RACHANA-432/Bank-Transactions-Fraud-Detection-System
GitHub: RACHANA-432/Bank-Transactions-Fraud-Detection-System
基于Azure构建的端到端数据工程管道,使用medallion架构和规则引擎实现银行交易欺诈检测。
Stars: 0 | Forks: 0
# 银行交易欺诈检测(基于规则)
## 项目概述
本项目实现了一个**端到端数据工程管道**,使用**基于规则的逻辑**检测欺诈性银行交易。它利用 Azure 云服务以及现代数据工程实践,以规模化方式摄取、转换和分析交易数据。
该管道采用** medallion 架构(Bronze、Silver、Gold)**设计,以确保数据质量、可扩展性和可维护性。欺诈检测使用业务驱动的规则执行,例如识别高价值交易和检测短时间窗口内的多笔交易。
## 架构
**端到端流程:**
```
Source (CSV / Azure SQL)
│
▼
Azure Data Factory (Ingestion & Orchestration)
│
▼
Azure Data Lake Storage (Bronze → Silver → Gold)
│
▼
Azure Databricks (PySpark Transformations)
│
▼
Delta Lake + Unity Catalog
│
▼
Power BI Dashboard (Visualization)
```
## Medallion 架构
### Bronze 层(原始数据)
- 存储原始摄取的交易数据
- 不应用任何转换
### Silver 层(清洗后的数据)
- 数据已清洗和标准化
- 转换包括:
- 处理空值
- 数据类型转换
- 删除重复项
- 重命名列
- 选择所需列
### Gold 层(业务层)
- 应用欺诈检测规则
- 为每笔交易包含欺诈标记
- 生成可供分析使用的 Gold 表
- fact_all_transactions
- fact_fraud_transactions
- dim_customer_details
## 欺诈检测规则
实现了两个基于规则的关键检查:
### 1. 高价值交易
超过定义的高价值阈值的交易被标记为欺诈。
### 2. 多笔交易(窗口函数)
同一用户在短时间窗口内的多笔交易被标记为欺诈。
## 技术栈
使用的工具和技术:
- Azure SQL
- Azure Data Factory
- Azure Databricks
- Unity Catalog
- Delta Lake
- Power BI
## Azure SQL
Azure SQL 数据库在本项目中用作主要源系统。它在数据管道摄取之前存储结构化的银行交易数据。
**用途:**
- 作为交易数据的可信来源
- 以结构化格式存储原始交易记录
- 支持与 Azure Data Factory(ADF)无缝集成以进行数据摄取
- 支持可扩展和安全的数据存储
## Azure Databricks
Azure Databricks 用作核心数据处理引擎,使用 PySpark 转换和分析交易数据。
**实现:**
- 从 Bronze → Silver → Gold 的所有转换都使用面向对象编程原则(类、可重用函数、模块化设计)的 PySpark 实现。
- 数据以 ADLS 中外部表的形式存储在各层中。
- 管道日志维护在托管表中,用于监控和调试。
## Delta 表
Delta Lake 用于在 Bronze、Silver 和 Gold 层存储数据,确保可靠和优化的数据处理。
主要优势:
- ACID 事务
- 模式强制执行
- 时间旅行(数据版本控制)
- 高效的 MERGE 操作用于增量加载
- 使用优化的存储和索引实现更快的查询性能
Delta 表确保可靠和优化的数据处理。
## Unity Catalog
用于集中数据治理和访问控制。
**组件:**
* Metastore → 集中元数据存储库
* External Locations → ADLS 路径的安全映射
