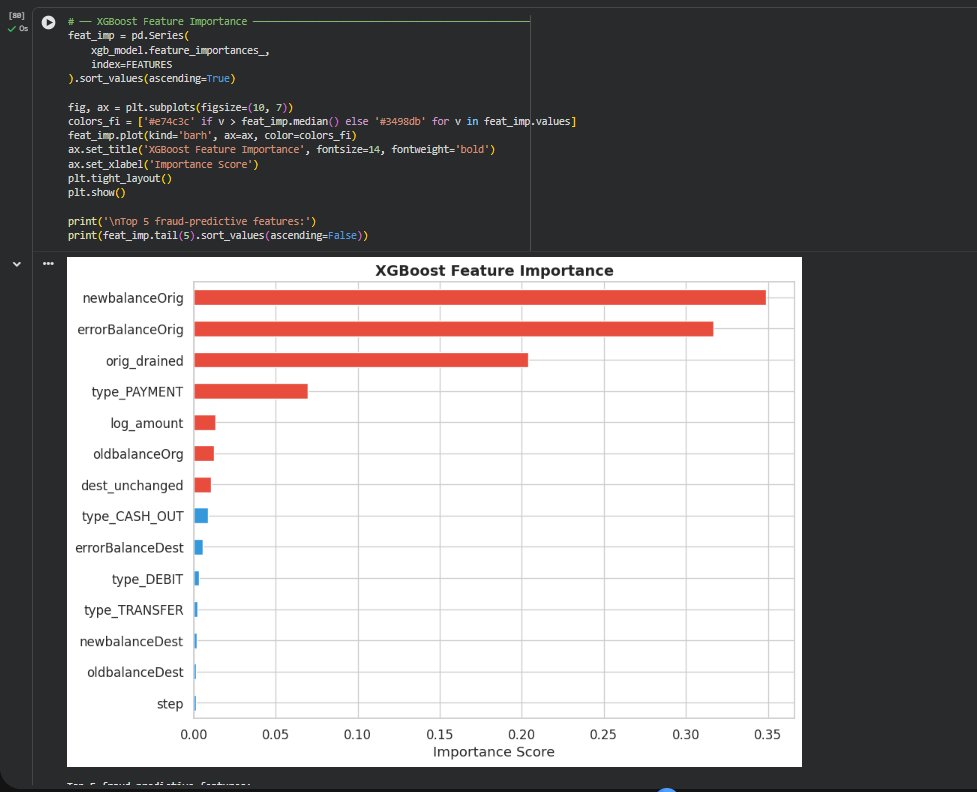
### 特征重要性
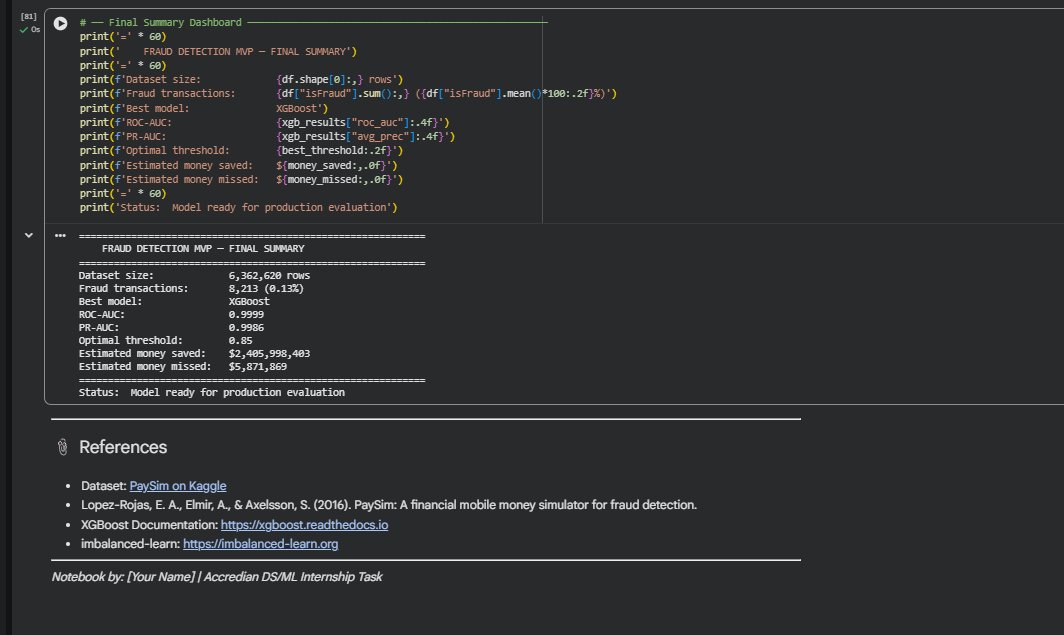
### 最终摘要仪表板
## Notebook 内容
本 Notebook 详细介绍了从原始数据到生产就绪模型的完整流水线,并附带了每一个决策的推理过程:
**问题定义** —— 理解欺诈给业务带来的成本,为什么准确率是错误的指标,以及误报和漏报在实际操作中真正的权衡关系。
**探索性分析** —— 按交易类型统计的欺诈率、金额分布,以及账户清空行为,这被证明是数据中最强的信号之一。
**数据清洗** —— 处理缺失值,剔除低信号列,并为逻辑回归稳定性限制极端异常值(而不完全移除它们,因为异常值本身就是欺诈检测中的信号)。
**特征工程** —— 构建余额误差特征以捕获交易记账中的不一致性,账户清空标志,目标账户余额变化标志,以及对数转换后的金额。
**多重共线性检查** —— VIF 分析显示原始余额列高度相关。工程化后的差值特征将取代它们。
**建模** —— 对比了三个模型:作为基准的逻辑回归、随机森林和 XGBoost。仅对训练数据应用 SMOTE 来处理类别不平衡。
**评估** —— 以 ROC-AUC 和 PR-AUC 为主要指标,并通过阈值调整寻找在欺诈类别上最大化 F1 分数的最佳操作点。
**业务影响估算** —— 将模型性能转化为挽回的金额和错过的金额,以及误报的成本。
**建议** —— 部署模型的具体步骤,在其之上叠加基于规则的拦截层,以及部署后衡量其效果的方法。
## 结果
| 模型 | ROC-AUC | PR-AUC |
|---|---|---|
| 逻辑回归 | 0.9977 | 0.770 |
| 随机森林 | 0.9999 | 0.9987 |
| XGBoost | 0.9999 | 0.9986 |
XGBoost 被选为最终模型。在 0.85 的最佳阈值下,它捕获了绝大多数欺诈行为,且误报极少。最重要的预测特征是 newbalanceOrig、errorBalanceOrig 和 orig_drained —— 所有这些都直接对应真实的犯罪行为:快速清空账户、转移资金,并在任何人察觉之前提现。
在测试集上估算的业务影响:挽回 $2,405,998,403,漏损 $5,871,869。
## 技术栈
- Python 3.12
- pandas, numpy
- scikit-learn
- XGBoost
- imbalanced-learn (SMOTE)
