Oliwer1992/Azure-Fraud-Detection
GitHub: Oliwer1992/Azure-Fraud-Detection
这是一个基于 Azure 云构建的端到端金融欺诈检测系统,整合了数据工程、机器学习与可视化部署,旨在精准识别海量交易中的异常行为。
Stars: 0 | Forks: 0
# 🏦 Azure 端到端欺诈检测系统
## 📌 项目概述
本项目重点在于检测欺诈性金融交易,并识别海量金融数据集中隐藏的异常情况。主要目标是揭露非法活动,使金融机构能够采取主动的安全措施并最大限度地减少资金损失。
该项目包含四个主要阶段:**云数据工程**,用于在 Microsoft Azure 上构建自动化、可扩展的数据摄取管道;**探索性数据分析 (EDA)**,用于理解数据并发现关键的欺诈模式;**高级异常检测**,用于构建专注于成本敏感业务优化的预测解决方案;以及**模型部署**。
## 📊 数据集信息
本项目使用的数据来自 Kaggle 上提供的用于欺诈检测的合成金融数据集。
* **来源:** https://www.kaggle.com/datasets/ealaxi/paysim1
* **记录数:** 6362620
* **特征:** 10 列(9 个特征 + 1 个目标变量)
* **类别不平衡:** isFraud = 1: 8213 (~ 0,13 %) | isFraud = 0: 6354407 (~ 99,87 %)
## 🛠️ 技术栈与工具
* **语言:** Python, SQL
* **云与数据工程:** Azure Data Factory (ADF), Azure Data Lake Storage Gen2, Azure SQL Database
* **容器化与部署:** Docker, Streamlit
* **商业智能:** Power BI
