shekh-2810/VIGIL
GitHub: shekh-2810/VIGIL
Vigil 是一款结合了自定义 XGBoost 机器学习模型与 DOM 实时分析的 Chrome 扩展,旨在通过多维特征检测识别钓鱼网站并拦截凭据窃取。
Stars: 0 | Forks: 0
# 🛡️ Vigil — AI 驱动的网络钓鱼检测
**由 ZeroDay Legends · VIT Bhopal · NextGen 2026 构建**
## 预览
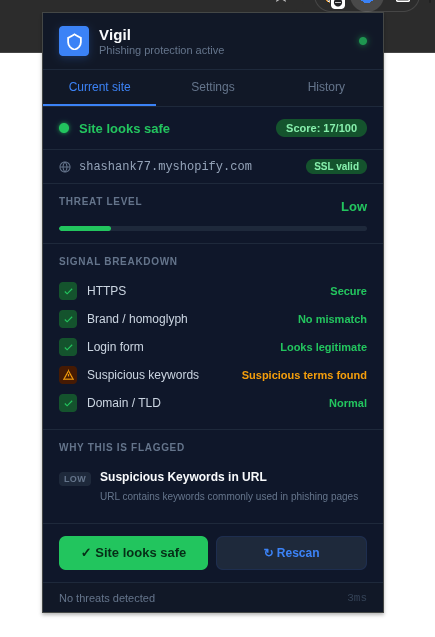 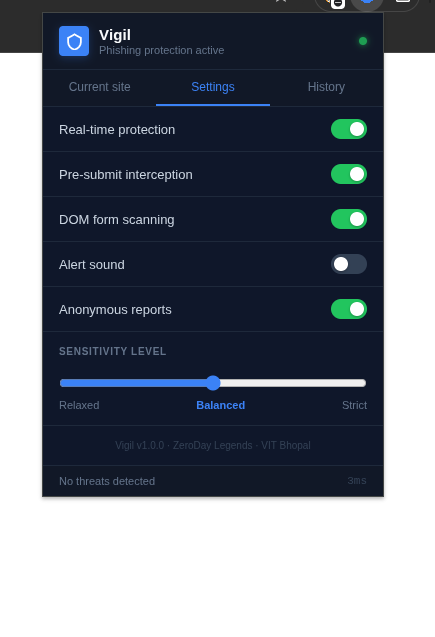
## 工作原理
```
Browser Tab
│
▼
content.js — extracts 14 DOM signals from the live page
│ (chrome.runtime.sendMessage)
▼
background.js — service worker proxies the API call to bypass
│ Chrome's Private Network Access restriction
▼
FastAPI /analyze — extracts 50 features from URL + DOM
│
▼
XGBoost Model — outputs probability 0.0 → 1.0
│
▼
Popup UI — threat score, signal breakdown, flags, history
```
1. 当您访问任何页面时,content script 会提取 **14 个 DOM 信号** —— 登录表单、隐藏输入、混淆 JS、favicon 不匹配、表单 action 域名不匹配等
2. 后台 service worker 将请求代理到 FastAPI 后端(由于 Chrome 的 Private Network Access 策略,这是必要的 —— 更多信息请参阅“开发中遇到的问题”)
3. 后端从 URL 结构、SSL 证书和 DOM 内容中提取 **50 个特征**
4. XGBoost 输出 **0–100 的威胁评分**,并提供人类可读的标记,解释页面可疑的确切原因
5. 如果评分超过 60,表单提交将被**拦截**,并在任何凭据离开浏览器之前通过警告模态框阻止用户
## 🏗️ 项目结构
```
vigil/
├── README.md
├── railway.json # Railway deployment config
│
├── backend/
│ ├── app.py # FastAPI server + threat flag generator
│ ├── features.py # 50-feature extractor (URL + SSL + DOM)
│ ├── build_dataset_v3.py # Synthetic dataset builder (10k samples)
│ ├── train_model.py # XGBoost trainer with early stopping
│ ├── requirements.txt
│ ├── Dockerfile
│ └── model/
│ ├── vigil_model.json # Trained XGBoost model
│ ├── scaler.pkl # StandardScaler for feature normalization
│ └── model_meta.json # Metrics, feature names, top features
│
└── extension/
├── manifest.json # Chrome MV3 manifest
├── background.js # Service worker — API proxy + badge
