alvenyuka/Fraud-Detection-System
GitHub: alvenyuka/Fraud-Detection-System
这是一个基于XGBoost的移动支付欺诈检测系统,以高精度低误报识别欺诈交易,解决极端不平衡数据下的分类问题。
Stars: 0 | Forks: 0
# 欺诈检测系统
[](LICENSE)
[](https://www.python.org/)
[](https://xgboost.readthedocs.io/)
[](#结果)
[](#校准)
[](https://jupyter.org/)

## 为什么?
移动支付欺诈是一个精度问题,而非准确率问题。PaySim数据集的正样本比例为0.13%;一个总是预测“非欺诈”的模型能获得99.87%的准确率,但抓不到任何欺诈。生产环境中的欺诈运营流程会在触发标记时冻结客户资金,因此误报会直接带来信任和合规成本。本仓库构建了一个诚实面对这种权衡的分类器:精度维持在99%以上,并且在基于严格时间划分的测试集上评估模型——避免了未来信息泄露。
## 特性
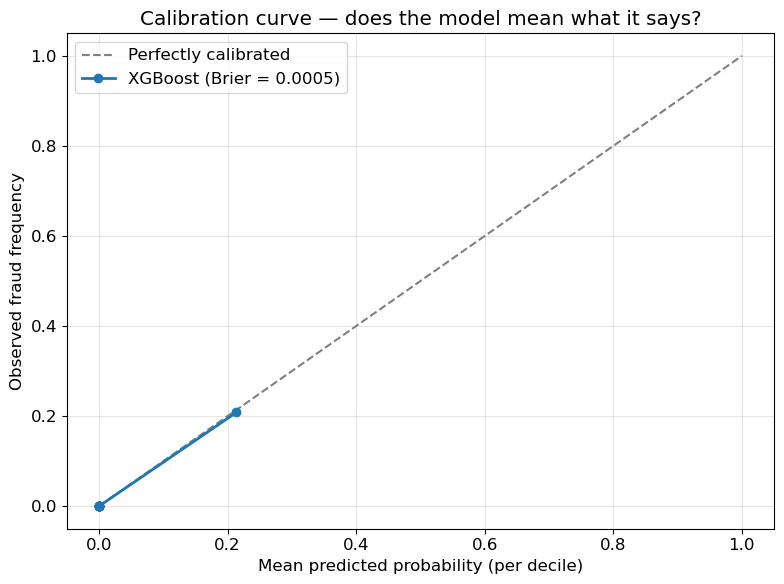
- 📈 **XGBoost分类器**,校准后的Brier分数为0.0005(随机基线约为0.0204)
- 🎯 在部署操作点(阈值0.9989)下达到**99.11%的精度/96.88%的召回率**
- ⏱️ **基于时间的训练/测试划分**(在步骤490处)——无随机打乱,无信息泄露
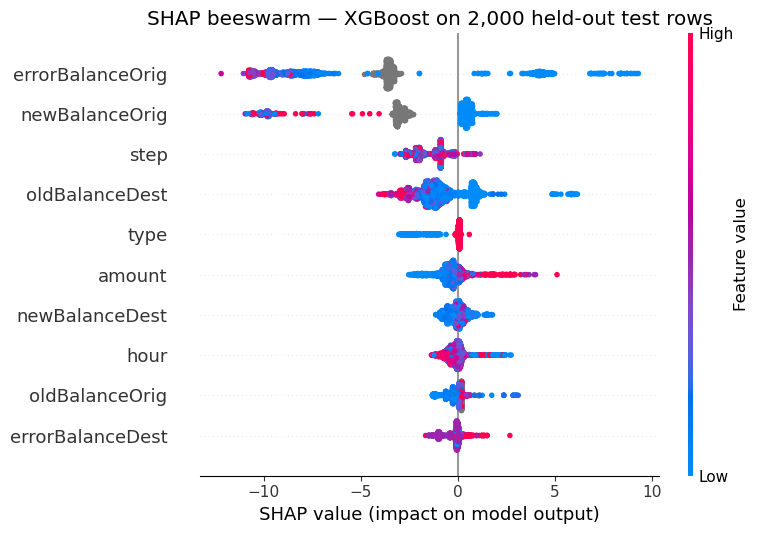
- 🧮 **余额差异特征工程**,承载了约85%的预测信号
- 🔬 **SHAP归因分析**,用于单次预测的解释
- 📊 **五模型比较**(随机森林,堆叠,XGBoost,逻辑回归,LightGBM),使用相同特征
- ✅ **可复现的流水线**,在一个Jupyter notebook中完成,具有确定性的随机种子
## 技术栈
| 层级 | 工具 |
|---|---|
| 语言 | Python 3.10+ |
| 核心数据处理 | `numpy`, `pandas` |
| 建模 | `scikit-learn`, `xgboost`, `lightgbm`, `imbalanced-learn` |