* **数据处理与分析:** `pandas`
* **数据可视化:** `seaborn`, `matplotlib`
* **机器学习:** `scikit-learn`, `lightgbm`
## 📂 项目架构
该项目遵循 Medallion 架构(Bronze → Silver → Gold)以确保结构化和可扩展的数据处理。
### 1️⃣ 第一阶段:云数据工程
#### 🥉 Bronze 层 – 数据摄取
目前已实现原始数据摄取管道。
##### 架构
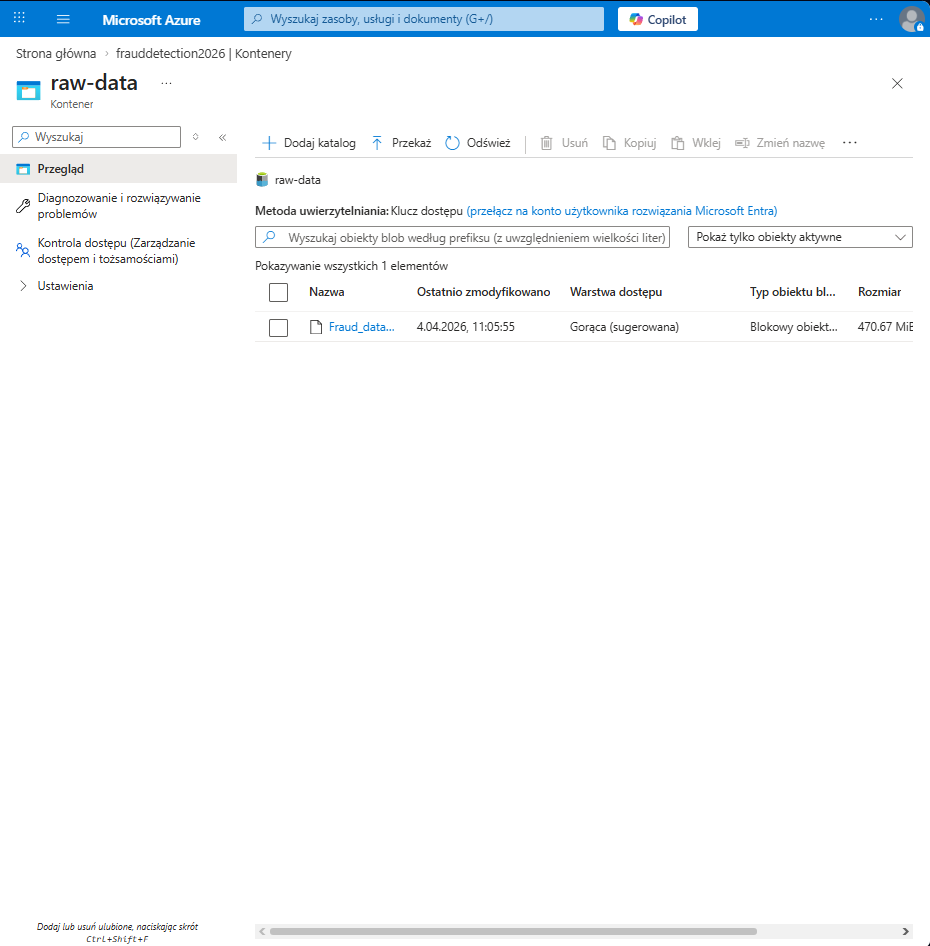
1. **数据湖:** 安全存储在 **Azure Data Lake Storage Gen2**(`raw-data` 容器)中。
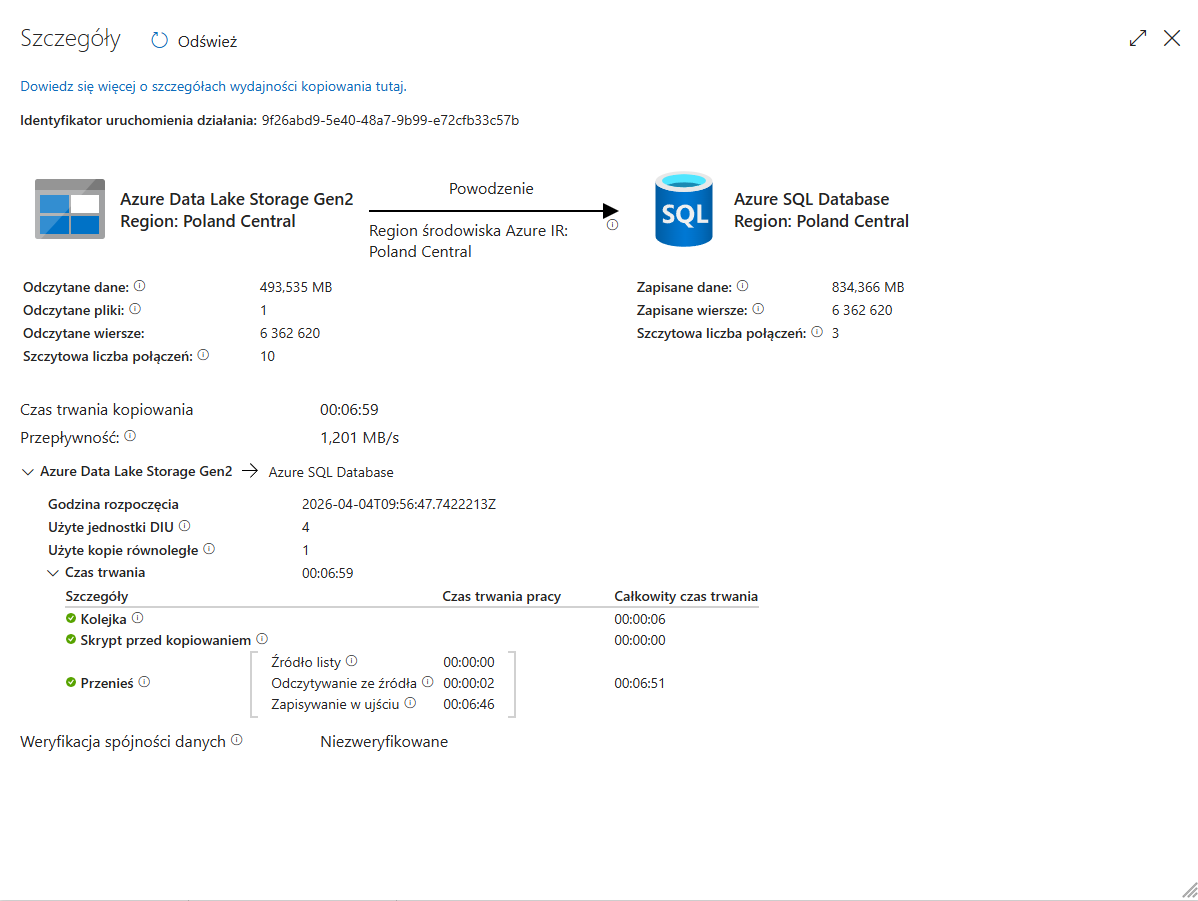
2. **编排:** 创建了 **Azure Data Factory (ADF)** 管道以动态读取 CSV 并自动创建架构。
3. **数据库:** 数据加载到 **Azure SQL Database**(为了成本优化采用 Serverless 层)。
**数据摄取证明**
**1. Azure Data Lake 中的原始数据:**
**2. ADF 管道成功:**
##### 数据验证 (SQL)
初始数据画像分析:
- 总记录数:6362620
- 欺诈案例:8213 (~ 0,13 %)
- 非欺诈案例:6354407 (~ 99,87 %)
##### SQL 验证脚本
所有数据画像查询存储在:
文件 `01_data_profiling.sql`
文件:`sql/01_data_profiling.sql`
该脚本包括:
- 行计数验证
- 架构检查
- 目标变量分布(类别不平衡)
- 基础数据预览