- statsmodels (VIF)
- matplotlib, seaborn
## 数据集
PaySim —— 可在 Kaggle 上获取:
https://www.kaggle.com/datasets/ealaxi/paysim1
由于文件大小(约 470 MB),CSV 文件未包含在此仓库中。请从 Kaggle 下载并将其放在项目根目录下,然后再运行 Notebook。
## 如何运行
1. 克隆仓库
2. 安装依赖:`pip install -r requirements.txt`
3. 从 Kaggle 下载 PaySim 数据集并将其放在项目根目录下
4. 在 Jupyter 或 Google Colab 中打开 `Fraud_Detection.ipynb`
5. 按顺序运行所有单元格
本 Notebook 设计为易于理解。每一个非显而易见的决策都附有解释其背后原因的注释。
## 已知问题与修复方法
在开发过程中出现了一些值得记录的问题:
VIF 计算需要一个干净的数值矩阵。在特征工程过程中,余额列可能会产生 inf 值,这是 statsmodels 无法处理的。修复方法是将 inf 替换为 NaN,并在计算 VIF 之前删除这些行 —— 这直接应用于临时的 VIF 数据框,而不是主数据集。
如果目标列包含 NaN,训练-测试拆分将失败并报 ValueError。如果特征工程中引入了 inf 值且未及早捕获,就会发生这种情况。修复方法是在定义 X 和 y 之前清理 df_clean —— 替换 inf,删除目标列中包含 NaN 的行,并用零填充特征列中剩余的 NaN。
在较新版本的 imbalanced-learn 中,SMOTE 的 n_jobs 参数已被移除。如果遇到 TypeError,请从 SMOTE 构造函数中删除它。
## 作者
Kartavya Raikwar
邮箱:kartvayaraikwar@gmail.com
作品集:
https://kartvaya2008.github.io/portfolio_website-/
LinkedIn:
https://www.linkedin.com/in/kartavya-raikwar-4940013a3
标签:Apex, PaySim数据集, XGBoost, 不平衡数据, 业务洞察, 分类算法, 反欺诈, 异常检测, 数据清洗, 数据科学, 机器学习, 模型调优, 特征工程, 移动支付, 端到端项目, 精准率与召回率, 资源验证, 资金转移, 逆向工具, 金融科技, 阈值调整, 随机森林, 风控系统