aws-samples/sample-emr-eks-spark-kerberos-hms
GitHub: aws-samples/sample-emr-eks-spark-kerberos-hms
为 Amazon EMR on EKS 上的 Apache Spark 作业提供 Kerberos 认证方案,使其能够安全连接到已启用 Kerberos 的集中式 Hive Metastore,实现与 EMR on EC2 工作负载的统一元数据管理。
Stars: 0 | Forks: 0
# 为 Amazon EMR on EKS 上的 Apache Spark 作业实现 Kerberos 认证以访问启用 Kerberos 的 Hive Metastore
许多组织在 [Amazon EMR on Amazon EC2](https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-what-is-emr.html) 上运行其 [Apache Spark](https://spark.apache.org/docs/latest/) 分析平台,并使用 [Kerberos](https://web.mit.edu/kerberos/) 认证来保护 Spark 作业与集中式共享 [Apache Hive Metastore (HMS)](https://hive.apache.org/) 之间的连接。借助 [Amazon EMR on Amazon EKS](https://docs.aws.amazon.com/emr/latest/EMR-on-EKS-DevelopmentGuide/emr-eks.html),他们获得了一种运行 Spark 作业的新选择,并可享受基于 [Kubernetes](https://kubernetes.io/docs/concepts/overview/) 的容器编排、更高的资源利用率以及更快的作业启动时间带来的优势。然而,一个 HMS 部署一次仅支持一种认证机制。这意味着他们必须为 Amazon EMR on EKS 上的 Spark 作业配置 Kerberos 认证,才能连接到现有的启用 Kerberos 的 HMS。
在本代码库中,我们展示了如何为 Amazon EMR on EKS 上的 Spark 作业配置 Kerberos 认证,针对启用 Kerberos 的 HMS 进行身份验证,以便您可以针对单个安全的 HMS 部署同时运行 Amazon EMR on EC2 和 Amazon EMR on EKS 工作负载。
有关更多信息,请参阅 AWS Big Data Blog 文章《[为 Amazon EMR on EKS 上的 Apache Spark 作业实现 Kerberos 认证以访问启用 Kerberos 的 Hive Metastore](https://aws.amazon.com/blogs/big-data/implementing-kerberos-authentication-for-apache-spark-jobs-on-amazon-emr-on-eks-to-access-a-kerberos-enabled-hive-metastore/)》。
## 解决方案概述
考虑这样一个企业数据平台团队,他们在 Amazon EMR on EC2 上运行 Spark 作业已有数年。其架构包含一个启用 Kerberos 的独立 HMS 作为集中式数据目录,并由 Microsoft Active Directory 作为密钥分发中心 (KDC)。当该团队评估将 Amazon EMR on EKS 用于新工作负载时,他们现有的 HMS 必须继续为 Amazon EMR on EC2 提供服务,并且两者都要通过相同的 Kerberos 基础设施进行认证。
为了解决这个问题,平台团队必须配置其在 Amazon EMR on EKS 上运行的 Spark 作业,以便与同一个 KDC 进行认证。这样一来,他们就可以获取有效的 Kerberos 票据并与 HMS 建立经过认证的连接,同时在其数据平台上维持统一的安全态势。
下面的架构图展示了该实现的核心组件。
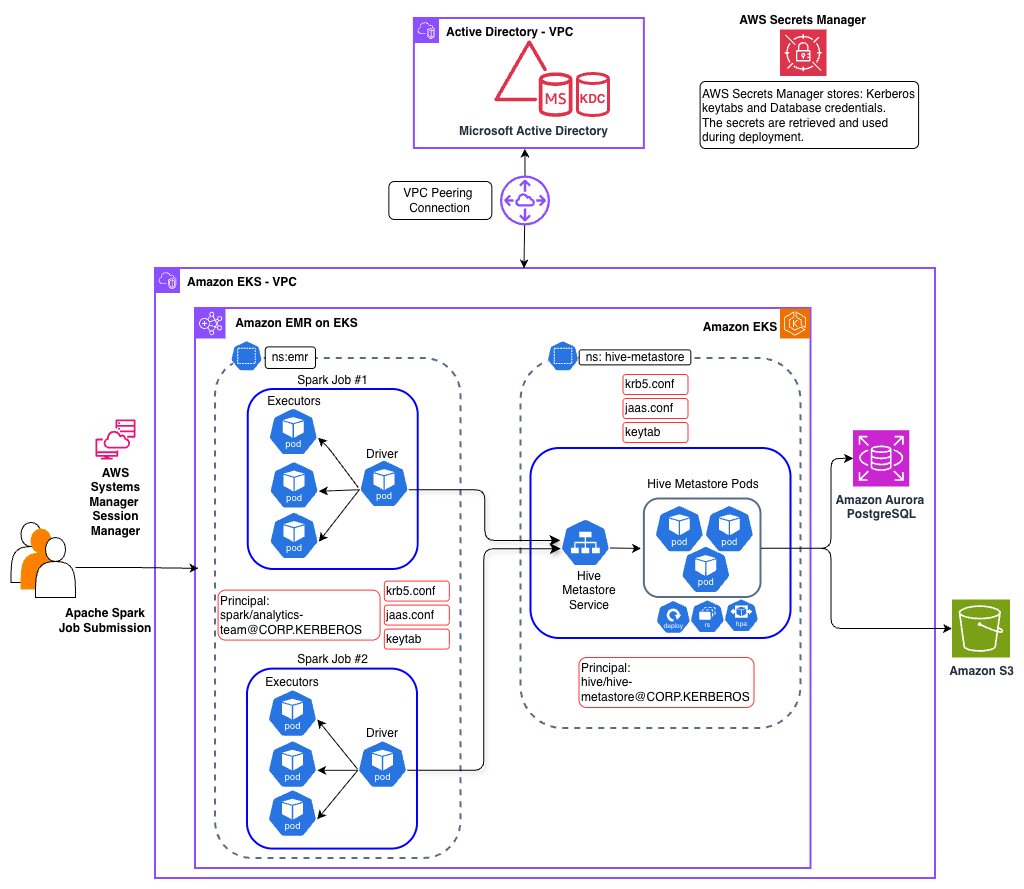
有关 Spark 与 Hive Metastore 之间 Kerberos 认证流程的详细序列图,请参阅 [Kerberos 认证流程](docs/kerberos-authentication-flow.md)。
## 前置条件
在部署此解决方案之前,请确保已满足以下前置条件:
- 拥有有效的 [AWS 账户](https://signin.aws.amazon.com/signin) 访问权限以及创建 AWS 资源的权限。
- 您的本地计算机上已[安装](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) [AWS Command Line Interface (AWS CLI)](http://aws.amazon.com/cli)。
- 您的本地计算机上已安装 [Git](https://github.com/git-guides/install-git)、[Docker](https://docs.docker.com/engine/install/)、[eksctl](https://docs.aws.amazon.com/eks/latest/userguide/eksctl.html)、[kubectl](https://docs.aws.amazon.com/eks/latest/userguide/install-kubectl.html)、[Helm](https://helm.sh/docs/intro/install/)、[envsubst](https://man7.org/linux/man-pages/man1/envsubst.1.html)、[jq](https://jqlang.github.io/jq/) 和 [yq](https://mikefarah.gitbook.io/yq) 等实用工具。
- 熟悉 [Kerberos](https://web.mit.edu/kerberos/)、[Apache Hive Metastore (HMS)](https://hive.apache.org/)、[Apache Spark](https://spark.apache.org/docs/latest/)、[Kubernetes](https://kubernetes.io/)、[Amazon EKS](https://aws.amazon.com/eks/) 以及 [Amazon EMR on Amazon EKS](https://docs.aws.amazon.com/emr/latest/EMR-on-EKS-DevelopmentGuide/emr-eks.html)。
## 部署指南
### 克隆代码库并设置环境变量
```
git clone git@github.com:aws-samples/sample-emr-eks-spark-kerberos-hms.git
cd sample-emr-eks-spark-kerberos-hms
export REPO_DIR=$(pwd)
export AWS_REGION=
```
### 部署 Active Directory 基础设施
```
cd ${REPO_DIR}/microsoft-ad/
./setup.sh
```
### 验证 AD 域服务是否就绪
在创建服务主体之前,请在堆栈部署完成后等待大约 30 分钟,然后验证 Active Directory Domain Services (AD DS) 是否已完全初始化。该 EC2 实例会在 AD DS 安装后重启。
```
# 获取运行中的实例 ID
INSTANCE_ID=$(aws ec2 describe-instances \
--filters "Name=tag:Name,Values=*ADServer*" "Name=instance-state-name,Values=running" \
--query "Reservations[0].Instances[0].InstanceId" --output text)
# 发送命令以检查 AD DS 是否准备就绪
COMMAND_ID=$(aws ssm send-command \
--instance-ids $INSTANCE_ID \
--document-name "AWS-RunPowerShellScript" \
--parameters 'commands=["Get-ADDomain"]' \
--query "Command.CommandId" --output text)
If the output shows an error like ```aws: [ERROR]: An error occurred (InvalidInstanceId) when calling the SendCommand operation: Instances not in a valid state for account``` wait a few more minutes and retry.
