GunaPalanivel/Praxis
GitHub: GunaPalanivel/Praxis
Praxis 是一个 OpenEnv 兼容的强化学习环境,用于训练和评估 AI 智能体在真实 SRE 事件响应场景中的调查、诊断和修复能力。
Stars: 0 | Forks: 2
title: Praxis
emoji: 🔥
colorFrom: blue
colorTo: green
sdk: docker
app_port: 7860
tags:
- openenv
pinned: false
# Praxis - 作为 OpenEnv 的任务式事件响应
**一句话简介:** Praxis 是一个 OpenEnv 风格的**事件指挥中心**:agent 必须像值班工程师一样进行调查、计划和修复。奖励遵循**完整轨迹**(多步 `/step`),而不是单次侥幸的回答。
## 快速导航
| 章节 | 内容概述 |
| ----------------------------------------------------------------------- | ----------------------------------------------------------- |
| [链接与材料](#links--materials-judges-start-here) | HF Space, Hub, Trackio, Colab, 博客, 黑客松 |
| [生产合并检查清单 (13)](#production-merge-checklist-13-items) | 针对**真实** URL、任务和测试证据的门禁条目 |
| [问题背景](#the-problem) | 为什么事件响应是一个困难且值得训练的目标 |
| [环境运作方式](#how-the-environment-works) | API 契约、观察、奖励、确定性 |
| [结果](#results) | 任务矩阵、基线、GRPO 冒烟测试与生产 HF Jobs |
| [可视化证据](#visual-evidence) | Rollout 对比、GIF、奖励/损失曲线 |
| [训练与复现](#training--reproduction) | 脚本、HF Jobs 启动器、详细文档 |
| [快速开始](#quick-start-5-commands) | 克隆、安装、本地运行服务器 |
| [API 参考](#api-reference) | `/health`, `/reset`, `/step`, `/state` |
| [开发](#development) | 测试、Docker、目录布局 |
## 链接与材料(评委从这里开始)
**必需:** 实时 **Hugging Face Space**(托管环境)是调用训练器和 Colab 所使用的同一 HTTP API 的主要方式。
| 材料 | URL | 说明 |
| ------------------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------- |
| **实时环境 (HF Space)** | **[https://gp5901-praxis.hf.space](https://gp5901-praxis.hf.space)** | 兼容 OpenEnv 的 HTTP API (`/health`, `/reset`, `/step`, `/state`)。 |
| Space 仓库 | [huggingface.co/spaces/gp5901/praxis](https://huggingface.co/spaces/gp5901/praxis) | Dockerfile, secrets, Space 设置。 |
| Space / 仓库说明文档 (博客) | [Space 上的 Blog.MD](https://huggingface.co/spaces/gp5901/praxis/blob/main/Blog.MD) · [GitHub 镜像](https://github.com/GunaPalanivel/Praxis/blob/main/Blog.MD) | 面向评委和读者的叙述。 |