* Credentials → 安全存储访问(托管标识)
* Catalog & Schemas → 逻辑分离(bronze、silver、gold)
### Unity Catalog 设置
1. 访问连接器(托管标识)
- 为 Databricks 创建访问连接器
- 用作托管标识以安全访问 ADLS(无需密钥或访问令牌)
2. 角色分配
- 分配角色:存储 Blob 数据参与者
- 范围:ADLS 存储账户
3. 创建 Metastore
- 创建并附加 Unity Catalog Metastore
- 在 ADLS 中定义根存储路径
```
abfss://@.dfs.core.windows.net/
```
4. 存储凭证
- 创建存储凭证以定义 Unity Catalog 如何访问存储。
```
CREATE STORAGE CREDENTIAL my_credential
WITH AZURE_MANAGED_IDENTITY
```
→ 使用访问连接器的托管标识
5. 创建外部位置
- 外部位置提供对 ADLS 中特定路径的访问。
```
CREATE EXTERNAL LOCATION my_external_location
URL 'abfss://@.dfs.core.windows.net/'
WITH (STORAGE CREDENTIAL my_credential)
```
6. 创建 Catalog 和 Schema
```
CREATE CATALOG catalog_name;
USE CATALOG catalog_name;
CREATE SCHEMA schema_name;
```
### 安全优势
- 无硬编码凭证
- 基于角色的访问控制(RBAC)
- 细粒度权限(catalog/schema/table 级别)
- 跨工作区的集中治理
## Azure Data Factory 管道
Azure Data Factory(ADF)在本项目中用作编排和数据集成服务。它自动化数据从源系统到数据湖的移动,并触发下游处理工作流。
### 方法 1:顺序管道
- 复制活动(Azure SQL → ADLS Bronze)
- Databricks Notebook 活动(摄取 Bronze)
- Databricks Notebook 活动(Bronze → Silver)
- Databricks Notebook 活动(Silver → Gold)
→ 简单且易于管理
### 方法 2:模块化管道 + Databricks 工作流
- 复制活动(Azure SQL → ADLS Bronze)
- ADF 触发 Databricks 作业
- Databricks 作业执行多个 notebook(任务):
- 摄取(Bronze)
- 转换(Bronze → Silver)
- 欺诈检测(Silver → Gold)
→ 更加可扩展且适合生产环境
### 链接服务和数据集
**链接服务**
- 定义与外部系统的连接。
- 用于连接 ADF:
- Azure SQL 数据库(源)
- ADLS Gen2(存储)
- Azure Databricks(计算)
**数据集**
表示链接服务内的数据结构。
- 定义:
- 表(用于 SQL 源)
- 文件格式和路径(用于 ADLS)
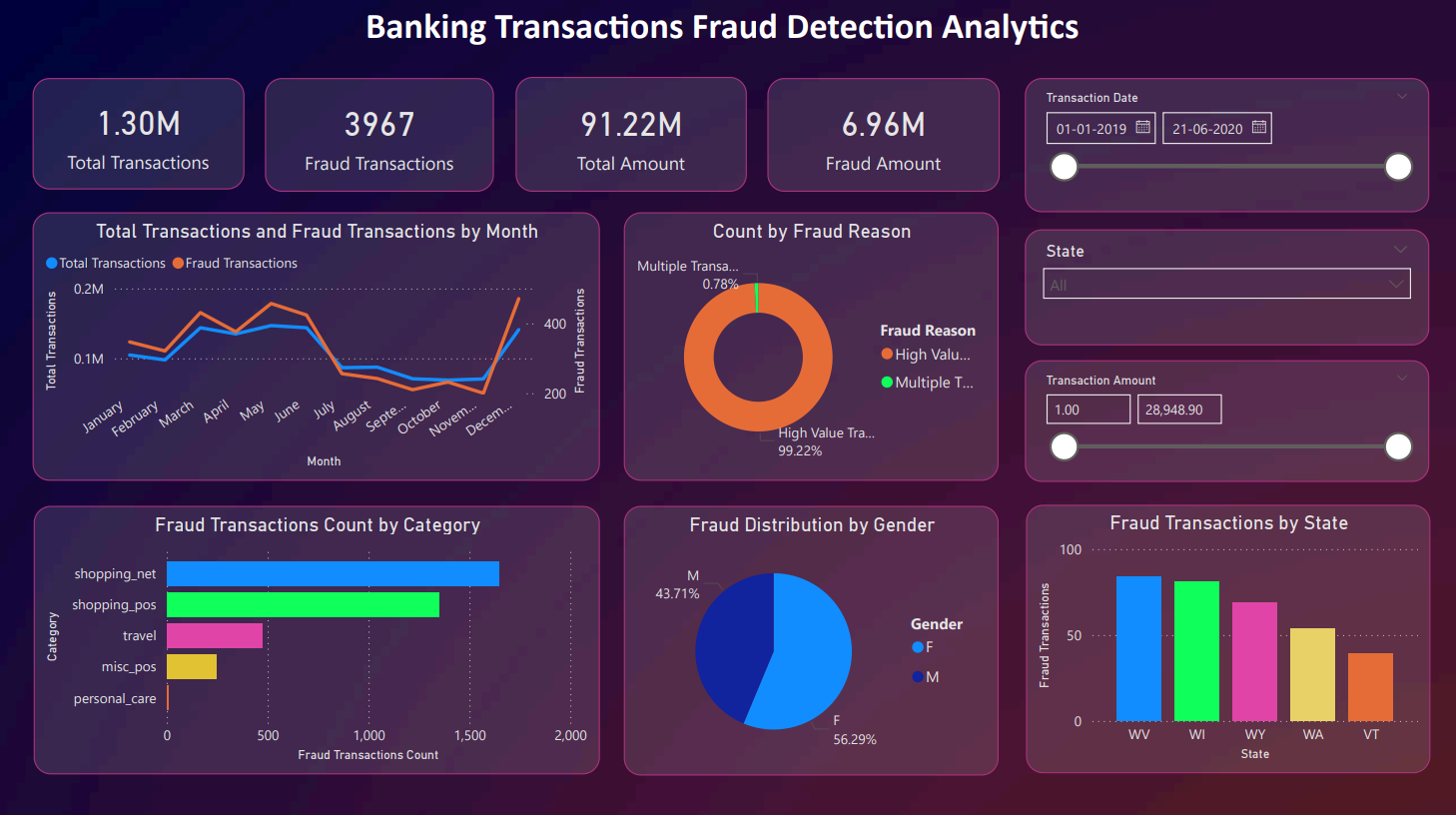
## Power BI
Power BI 用于数据可视化和报告,使利益相关者能够监控欺诈趋势和交易洞察。
### 欺诈分析仪表板
 ## 项目结构
```
Bank-Transactions-Fraud-Detection-System/
│
├── data/
│ └── sample/
│ └── credit_card_transactions_dataset
│
├── notebooks/
│ ├── 00-Configurations.ipynb
│ ├── 01-Ingest (Bronze Layer).ipynb
│ ├── 02-Bronze-to-Silver.ipynb
│ └── 03-Silver-to-Gold.ipynb