# 检查结果(等待几秒钟使命令完成)
aws ssm get-command-invocation \
--command-id $COMMAND_ID \
--instance-id $INSTANCE_ID \
--query "[Status, StandardOutputContent]" --output text
```
如果输出显示 `Success` 及随后的域信息(DNSRoot、NetBIOSName 等),则说明 AD DS 已准备就绪。如果您看到“The term 'Get-ADDomain' is not recognized”或者 `InProgress`,亦或是 `Pending`,请再等待几分钟并重试。
### 部署 EKS 基础设施
```
cd ${REPO_DIR}/data-infra/
./setup.sh
```
### 配置 VPC 对等连接
```
cd ${REPO_DIR}/vpc-peering/
./setup.sh
```
### 创建 Hive Kerberos 服务主体
```
cd ${REPO_DIR}/microsoft-ad/
# 创建 HMS service principal
./manage-ad-service-principals.sh create hive "hive/hive-metastore-svc.hive-metastore.svc.cluster.local"
# 验证 service principal 是否已创建
./manage-ad-service-principals.sh list
```
### 部署 HMS
此步骤将构建一个用于 Hive Metastore 的 Docker 镜像。如果您没有使用 Docker Desktop 并且 `docker buildx version` 返回错误,请参阅 [Docker Buildx 设置](docs/docker-buildx-setup.md) 获取安装说明。
```
cd ${REPO_DIR}/hive-metastore/
./deploy.sh
```
## 测试解决方案
按照以下步骤测试与 HMS 的 Kerberos 认证 Spark 连接。
### 测试的前置条件
- 之前所有的设置脚本均已成功完成
- EKS 集群和 HMS 服务正在运行
- Kerberos keytab 已正确配置
### 创建 Spark 服务主体并生成配置
```
cd ${REPO_DIR}/microsoft-ad/
./manage-ad-service-principals.sh create spark "spark/analytics-team"
cd ${REPO_DIR}/spark-jobs/
./generate-spark-configs.sh --principal "spark/analytics-team@CORP.KERBEROS" --namespace emr
```
### 提交测试 Spark 作业
上一步骤会在 `spark-jobs/` 目录中生成 `spark-operator-job.yaml`。
```
cd ${REPO_DIR}/spark-jobs/
kubectl apply -f spark-operator-job.yaml
# 监控 job 执行
kubectl get sparkapplications -n emr -w
# 检查日志
kubectl logs spark-operator-kerberos-job-driver -n emr
```
### Kerberos 认证凭证
运行 Spark 作业后,日志应显示以下成功进行 Kerberos 认证的凭证:
**KDC 登录成功:**
```
HadoopDelegationTokenManager: Attempting to login to KDC using principal: spark/analytics-team@CORP.KERBEROS
HadoopDelegationTokenManager: Successfully logged into KDC.
```
**委托令牌处理:**
```
HadoopFSDelegationTokenProvider: getting token for: org.apache.hadoop.hive.ql.io.ProxyLocalFileSystem@32129dac with renewer spark/analytics-team@CORP.KERBEROS
```
**使用 Kerberos 连接 Hive Metastore:**
```
metastore: Trying to connect to metastore with URI thrift://hive-metastore-svc.hive-metastore.svc.cluster.local:9083
metastore: Opened a connection to metastore, current connections: 1
metastore: Connected to metastore.
```
**测试结果 - 全部通过:**
```
[PASS] Spark session created successfully
[PASS] Basic DataFrame operations successful
[PASS] Hive Metastore connection successful
=== All Kerberos tests completed successfully! ===
```
**数据库查询成功:**
```
Available databases:
+---------+
|namespace|
+---------+
| default|
+---------+
```
## 清理
要删除此解决方案创建的所有资源,请运行清理脚本。
```
cd ${REPO_DIR}/
./cleanup.sh
```
清理完成后,请通过检查 AWS CloudFormation 控制台中是否存在剩余堆栈来验证所有资源是否已被删除。
## 总结
此解决方案演示了在连接到 HMS 时,如何为运行在 Amazon EMR on EKS 上的 Apache Spark 工作负载实现 Kerberos 认证。通过使用 Microsoft Active Directory 作为密钥分发中心 (KDC) 并利用 VPC 对等连接实现安全的网络连通性,组织可以为其大数据工作负载实现企业级认证。
此方法的主要优势包括:
- 通过 Active Directory 集成实现集中式身份管理
- 使用行业标准 Kerberos 协议进行安全认证
- 可扩展的架构,将认证基础设施与计算工作负载分离开来
- 与现有的企业安全策略和合规性要求兼容
对于生产部署,请考虑实施额外的安全措施,例如 keytab 轮换、网络隔离以及对认证事件的全面监控。
## 贡献
有关更多信息,请参阅 [CONTRIBUTING](CONTRIBUTING.md#security-issue-notifications)。
## 许可证
本项目根据 [LICENSE](/LICENSE) 文件中指定的条款进行许可。
## 免责声明
此解决方案在 AWS 云中部署了开源软件。AWS 对任何开源软件的安全属性不作任何声明。在实施该解决方案之前,请根据您组织的安全最佳实践评估所有开源软件。客户应始终将其组织的安全最佳实践置于本代码中提供的任何指南之上。此解决方案旨在提供一般性指导,尚未针对您组织的特定需求进行量身定制。
标签:Amazon EKS, Amazon EMR, Amazon RDS, Apache Spark, AWS, DPI, EC2, EMR on EKS, Hive Metastore, HTTP, IaC, Kerberos认证, Microsoft Active Directory, Spark作业, 大数据分析, 大数据架构, 子域名突变, 容器编排, 数据目录, 模拟器, 请求拦截, 跨平台集成