| 源代码 | [github.com/GunaPalanivel/Praxis](https://github.com/GunaPalanivel/Praxis) | Issues、PRs、CI。 |
| GRPO Colab | [在 Colab 中打开](https://colab.research.google.com/github/GunaPalanivel/Praxis/blob/main/praxis_grpo_colab.ipynb) | **GPU:** `uv run train_praxis_grpo.py` (TRL+Unsloth, 短时运行 + 绘图)。 **CPU:** 仅限冒烟测试。 |
| Colab 导出 (曲线, 日志) | [`colabresults/`](colabresults/README.md) | 包含 [`eval_checkpoints.json`](colabresults/eval_checkpoints.json)。 |
| **Trackio (训练指标)** | **[https://gp5901-trackio.hf.space/](https://gp5901-trackio.hf.space/)** | 实时 GRPO / trainer 指标 (HF 原生)。 |
| Trackio Space (仓库) | [huggingface.co/spaces/gp5901/trackio](https://huggingface.co/spaces/gp5901/trackio) | 支撑仪表盘的 Dataset 同步。 |
| **Hub 模型 (GRPO adapter + checkpoints)** | **[huggingface.co/gp5901/praxis-grpo-7b](https://huggingface.co/gp5901/praxis-grpo-7b)** | 来自 `HF_HUB_MODEL_ID` 训练运行的结果产物。 |
| 训练手册 | [`docs/training_links.md`](docs/training_links.md) | HF Jobs 命令、job ID、环境变量。 |
| 部署 | [`docs/deployment.md`](docs/deployment.md) | Docker / Space 检查清单。 |
| 黑客松背景 | [Meta PyTorch OpenEnv Hackathon × SST](https://www.scaler.com/school-of-technology/meta-pytorch-hackathon) | 活动链接。 |
### 必需部署(每次推送到 `main` 之后)
| 目标 | 谁负责更新 | 命令 / 操作 |
| ------ | -------------- | ----------------- |
| **实时 HF Space** (`gp5901-praxis`) | 拥有 Hub 写权限的维护者 | `uv run python scripts/sync_hf_praxis_space.py --ref origin/main` ([`scripts/README.md`](scripts/README.md))。使用 `HF_TOKEN` 或 `hf auth login`。等待 Space 构建完成(约 2 分钟),然后执行 `curl https://gp5901-praxis.hf.space/health` → `200`。 |
| **GRPO Colab** (徽章 URL) | 无 — 始终从 GitHub 读取 **`main`** | 评委在下一次点击 **在 Colab 中打开** 时会获取最新的 notebook;无需单独的发布步骤。 |
| **Trackio** (`gp5901-trackio`) | 训练运行 / HF Jobs | 设置 `TRACKIO_SPACE_ID`;指标从 trainer 同步,而不是通过 `sync_hf_praxis_space.py`。 |
| **Hub 模型** (`gp5901/praxis-grpo-7b`) | HF Jobs 引导 / 手动上传 | 训练完成后,由 `scripts/run_hf_grpo_job.py` 上传 `checkpoints/praxis-grpo/`;不属于 Space 同步的一部分。 |