│
├── pipelines/
│ ├── ADF-Pipeline.json
│ └── ADF-Databricks-Pipeline.json
│
├── screenshots/
│ ├── ADF-Pipeline.png
│ ├── ADF-Databricks-Pipeline.png
│ ├── ADLS-Container.png
│ ├── Project-Resource-Group.png
│ └── Databricks-Job-Tasks.png
│ └── Azure SQL - DB.png
│ └── Pipeline Logs Table.png
│
└── README.md
```
## 主要功能
- 使用 Azure 服务构建的端到端数据管道
- 基于规则的欺诈检测逻辑
- Medallion 架构实现
- 使用 PySpark 的可扩展数据处理
- Delta Lake 优化存储
- Unity Catalog 治理
- 模块化且可重用的 notebook 设计
- 日志记录和审计跟踪
## 未来改进
- 实现增量数据加载(水印/CDC)以仅处理新增和更新的记录
- 使用 Delta Lake upsert(MERGE)进行高效的插入/更新处理,而不是全量加载
- 集成基于 ML 的欺诈检测模型以进行高级异常检测
- 使用 Databricks 中的分区、Z-ordering 和缓存优化性能
- 使用流式处理(Event Hub / Kafka)启用实时处理,以实现即时欺诈检测
## 结论
本项目展示了一个完整的、真实的欺诈检测数据工程解决方案,采用现代云技术和行业最佳实践构建。它涵盖了完整的数据生命周期——从摄取到转换和分析——使用 Azure 上的可扩展 Medallion 架构。凭借强大的管道编排、通过 Unity Catalog 的安全数据治理以及使用 Databricks 和 Delta Lake 的高效处理,该系统旨在可靠地处理大规模交易数据。总体而言,它展示了一种可扩展、可维护且符合现代企业数据平台的生产就绪方法。
## 作者
Rachana Chavan
## 项目结构
```
Bank-Transactions-Fraud-Detection-System/
│
├── data/
│ └── sample/
│ └── credit_card_transactions_dataset
│
├── notebooks/
│ ├── 00-Configurations.ipynb
│ ├── 01-Ingest (Bronze Layer).ipynb
│ ├── 02-Bronze-to-Silver.ipynb
│ └── 03-Silver-to-Gold.ipynb
│
├── pipelines/
│ ├── ADF-Pipeline.json
│ └── ADF-Databricks-Pipeline.json
│
├── screenshots/
│ ├── ADF-Pipeline.png
│ ├── ADF-Databricks-Pipeline.png
│ ├── ADLS-Container.png
│ ├── Project-Resource-Group.png
│ └── Databricks-Job-Tasks.png
│ └── Azure SQL - DB.png
│ └── Pipeline Logs Table.png
│
└── README.md
```
## 主要功能
- 使用 Azure 服务构建的端到端数据管道
- 基于规则的欺诈检测逻辑
- Medallion 架构实现
- 使用 PySpark 的可扩展数据处理
- Delta Lake 优化存储
- Unity Catalog 治理
- 模块化且可重用的 notebook 设计
- 日志记录和审计跟踪
## 未来改进
- 实现增量数据加载(水印/CDC)以仅处理新增和更新的记录
- 使用 Delta Lake upsert(MERGE)进行高效的插入/更新处理,而不是全量加载
- 集成基于 ML 的欺诈检测模型以进行高级异常检测
