mohTalib/AACDI
GitHub: mohTalib/AACDI
AACDI是一个利用Claude大语言模型对安全事件进行推理分析并产生可操作决策的实验性AI安全分析系统,旨在解决告警疲劳和规则检测的局限性。
Stars: 0 | Forks: 0
# AACDI — 自适应对抗性网络防御智能系统
`获得`feGaussianBlur`发光滤镜
- D3拖动行为附加到enter选择
- 模拟使用`forceManyBody(-300)`、`forceLink(0.4)`、``forceCenter(0.05)`、`forceCollide`
- 图形数据在每个事件/欺骗更新时通过`buildGraph()`纯函数重建
## 仪表板
仪表板是一个实时React应用程序,通过持久WebSocket连接到后端。所有数据从后端流动——没有数据是在客户端生成的。
### 每攻击者上下文
从左侧面板名单中选择攻击者时:
- 绿色过滤徽章出现在标题中,显示所选IP
- 所有选项卡过滤为仅显示与该攻击者相关的事件和分析
- 每个选项卡中出现蓝色/紫色上下文横幅,说明正在过滤的内容
- 右侧的事件提要仅显示该攻击者的事件
- "显示全部"按钮恢复全局视图
状态持久化:选择攻击者`45.33.32.156`并切换到时间线选项卡,然后刷新页面,会恢复所选攻击者和时间线选项卡。
### 选项卡参考
| 选项卡 | 用途 | 过滤到所选攻击者? |
|-------|---------|-------------------------------|
| 攻击者 | 完整每攻击者画像,带雷达和事件日志 | 显示所选攻击者的画像 |
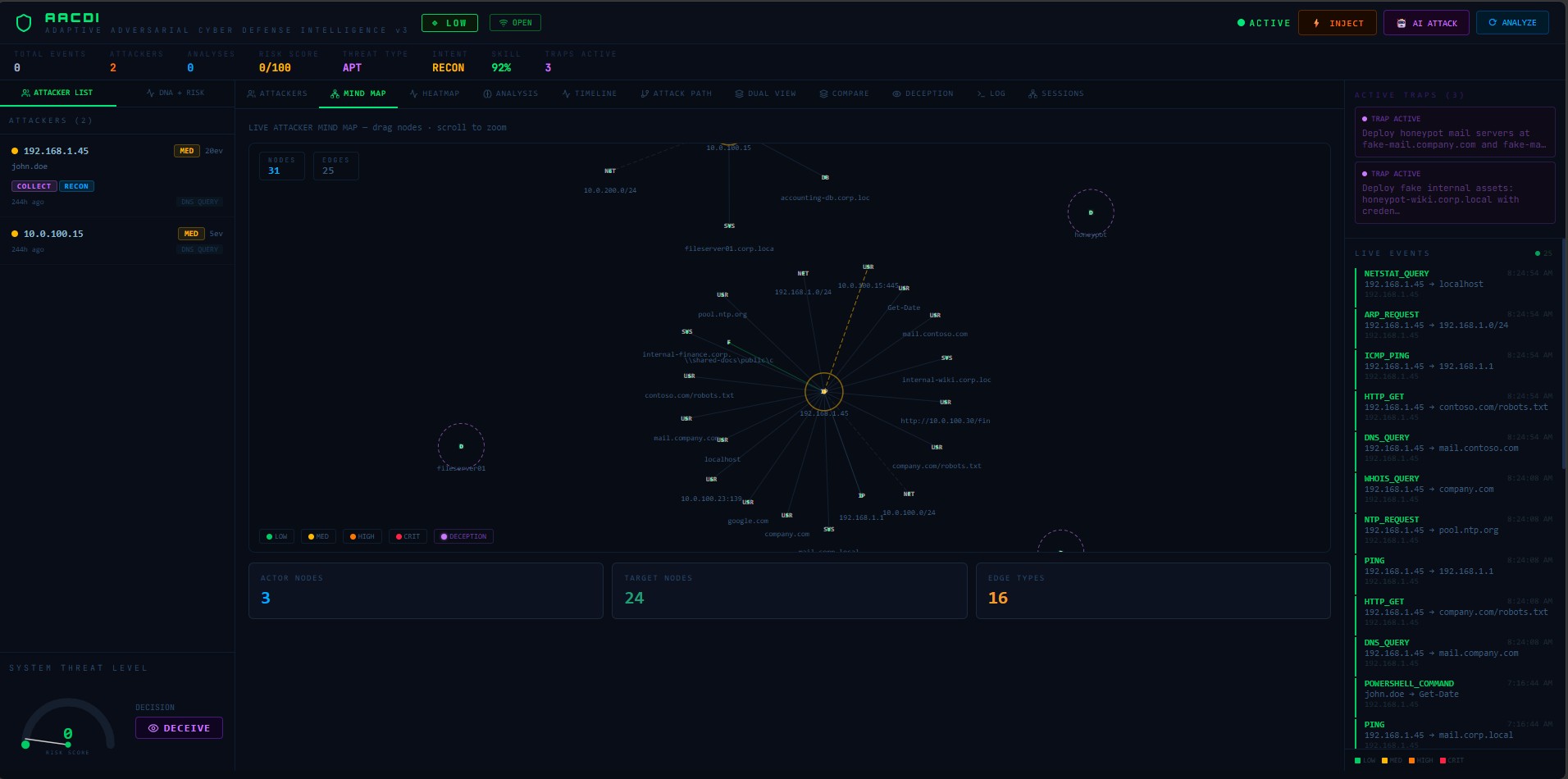
| 思维图 | 实时D3实体图 | 过滤到所选攻击者的节点/边 |
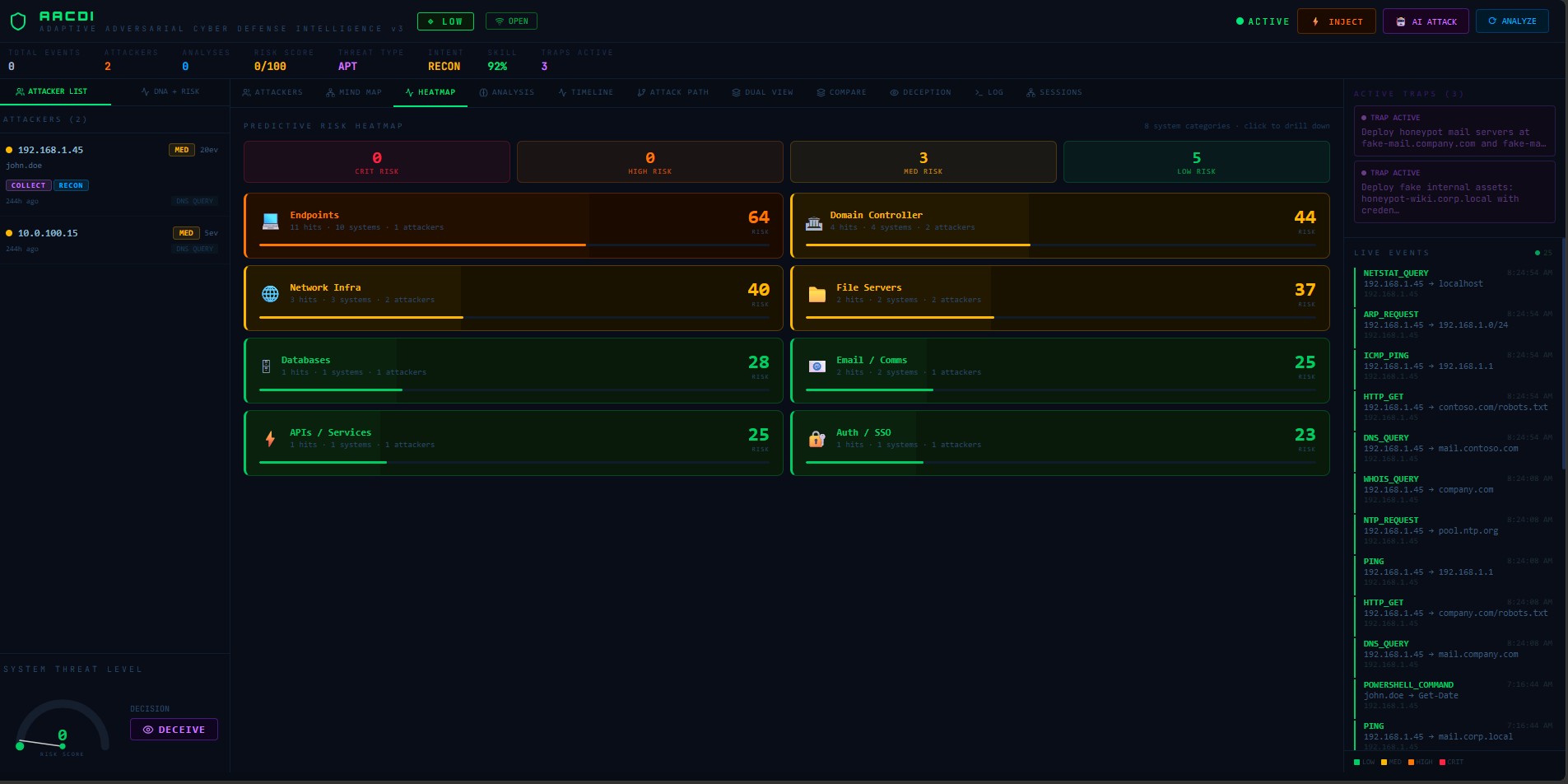
| 热图 | 按系统类别的预测风险 | 过滤到所选攻击者的目标 |
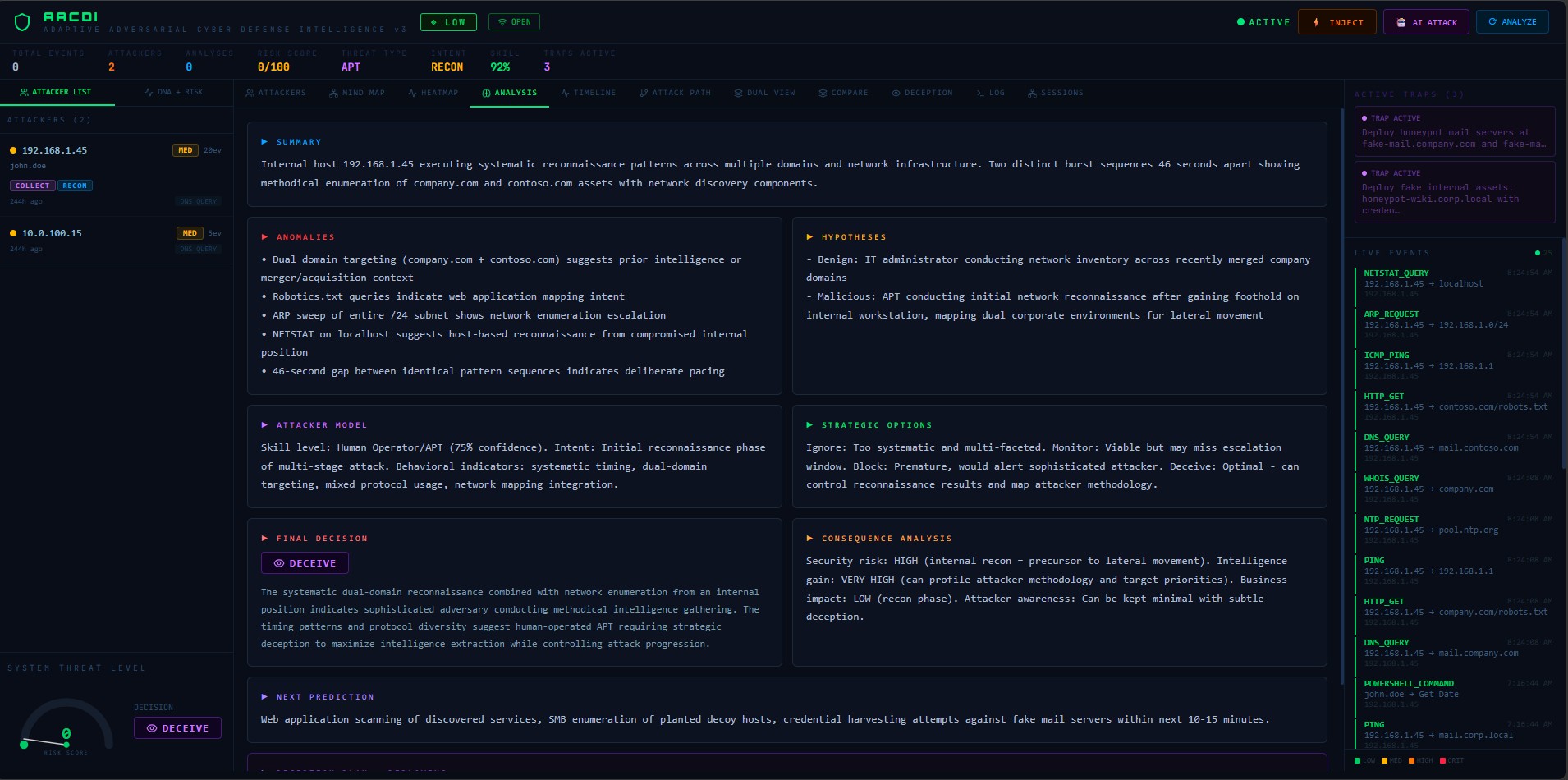
| 分析 | Claude的10段分析输出 | 显示提及所选IP的最新分析 |
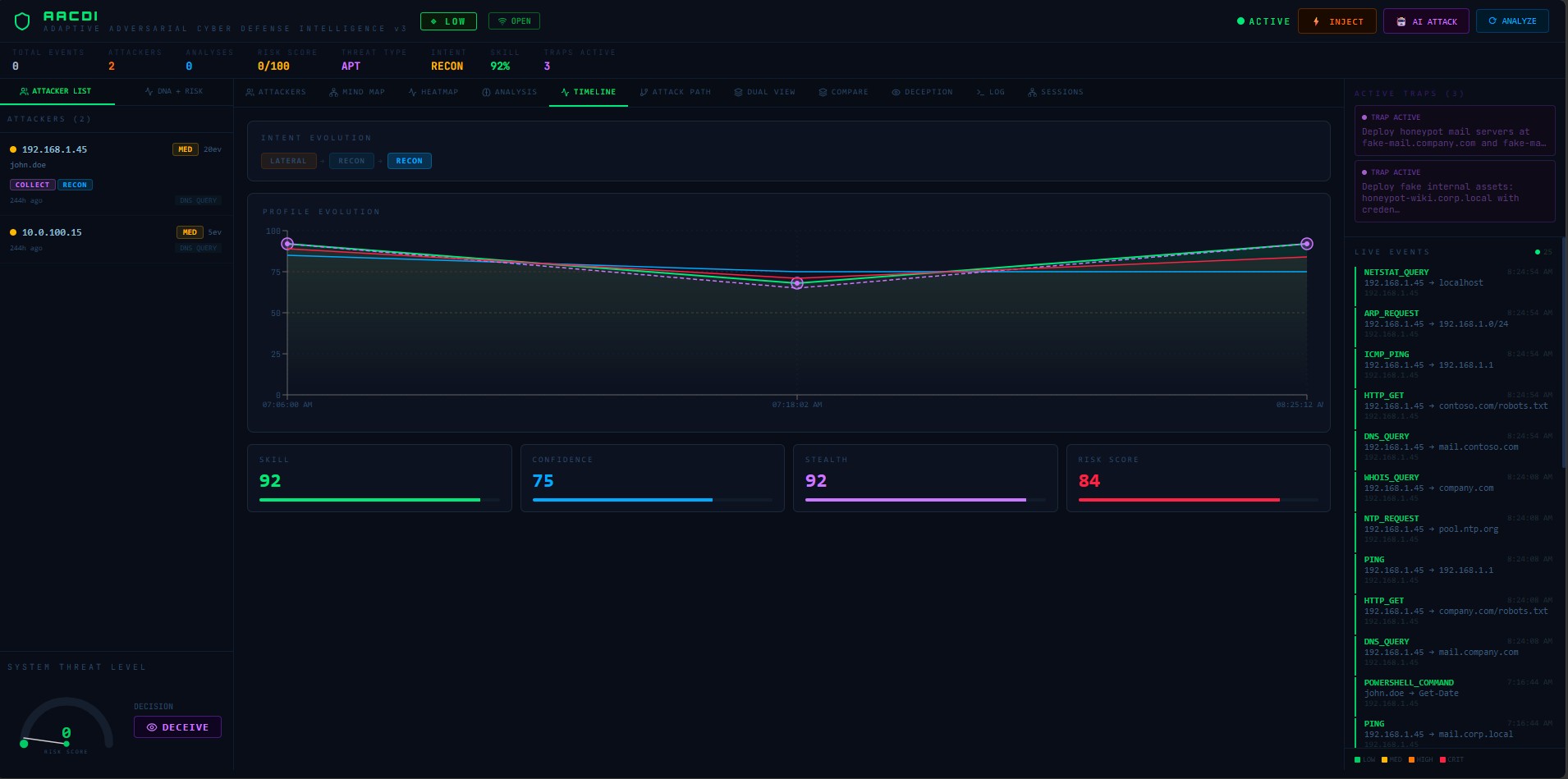
| 时间线 | 技能/风险随时间的演变 | 过滤到提及所选IP的分析 |
