### Agent 记忆,人类创新。
[](https://www.npmjs.com/package/@tencentdb-agent-memory/memory-tencentdb)
[](./LICENSE)
[](https://nodejs.org/)
[](https://github.com/openclaw/openclaw)
[](https://hermes-agent.nousresearch.com/docs/)
[](https://discord.gg/kDtHb5RW2)
[亮点](#-highlights) · [概述](#overview) · [核心技术](#core-technology-reject-flat-storage-embrace-layering-and-symbolization) · [功能](#-features) · [快速开始](#quick-start)
[**English**](./README.md) · [简体中文](./README_CN.md)
## ✨ 亮点
与 OpenClaw 集成时,它最多可减少 **61.38%** 的 token 使用量,将 pass rate(相对)提高 **51.52%**,并将 PersonaMem 准确率从 **48%** 提升至 **76%**。
| 记忆能力 | 基准测试 | OpenClaw 成功率 | 使用本插件 | 相对变化 (Δ) | OpenClaw Tokens | 使用本插件 Tokens | 相对变化 (Δ) |
| :--- | :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| **短期** | WideSearch | 33% | **50%** | **+51.52%** | 221.31M | **85.64M** | **−61.38%** |
| **短期** | SWE-bench | 58.4% | **64.2%** | **+9.93%** | 3474.1M | **2375.4M** | **−33.09%** |
| **短期** | AA-LCR | 44.0% | **47.5%** | **+7.95%** | 112.0M | **77.3M** | **−30.98%** |
| **长期** | PersonaMem | 48% | **76%** | **+59%** | — | — | — |
## 概述
**记忆不是为了在 AI 中囤积一切——而是为了让人类免于不断重复自己。**
在实践中,我们不断向 Agent 重新解释相同的 SOP、项目背景、工具约定和输出格式。这类信息不应需要重复,也不应被不加区分地全盘倾倒进上下文中。
TencentDB Agent Memory 帮助 Agent 学习您的工作流、保留任务上下文并复用过往经验。我们既拒绝暴力的历史累积,也拒绝不可逆的有损摘要。相反,我们将记忆设计为一个分层系统:用于任务内信息超载的**符号记忆 (symbolic memory)**,以及用于跨会话经验的**记忆分层 (memory layering)**。
## 核心技术:拒绝扁平化存储,拥抱分层与符号化
我们的架构建立在两大支柱之上:**记忆分层**和**符号记忆**。它们共同确保 Agent 不仅是“记住得更多”,而是“推理得更好”。
### 1. 记忆分层:异构存储与渐进式披露
传统记忆系统将数据切碎成片段并倾倒进扁平的向量库中。召回退化成了在互不相连的碎片间进行盲搜,毫无宏观层面的指引。
无论是长期知识、短期任务还是未来的技能能力,记忆都不应是扁平的——它的形成和召回都必须是分层的。TencentDB Agent Memory 采用**分层**作为其统一的架构范式:
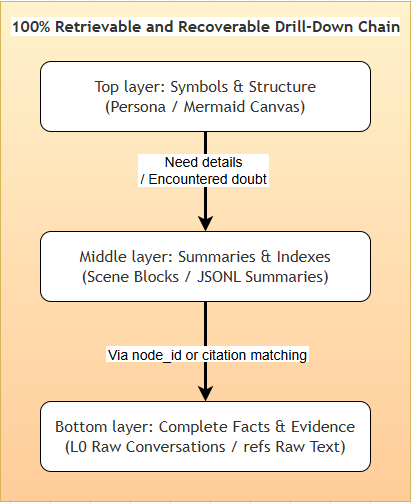
* **短期上下文分层。** 底层归档原始的工具输出 (`refs/*.md`);中层提取步骤级摘要 (`jsonl`);顶层将状态浓缩为轻量级的 Mermaid 画布。Agent 在上下文中只需关注顶层的结构,当出现错误时再通过 `node_id` 深入底层。
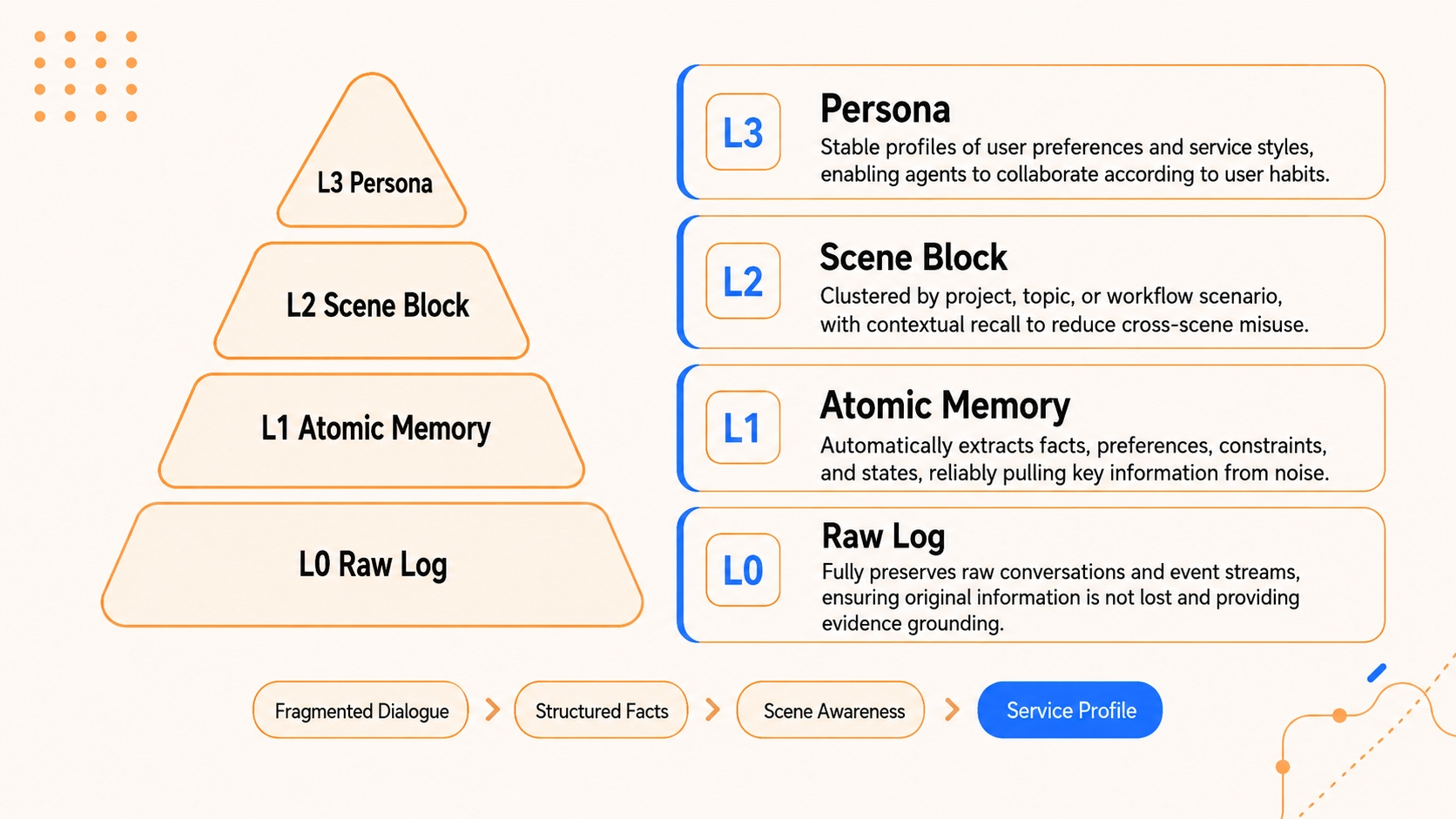
* **长期个性化分层。** 取代扁平日志的,是我们构建的语义金字塔:**L0 Conversation**(原始对话)→ **L1 Atom**(原子事实)→ **L2 Scenario**(场景块)→ **L3 Persona**(用户画像)。Persona 层承载日常偏好;系统仅在需要细节时下钻至 Atoms 层。