在此分支上故意**不**使用 WandB(除非设置了 `WANDB_API_KEY`,否则 `_init_wandb` 是一个空操作)。生产环境遥测**仅限 Trackio**,通过 `TRACKIO_SPACE_ID` 配置(见 [`scripts/submit_hf_grpo_job.py`](scripts/submit_hf_grpo_job.py))。
## 生产合并检查清单(13 项)
这些行将**生产合并**门禁映射到**可观察的**证据(HF Space、Hub、HF Jobs、Trackio 或自动化测试)。门禁条目在 **`main`** 分支上满足;历史 **PR:** [https://github.com/GunaPalanivel/Praxis/pull/57](https://github.com/GunaPalanivel/Praxis/pull/57)。
| # | 要求 | 状态 | 真实世界证据 |
| --- | --------------------------------------------------------------------------------------------------------------------------------------------- | ------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| 1 | 在 **Hugging Face Spaces** 上托管的环境 | 完成 | [gp5901-praxis.hf.space](https://gp5901-praxis.hf.space) |
| 2 | 完整的 **GPU GRPO** 路径 (`max_steps=200`, `lr=1e-4`, `group_size=8`, 针对实时 Space 的 rollout) | 完成 | HF Job [69edd94dd2c8bd8662bcfb08](https://huggingface.co/jobs/gp5901/69edd94dd2c8bd8662bcfb08) 到达 TRL 训练循环;日志显示分步进度 + Trackio 同步 |
| 3 | **仅限 Trackio** 的训练透明度(无 WandB 依赖) | 完成 | [gp5901-trackio.hf.space](https://gp5901-trackio.hf.space/) + Space [gp5901/trackio](https://huggingface.co/spaces/gp5901/trackio) |
| 4 | checkpoints / manifest 的 **Hub** 持久化 | 完成 | [gp5901/praxis-grpo-7b](https://huggingface.co/gp5901/praxis-grpo-7b) |
| 5 | **`efficiency_bonus_max = 0.1`**(奖励信号未失效) | 完成 | `server/reward.py` 默认值;`pytest tests/` |
| 6 | 安全的 **默认 GRPO 学习率** (`1e-4`, 而非 `0.06`) | 完成 | `train_praxis_grpo.py` `parse_args` |
| 7 | 处于可靠范围内的冒烟测试 / Colab **学习率** (`1e-4` 等) | 完成 | `praxis_grpo_colab.ipynb` 训练单元格 → `uv run train_praxis_grpo.py … --learning-rate 1e-4` (而非旧版的 `TrainConfig` / `0.06`) |
| 8 | Colab 的 **`--group-size 8`** 与 trainer 对齐 | 完成 | 同一个 notebook 训练单元格 (`PRAXIS_COLAB_FULL=1` → 完全等同于 HF Jobs) |
