jemin6780-afk/Bio-Process-Digital-Twin-Quality-Control-Engine
GitHub: jemin6780-afk/Bio-Process-Digital-Twin-Quality-Control-Engine
面向生物制药行业的数字孪生原型,通过多元统计分析、AI异常检测和流体动力学仿真帮助MSAT团队进行工艺偏差预警与根因调查。
Stars: 0 | Forks: 0
# 🧬 生物工艺数字孪生与质量控制引擎
本项目是 **MSAT(制造科学与技术)优化**的原型,连接理论流体动力学与实际生物工艺放大逻辑。
## 📊 示例输出
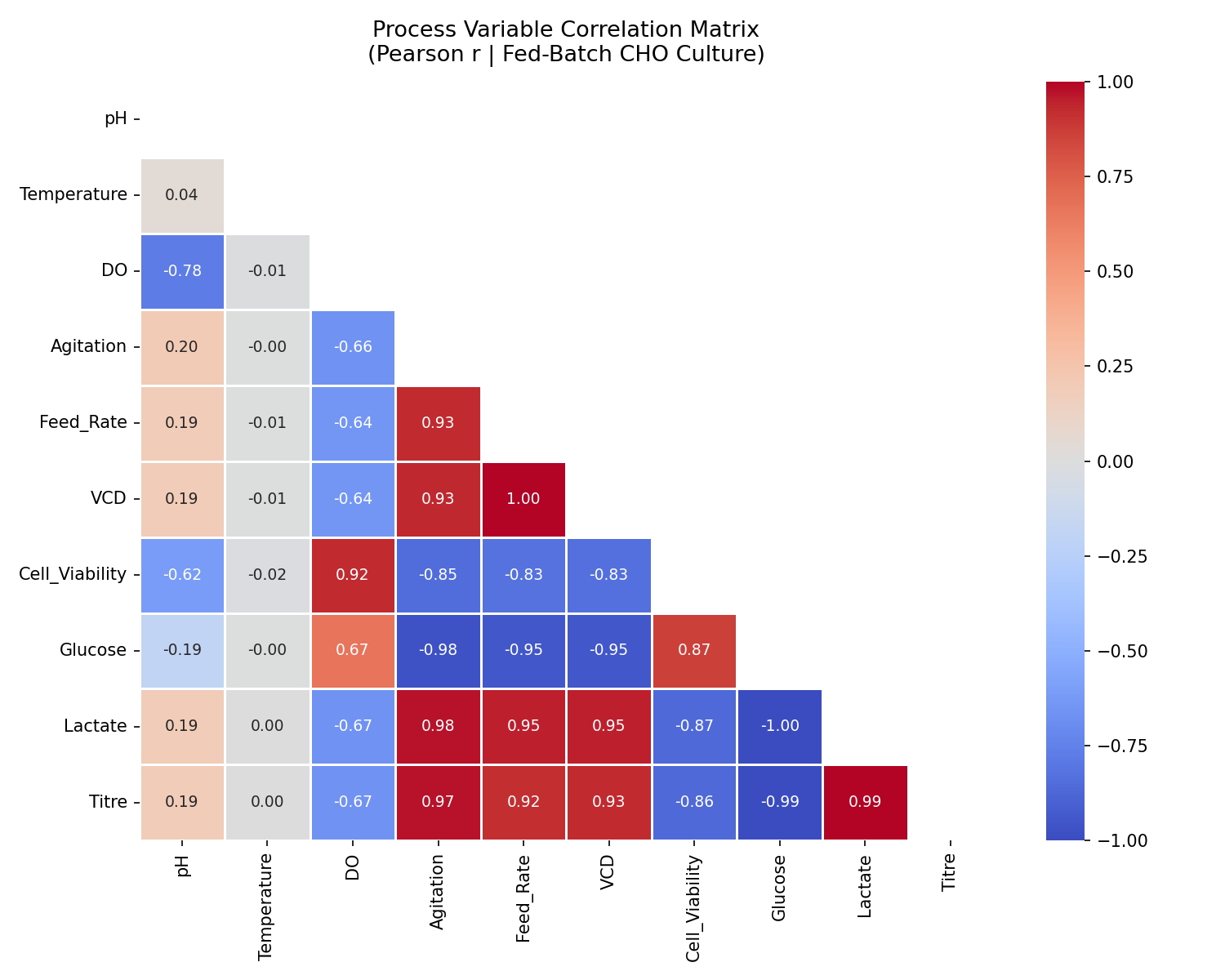
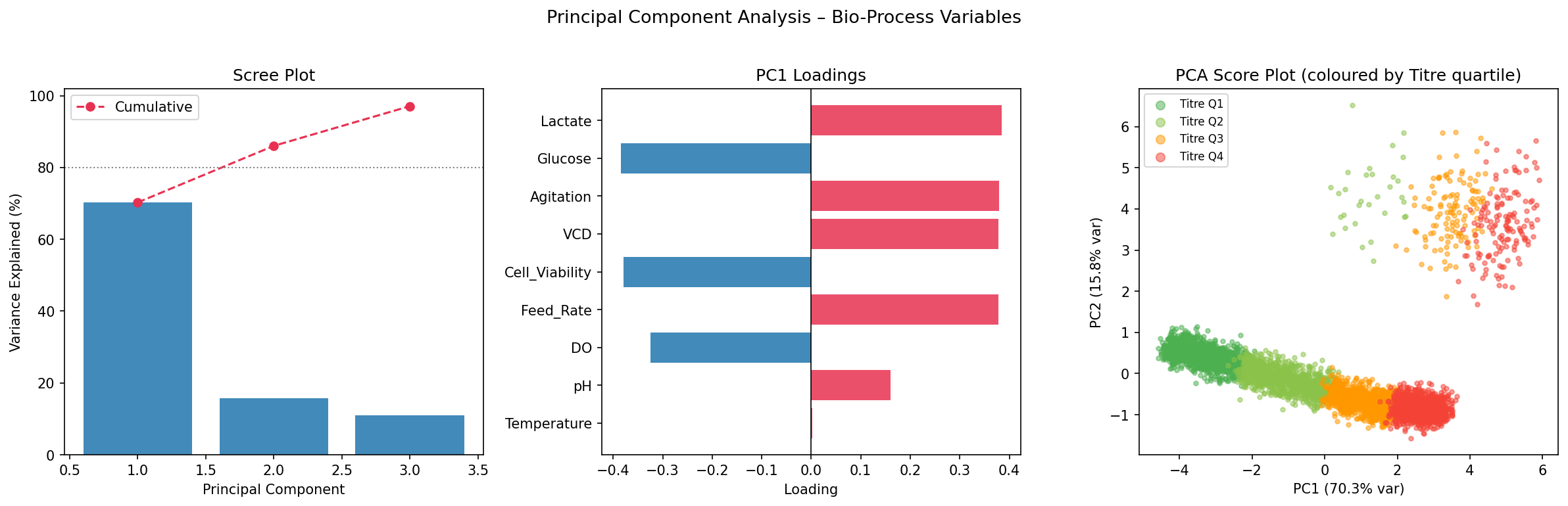
### 模块 1 — 多元分析
/BioProcess-Optimizer.git