| 可解释性 | `shap` |
| 绘图 | `matplotlib`, `seaborn`, `plotly` |
| 环境 | `jupyter`, `jupyterlab` |
## 安装
```
git clone https://github.com/alvenyuka/Fraud-Detection-System.git
cd Fraud-Detection-System
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install -r requirements.txt
```
从[Kaggle](https://www.kaggle.com/datasets/ealaxi/paysim1)下载PaySim数据集,并将`PS_20174392719_1491204439457_log.csv`文件放置在项目根目录。
## 用法
```
jupyter lab "Fraud Detection System.ipynb"
```
该notebook从头到尾运行:数据加载 → 基于时间的划分 → 特征工程 → 五模型训练 → 校准 → SHAP归因。本README中的每张图都从notebook的单元格重新生成——无隐藏状态。
## 数据集
**PaySim** — 一个基于真实非洲移动支付交易日志构建的模拟器,已进行匿名化和时间对齐处理。包含六种交易类型(`CASH_IN`、`CASH_OUT`、`DEBIT`、`PAYMENT`、`TRANSFER`,以及内部`M*`商户行)。每条交易包含一个来源和目标账户、交易前后的余额快照,以及一个`isFraud`标签。
| 属性 | 值 |
|---|---|
| 行数 | 6,362,620 |
| 时间跨度 | 31天(744个时间步) |
| 欺诈率 | 0.1291% |
| 有效欺诈类型 | 仅`TRANSFER`、`CASH_OUT` |
| 过滤后数据集 | 2,770,409行(减少56.5%,正样本零损失) |
## 方法论
### 评估策略
评估采用**在步骤490处的严格时间划分**(约占模拟时间跨度的66%)。随机划分会将未来信息泄露到训练集,并虚高PR-AUC,因为欺诈模式在整个数据集中是演变的。生产环境的欺诈模型必须基于过去的证据预测未来的交易,评估方法也必须与此匹配。