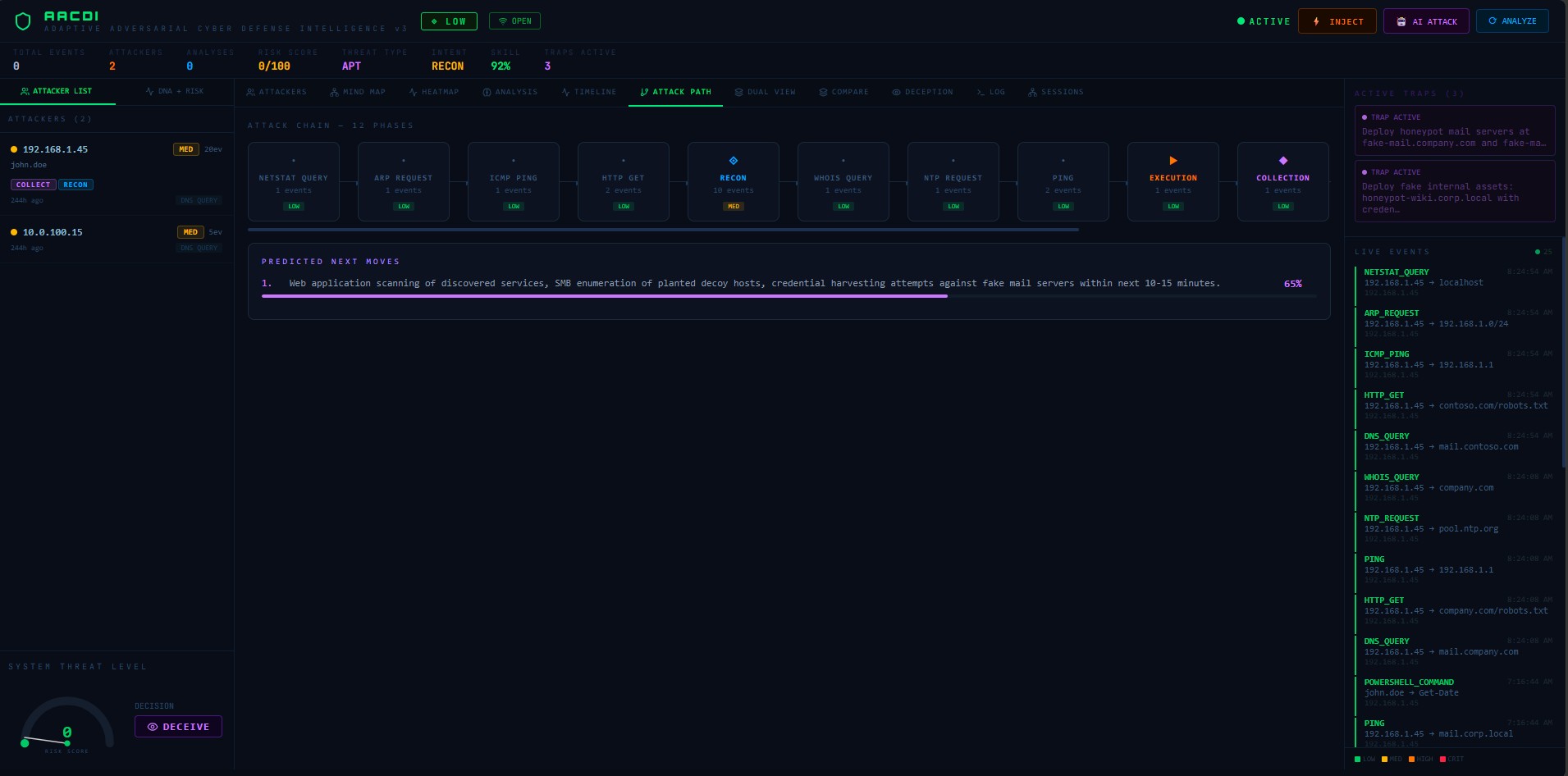
| 攻击路径 | 杀伤链重建 | 仅从所选攻击者的事件构建链 |
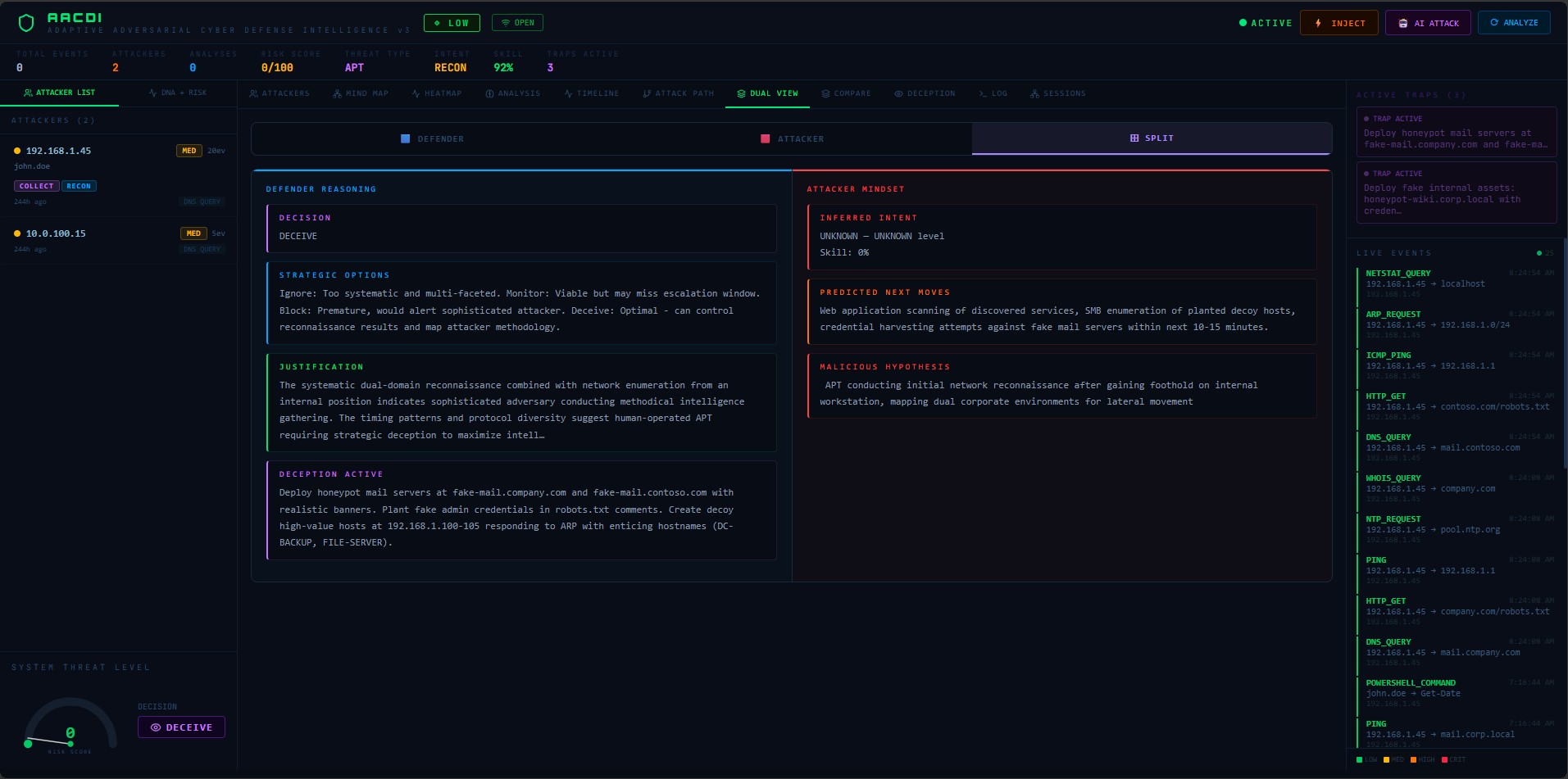
| 双视图 | 防御者+攻击者视角 | 使用与所选攻击者相关的分析 |
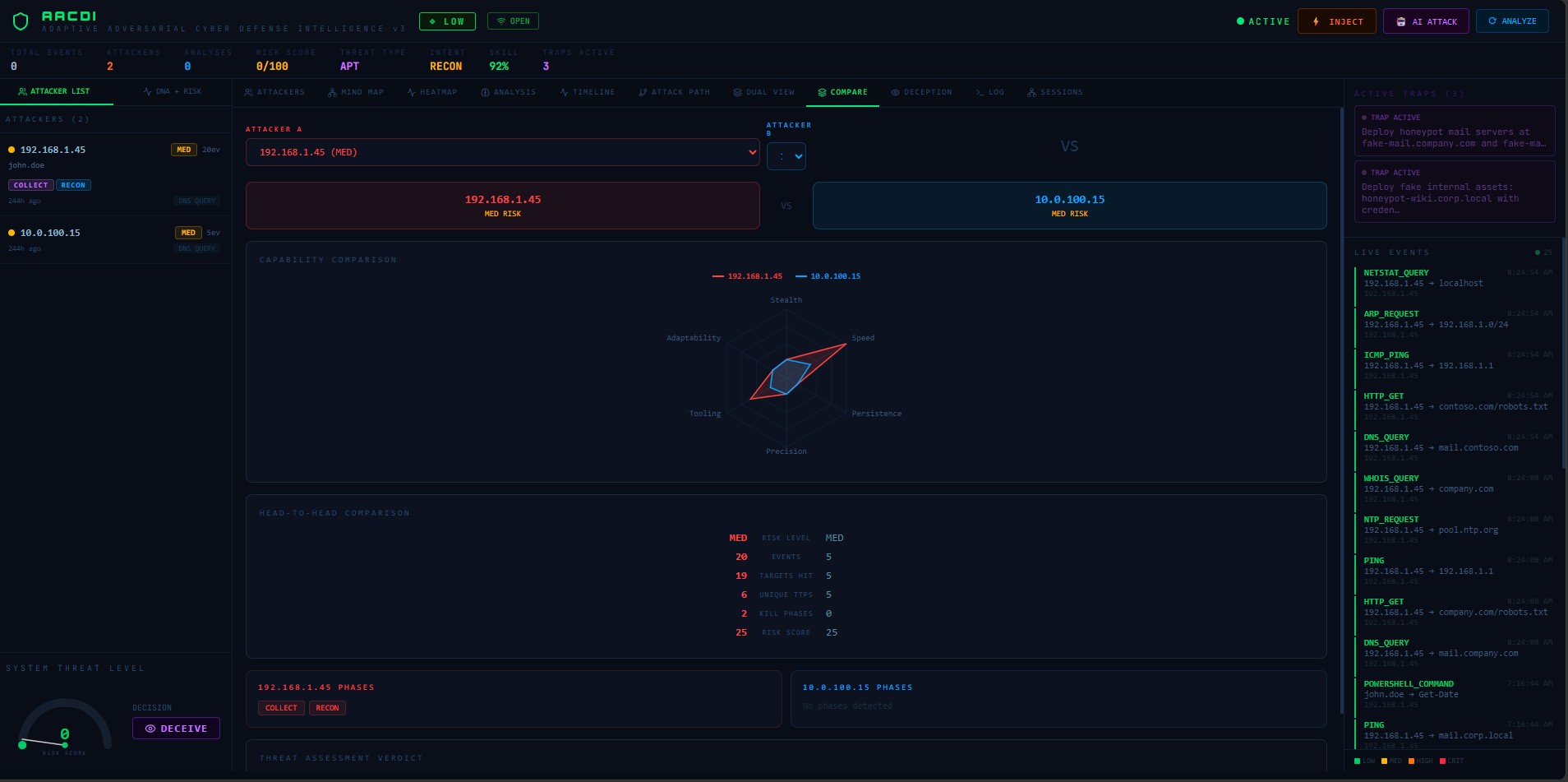
| 比较 | 并排两攻击者比较 | 预加载所选攻击者为攻击者A |
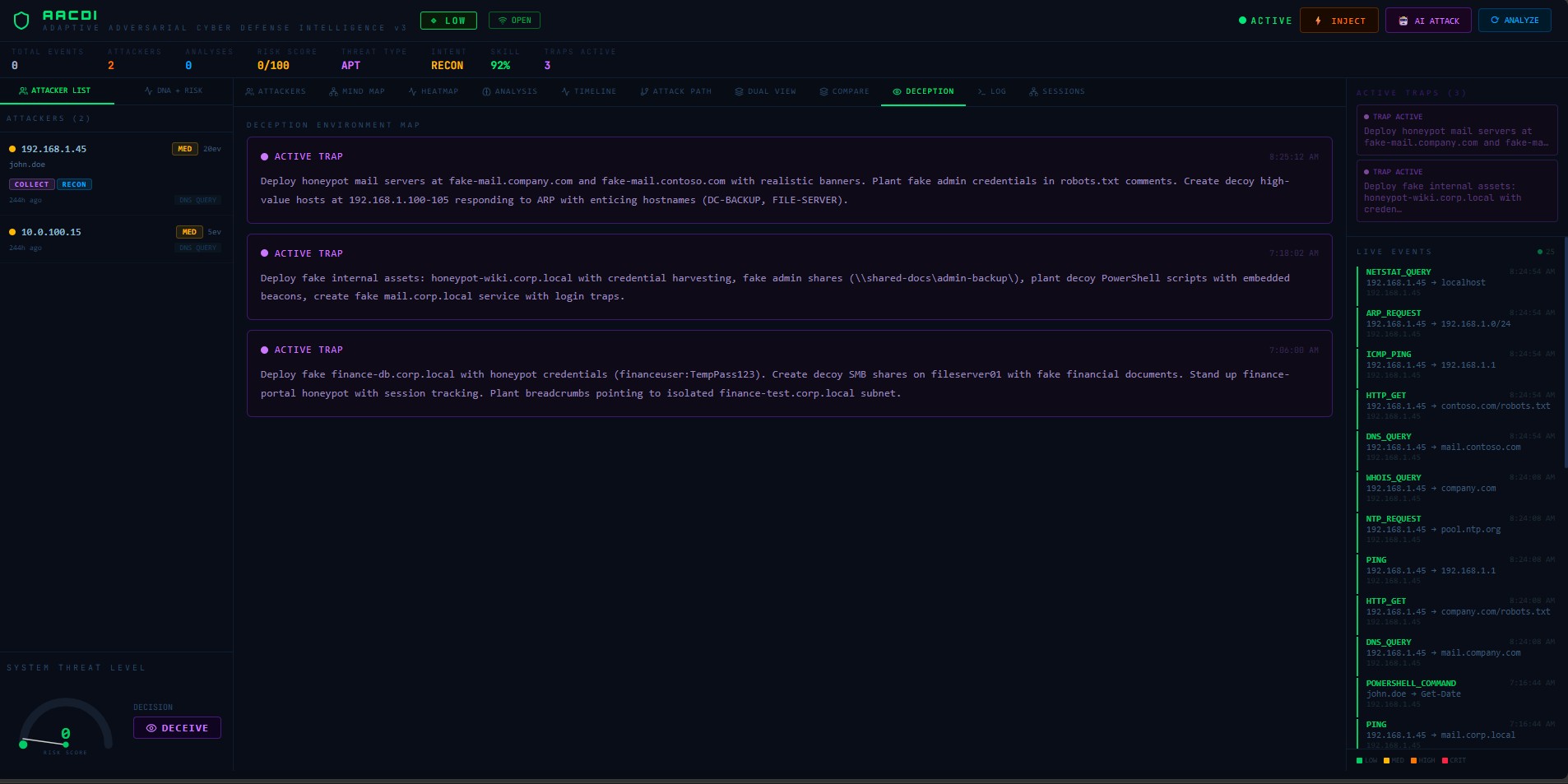
| 欺骗 | 活跃的欺骗陷阱 | 过滤到针对所选IP部署的陷阱 |
| 日志 | 决策历史 | 过滤到提及所选IP的分析 |
| 会话 | 多会话切换器 | 与攻击者选择无关 |
## 快速开始(本地开发)
### 唯一的前提条件:Docker Desktop
一切都在容器中运行。您不需要在本地安装Python、Node或Redis。
```
# 解压并进入项目
unzip AACDI-fullstack-v5.zip
cd aacdi
# 从模板创建 .env
cp .env.example .env
```
打开`.env`并设置这两个值:
```
ANTHROPIC_API_KEY=sk-ant-your-actual-key-here
REDIS_PASSWORD=anything123
```
对于Windows,还要设置:
```
AUTH_ENABLED=false
ALLOWED_ORIGINS=*
VITE_API_URL=http://localhost:8000
VITE_WS_URL=ws://localhost:8000
```
**Windows重要提示:** 在`docker-compose.yml`中,Redis服务命令必须硬编码,不使用变量:
```
command: redis-server --requirepass anything123 --maxmemory 512mb --maxmemory-policy allkeys-lru
```
**所有平台重要提示:** 在`backend/main.py`中,用以下内容替换CORS中间件:
```
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=False,