| 9 | **HF Jobs** 引导 + **git clone race** 预检 | 完成 | [`scripts/run_hf_grpo_job.py`](scripts/run_hf_grpo_job.py), [`scripts/submit_hf_grpo_job.py`](scripts/submit_hf_grpo_job.py) |
| 10 | 为高 `/step` 量准备的 Rollout **Space** 容量 | 完成 | Space 硬件设置为 **cpu-upgrade** 以应对 rollout 负载 ([gp5901/praxis](https://huggingface.co/spaces/gp5901/praxis)) |
| 11 | 针对 Jobs 上 TRL + Unsloth 的 **PEP 723** trainer 依赖 (`mergekit`, `llm-blender`, 指定版本的 `transformers`, `trackio`, `httpx`, `datasets`, `peft`) | 完成 | `train_praxis_grpo.py` 中的 Header;对比失败的任务 [69edcfdad2c8bd8662bcfa07](https://huggingface.co/jobs/gp5901/69edcfdad2c8bd8662bcfa07) (`mergekit` 导入) |
| 12 | Unsloth 上 **GRPOConfig** 的有效性(**generation_batch_size** vs `num_generations`,基于 4-bit 的 **LoRA**) | 完成 | 同一个成功任务的日志 + `run_training` 中的代码 |
| 13 | **回归测试** | 完成 | `pytest tests/` — **500+ 个通过**(PR 前的本地门禁) |
## 问题背景
值班事件响应是一个**真实的生产工作流**,而不是一个单轮的问答基准测试。工程师会筛选警报、从日志和指标中提取证据、形成假设,然后才进行修复——通常是在时间紧迫和信息不完整的情况下进行的。
**Praxis** 将该工作流浓缩为一个**确定性的、可通过程序评分的** OpenEnv:相同的动作序列 ⇒ 相同的观察和奖励。这使得 RLHF / GRPO 训练和回归测试对于**学术研究**和**评委评审**而言都是值得信赖的。
## 环境运作方式
1. **`POST /reset`** — 可选的 JSON `{"task_name":"..."}` 用于选择场景(见下方的任务表)。
2. **`POST /step`** — 请求体 `{"command":"..."}`;模型 rollout 的每一个非空行都可以映射为一个步骤(trainer 契约),在 `train_praxis_grpo.py` 中受 `--max-turns` 限制。
3. **响应** — `observation`, `reward`, `done`, 以及 `info`(启用时包含评分规则细分)。
4. **`GET /state`** — episode 元数据;终止的 episode 可能会暴露 `final_score` (ADR-20) 作为标量训练标签。
奖励是按步骤计算的、可组合的评分规则,位于 **`server/reward.py`** 中,经过了截断和塑造,使得调查、正确的诊断和有证据支持的修复得分高于盲目猜测或过早的升级上报。
### 动作空间(模板)
| 命令模板 | 目的 |
| ----------------------------------------------- | ----------------------- |
| `query_logs service= timerange=m` | 服务日志 |
| `check_metrics service= metric=` | 指标 |
| `check_deps service=` | 依赖图 |
| `check_config service=` | 配置 / 部署变更 |
| `check_runbook service=` | Runbook 指南 |
| `diagnose root_cause=` | 声明根本原因 |
| `restart_service service=` | 修复 |