#### 🥈 Silver 层 – 数据筛选与特征工程
在此阶段,原始数据通过 SQL Views 转换为模型就绪的格式。这种方法确保了资源优化(无数据重复)和动态更新。
##### 关键转换:
1. **数据筛选:** 通过专门关注 `TRANSFER` 和 `CASH_OUT` 交易类型(大多数欺诈案例发生的地方),将数据集从 630 万条减少到约 277 万条记录。
2. **特征工程:** 创建了两个新的分析列以捕获账户余额中的数学差异:
- `errorBalanceOrig`:计算发送方的预期余额与实际余额之间的差额。
- `errorBalanceDest`:计算接收方的预期余额与实际余额之间的差额。
##### SQL 转换脚本
文件 `sql/02_feature_engineering.sql`
### 2️⃣ 第二阶段:探索性数据分析与 🥇 Gold 层准备
在通过 Azure SQL 生成的 **Silver 层** 基础上,本阶段利用 Python (`pandas`, `seaborn`) 进行深度 EDA 并构建 **Gold 层** —— 一个高度丰富、模型就绪的数据集。
**1. 数据清洗与验证:**
* 验证并更正了列数据类型以优化内存。
* 进行了数据质量检查(缺失值和重复项验证)以确保数据完整性。
**2. 探索性数据分析 (EDA):**
* **单变量与双变量分析:** 可视化单个特征的分布及其与 `isFraud` 目标变量的关系。
* **相关性分析:** 评估数值变量之间的线性关系,以识别潜在的多重共线性和预测能力。
**3. 基于 Python 的特征工程(Gold 层赋能者):**
为了完成机器学习的 Gold 层,设计了额外的预测特征以捕获行为和时间模式:
* **时间特征:** 从连续的 `step` 变量中提取 `hour` 和 `day_of_week`,以模拟 24/7 自动化欺诈的性质。