├── content.js # DOM extraction + form intercept + modal
├── popup.html / css / js # Extension popup UI
└── icons/
```
## ✨ 功能
- **实时扫描** —— 每个页面在加载后约 800ms 内完成分析
- **50 个 ML 特征** —— URL 熵、同形异义字检测、SSL 年龄、DOM 信号、品牌仿冒
- **可解释标记** —— 告诉您站点被标记的确切原因,而不仅仅是一个评分
- **提交前拦截** —— 在凭据发送之前,阻止高风险页面上的表单提交
- **威胁历史** —— 记录每个扫描站点的会话日志及评分
- **敏感度控制** —— 宽松 / 平衡 / 严格检测模式
- **徽章指示器** —— 扩展图标显示每个标签页的实时威胁评分
- **零数据保留** —— 所有分析都是临时的,不会远程存储任何内容
## 快速开始
### 🌐 选项 1:使用托管后端(推荐)
无需设置 —— 后端已部署。
扩展连接至:
https://vigil-production-4c62.up.railway.app
#### 步骤:
1. 克隆仓库
```
git clone https://github.com/shekh-2810/VIGIL.git
cd VIGIL
```
2. 加载 Chrome 扩展
- 前往 chrome://extensions
- 启用开发者模式
- 点击 Load unpacked → 选择 extension/ 文件夹
- 固定 Vigil 图标
完成 —— 扩展无需运行后端即可立即工作
### 🛠️ 选项 2:本地运行后端(开发)
如果您想修改或调试后端,请使用此选项。
1. 克隆仓库
```
git clone https://github.com/shekh-2810/VIGIL.git
cd VIGIL
```
2. 启动后端
```
cd backend
pip install -r requirements.txt
uvicorn app:app --host 0.0.0.0 --port 8000 --reload
```
验证:
```
curl http://127.0.0.1:8000/health
# → {"status":"ok","model_loaded":true}
```
3. 将扩展指向本地后端
在扩展弹窗中打开 DevTools → Console:
```
localStorage.setItem("VIGIL_BACKEND", "http://127.0.0.1:8000");
```
4. 加载扩展
```
Go to chrome://extensions
Enable Developer mode
Click Load unpacked → select extension/
Reload extension
```
🔁 切换回托管后端
```
localStorage.setItem("VIGIL_BACKEND", "https://vigil-production-4c62.up.railway.app");
```
### ⚠️ 注意事项:
托管后端可能有冷启动延迟(2–5s)。添加扩展后请刷新站点。
本地后端速度更快且无速率限制
除非切换端点,否则不要同时运行两者
## 当前限制与持续改进
Vigil 正在积极演进。已识别以下边缘情况并正在处理:
- 受限环境(例如 Chrome Web Store 页面)
某些受浏览器保护的页面会阻止扩展脚本,这可能会显示为“后端离线”状态。
这是浏览器的安全约束,而非系统故障。
- 高度混淆网站上的误报
大型生产站点通常使用高级 JavaScript 混淆来提升性能和保护 IP。
这可能类似于网络钓鱼行为并触发警报。
- 表单繁重的平台(例如搜索引擎)
