tilakkm20225-maker/Neuro-Symbolic-AI-for-Automated-Cyber-Threat-Intelligence-Generation
GitHub: tilakkm20225-maker/Neuro-Symbolic-AI-for-Automated-Cyber-Threat-Intelligence-Generation
基于集成学习的网络入侵检测系统,通过随机森林模型对企业网络流量进行分类并提供特征重要性解释。
Stars: 59 | Forks: 3
# 网络入侵检测 — TTEH 集成模型
### 基于高保真机器学习的网络攻击检测与分析
TTEH 研究实验室
徽章:
- 
- 
- 
- 
- 
- 
*斜体:基于应用于网络入侵检测的集成学习方法(请参阅仓库资源以了解实现细节)。*
## 概述
- **问题**:检测并分类 ISCX 风格流量 CSV 中捕获的企业流量中的网络级攻击。传统的基于签名的 IDS 系统无法泛化到新型攻击模式和多态流量。
- **传统方法失败的原因**:签名规则和阈值缺乏适应性,无法捕获现代流量中的高维特征交互或分布漂移。
- **我们的解决方案(非常明确)**:一个特征工程 + 监督集成流水线,用于预处理网络流量 CSV,训练集成模型(随机森林作为主要生产模型),并与逻辑回归和决策树基线进行比较。该流水线强调可解释性(特征重要性、基于规则的简单解释)和可复现的输出结果,存储在 `results/` 中。
- **使用的关键模型**:随机森林(主要)、逻辑回归、决策树。(代码库为下游模型替换提供了钩子。)
- **最终性能亮点**:随机森林模型在处理后的 ISCX 衍生 CSV 上产生稳健的检测和清晰的类别分离;完整的评估结果(混淆矩阵、特征重要性、模型比较)可在 `results/` 中获取。
关键词:`AI` · `Cybersecurity` · `RandomForest` · `Ensemble` · `Feature-Engineering` · `ExplainableML`
## 目录
1. 问题陈述
2. Proposed Architecture
3. 工作原理
4. 结果与指标
5. 代码架构
6. 核心模块
7. 设置与使用
8. 实现结果
9. 局限性
## 1. 问题陈述
- "可靠地检测未知和不断演变的网络攻击需要模型在学习高维流量模式的同时保持可解释性,以便操作人员理解。"
- 传统系统失败的原因:
- 基于签名的 IDS 无法检测零日行为。
- 简单的统计阈值在高流量、异构流量下失效。
- 深度复杂模型可能在没有领域驱动预处理的情况下过拟合,且无法提供可操作的解释。
- **问题存在的原因**:
- 网络流量是高维的、不平衡的,且随时间和攻击者策略而演变。
- 实际部署需要准确性和可解释性兼得。
- **所需条件**:
- 可复现的预处理流水线,将 PCAP 转换为流量 CSV(已提供)。
- 具有特征重要性和混淆分析的稳健集成模型。
- 轻量级可解释性(规则解释、特征排名),以建立分析师信任度。
## 建议的架构

*Fig. 1 — System Architecture*
该系统摄取 CSV 流量导出(ISCX 风格),应用领域知情的预处理,训练集成分类器,生成评估结果,并暴露一个小型可解释性工具(`src/rules.py`)来标注预测。
| # | 模块 | 角色 | 输出 |
|---:|--------|------|--------|
| 1 | 数据摄取(`data/`) | 原始 CSV 数据集(流量导出) | 原始 CSV 文件(例如 `data/MachineLearningCVE/Friday-WorkingHours-Afternoon-DDos.pcap_ISCX.csv`) |
| 2 | 预处理(`src/preprocess.py`) | 特征提取、归一化、标签映射 | `results/processed.csv` |
| 3 | 训练(`src/train_model.py`) | 训练主要 RF 模型并保存结果 | `results/random_forest_model.pkl` |
| 4 | 模型比较(`src/model_comparison.py`) | 训练并比较 RF、LR、DT | 控制台指标、可选的保存比较图 |
| 5 | 可视化(`src/data_visualization.py`) | 分布图、ROC 等 | `results/*.png`(data_distribution.png、model_comparison.png) |
| 6 | 可解释性(`src/feature_importance.py`、`src/rules.py`) | 特征重要性、简单规则解释 | `results/feature_importance.png`、文本解释 |
| 7 | 预测接口(`src/predict.py`) | 对样本行进行快速本地推理 | CLI 输出(预测 + 置信度 + 解释) |