allow_methods=["*"],
allow_headers=["*"],
)
```
```
# 启动完整堆栈(首次运行需要2-3分钟来构建镜像)
docker compose up --build
```
当您看到:
```
aacdi-backend | INFO AACDI v2 backend ready
aacdi-frontend | nginx: worker process started
```
打开`http://localhost`——仪表板已上线。
### 首次测试
点击顶部栏的**⚡ 注入**。这会推送9个来自3个不同攻击者IP的预构建事件,模拟端口扫描、权限提升、凭证转储、横向移动和数据泄露。10–15秒后:
1. 事件出现在右侧提要中
2. 3个攻击者条目出现在左侧面板名单中
3. "认知引擎活跃"在选项卡栏中闪烁
4. 分析选项卡填充了Claude的完整推理
5. 思维图填充了实体节点和边
6. 如果决策是阻止或欺骗,可能会出现弹窗通知
7. 点击左侧面板中的任何攻击者会将所有选项卡过滤到该IP
## 运行模拟
`sensor_sim.py`脚本生成现实的攻击场景,无需任何真实的安全基础设施。
```
# 安装唯一依赖项
pip install httpx
# APT 攻击活动 — 6个阶段,隐蔽,最有趣的场景
python sensor_sim.py --scenario apt_campaign --session apt-test --duration 300
# 打开:http://localhost/?session=apt-test
# 多攻击者 — 3个同时参与者,最佳的每攻击者追踪测试
python sensor_sim.py --scenario multi_attacker --session multi-test
# 国家级 — 最复杂,5个阶段
python sensor_sim.py --scenario nation_state --session nation-test --duration 600
# 勒索软件 — 快速且具有破坏性
python sensor_sim.py --scenario ransomware --session ransom-test
# 供应链攻击
python sensor_sim.py --scenario supply_chain --session supply-test