| `rollback_deploy service=` | 回滚 |
| `scale_resource service= resource=` | 扩缩容 |
| `kill_query service= query_id=` | 停止失控查询 |
| `escalate reason=` | 带证据的上报 |
有效的示例包括 `error_rate`, `latency_p95`, `connections`, `memory`, `cpu`, 和 `resolution_failures`。
### Observation payload(概览)
| 字段 | 含义 |
| ---------------------- | --------------------------- |
| `alert_summary` | 事件摘要 |
| `system_status` | 各服务健康状态 |
| `investigation_result` | 最新动作结果 |
| `available_commands` | agent 可用的模板 |
| `time_elapsed_minutes` | 模拟时间 |
| `severity` | `P0`–`P3` |
| `services_affected` | 不健康的服务 |
| `step_number` | 步骤索引 |
### 架构
```
flowchart LR
subgraph Clients[Clients]
TR[train_praxis_grpo.py GRPOTrainer]
AG[Agent or inference.py]
end
B[FastAPI server]
C[PraxisEnvironment]
D[Command parser]
E[Scenarios]
F[Reward engine]
TR -->|HTTPS /reset /step| B
AG --> B
B --> C
C --> D
C --> E
E --> F
F --> C
C --> G[Observation + reward + done]
G --> TR
G --> AG
```
## 结果
### 任务目录
| 任务 | 难度 | 严重程度 | 最大步数 | 场景摘要 | 最优路径得分 |
| ---------------------- | ---------- | -------- | --------- | ------------------------------------------------ | -----------------: |
| `single-service-alert` | 简单 | P2 | 15 | 错误的 DB 主机部署配置导致认证失败 | 0.63 |
| `ambiguous-incident` | 中等 | P2 | 25 | 间歇性多服务故障;DNS / 基础设施证据 | 0.71 |
| `cascading-failure` | 困难 | P1 | 20 | 失控查询耗尽 DB 连接池 | 0.458 |
| `memory-leak` | 困难 | P2 | 25 | 批处理配置导致 Worker OOM | 0.475 |
`POST /reset` 接受别名:`easy` → `single-service-alert`,`medium` → `ambiguous-incident`,`hard` → `cascading-failure`。
### 基线与快照
| 切片 | 任务 | 平均分 | 说明 |
| ---------------------------------------------------------------------------- | -------------------- | ---------- | ----------------------------------------------------------------- |
| 推理快照 (2026-04-26, `inference.py --model random`, 本地服务器) | single-service-alert | 0.122 | 随机单次抽取 |
| 同上 | ambiguous-incident | 0.010 | |