* **`accountDrained` 标志:** 一个二进制指示符(`1` 或 `0`),用于捕获完全清空发送方账户的交易(`newbalanceOrig == 0` 且 `amount > 0`)。
* **`isHighAmount` 标志:** 一个动态二进制标志,标记超过转账金额 95th 百分位的交易,有效地隔离高风险的资金流动。
### 3️⃣ 第三阶段:高级异常检测
此阶段重点在于寻找最有效的算法,以处理极端的类别不平衡(0.3% 的欺诈率)和高数据量(270 万条记录)。
**1. 模型选择与基准测试:**
* **Logistic Regression:** 作为线性可分性的基线。
* **Isolation Forest:** 作为一种无监督异常检测方法进行了测试,用于识别“远离”的异常值(证明在此特定业务案例中效果不足)。
* **LightGBM(最终选择):** 因其在大规模数据处理、高计算速度方面的卓越表现以及捕捉复杂非线性欺诈模式的能力而被选中。
**2. 多阶段训练策略:**
为了优化计算时间和本地硬件资源(RAM 限制),实施了三阶段训练方法:
* **基线(100% 数据):** 在默认参数上进行初始训练以建立性能基准。
* **快速优化(10% 子样本):** 在平衡的 10% 子样本上利用 `RandomizedSearchCV` 和 `StratifiedKFold` 进行高效的超参数探索,而不会导致内存过载。
* **最终优化(100% 数据):** 在完整的 270 万条数据集上执行第二轮大规模 `RandomizedSearchCV`。该算法自然选择了更深的架构(例如,`num_leaves: 151`, `max_depth: 8`, `class_weight: 'balanced'`),以充分利用海量数据而不会过拟合。