像 Google 这样的站点使用多个隐藏输入字段来实现合法功能,
这可能会被误分类为可疑信号。
- 拥有分布式资产的大规模域名
企业通常从单独的域名或 CDN 提供资产(如 favicon),
这可能会被标记为域名不匹配。
## ML 模型详情
| 属性 | 值 |
|---|---|
| 算法 | XGBoost (gradient boosted trees) |
| 总特征数 | 50 |
| 训练样本数 | 6,000 |
| 精确率 | **0.9987** |
| 召回率 | **0.9947** |
| F1 分数 | **0.9967** |
| AUC-ROC | **1.00** |
| CV F1 (5-fold) | 0.9978 ± 0.0006 |
| 最佳迭代 | 492 / 500 (early stopping) |
### Top 10 特征重要性
| 特征 | 重要性 |
|---|---|
| num_hidden_inputs | 10.83% |
| unusual_tld | 10.72% |
| has_obfuscated_js | 8.73% |
| suspicious_keyword_count | 8.21% |
| form_action_mismatch | 8.17% |
| uses_https | 7.60% |
| query_length | 7.36% |
| is_url_shortener | 4.72% |
| has_right_click_disabled | 4.29% |
| has_external_form_action | 4.29% |
重要性分布在 10 个特征中 —— 没有单一特征占主导地位。这是泛化模型与过拟合模型的关键区别(我们的第一个模型有 2 个特征合计重要性达 97%)。
### 特征类别
**URL (32):** 长度、熵、子域名深度、连字符数量、数字数量、IP 地址使用、十六进制编码、HTTPS、可疑关键词、同形异义字检测、子域名/路径中的品牌仿冒、TLD 风险、URL 缩短器、查询字符串分析
**SSL (4):** 证书有效性、剩余天数、证书年龄、is-new-cert 标志
**DOM (14):** 密码字段、登录表单、隐藏输入、表单 action 域名不匹配、外部表单 action、favicon 不匹配、版权文本、iframe 数量、混淆 JS、外部链接比例、禁用右键、弹窗检测
## 🛡️ 威胁评分解读
| 评分 | 级别 | 操作 |
|---|---|---|
| 0 – 29 | 🟢 安全 | 无操作 |
| 30 – 59 | 🟡 可疑 | 在弹窗中显示警告 |
| 60 – 79 | 🔴 危险 | 阻止表单提交 |
| 80 – 100 | 🚨 严重 | 立即阻止 + 全屏模态框 |
## 设计决策与原因
### 为什么不使用 LangChain 或预训练模型?
#### 为什么不使用 LangChain / 基于 LLM 的 pipeline?
对于此问题,有意避免了 LangChain 和基于 LLM 的方法。
- **延迟** —— LLM 调用通常每个请求需要 500ms–3s,这对于实时保护来说太慢了。Vigil 的端到端运行时间约为 100–800ms。
- **非确定性输出** —— LLM 可能对相同的输入产生不一致的结果,这对于安全系统来说是不可接受的。
- **规模化成本** —— 每次页面访问都需要一次 API 调用,这使得系统昂贵且难以扩展。
- **隐私顾虑** —— 将每个访问的 URL 发送给第三方模型与安全工具的目标相悖。
- **对于结构化问题来说大材小用** —— 网络钓鱼检测从根本上说是一个结构化分类任务,而不是生成式推理问题。
**结论:** LLM 很强大,但不适合低延迟、确定性、注重隐私的检测系统。
#### 为什么不使用预训练模型 / 公共数据集?
也避免了使用来自网络的现成模型或数据集。
- **陈旧且不可靠的标签** —— 公共网络钓鱼数据集只是时间快照。URL 会更改、过期或被重新利用,从而引入隐藏噪声。
- **特征不匹配** —— 大多数数据集提供的是预计算特征,而不是原始输入。它们缺乏 Vigil 使用的实时 DOM 信号。
- **缺乏区域背景** —— 现有数据集严重偏向于美国/欧盟的网络钓鱼模式,错过了特定区域的攻击(例如 UPI、SBI、Paytm 诈骗)。
- **黑盒行为** —— 预训练模型通常缺乏透明度,使得难以解释*为什么*某个站点被标记。
- **对零日攻击的泛化能力差** —— 许多预训练系统依赖于不能很好地适应新网络钓鱼技术的模式。