# 内部威胁 — 缓慢且持久,看起来几乎合法
python sensor_sim.py --scenario insider_threat --session insider-test
# 随机场景
python sensor_sim.py --scenario random
```
每个场景在它自己的会话中运行。使用`?session=`打开多个浏览器选项同时监控它们——这模拟了同时监视多个网络段。
### 可用场景
| 场景 | 阶段 | 攻击者数量 | 描述 |
|----------|--------|----------------|-------------|
| `apt_campaign` | 6 | 1 | 侦察→鱼叉式钓鱼→提权→横向→暂存→泄露 |
| `ransomware` | 3 | 1 | VPN暴力破解→网络访问→大规模加密 |
| `insider_threat` | 3 | 1 | 合法用户访问未授权数据并泄露 |
| `credential_stuffing` | 3 | 1 | 批量登录尝试→成功入侵 |
| `data_exfil` | 3 | 1 | API滥用→暂存→泄露 |
| `multi_attacker` | 4 | 3 | 三个同时行动者(APT+勒索软件+内鬼) |
| `nation_state` | 5 | 1 | CEO鱼叉式钓鱼→域名入侵→IP盗窃 |
| `supply_chain` | 4 | 1 | 被入侵的npm包→反向shell→数据盗窃 |
## AI对抗AI模式
最具技术趣味的功能。第二个Claude实例扮演攻击者,适应防御者的决策,并故意做与防御者预测相反的事情。
```
# 从仪表板触发:点击 🤖 AI ATTACK
# 通过 API 触发:
curl -X POST http://localhost:8000/api/attacker/default/next \
-H "Content-Type: application/json" \
-d '{}'
```
### 攻击者状态机
```
RECON → INITIAL_ACCESS → EXECUTION → PRIVILEGE_ESCALATION
→ LATERAL_MOVEMENT → COLLECTION → EXFILTRATION
```