### 4️⃣ 第四阶段:模型部署
应用程序已成功容器化并配备了交互式 Web 界面,使其完全可复现并准备好上云。
* **容器化:** 将 ML 模型、Streamlit 应用程序和系统依赖项打包到一个独立的 Docker 容器中。
* **交互式 Web UI (Streamlit):** 开发了用户友好的前端,允许分析师输入交易详情并获得实时预测。
* **云就绪架构:** 配置了 `Dockerfile` 和 `requirements.txt` 以便无缝部署到任何容器托管服务。
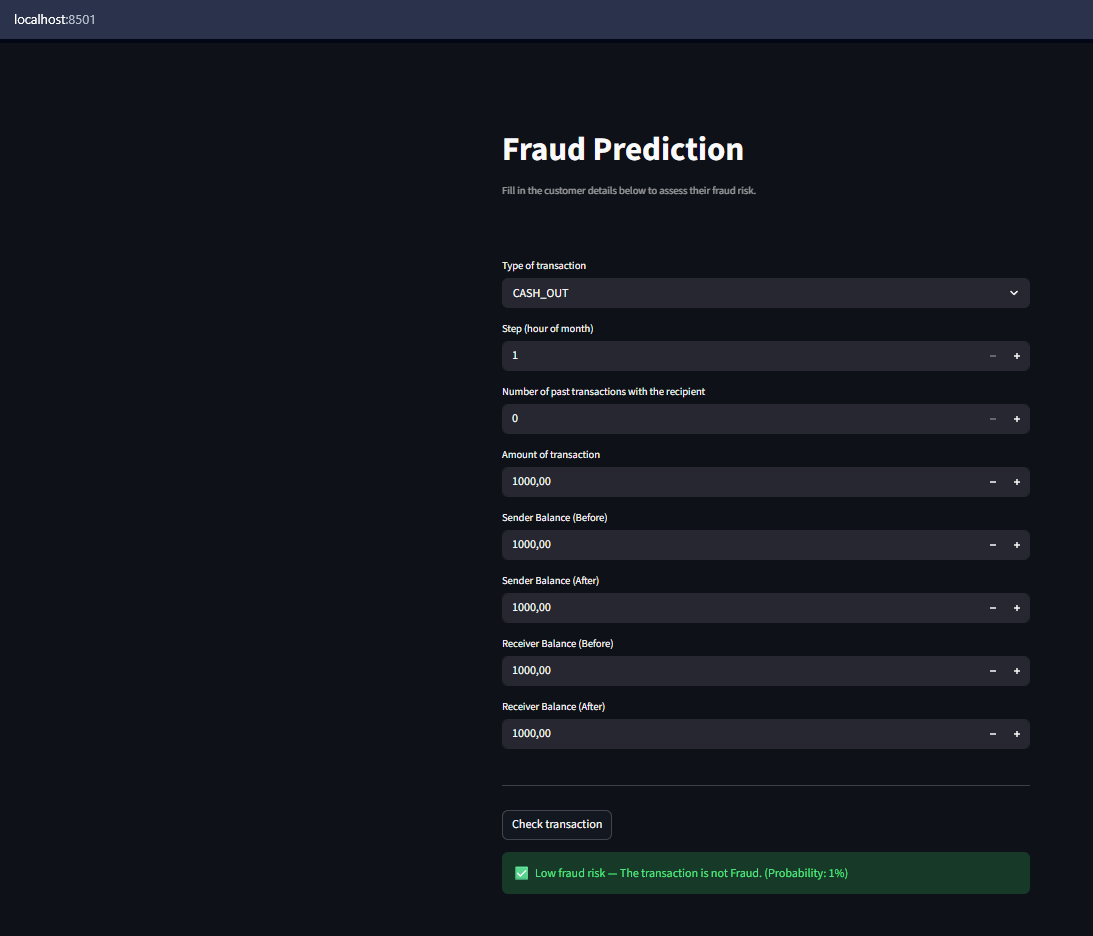
## 📈 结果
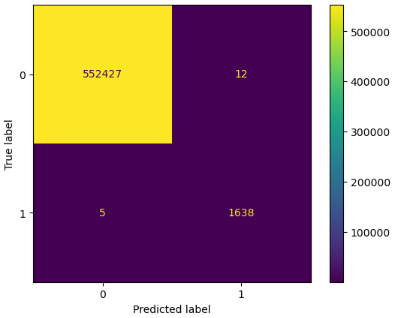
最终的 **LightGBM 分类器** 取得了卓越的结果,证明其在生产级欺诈检测方面非常可靠。
| 指标 | 得分 | 业务影响 |
| :--- | :--- | :--- |
| **Recall** | **99.70%** | 拦截了 **1,643 起欺诈中的 1,638 起**。 |
| **Precision** | **99.27%** | 在 55.4 万笔交易中只有 **12 次误报**。 |
| **F1-Score** | **0.9948** | 检测与用户摩擦之间的完美平衡。 |
| **PR-AUC** | **0.9981** | 在所有阈值下均具有出色的模型稳定性。 |
**性能分析:**
该模型展示了近乎完美的区分合法活动和欺诈活动的能力。通过优先考虑 **Recall**,系统仅漏掉 5 笔交易,从而最大限度地减少了资金损失,而高 **Precision** 确保了诚实客户几乎不会遇到任何阻碍(只有 12 个账户被错误标记)。
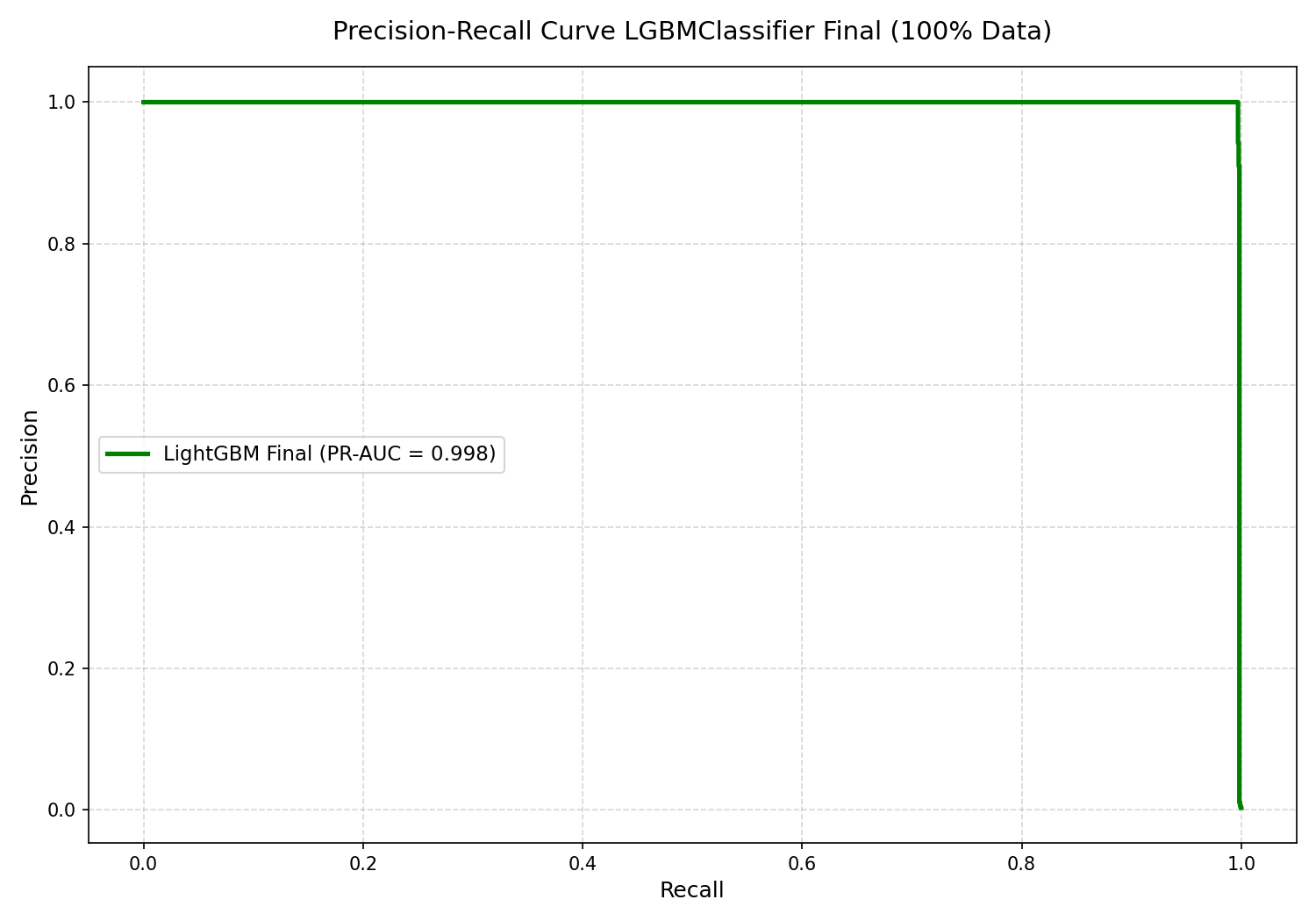.