#### 为什么选择自定义 XGBoost pipeline?
- **快速推理(~2ms)** —— 适合实时浏览器使用
- **确定性和可重现** —— 相同输入 → 相同输出
- **完全可解释** —— 每个预测都映射到清晰的信号
- **零外部依赖** —— 无第三方 API 调用
- **更好的零日检测** —— 学习结构模式,而不仅仅是已知 URL
### 设计理念
Vigil 围绕一个简单的原则构建:
这就是选择自定义 ML pipeline 而非通用框架或预训练解决方案的原因。
### 为什么使用合成数据集而非公共数据集?
- **标签陈旧:** 公共数据集是快照;URL 可能不再反映现实。
- **地理不匹配:** 缺乏印度网络钓鱼模式(SBI、UPI、Paytm 诈骗)。
- **特征不匹配:** 公共数据集缺乏本项目使用的基于 DOM 的特征。
合成生成允许:
- 受控的攻击模式(8 种类型)
- 现实的 HTTPS 使用(约 40% 网络钓鱼)
- 特定区域的网络钓鱼场景
- 与 50 特征 pipeline 完全对齐
**权衡:** 可能遗漏罕见的现实世界边缘情况,通过根据真实网络钓鱼技术设计模式来缓解。
## 开发中遇到的问题
### 1. Chrome 阻止 localhost 请求
- **问题:** 尽管 API 正常工作,但弹窗显示“后端离线”
- **原因:** 由于 Chrome Private Network Access 限制,content scripts 无法访问 `localhost`
- **修复:** 将 API 调用移至 `background.js`(service worker 代理)
### 2. XGBoost API 变更
- **问题:** `early_stopping_rounds` 错误
- **原因:** 参数在较新的 XGBoost 版本中已移动
- **修复:** 将其从 `.fit()` 移至模型构造函数
### 3. 模型过拟合(虚假的完美)
- **问题:** F1 = 1.0 但模型仅依赖 2 个特征
- **原因:** 数据集缺陷 —— HTTPS 完美分离了类别
- **修复:** 重建数据集:
- 混合 HTTPS 使用
- 添加现实的域名模式
- 扩展至 10k 个样本
**结果:** F1 = 0.9967,特征重要性平衡
## 🧪 本地用户直接测试 API
```
# Safe site
curl -X POST http://127.0.0.1:8000/analyze \
-H "Content-Type: application/json" \
-d '{"url":"https://google.com","dom_data":{}}'
# Phishing with DOM signals
curl -X POST http://127.0.0.1:8000/analyze \
-H "Content-Type: application/json" \
-d '{
"url": "http://secure-paypa1-login.xyz/webscr?cmd=login",
"dom_data": {
"has_password_field": true,
"has_login_form": true,
"has_obfuscated_js": true,
"num_hidden_inputs": 4,
"form_action_domain_mismatch": true
}
}'
# Debug — see all 50 features the model uses
curl http://127.0.0.1:8000/features
```
## 🤝 贡献
1. Fork 仓库
2. 创建功能分支:`git checkout -b feature/my-feature`
3. 提交:`git commit -m 'Add my feature'`
4. 推送并打开 Pull Request
Built with 🛡️ by ZeroDay Legends · VIT Bhopal
标签:Apex, AV绕过, Chrome插件, DOM检查, FastAPI, Python后端, SSL证书验证, URL情报, Web安全, XGBoost, 人工智能, 凭证窃取防护, 前端安全, 反钓鱼, 威胁评分, 实时分析, 恶意软件防护, 搜索语句(dork), 数据可视化, 机器学习, 浏览器扩展, 用户模式Hook绕过, 网络安全, 蓝队分析, 请求拦截, 逆向工具, 钓鱼检测, 隐私保护