* **技能生成分层。** 分层同样适用于动作。中层从底层的执行轨迹 (**Conversation**) 中提取常见的解决方案模式 (**Scenario**),而顶层则提炼出可复用的 Skills 或标准 SOP (**Persona**)。
**异构存储与渐进式披露。** 双层存储策略是此架构的基石。底层(事实、日志、轨迹)持久化到数据库中,以实现稳健的全文本检索;顶层(用户画像、场景、画布)以人类可读的 Markdown 文件存储,以实现高信息密度和白盒审查。**底层保留证据;上层保留结构。**
**全链路可追溯与无损恢复。** 压缩通常会牺牲可追溯性。TencentDB Agent Memory 通过维护一条从高层抽象回溯至真相证据的确定性路径,避免了不可逆的压缩。无论是被转移的错误日志还是提炼出的用户偏好,系统都保证了完整的下钻路径:“顶层符号 (Persona / 画布) → 中层索引 (Scenario / jsonl) → 底层原始文本 (L0 Conversation / refs)”。
### 2. 符号记忆:以最少符号承载最大语义 (Mermaid 画布)
在长任务中,消耗 token 最多的就是冗长的中间日志(搜索结果、代码、错误轨迹)。为了解决这个问题,我们将**上下文转移 (context offloading)** 与 **符号记忆** 结合起来:
* **Mermaid 符号图。** 我们使用高密度的 Mermaid 语法对任务状态转移进行编码,而不是冗长的散文或扁平的 JSON——对 LLM 而言足够精确以进行解析,对人类而言也足够简洁以便阅读。
* **历史卸载。** 完整的工具日志被卸载到外部文件中;上下文中只留下一个轻量级的 Mermaid 任务图。
* **`node_id` 追踪。** Agent 在符号图上进行推理;如需验证某个细节,它会 grep 搜索 `node_id` 并立即检索出完整的原始文本——在削减 token 成本的同时保留完整的可追溯性。
```
graph LR
Log["Verbose Logs
(hundreds of thousands of tokens)"] -->|"1. Offload full text"| FS[("External FS
(refs/*.md)")]
Log -->|"2. Extract relations"| MMD["Mermaid Canvas
(with node_id)"]
MMD -->|"3. Light injection"| Agent(("Agent Context
(a few hundred tokens)"))
Agent -. "4. Recall via node_id" .-> FS
style Log fill:#f1f5f9,stroke:#94a3b8,stroke-dasharray: 5 5,color:#475569
style FS fill:#f8fafc,stroke:#cbd5e1,stroke-width:2px,color:#334155
style MMD fill:#eff6ff,stroke:#3b82f6,stroke-width:2px,color:#1e3a8a
style Agent fill:#fffbeb,stroke:#f59e0b,stroke-width:2px,color:#92400e
```
## 快速开始
## 🎬 演示
|
|
|
|
OpenClaw × Agent Memory
|
Hermes × Agent Memory
|
### OpenClaw
### 1.1 安装插件
```
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
openclaw gateway restart
```
### 1.2 零配置启用
默认使用本地 `SQLite + sqlite-vec` 作为后端。
```
// ~/.openclaw/openclaw.json
{
"memory-tencentdb": {
"enabled": true
}
}
```
启用后,TencentDB Agent Memory 会自动处理对话捕获、记忆提取、场景聚合、用户画像生成,并在下一轮对话前进行召回。
### 1.3 启用短期压缩(可选,需要版本 ≥ 0.3.4)
```
{
"memory-tencentdb": {
"config": {
"offload": {
"enabled": true
}
}
}
}
```
#### 步骤 1 — 在您的插件配置中注册 slot
添加 `slots` 字段,以便 OpenClaw 将上下文转移请求路由至此插件:
```
{
"plugins": {
"slots": {
"contextEngine": "memory-tencentdb"
}
}
}
```
#### 步骤 2 — 应用运行时补丁
为获得最佳效果,请运行以下补丁脚本。它会挂钩 `after-tool-call` 消息,以便它们能被正确地转移和恢复:
```
bash scripts/openclaw-after-tool-call-messages.patch.sh
```
### Hermes
除了 OpenClaw,此插件还支持 [Hermes](https://github.com/NousResearch/hermes-agent) Agent。请根据您的部署场景选择安装路径:
| 您想要 … | 使用方式 |
|---|---|
| 通过一条命令从零开始启动一个带记忆功能的 Hermes | 2.A Docker(如下) |
| 为现有的 Hermes 安装添加记忆功能 | 2.B 接入现有的 Hermes(下一节) |
#### 2.A Docker(全新部署,需要版本 ≥ 0.3.4)
Docker 镜像捆绑了 `hermes-agent` 和 `memory_tencentdb` provider。Gateway 监听端口 `:8420`:
```
# ============ 配置参数 ============
# MODEL_API_KEY LLM API key(必填)— 替换为您自己的凭证
# MODEL_BASE_URL LLM endpoint,默认为 Tencent Cloud LKE(Large Model Knowledge Engine)
# MODEL_NAME 模型名称,默认为 DeepSeek-V3.2
# MODEL_PROVIDER Provider 类型:"custom" 适用于任何 OpenAI 兼容的 endpoint
MODEL_API_KEY="your-api-key"
MODEL_BASE_URL="https://api.lkeap.cloud.tencent.com/v1"
MODEL_NAME="deepseek-v3.2"
MODEL_PROVIDER="custom"
# ============ docker run 标志 ============
# -d 在 detached(后台)模式下运行 container
# --name hermes-memory Container 名称,用于后续的 docker exec / logs / stop
# --restart unless-stopped 在崩溃或宿主机重启时自动重启
# -p 8420:8420 宿主机端口 ↔ container 端口(Hermes Gateway)
# -e MODEL_* 将上述配置参数作为 env vars 注入
# -v hermes_data:/opt/data 将 memory 数据持久化到 named volume 中(重启后仍然保留)
# 进入 Docker build 目录(已 clone repo 并位于 repo 根目录)
cd docker/opensource
# Build
docker build -f Dockerfile.hermes -t hermes-memory .
# Run
docker run -d \
--name hermes-memory \
--restart unless-stopped \
-p 8420:8420 \
-e MODEL_API_KEY="your-api-key" \
-e MODEL_BASE_URL="https://api.lkeap.cloud.tencent.com/v1" \
-e MODEL_NAME="deepseek-v3.2" \
-e MODEL_PROVIDER="custom" \
-v hermes_data:/opt/data \
hermes-memory
# 验证 Gateway
curl http://localhost:8420/health
# 进入 Hermes 交互式 shell
docker exec -it hermes-memory hermes
```
#### 2.B 接入现有的 Hermes(无需 Docker)
如果您的主机上已经安装了 `hermes-agent` 并且只想添加记忆功能,**则无需 Docker 镜像**。
**1. 将插件包下载到统一的目录中**:
```
mkdir -p ~/.memory-tencentdb
TEMP_DIR=$(mktemp -d)