- 使用 Databricks 中的分区、Z-ordering 和缓存优化性能
- 使用流式处理(Event Hub / Kafka)启用实时处理,以实现即时欺诈检测
## 结论
本项目展示了一个完整的、真实的欺诈检测数据工程解决方案,采用现代云技术和行业最佳实践构建。它涵盖了完整的数据生命周期——从摄取到转换和分析——使用 Azure 上的可扩展 Medallion 架构。凭借强大的管道编排、通过 Unity Catalog 的安全数据治理以及使用 Databricks 和 Delta Lake 的高效处理,该系统旨在可靠地处理大规模交易数据。总体而言,它展示了一种可扩展、可维护且符合现代企业数据平台的生产就绪方法。
## 作者
Rachana Chavan
## 项目结构
```
Bank-Transactions-Fraud-Detection-System/
│
├── data/
│ └── sample/
│ └── credit_card_transactions_dataset
│
├── notebooks/
│ ├── 00-Configurations.ipynb
│ ├── 01-Ingest (Bronze Layer).ipynb
│ ├── 02-Bronze-to-Silver.ipynb
│ └── 03-Silver-to-Gold.ipynb
│
├── pipelines/
│ ├── ADF-Pipeline.json
│ └── ADF-Databricks-Pipeline.json
│
├── screenshots/
│ ├── ADF-Pipeline.png
│ ├── ADF-Databricks-Pipeline.png
│ ├── ADLS-Container.png
│ ├── Project-Resource-Group.png
│ └── Databricks-Job-Tasks.png
│ └── Azure SQL - DB.png
│ └── Pipeline Logs Table.png
│
└── README.md
```
## 主要功能
- 使用 Azure 服务构建的端到端数据管道
- 基于规则的欺诈检测逻辑
- Medallion 架构实现
- 使用 PySpark 的可扩展数据处理
- Delta Lake 优化存储
- Unity Catalog 治理
- 模块化且可重用的 notebook 设计
- 日志记录和审计跟踪
## 未来改进
- 实现增量数据加载(水印/CDC)以仅处理新增和更新的记录
- 使用 Delta Lake upsert(MERGE)进行高效的插入/更新处理,而不是全量加载
- 集成基于 ML 的欺诈检测模型以进行高级异常检测
- 使用 Databricks 中的分区、Z-ordering 和缓存优化性能
- 使用流式处理(Event Hub / Kafka)启用实时处理,以实现即时欺诈检测
## 结论
本项目展示了一个完整的、真实的欺诈检测数据工程解决方案,采用现代云技术和行业最佳实践构建。它涵盖了完整的数据生命周期——从摄取到转换和分析——使用 Azure 上的可扩展 Medallion 架构。凭借强大的管道编排、通过 Unity Catalog 的安全数据治理以及使用 Databricks 和 Delta Lake 的高效处理,该系统旨在可靠地处理大规模交易数据。总体而言,它展示了一种可扩展、可维护且符合现代企业数据平台的生产就绪方法。
## 作者
Rachana Chavan标签:Azure, Azure Databricks, Azure Data Factory, Bronze Silver Gold, Delta Lake, ETL, Gradle集成, JavaCC, Medallion Architecture, Power BI, PySpark, Unity Catalog, 业务智能, 云数据工程, 云计算, 交易监控, 可扩展数据处理, 大数据管道, 实时欺诈检测, 异常检测, 数据仓库, 数据工程, 数据治理, 数据湖, 数据质量, 欺诈检测, 规则引擎, 金融安全, 金融数据, 银行交易