### 适应逻辑
| 防御者决策 | 攻击者响应 |
|------------------|-------------------|
| 阻止 | 切换到隐形模式,改变技术,降低事件频率 |
| 欺骗 | 40%概率检测到蜜罐。如果检测到:后退,改变方法。如果未检测到:继续进入陷阱。 |
| 监视 | 增加检测计数器,可能继续当前阶段或转向 |
| 忽略 | 进入下一攻击阶段,升级攻击性 |
攻击者还会阅读防御者的下一步预测部分并故意做相反的事情。如果AACDI预测"接下来尝试凭证转储",攻击者会先转向横向移动。这模拟了真实威胁情报操作中的猫鼠动态。
## 技术栈
| 层 | 技术 | 选择原因 |
|-------|-----------|-------------------|
| AI引擎 | Anthropic Claude Sonnet 4 | 多步安全分析的最佳推理。API密钥保留在服务端——永不到达浏览器。 |
| 后端 | FastAPI + Uvicorn | 异步Python、原生WebSocket支持、`/api/docs`自动OpenAPI文档、优秀性能 |
| 状态 | Redis 7 | O(1)列表操作用于事件队列、TTL用于会话过期、AOF持久化、pub/sub准备好多工作器扩展 |
| 前端 | React 18 + Vite | 组件模型、开发中快速HMR、带代码分割的小生产包 |
| 力导向图 | D3.js v7 | 需要直接DOM操作用于模拟tick循环——React无法管理D3的动画状态 |
| 图表 | Recharts | 声明式React图表,数据变化时正确重新渲染 |
| 反向代理 | nginx | TLS终止、WebSocket升级头、静态文件服务带激进缓存、速率限制 |
| 容器 | Docker Compose | 单命令部署、网络隔离、可重现环境 |
| 认证 | JWT + SHA-256 API密钥 | UI无状态,传感器集成简单 |
| 威胁情报 | AbuseIPDB / VirusTotal | 可选的IP信誉检查,Redis缓存1小时 |