cd "$TEMP_DIR"
npm init -y --silent
npm install @tencentdb-agent-memory/memory-tencentdb@latest --omit=dev
cp -r node_modules/@tencentdb-agent-memory/memory-tencentdb \
~/.memory-tencentdb/tdai-memory-openclaw-plugin
rm -rf "$TEMP_DIR"
```
**2. 安装 Gateway 依赖**:
```
cd ~/.memory-tencentdb/tdai-memory-openclaw-plugin
npm install --omit=dev
npm install tsx
```
**3. 链接到 Hermes 插件目录**:
```
rm -rf ~/.hermes/hermes-agent/plugins/memory/memory_tencentdb
ln -sf ~/.memory-tencentdb/tdai-memory-openclaw-plugin/hermes-plugin/memory/memory_tencentdb \
~/.hermes/hermes-agent/plugins/memory/memory_tencentdb
```
**4. 在 `~/.hermes/config.yaml` 中声明 provider**:
```
memory:
provider: memory_tencentdb
```
**5. 配置 Gateway 环境变量**
编辑 `~/.hermes/.env` 并添加:
```
MEMORY_TENCENTDB_GATEWAY_CMD="sh -c 'cd ~/.memory-tencentdb/tdai-memory-openclaw-plugin && exec npx tsx src/gateway/server.ts'"
MEMORY_TENCENTDB_GATEWAY_HOST="127.0.0.1"
MEMORY_TENCENTDB_GATEWAY_PORT="8420"
```
根据需要添加 LLM 凭证(Gateway 实际上会读取 `TDAI_LLM_*` 变量):
```
TDAI_LLM_API_KEY="sk-your-api-key-here"
TDAI_LLM_BASE_URL="https://api.openai.com/v1"
TDAI_LLM_MODEL="gpt-4o"
```
或者,使用位于 `~/.memory-tencentdb/memory-tdai/tdai-gateway.json` 的 Gateway 配置文件:
```
{
"llm": {
"baseUrl": "https://your-api-endpoint/v1",
"apiKey": "your-api-key",
"model": "your-model-name"
}
}
```
**6. 启动 Gateway**(选择两种方法之一):
- **对话时自动发现(推荐,零配置)**:无需手动启动 Gateway——只需开始与 Hermes 对话即可。Provider 会自动检测 `~/.memory-tencentdb/tdai-memory-openclaw-plugin/src/gateway/server.ts`,并在首次对话时通过 `Popen()` 启动它。初次对话可能会有轻微延迟。
- **手动运行**:提前启动一个独立的 Gateway 进程:
cd ~/.memory-tencentdb/tdai-memory-openclaw-plugin
npx tsx src/gateway/server.ts
**7. 验证**:
```
curl http://127.0.0.1:8420/health
# 应返回 {"status":"ok"} 或 {"status":"degraded"}
```
## 🔒 Gateway 安全性(可选)
Hermes Gateway 监听 `:8420` 端口并暴露 capture / search / recall HTTP endpoint。两个可选开关可以让您从“开放的 localhost 边车”转变为“经过身份验证的网络服务”。**两者默认均关闭,因此现有部署将保持不变地继续工作。**
| 字段 | 环境变量 | 默认值 | 描述 |
| :--- | :--- | :--- | :--- |