| 划分 | 步骤 | 行数 | 欺诈率 |
|---|---|---|---|
| 训练集 | 1–490 | 2,638,273 | 0.207% |
| 测试集 | 491–743 | 132,136 | 2.084% |
### 为什么使用PR-AUC,而不是准确率或ROC-AUC
欺诈率为0.13%,因此一个对每笔交易都预测为“非欺诈”的模型准确率可达99.87%,但抓不到任何欺诈。ROC-AUC同样会被虚高,因为无论欺诈类别的表现如何,真正的负样本数量主导了曲线。**PR-AUC是唯一完全基于正样本类别内精度/召回率权衡的指标**,也是在极端不平衡情况下衡量欺诈检测性能的唯一诚实指标。
### 操作点选择
欺诈运营流程会在触发标记时冻结客户资金,因此误报会直接带来信任和合规成本。部署相关的关键问题是**在精度维持在99%或以上的前提下,能达到的最高召回率是多少**,而不是在真空中最大化F1分数的阈值。对于XGBoost,这个点位于概率阈值0.9989。
### 校准
可部署的模型相对于随机基线的Brier分数(约0.0204)进行了校准。校准后的概率很重要,因为下游的欺诈运营团队会根据分数设定阈值,而未经校准的树模型输出无法解释为概率。
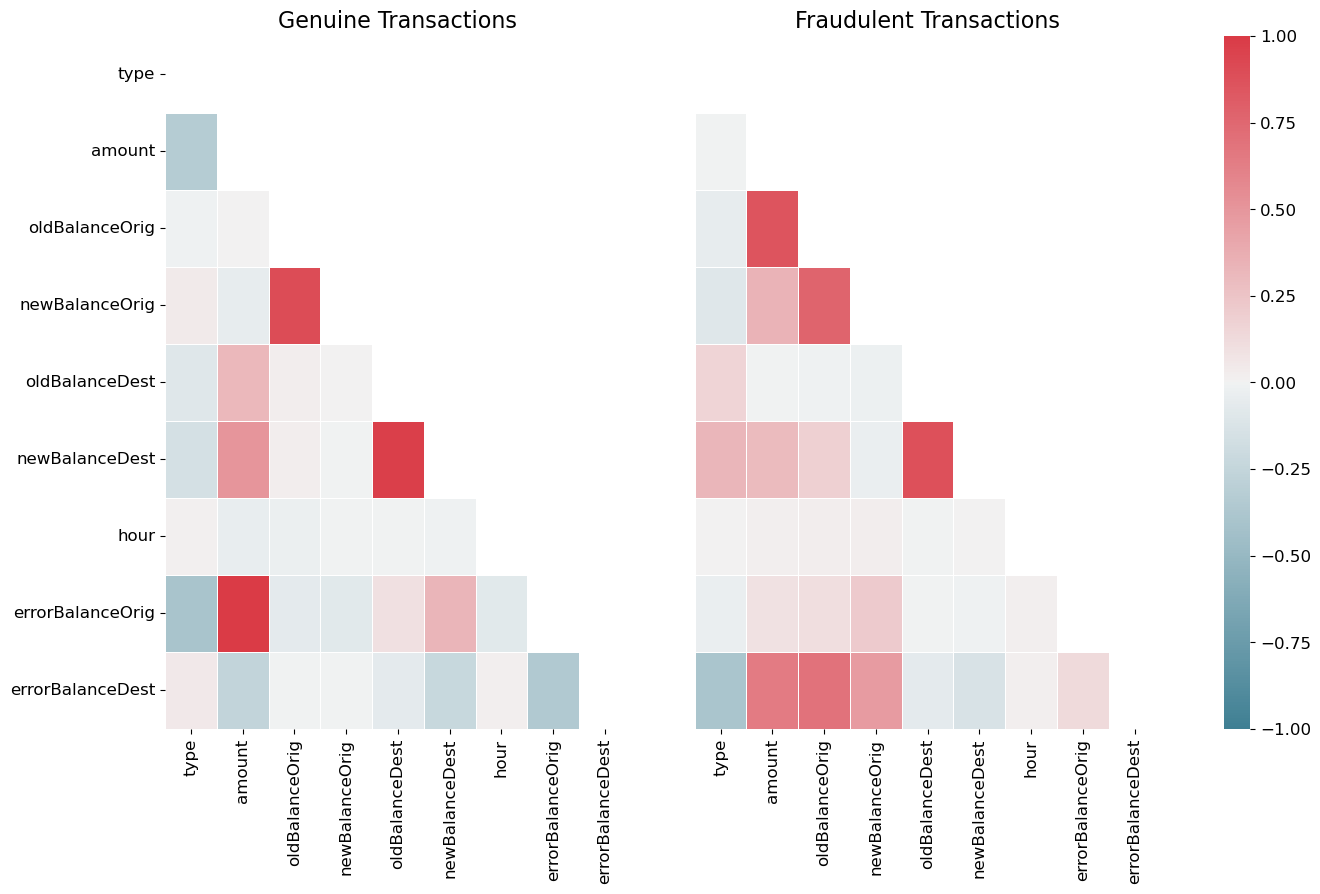
### 特征工程 — 余额差异逻辑
原始的交易`金额`无法区分欺诈和正常交易;两者分布有显著重叠。判别性信号存在于**预期与实际交易后余额的偏差**中。对于合法交易,会计恒等式成立;对于欺诈交易,则不成立。将这种差异作为显式特征进行工程化,驱动了模型大约85%的预测提升。
## 结果
### 核心性能
| 指标 | 值 |
|---|---|
| 模型 | XGBoost(已校准) |
| 精度 | **99.11%** |
| 召回率 | **96.88%** |
| F1 | 0.980 |
| PR-AUC | 0.9987 |
| ROC-AUC | 1.0000 |
| Brier分数 | 0.0005 |
| 操作阈值 | 0.9989 |
| 测试窗口 | 步骤491–743(132,136笔交易,2,754个正样本) |
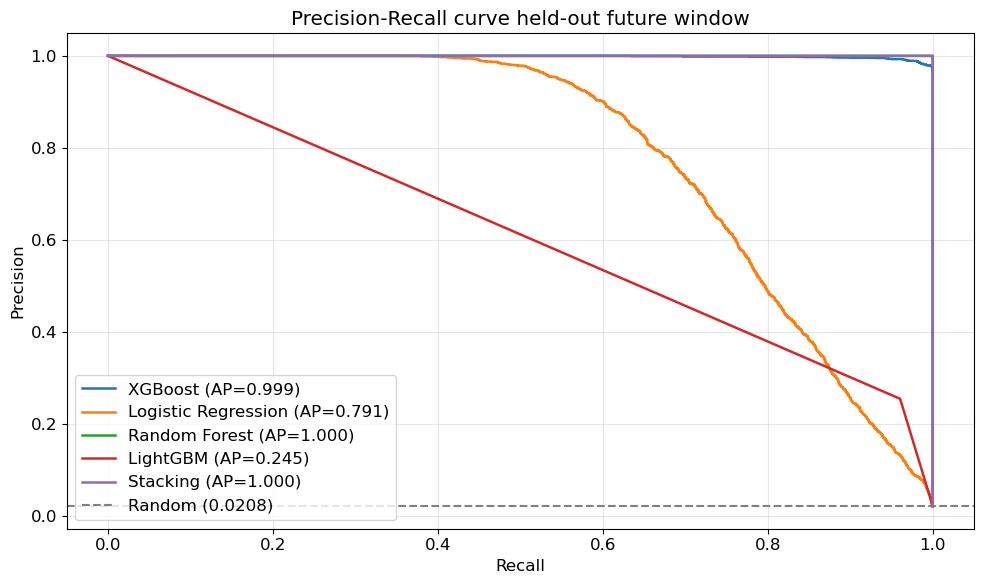