## 🔍 主要发现
**1. 数据与业务洞察 (EDA):**
* **定向攻击与极端不平衡:** 欺诈仅占所有交易的 0.13%,并且仅发生在两种交易类型中:**CASH_OUT** 和 **TRANSFER**。
* **24/7 自动化操作:** 虽然合法用户的活动自然在上午 9 点到晚上 8 点之间达到高峰,但欺诈尝试在全天保持相对恒定。这种行为强烈表明使用了自动化僵尸网络或来自不同时区的协调攻击。
* **利用系统限制:** 交易金额分布显示,欺诈涉及的金额明显高于正常转账。值得注意的是,在 **10000000** 的标记处欺诈激增,这表明欺诈者试图系统地清空账户直至达到硬编码的系统阈值。
* **账目核对:** 追踪余额差异的特征工程(**errorBalanceOrig** 和 **errorBalanceDest**)被证明是近乎完美的类别分隔符。真实的交易总是在数学上完美核对。相反,欺诈事件系统地破坏了账目逻辑,在发送方和接收方两端都产生了大量未记录的余额。
**2. 模型洞察与性能:**
* **模型有效性:** 最终的 LightGBM 模型成功应对了极端的类别不平衡,达到了 **0.9981 的 PR-AUC 得分**,这得益于 **99.70% 的 Recall**。这确保了绝大多数欺诈尝试都被高精度地拦截。
* **关键欺诈指标:** 根据 Feature Importance 分析,模型严重依赖交易规模(**amount**)、发送方初始资金(**oldbalanceOrg**)、目标账户异常(**newbalanceDest**)以及目标账户的使用频率(**destTransactionCount**)。
通过将这些行为特征与检测到的账目错误相结合,模型有效地识别了“账户清空”模式以及新创建的“骡子”账户的使用。
## 📊 Power BI 安全运营中心 (SOC) 仪表板
项目的最后阶段是一个交互式 Power BI 仪表板,专为实时欺诈监控而设计。它过滤掉安全交易的噪音,严格专注于高风险领域,并通过六个关键可视化提供可行的洞察:
* **执行层 KPI:** 实时跟踪高风险交易量(277 万)、已确认的欺诈案例总数(8,213)以及整体欺诈率(0.30%)。
* **活动与欺诈尝试对比 (24小时):** 双轴图表,对比合法交易的自然昼夜节律(蓝色条形,中午达到高峰)与欺诈机器人平坦的 24/7 自动化活动(红线)。
* **按类型划分的欺诈分布:** 环形图,确认欺诈仅发生在 `CASH_OUT` 和 `TRANSFER` 交易类型中,且分割比例几乎正好是 50/50。