| `server.apiKey` | `TDAI_GATEWAY_API_KEY` | _(未设置)_ | 设置后,除 `GET /health` 外的每个路由都需要 `Authorization: Bearer
`;缺失或错误的 token 将返回 HTTP 401。比较过程为常量时间。 |
| `server.corsOrigins` | `TDAI_CORS_ORIGINS` (逗号分隔) | `[]` | CORS 白名单。如果列表为空,则**不会**发出 `Access-Control-Allow-*` 标头——浏览器随后将拦截所有跨域请求。仅在本地开发时使用 `["*"]`。 |
如果未设置 `apiKey`,Gateway 会打印一条启动警告 `WARN`。如果它绑定到非回环主机(例如 `0.0.0.0`)且没有 apiKey,则会发出第二条更严厉的警告。
客户端使用 Bearer token 调用受保护的路由:
```
curl -H "Authorization: Bearer $TDAI_GATEWAY_API_KEY" \
-H "Content-Type: application/json" \
-d '{"query":"...","session_key":"..."}' \
http://127.0.0.1:8420/recall
```
`GET /health` 保持无需 token 即可开放访问,因此编排器探测(`docker healthcheck`、`kubectl liveness`)仍能正常工作。
### Hermes 插件端
Hermes 的 `memory_tencentdb` 插件是 Gateway 的**客户端**。要让其与开启了身份验证的 Gateway 通信,请设置:
```
export MEMORY_TENCENTDB_GATEWAY_API_KEY=""
```
然后,插件会在其发送给 Gateway 的每个请求中附加 `Authorization: Bearer `。如果该变量未设置,插件将不发送 auth 标头——这与 Gateway 的旧版默认设置相符,对于未选择开启 `TDAI_GATEWAY_API_KEY` 的 Gateway 来说运行良好。
重要提示:插件仅处理**客户端部分**。Gateway 是否真正执行 Bearer 校验由 Gateway 端(`TDAI_GATEWAY_API_KEY` `server.apiKey`)决定。请在两端配置相同的密钥——插件不会跨进程传播密钥,因为 Gateway 可能由插件控制范围之外的 Docker、systemd 或任何其他方式启动。
如果 `MEMORY_TENCENTDB_GATEWAY_API_KEY` 未设置,插件也会将 `TDAI_GATEWAY_API_KEY` 作为后备方案读取——这非常适用于两个进程共享一个 env 文件且操作员只想设置一个变量名的情况。Gateway 从不读取 `MEMORY_TENCENTDB_GATEWAY_API_KEY`;该名称仅在插件端使用。
## 🔧 可配置参数
**每个字段都有合理的默认值——无需配置即可运行。** 当您需要进行调优时,可根据您的深入程度逐层展开配置。
🟢 Level 1 · 日常调优(覆盖 90% 的使用场景)
| 字段 | 默认值 | 描述 |
| :--- | :--- | :--- |
| `timezone` | `"system"` | 面向用户/LLM 的时间戳时区:`"system"`(遵循进程时区)/ IANA 名称 (`Asia/Shanghai`) / 偏移量字符串 (`+08:00`) |
| `storeBackend` | `"sqlite"` | 存储后端:`sqlite` |
| `recall.strategy` | `"hybrid"` | 召回策略:`keyword` / `embedding` / `hybrid` (RRF 融合,推荐) |
| `recall.maxResults` | `5` | 每次召回返回的条目数 |
| `recall.maxCharsPerMemory` | `0` | 为单次召回的 L1 记忆注入的最大字符数;`0` 表示禁用此防护 |
| `recall.maxTotalRecallChars` | `0` | 自动召回的 L1 记忆的总字符预算;`0` 表示禁用此防护 |
| `pipeline.everyNConversations` | `5` | 每 N 轮触发一次 L1 记忆提取 |
| `extraction.maxMemoriesPerSession` | `20` | 每次 L1 处理提取的最大记忆数 |
| `persona.triggerEveryN` | `50` | 每新增 N 条记忆生成一次用户画像 |