| 同上 | cascading-failure | 0.441 | |
| 同上 | memory-leak | 0.010 | |
| 同上 | **平均(4 个任务)** | **0.146** | |
| 实时 Space (Qwen2.5-72B, 2026-04-10 拉取) | single-service-alert | 0.092 | 步数较少;见 [训练演进](docs/training_evolution.md) |
| 同上 | cascading-failure | 0.041 | |
| 同上 | ambiguous-incident | 0.020 | |
| 同上 | memory-leak | 0.095 | |
| 同上 | 平均 | 0.062 | |
### GRPO 冒烟测试 vs 生产 HF Jobs
| 证据类型 | 位置 | 摘要 |
| ------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------- |
| 冒烟 GRPO (80 ep, 旧版 Colab 路径) | [`colabresults/eval_checkpoints.json`](colabresults/eval_checkpoints.json) | 在 **single-service-alert** 上提升最明显;其他任务需要更长的 GPU GRPO—见 JSON `notes`。 |
| 生产栈验证 | HF Job [69edd94dd2c8bd8662bcfb08](https://huggingface.co/jobs/gp5901/69edd94dd2c8bd8662bcfb08) + [Trackio](https://gp5901-trackio.hf.space/) + [Hub](https://huggingface.co/gp5901/praxis-grpo-7b) | Unsloth 4-bit + LoRA, `GRPOTrainer`, 200 `max_steps`, `lr=1e-4`, `group_size=8`。 |
| 失败的导入(已修复) | HF Job [69edcfdad2c8bd8662bcfa07](https://huggingface.co/jobs/gp5901/69edcfdad2c8bd8662bcfa07) | PEP 723 环境中缺少 `mergekit`;已在 `train_praxis_grpo.py` 的 PEP 723 header 中修复。 |
**各任务训练后与基线对比**(均值来自 [`colabresults/eval_checkpoints.json`](colabresults/eval_checkpoints.json): 80 次 smoke GRPO episodes, 旧版 Colab 路径;详见该文件的 `config` 和 `notes`)。
| 任务 | 基线 | 训练后 | Δ |
| -------------------- | ---------: | ---------: | ----------: |
| single-service-alert | 0.0626 | 0.1010 | +0.0384 |
| ambiguous-incident | 0.0283 | 0.0187 | -0.0096 |
| cascading-failure | 0.0422 | 0.0389 | -0.0033 |
| memory-leak | 0.1350 | 0.1183 | -0.0167 |
| **平均** | **0.0670** | **0.0692** | **+0.0022** |
## 可视化证据
| 资产 | 文件 | 作用 |
| ------------------------ | ---------------------------------------------------------------------- | ----------------------------------- |
| Rollout 对比 (静态) | [`docs/figures/rollout_compare.png`](docs/figures/rollout_compare.png) | 基线与训练后在一幅图表中对比 |