### 模型比较
所有模型在相同的时间划分(步骤1–490训练,491–743测试)和相同的特征流水线上训练。
| 模型 | PR-AUC | ROC-AUC | 在99%精度下的召回率 | 相对`isFlaggedFraud`的提升 |
|---|---|---|---|---|
| 随机森林 | 1.0000 | 1.0000 | 1.0000 | 35.3倍 |
| 堆叠集成 | 1.0000 | 1.0000 | 1.0000 | 35.3倍 |
| **XGBoost(可部署)** | **0.9987** | **1.0000** | **0.9688** | **35.3倍** |
| 逻辑回归 | 0.7905 | 0.9796 | 0.4506 | 27.9倍 |
| LightGBM(默认) | 0.2451 | 0.9502 | 0.0000 | 8.7倍 |
| `isFlaggedFraud`(规则基线) | 0.0283 | 0.5888 | 0.0000 | 1.0倍 |
### 特征归因
## 路线图
- [x] 基于时间的评估框架
- [x] 使用相同流水线的五模型比较
- [x] 校准 + SHAP归因
- [x] 成本敏感阈值分析
- [ ] 流式推理框架(Kafka → FastAPI)
- [ ] 漂移监控(基于余额差异特征的PSI)
- [ ] 模型卡片发布至Hugging Face
## 许可
MIT — 参见[`LICENSE`](LICENSE)。
## 联系方式
📫 [alvenyuka2@gmail.com](mailto:alvenyuka2@gmail.com) · 💼 [LinkedIn](https://www.linkedin.com/in/alvenyuka) · 🐙 [GitHub](https://github.com/alvenyuka)
标签:Apex, Jupyter, LightGBM, PaySim, Python, scikit-learn, SHAP, XGBoost, 不平衡数据, 分类器, 召回率, 安全, 数据科学, 无后门, 时间序列, 机器学习, 模型校准, 模型解释性, 欺诈检测, 特征工程, 移动支付, 精度优化, 资源验证, 超时处理, 逆向工具, 金融科技