* **账目差异(平均缺失资金):** 攻击者利用的数学漏洞的可视化证明。欺诈交易(红色条形)在目标账户上产生巨大的平均账目错误,而合法交易(蓝色条形)则完美地核对为零。
* **异常检测(账户清空模式):** 散点图,将交易金额与原始余额进行映射。欺诈交易(红点)形成明显的视觉模式,证明了“账户清空”策略,即攻击者转账确切的全部余额。
* **顶级欺诈尝试(达到 10M 限制):** 目标矩阵,曝光了反复尝试清空正好 $10,000,000 的自动化脚本——即系统的硬编码阈值。
* **欺诈根本原因分析:** AI 驱动的分解树,按交易类型和一天中的时间细分欺诈案例,以便进行快速、交互式的钻取调查。
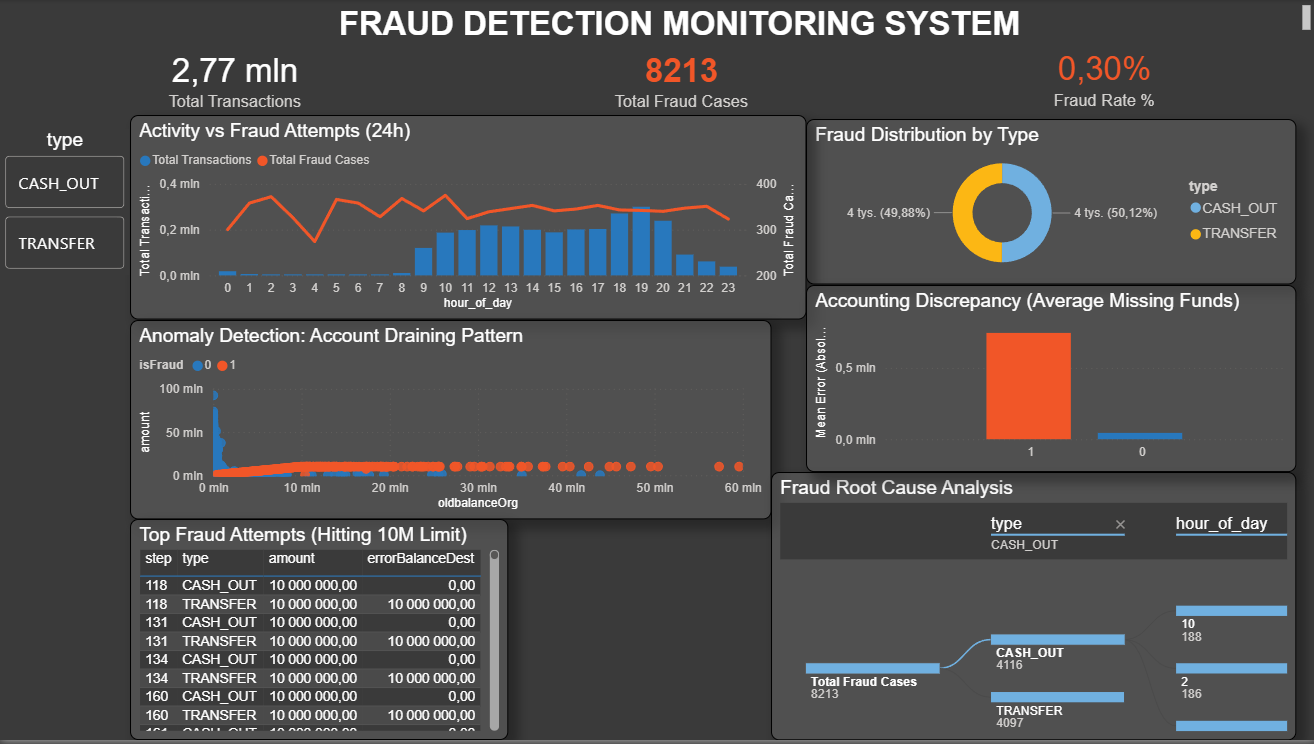
*(注意:`.pbit` 模板文件可在 `/reports` 文件夹中找到。它需要有效的 Azure 访问密钥才能填充实时数据)。*
## 🚀 如何运行应用程序
应用程序已完全容器化。要在本地运行交互式 Streamlit 仪表板,请按照以下步骤操作:
1. **克隆仓库:**
```
git clone https://github.com/Oliwer1992/Azure-Fraud-Detection.git
cd Azure-Fraud-Detection
```
2. **构建 Docker 镜像:**
```
docker build -t fraud-detection-app .
```
3. **运行容器:**
```
docker run -p 8501:8501 fraud-detection-app
```
4. **访问仪表板:**
打开 Web 浏览器并导航至:http://localhost:8501
标签:Apex, Azure, Azure Data Factory, Azure Data Lake Storage, Azure SQL Database, BI, Docker, EDA, ETL, Gradle集成, JavaCC, Kubernetes, LightGBM, Medallion架构, NIDS, Power BI, Python, Scikit-learn, SQL, Streamlit, 代码示例, 反欺诈, 多线程, 大数据, 安全防御评估, 容器化, 异常检测, 数据分层, 数据分析, 数据工程, 数据湖, 数据管道, 无后门, 机器学习, 模型部署, 欺诈检测, 监督学习, 目录扫描, 端到端项目, 类别不平衡, 系统审计, 访问控制, 请求拦截, 软件工程, 逆向工具, 金融科技, 风控