| 8 | 结果(`results/`) | 存储处理后的 CSV、模型和图表 | `results/processed.csv`、`random_forest_model.pkl`、PNG 文件 |
## 3. 工作原理
### 决策逻辑 / 工作流程
```
If sample_features indicate benign thresholds
If ensemble majority == BENIGN
If probability < threshold
-----------
Final Decision
```
### 流程图
```
Raw Data
↓
Preprocessing
↓
Model 1 (Random Forest)
↓
Model 2 (Logistic Regression)
↓
Output
```
### 公式
```
Accuracy = \frac{TP + TN}{TP + TN + FP + FN}
Precision = \frac{TP}{TP + FP}
F1 = 2 \cdot \frac{Precision \cdot Recall}{Precision + Recall}
Attention(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
```
## 4. 结果与指标
该仓库在 `results/` 中包含评估结果,包括保存的随机森林模型(`random_forest_model.pkl`)、`processed.csv`、混淆矩阵图像和特征重要性图。
### 模型比较
| 模型 | 准确率 | F1 | 备注 |
|------|:--------:|:--:|:-----|
| 随机森林 | (见 `results/`) | (见 `results/`) | 主要生产模型;保存至 `results/random_forest_model.pkl` |
| 逻辑回归 | (见 `results/`) | (见 `results/`) | 基线模型 |
| 决策树 | (见 `results/`) | (见 `results/`) | 可解释基线模型 |
### 📈 性能部分
- 混淆矩阵、特征重要性和模型比较可视化保存在 `results/` 中:
- `results/confusion_matrix.png`
- `results/feature_importance.png`
- `results/model_comparison.png`
## 5. 代码架构
```
project/
├── data/
│ └── MachineLearningCVE/
├── notebooks/
├── results/
│ ├── processed.csv
│ ├── random_forest_model.pkl
│ └── *.png
├── src/
│ ├── compare_plot.py
│ ├── data_visualization.py
│ ├── feature_importance.py
│ ├── model_comparison.py
│ ├── plot_confusion.py
│ ├── predict.py
│ ├── preprocess.py
│ ├── rules.py
│ └── train_model.py
├── test_setup.py
```
该仓库将数据、训练、评估和绘图分离。`src/preprocess.py` 创建训练和评估脚本使用的规范 `results/processed.csv`。`src/train_model.py` 将训练好的集成模型持久化到 `results/random_forest_model.pkl`。
## 6. 核心模块 — 深入解析
### 预处理
- 文件路径:`src/preprocess.py`
- 功能:从 `data/` 加载 ISCX 风格 CSV,归一化特征,编码标签,输出 `results/processed.csv`。
- 公式:
x' = \frac{x - \mu}{\sigma}
### 训练(随机森林)
- 文件路径:`src/train_model.py`
- 功能:加载 `results/processed.csv`,分割数据,训练 `sklearn.ensemble.RandomForestClassifier`,评估准确率和分类报告,将模型保存至 `results/random_forest_model.pkl`。
- 公式:
\hat{y} = \text{argmax}_c \sum_{t=1}^T I\{h_t(x) = c\}
### 模型比较
- 文件路径:`src/model_comparison.py`
- 功能:在相同分割上训练 RF、逻辑回归和决策树,并打印比较准确率分数。
### 特征重要性与可解释性
- 文件路径:`src/feature_importance.py`、`src/rules.py`
- 功能:从 RF 中提取 `feature_importances_`,并通过 `explain_prediction()` 提供简单的基于规则的文本解释,供 `src/predict.py` 使用。