| 动图 (8s 循环) | [`docs/demo.gif`](docs/demo.gif) | 与图表相同的内容 |
| 奖励曲线 | [`docs/figures/reward_curve.png`](docs/figures/reward_curve.png) | 平均奖励与参考线对比 |
| 损失曲线 | [`docs/figures/loss_curve.png`](docs/figures/loss_curve.png) | 训练 loss 附图 |
| 叙述 | [`docs/training_evolution.md`](docs/training_evolution.md) | 黑客松期间分数如何变化 |
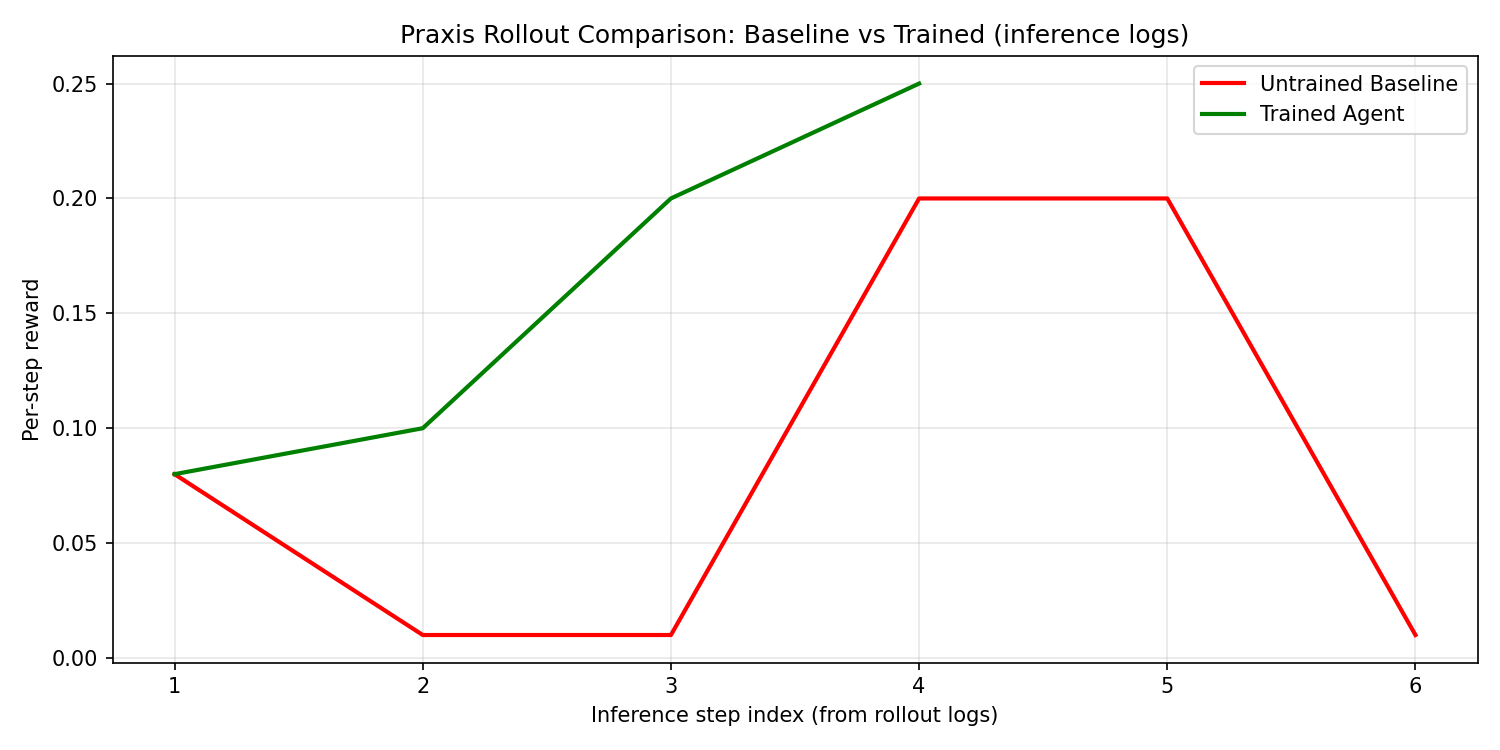
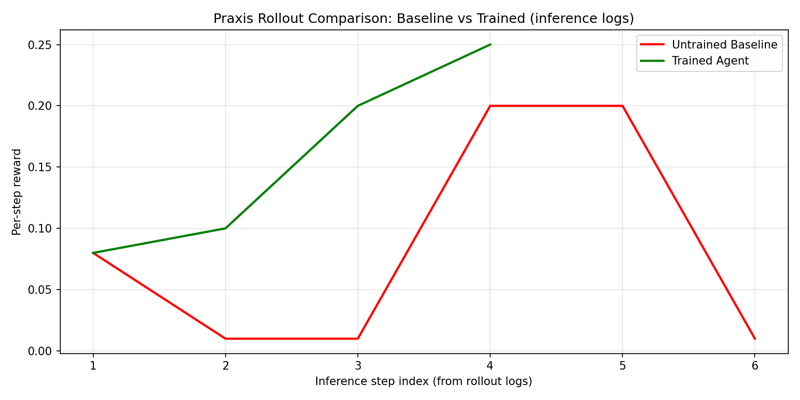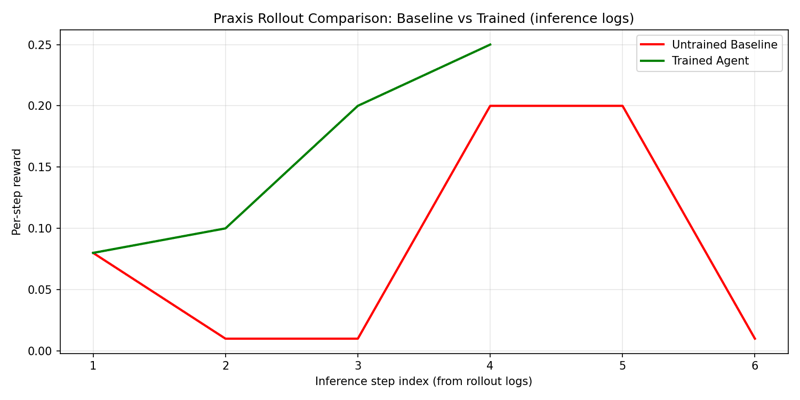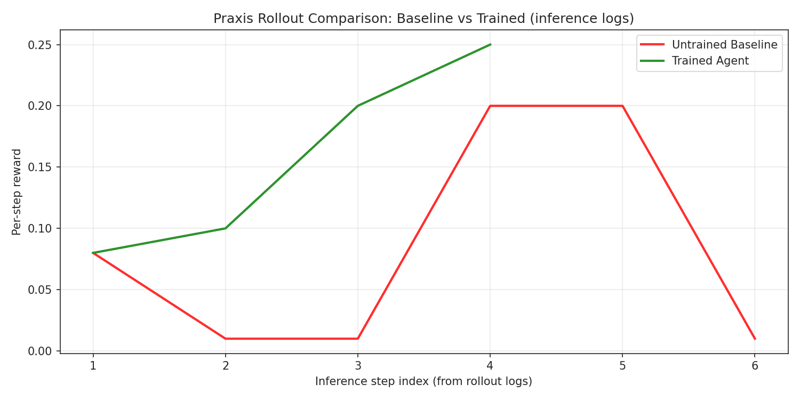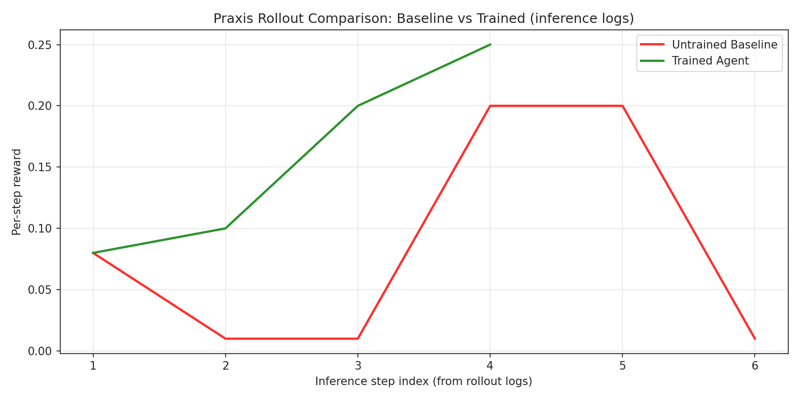
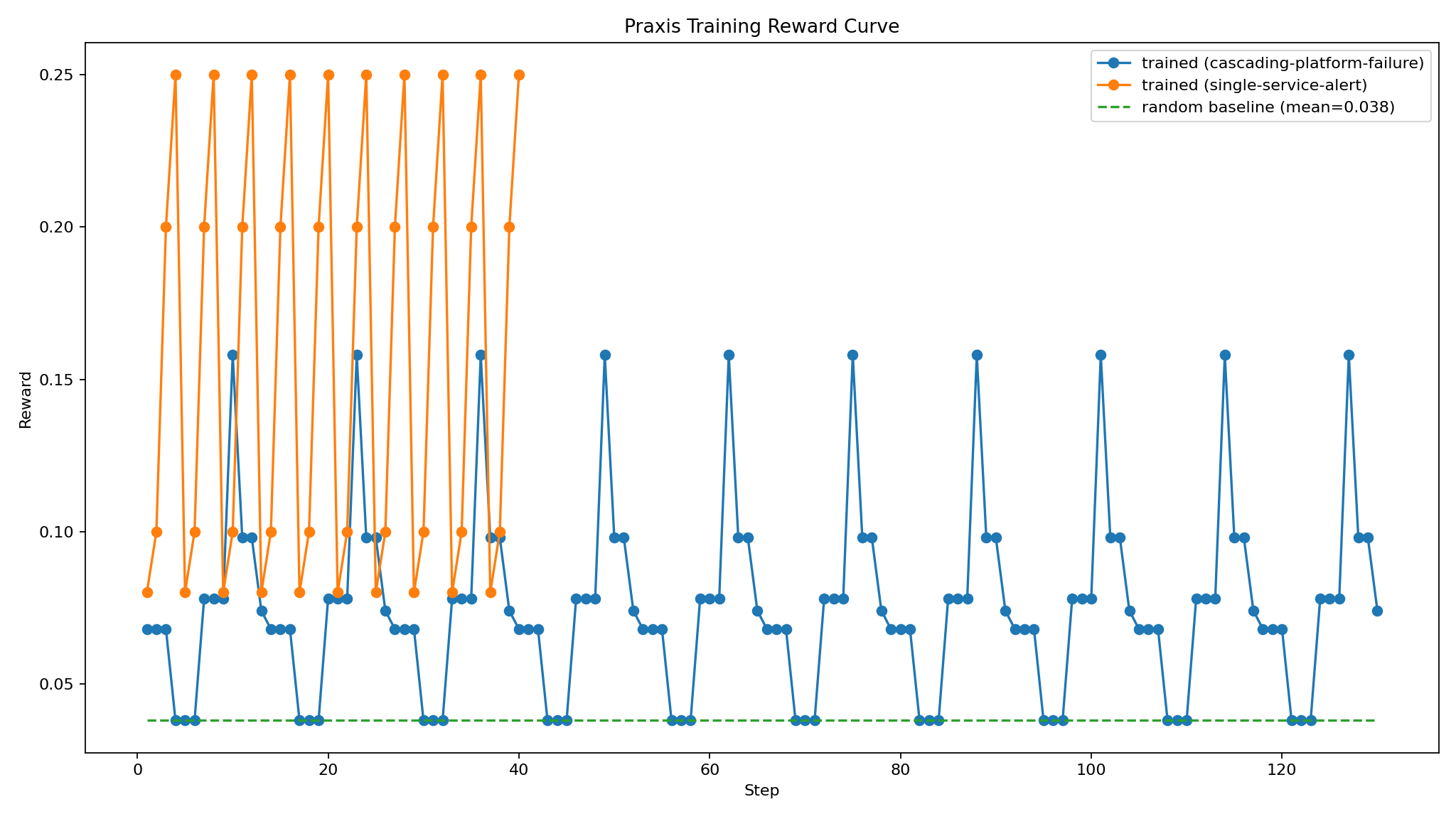
## 训练与复现
**TRL (`train_praxis_grpo.py`, 非 smoke 模式):** GRPO 的 `reward_func` 会为每次模型补全运行一个**轨迹**:每个 dataset 行执行一次 `reset`,然后为每个非空输出行执行一次 `/step`(有序,受 `--max-turns` 限制),除非模型只输出一行(单步)。标量标签在 episode 终止时优先采用服务器在 `/state` 上的 **`final_score`**;否则采用每步奖励的平均值。对于生产环境,请将训练指向**实时 Space** URL;本地运行可以自动启动 uvicorn(stderr 输出到临时文件中— 见 [`docs/deployment.md`](docs/deployment.md))。
| 操作 | 命令 / 文档 |
| ---------------- | ---------------------------------------------------------------------------------------------------------------------------------------------- |
| HF Jobs 一次性任务 | `python scripts/submit_hf_grpo_job.py --hub-model-id gp5901/praxis-grpo-7b --trackio-space-id gp5901/trackio --flavor a10g-large --timeout 5h` |
| 启动器详情 | [`scripts/README.md`](scripts/README.md) |
| 产物索引 | [`docs/training_links.md`](docs/training_links.md) |
## 快速开始(5 条命令)
```
git clone https://github.com/GunaPalanivel/Praxis.git
cd Praxis
pip install -e ".[dev]"
python -m uvicorn server.app:app --host 0.0.0.0 --port 7860
curl http://localhost:7860/health
```
可选的冒烟检查:
```
curl http://localhost:7860/tasks
curl -X POST http://localhost:7860/reset
curl -X POST http://localhost:7860/reset -H "Content-Type: application/json" -d '{}'
curl -X POST http://localhost:7860/reset -H "Content-Type: application/json" -d '{"task_name":"single-service-alert"}'