| `offload.enabled` | `false` | 是否启用短期压缩 |
🟡 Level 2 · 高级调优(长任务 / 长会话)
| 字段 | 默认值 | 描述 |
| :--- | :--- | :--- |
| `pipeline.enableWarmup` | `true` | 预热:新会话从第 1 轮开始触发,每次翻倍直到 N (1→2→4→…) |
| `pipeline.l1IdleTimeoutSeconds` | `600` | 用户空闲多少秒后触发 L1 |
| `pipeline.l2MinIntervalSeconds` | `900` | 同一会话内两次 L2 处理之间的最小间隔 |
| `recall.timeoutMs` | `5000` | 召回超时时间;超时发生时跳过注入而不阻塞对话 |
| `extraction.enableDedup` | `true` | L1 向量去重 / 冲突检测 |
| `capture.excludeAgents` | `[]` | 用于排除特定 Agent 的 Glob 匹配模式(例如 `bench-judge-*`) |
| `capture.l0l1RetentionDays` | `0` | L0 / L1 文件的本地保留天数;`0` = 永不清理 |
| `offload.mildOffloadRatio` | `0.5` | 轻度压缩触发比例(占上下文窗口的比例) |
| `offload.aggressiveCompressRatio` | `0.85` | 激进压缩触发比例 |
| `offload.mmdMaxTokenRatio` | `0.2` | MMD 注入的 token 预算比例 |
| `bm25.language` | `"zh"` | 分词器语言:`zh` (jieba) / `en` |
🔴 Level 3 · 完整参数参考(运维 / 自定义模型 / 远程 embedding)
有关所有字段、类型和约束,请参见 [`openclaw.plugin.json`](./openclaw.plugin.json)。
- `embedding.*` — 远程 embedding 服务(兼容 OpenAI 的 API)
- `embedding.sendDimensions` (默认 `true`):是否在请求体中包含 `dimensions` 字段。OpenAI 的 `text-embedding-3-*` 模型依赖它进行 Matryoshka 截断,但一些自托管 / 开源模型(例如 **BGE-M3**)不支持自定义维度,并会以 HTTP 400 `does not support matryoshka representation` 拒绝请求。对于这些后端,请将其设置为 `false`,例如:
{
"embedding": {
"enabled": true,
"provider": "openai",
"baseUrl": "http://your-host:your-port/v1",
"apiKey": "",
"model": "bge-m3",
"dimensions": 1024,
"sendDimensions": false
}
}
- `llm.*` — 独立 LLM 模式(绕过 OpenClaw 的内置模型,并使用指定的 API 运行 L1/L2/L3)
- `offload.backendUrl / backendApiKey` — 将 L1/L1.5/L2/L4 流程转移到后端服务
- `report.*` — 指标报告
## 🤔 功能
### 1. 宏观画像 + 微观事实:统一的下钻机制
压缩中最大的风险就是以丢失证据为代价来节省 token。因此,TencentDB Agent Memory 不会将历史折叠成不可逆的摘要——它保留了从高层抽象回溯至真相证据的清晰路径。
| 问题类型 | 首先查看 | 下钻至 |
| :--- | :--- | :--- |
| 日常偏好、语气、长期目标 | L3 Persona / L2 Scenario | 需要事实时查看 L1 Atom / L0 Conversation |
| 具体事实、日期、项目细节 | L1 Atom / L0 Conversation | 扩大时间范围,或在结果稀疏时回退至语义召回 |
| 继续长时间运行的任务 | 活动的 Mermaid 任务画布 | 摘要缺乏细节时检查 JSONL,然后查看 `refs/*.md` 获取原始文本 |
| 恢复历史任务 | 元数据任务条目 | 打开 Mermaid 画布 → 定位 `node_id` → 追踪 `result_ref` |