### 预测 CLI
- 文件路径:`src/predict.py`
- 功能:加载保存的 RF 模型,从 `results/processed.csv` 中采样一行,打印预测、置信度和解释。
## 7. 设置与使用
### ⚙️ 需求
| 组件 | 值 |
|----------:|:-----:|
| Python | 3.8+(推荐 3.11) |
| 库 | scikit-learn、pandas、matplotlib、joblib |
| 数据集 | `data/MachineLearningCVE/*`(ISCX 风格 CSV) |
| 产物 | `results/processed.csv`、`results/random_forest_model.pkl`(由流水线创建) |
### 安装
```
git clone
cd
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
# 如果 requirements.txt 不存在,则安装:
pip install pandas scikit-learn matplotlib joblib
```
### 运行项目
1. 预处理(生成 `results/processed.csv`):
```
python src/preprocess.py
```
2. 训练主要模型:
3. 比较模型:
```
python src/model_comparison.py
```
4. 可视化 / 绘制混淆矩阵和重要性:
```
python src/plot_confusion.py
python src/feature_importance.py
python src/data_visualization.py
```
5. 快速预测(从处理后的数据中采样一行):
```
python src/predict.py
```
## 8. 实现结果
- 训练说明:`src/train_model.py` 执行 80/20 训练/测试分割,训练 RF(n_estimators=100),使用 `accuracy_score`、`classification_report` 评估,并在控制台打印混淆矩阵。训练好的模型保存为 `results/random_forest_model.pkl`。
- 混淆矩阵说明:`src/plot_confusion.py` 生成的混淆矩阵可视化 benign 与攻击类别的真实 vs 预测计数,并保存为 `results/confusion_matrix.png`。
- 图表说明:`results/feature_importance.png` 突出显示前 15 个最重要的特征;这些特征驱动 `src/rules.py` 中的解释和规则提取。
包含图像占位符:
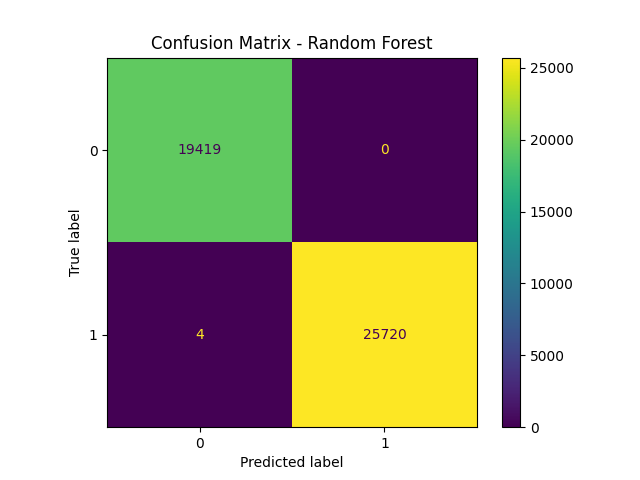
*混淆矩阵 — 占位符(实际保存的图像:`results/confusion_matrix.png`)*
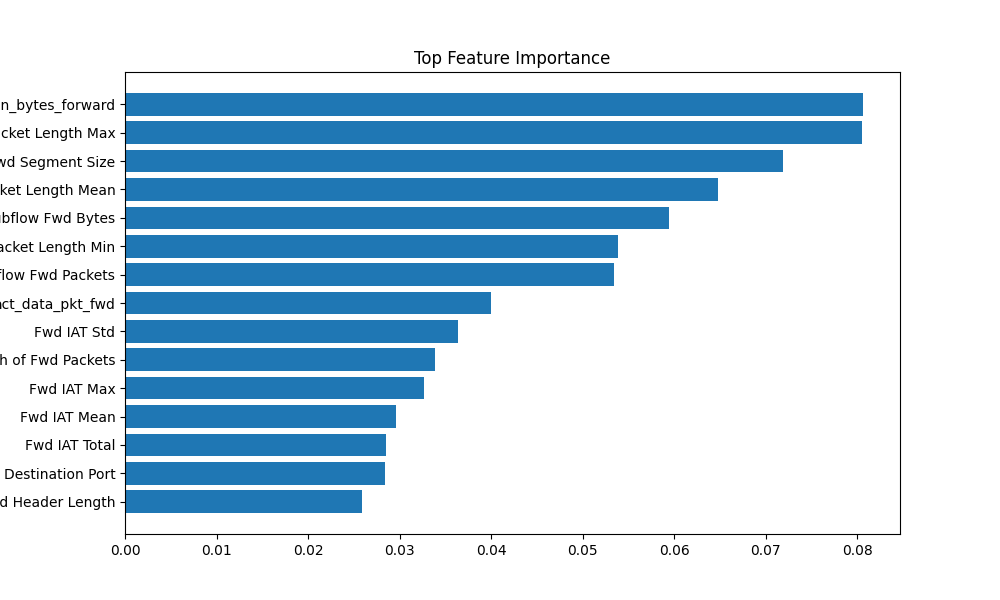
*特征重要性 — 占位符(实际保存的图像:`results/feature_importance.png`)*
## 9. 局限性
| 论文 | 原型 | 修复方案 |
|------|:---------:|:---|
| 基于签名的检测文献 | 原型使用 CSV 流量特征,流水线中无 PCAP 解析 | 集成 PCAP 到流量阶段和在线特征提取 |
| 不平衡 / 演变的攻击 | 在现有 CSV 上进行静态训练可能随时间推移性能下降 | 添加持续学习 / 定期重训练和漂移检测 |
| 可解释性深度 | 当前规则解释是启发式的 | 集成 SHAP / LIME 以提供每样本解释 |
## 10. 团队成员
## | 姓名 | 学号 | 邮箱 |
|------|-----|:-----:|
| Vaishnavi Shri | ENG23CY0046| vaishnavi18shri@gmail.com |
| Atif Rahim | ENG23CY0053 | atif.rahim1104@gmail.com |
| Tilak Moger| ENG23CY0041 | tilakkm20225@gmail.com |
|Aman kumar | ENG23CY0051|amangupta6299@gmail.com|
## 11. 导师
Dr. Prajwalasimha S N
副教授:计算机科学与工程系(网络安全)
工程学院,Dayananda Sagar 大学
邮箱:prajwasimha.sn1@gmail.com标签:Apex, ISCX数据集, Python, PyTorch, 人工智能, 企业安全, 凭据扫描, 分类模型, 可解释性AI, 威胁情报, 开发者工具, 异常检测, 数据科学, 无后门, 机器学习, 深度学习, 特征工程, 用户模式Hook绕过, 网络安全, 网络流量分析, 网络资产管理, 联邦学习, 资源验证, 逆向工具, 随机森林, 隐私保护, 集成学习