## 安全注意事项
**API密钥暴露**——Anthropic API密钥是容器中的环境变量。在任何网络可访问的部署之前,使用适当的密钥管理器(HashiCorp Vault、AWS Secrets Manager)。
**`AUTH_ENABLED=false`仅用于本地测试**——禁用认证后,任何能到达端口8000的人都可以推送事件、读取所有分析并控制攻击者代理。永远不要在网络上以认证禁用状态部署。
**JWT密钥`localtestsecret`必须替换**——生成加密随机的64字符密钥:`python3 -c "import secrets; print(secrets.token_hex(32))"`。
**Redis在默认配置中没有TLS**——所有事件、分析和会话数据在后端和Redis之间以明文传输。在任何敏感环境中启用Redis TLS。
**欺骗层的法律风险是真实的**——在您不拥有的基础设施上部署蜜罐或蜜罐凭证,或没有明确的书面授权,在大多数司法管辖区根据计算机欺诈和滥用法规(美国的CFAA、英国的《计算机滥用法》等)是违法的。欺骗层是架构上可能实现的概念证明。在使用之前获得法律批准。
**AACDI决策是建议性的**——系统可能会出错。忽略决策不会将某物认证为安全。阻止决策不会将某物认证为恶意。将每个决策视为人类判断的输入,而不是事实真相。
**提示注入是可能的**——没有防御能阻止攻击者特意制作事件字段值来操纵Claude的输出。足够复杂的攻击者如果控制了流入AACDI的事件,可能会影响分析结果。这是所有处理不可信输入的LLM系统的已知限制。
## 已知限制
- **单工作器WebSocket**——WebSocket连接在Python字典中跟踪。多个uvicorn工作器不共享连接状态。扩展需要Redis pub/sub进行跨工作器广播。
- **没有自动响应执行**——AACDI做出决策。它不执行行动。SOAR集成留作练习。
- **仅限英语**——系统提示和所有解析假设英语Claude输出。
- **上下文窗口扩展**——非常长的会话最终可能达到Claude的上下文限制。当前实现使用最后2个分析作为历史。向量数据库方法可以正确处理这个。
- **没有多租户**——所有能访问仪表板的用户都能看到所有会话。未实现每用户会话隔离。
- **欺骗执行器本地部署文件**——实际部署需要与您的文件分发机制(AD GPO、端点管理、网络共享)集成。
## 研究背景
本项目借鉴了几个活跃的研究领域:
**用于安全推理的AI**——LLM在代码漏洞检测和恶意软件分类方面表现出色。它们在SOC运营中的行为分析和战略决策应用是较新的领域。本项目测试LLM是否能执行经验丰富的L2/L3分析师所做的多步推理。
**主动网络防御**——从纯粹被动的安全转向主动的基于欺骗的防御。欺骗决策路径借鉴了Jajodia、Swarup、Schwartz和Gehling的学术网络欺骗工作,以及蜜罐、蜜罐网络和欺骗技术平台的实际实现。
**安全运营中的人机协作**——本系统不是取代分析师,而是尝试通过处理L1分类层来增强他们,让人类注意力集中在每天实际上需要人类判断的2–3种情况上。
**对抗性AI动态**——AI对抗AI模式探索当攻击者和防御者都使用基于LLM的推理时会发生什么。适应循环(防御者适应→攻击者适应→防御者演变)反映了对抗性交互的博弈论模型,特别是Stackelberg安全游戏。
## 许可证
MIT许可证——详见`LICENSE`。
本许可证涵盖代码。它不授予在未经授权的情况下对系统或人员部署欺骗技术的权限。您的欺骗组件使用受您所在司法管辖区的法律管辖。本项目不构成法律或安全建议。







**一个由AI驱动的网络安全智能系统,它像防御者一样思考,**
**像战略家一样推理,像反情报人员一样实施欺骗。**
[快速开始](#getting-started-local-development) •
[架构](ARCHITECTURE.md) •
[集成](INTEGRATIONS.md) •
[欺骗层](DECEPTION.md)
## 目录
- [什么是AACDI?](#what-is-aacdi)
- [演示](#record)
- [为什么存在这个项目](#why-this-exists)
- [它解决的核心问题](#the-core-problem-it-solves)
- [核心能力](#key-capabilities)
- [工作原理](#how-it-works)
- [四种决策](#the-four-decisions)
- [项目结构](#project-structure)
- [组件详解](#component-deep-dive)
- [仪表板](#the-dashboard)
- [快速开始](#getting-started-local-development)
- [运行模拟](#running-simulations)
- [AI对抗AI模式](#ai-vs-ai-mode)
- [技术栈](#technology-stack)