cd BioProcess-Optimizer
# 安装依赖
pip install -r requirements.txt
# 运行完整流水线
python main.py
```
输出图表保存至 `outputs/{multivariate,deviation,fluid}/`
## 📊 示例输出
| 模块 | 输出 |
|---|---|
| 模块 1 | 相关性热图 · PCA 碎石图 · 得分散点图 · ANOVA 箱线图 |
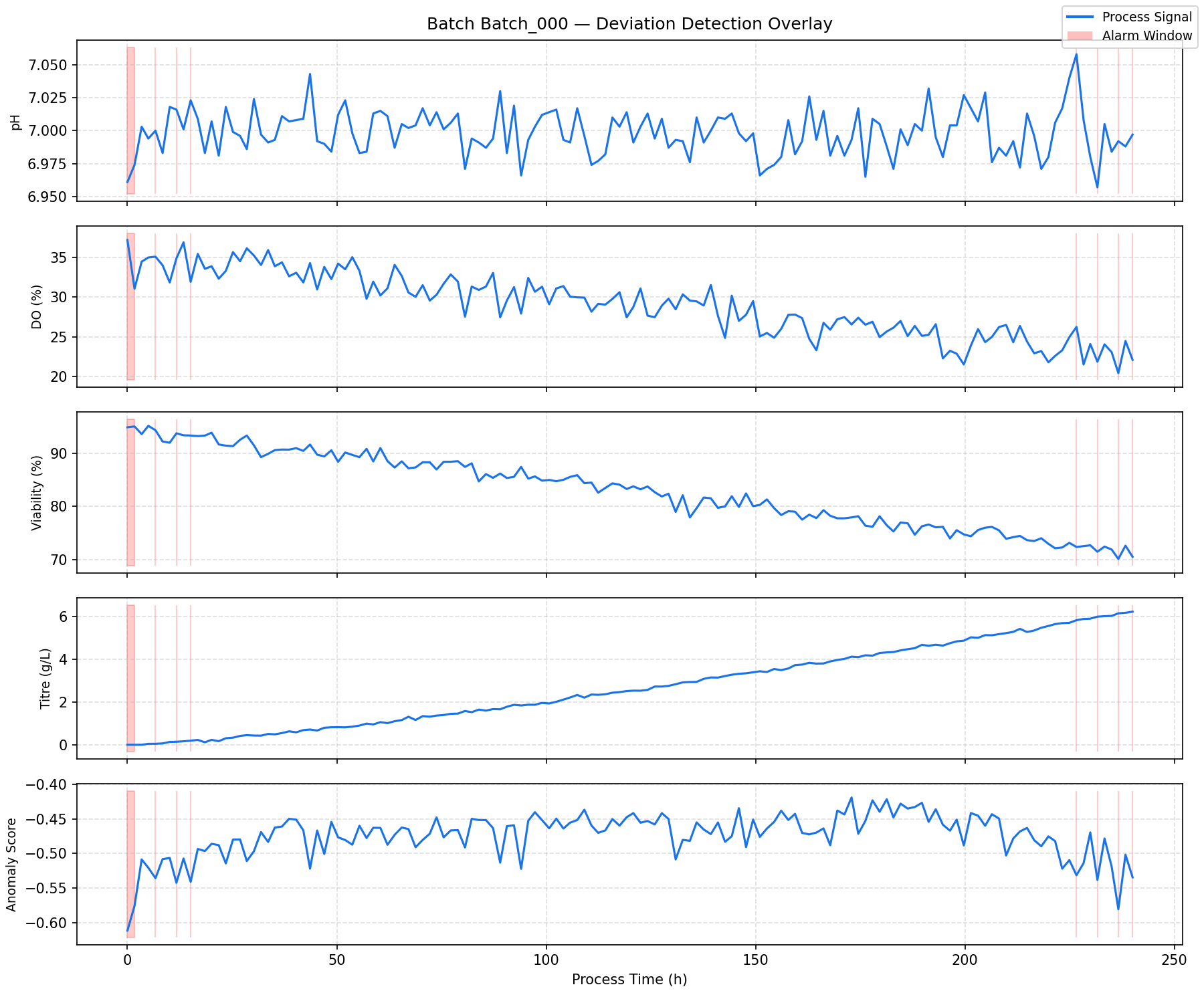
| 模块 2 | 时间序列异常叠加 · LIR `.txt` 草稿 · 精确率/召回率报告 |
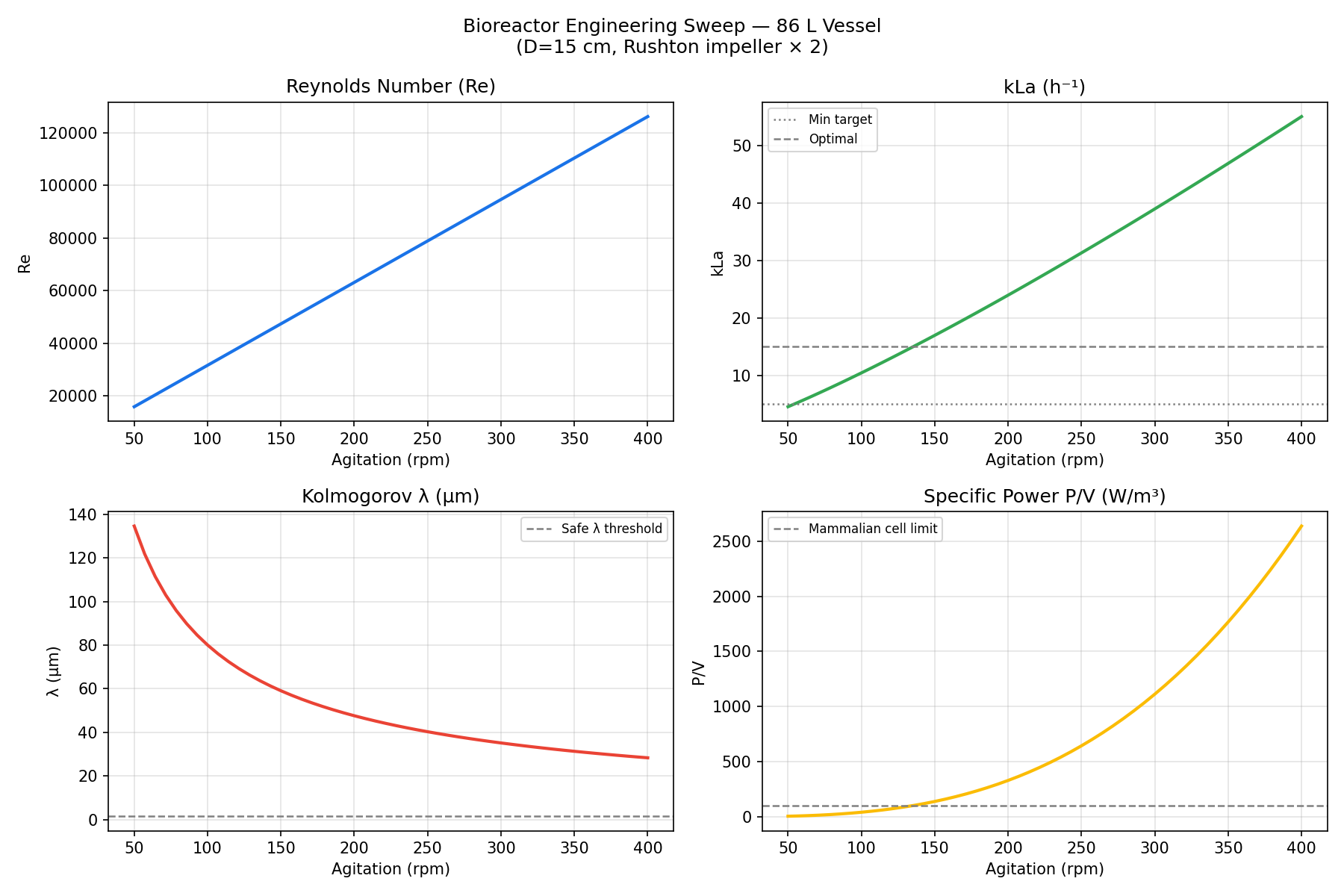
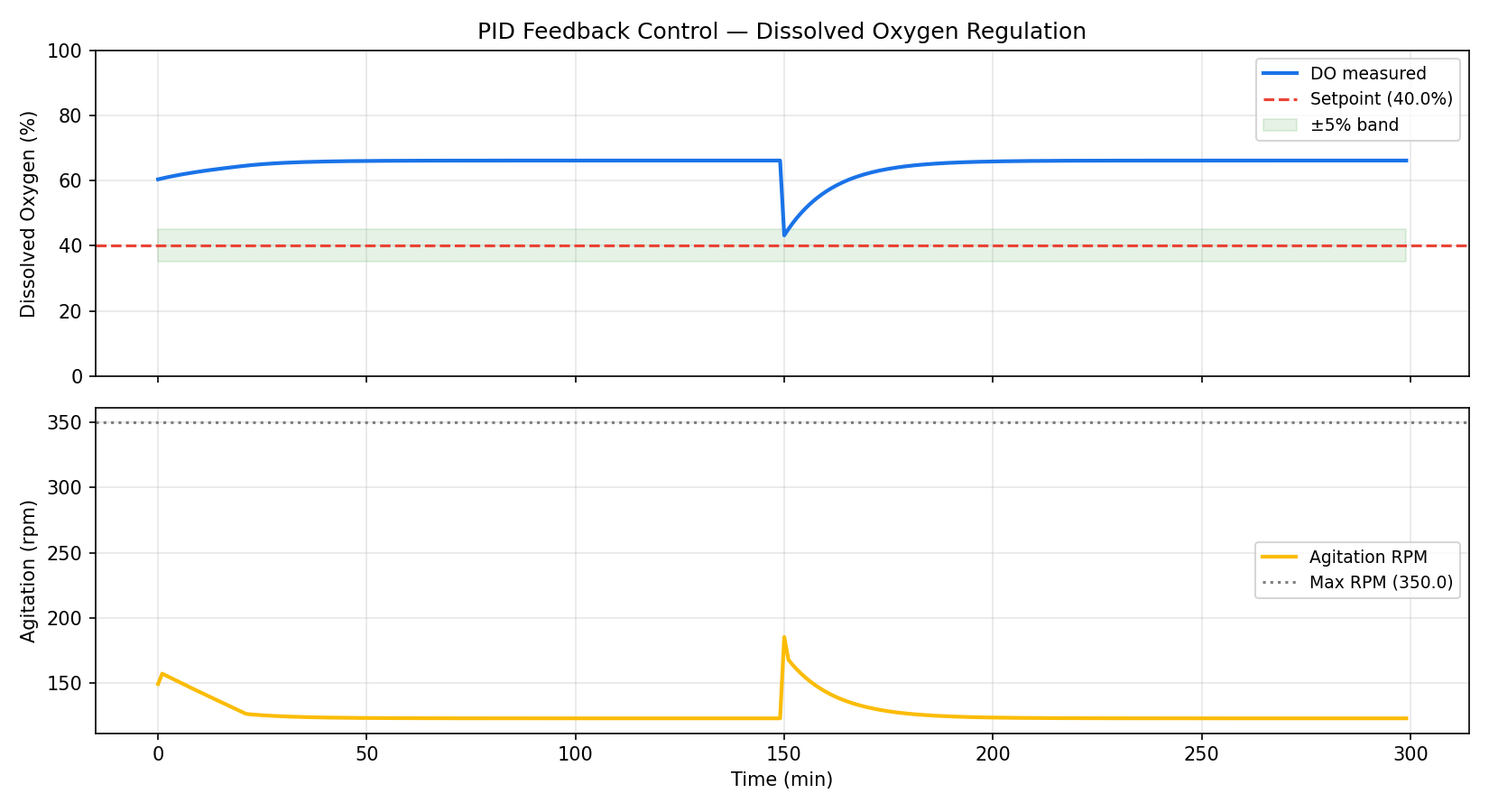
| 模块 3 | 搅拌扫描(Re / kLa / λ / P/V)· PID DO 控制响应 |