curl -X POST http://localhost:7860/step -H "Content-Type: application/json" -d '{"command":"query_logs service=auth timerange=5m"}'
```
## 奖励函数(摘要)
- **调查** 命中相关证据 → 小幅正向信号。
- **正确诊断** → 较大幅度的正向奖励。
- **正确修复或有证据支持的上报** → 最高奖励。
- **错误诊断 / 错误修复 / 过早上报** → 扣分后接近于零。
- **重复动作** → 受到惩罚(减少 50%)。
- **步骤成本** → 中/高难度任务会施加每步压力。
- **`check_runbook`** → 小额机制性奖励。
- **`efficiency_bonus_max`** 在默认策略中为 **0.1**(效率信号已激活)。
## 推理输出契约
`inference.py` 输出供评委解析的结构化行:
```
[START] task= env= model=
[STEP] step= action= reward=<0.00> done= error=
[END] success= steps= score=<0.000> rewards=
```
每步奖励被截断至 `[0.01, 0.99]`;任务得分为步骤奖励的平均值,并截断至 `[0.001, 0.999]`。
## 开发
```
pip install -e ".[dev]"
pytest tests/ -v --tb=short
openenv validate
```
Docker:
```
docker build -t praxis-env:latest .
docker run --rm -p 7860:7860 --name praxis-env praxis-env:latest
```
新场景:在 `praxis_env/scenarios/` 下实现,注册,并添加 `tests/`。
## API 参考
| 端点 | 方法 | 请求 | 响应 |
| --------- | ------ | ------------------------------ | --------------------------------------- |
| `/health` | GET | — | 状态、版本、任务 |
| `/tasks` | GET | — | 任务列表 |
| `/reset` | POST | 可选 `{"task_name":"..."}` | 初始观察 |
| `/step` | POST | `{"command":"..."}` | `observation`, `reward`, `done`, `info` |
| `/state` | GET | — | episode 元数据 |
`observation` 包括 `alert_summary`, `system_status`, `investigation_result`, `available_commands`, `time_elapsed_minutes`, `severity`, `services_affected`, `step_number`。
## 部署
根目录 **Dockerfile**,端口 **7860**,Hugging Face Docker Spaces — 完整检查清单见 [`docs/deployment.md`](docs/deployment.md)。
## 仓库布局
| 路径 | 作用 |
| ------------- | ------------------------------------------------- |
| `praxis_env/` | 模型、客户端、场景 |
| `server/` | FastAPI 应用、解析器、编排、奖励引擎 |
| `tests/` | 场景、奖励、API、推理测试 |
| `docs/` | 技术文档与图表 |
| `idea/` | 规划笔记(未作为产品 API 发布) |
标签:Python脚本, 请求拦截, 逆向工具