- [安全注意事项](#security-considerations)
- [已知限制](#known-limitations)
- [研究背景](#research-background)
## 什么是AACDI?
AACDI是一个实验性的AI驱动的安全分析系统,介于您现有的安全工具和安全团队之间。它从SIEM、EDR平台、防火墙和IDS系统摄取原始安全事件,然后使用Claude(Anthropic的大语言模型)对攻击者行为进行推理,并产生可操作的决策。
与现有工具的根本区别:**AACDI不会将事件与规则进行匹配。它会对其进行推理。**
当SIEM触发10,000条告警时,AACDI会将它们作为叙事来阅读——询问攻击者试图完成什么,他们的技能如何,他们接下来会做什么,以及欺骗他们是否比阻止他们能获得更多情报。
这是一个研究项目,展示了在以下情况下架构上可能实现的功能:
- 具备完整安全上下文的大语言模型推理
- 有状态的记忆,跨时间持久化攻击者行为画像
- 第四种决策(欺骗),这是现有安全产品都不提供的
- 攻击者认知模型的实时可视化
## 演示
https://github.com/user-attachments/assets/11fb1267-3853-40fd-92a0-645d5d41cf41
## 示例
**作为探索AI驱动的网络防御的研究项目构建。**
*概念验证。非生产就绪。非法律建议。非安全建议。*
*部署蜜罐前获得许可。*
**另请参阅:** [INTEGRATIONS.md](INTEGRATIONS.md) • [DECEPTION.md](DECEPTION.md) • [ARCHITECTURE.md](ARCHITECTURE.md)
标签:AI安全, AMSI绕过, AV绕过, BOF, Chat Copilot, Claude, CVE检测, DNS 反向解析, EDR, FastAPI, FTP漏洞扫描, HTTP工具, IP 地址批量处理, LLM, Python, React, Redis, Syscalls, Unmanaged PE, 事件分析, 人工智能, 威胁情报, 威胁检测, 安全分析平台, 安全编排, 安全运营, 开发者工具, 扫描框架, 无后门, 无线安全, 欺骗防御, 流量嗅探, 版权保护, 用户模式Hook绕过, 网络安全, 网络安全审计, 脆弱性评估, 自动化响应, 防火墙, 隐私保护