## 🔬 合成数据集
数据集(`data/synthetic_batch_data.py`)生成 **30 × 144 个时间点的补料批次 CHO 细胞培养**记录,包含:
- 现实变量范围:pH 6.8–7.2,DO 5–70%,滴度 0–8 g/L,VCD 0–130 × 10⁶ cells/mL
- 逻辑斯蒂 VCD 生长模型,带有批次间 µ_max 变异性
- 在约 15% 的批次中注入偏差场景(pH 漂移、DO 骤降)
- 用于模型评估的真实 `Is_Deviation` 标签
## 📐 设计原则
- **OOP 架构** — 每个模块都是具有清晰公共 API 的独立类,支持独立单元测试和未来集成到 Flask/FastAPI 仪表板。
- **GMP 感知输出** — 所有解释使用监管词汇(CPP、CQA、NOR、CAPA、PAR),符合 ICH Q8/Q10。
- **安全失败解释** — 每个数值结果都附带条件解释块,将值映射到工艺工程决策,消除静默失败的风险。
- **放大就绪** — `BioreactorGeometry` 和 `FluidState` 是数据类;从 50 L 放大到 2000 L 生产罐只需更改两个参数即可。
## 🛠️ 技术栈
| 层级 | 库 |
|---|---|
| 数据处理 | `pandas`、`numpy` |
| 机器学习 | `scikit-learn`(IsolationForest、PCA)|
| 统计 | `scipy.stats`(f_oneway)|
| 可视化 | `matplotlib`、`seaborn` |
## 🔭 路线图
- [ ] 基于 LSTM 的时间序列异常检测(滚动窗口)
- [ ] 用于实时批次监控的 Streamlit Web 仪表板
- [ ] 与公开 FDA 不良事件数据集集成,用于 CPP 基准测试
- [ ] 用于响应面方法论的 DoE(实验设计)模块
## 👤 关于
由 **Jemin Lee** 构建,作为为 **伦敦帝国理工学院** 计算生物工程硕士课程自主准备的一部分。
该项目的核心信念是:生物制药 MSAT 缺失的部分不是更多数据——而是使这些数据能够实时可操作的计算基础设施。
## 📄 许可证
MIT 许可证——详见 [LICENSE](LICENSE)。
标签:ANOVA, Apex, Bioprocess, CPP, CQA, Golden Batch, Isolation Forest, kLa, LIR, MSAT优化, PCA, PID控制, Python, Reynolds数, Scale-up, 上游工艺, 偏差检测, 多变量分析, 异常检测, 批次数据, 数字孪生, 无后门, 无监督学习, 机器学习, 流体动力学, 溶解氧控制, 生物制药, 生物反应器, 细胞培养, 统计分析, 过程参数映射, 过程控制, 逆向工具, 预测性维护