上层承载判断和方向;下层承载证据和精度。短期压缩和长期记忆形成了一个单一的闭环:**可折叠和可展开,抽象且可审计。**
### 2. 白盒可调试性:记忆不是黑盒
大多数记忆系统都在这一点上显得不足:当召回出错时,您看到的只是一个向量分数列表,根本无法分辨哪里出了问题。TencentDB Agent Memory 将关键的中间产物保留为人类可读的文件:
- L2 Scenario 块是纯 Markdown——直接打开检查即可。
- L3 Persona 存在于 `persona.md` 中,并且可以追溯到生成它的 Scenario。
- 短期任务画布是 Mermaid 格式——人类和 Agent 均可读取。
- 原始 payload、摘要和节点通过 `result_ref` 和 `node_id` 链接。
调试不再意味着探测不透明的数据库——它变成了一次沿着“Persona → Scenario → Atom → Conversation”链条进行的确定性遍历,直到根本原因浮出水面。
**所有这些分层记忆的产出物都位于 `~/.openclaw/memory-tdai/` 目录下——请随意打开该目录并亲自检查每一层。**
### 3. 生产级工程:并非演示品
| 能力 | 描述 |
| :--- | :--- |
| OpenClaw 插件 | 安装后自动捕获、提取和召回记忆 |
| Hermes Gateway 适配器 | `TdaiCore + HostAdapter`,与宿主框架解耦 |
| 本地后端 | `SQLite + sqlite-vec`,开箱即用 |
| 混合检索 | BM25 + vector + RRF——同时支持关键字和语义召回 |
| Agent 工具 | `tdai_memory_search` / `tdai_conversation_search` |
## 文档
| 文档 | 内容 |
| :--- | :--- |
| [`scripts/README.memory-tencentdb-ctl.md`](./scripts/README.memory-tencentdb-ctl.md) | 运维与管理工具 |
| [`CHANGELOG.md`](./CHANGELOG.md) | 发布说明与版本历史 |
| [`openclaw.plugin.json`](./openclaw.plugin.json) | OpenClaw 插件清单与配置 schema |
## 社区与贡献
我们欢迎任何形式的贡献——bug 报告、功能想法、文档修复、基准测试复现、生态集成或 Pull Request。Agent 记忆远未达到完美解决的程度,我们很乐意与您一起探索。
- 🐞 **发现 bug 或有问题?** 在 [GitHub Issues](https://github.com/Tencent/TencentDB-Agent-Memory/issues) 中提issue——我们将在 24 小时内回复。
- 💡 **有想法要分享?** 在 [GitHub Discussions](https://github.com/Tencent/TencentDB-Agent-Memory/discussions) 中发起讨论。
- 🛠️ **想要贡献代码?** 请先阅读 [CONTRIBUTING.md](./CONTRIBUTING.md)。
- 💬 **想与我们交流?** 加入我们的 [Discord 社区](https://discord.gg/kDtHb5RW2),直接与早期开发者对话。
## 路线图
- [x] 长期个性化记忆 (L0 → L3)
- [x] 短期上下文压缩 (Context Offload + Mermaid 画布)
- [x] 本地 SQLite 后端与腾讯云向量数据库 (TCVDB) 后端
- [x] OpenClaw 插件与 Hermes Gateway 集成
- [ ] 可移植记忆:跨 Agent / 跨框架 / 跨设备的导入、导出与实时迁移
- [ ] 自动 Skill 生成
- [ ] 可视化调试与记忆可观测性仪表板
If TencentDB Agent Memory has been useful to you, please give the project a ⭐ to support us.
For any suggestions, feel free to open an issue and start the discussion.
|

|
[MIT](./LICENSE) © TencentDB Agent Memory Team