ckvishwa/Maltrace
GitHub: ckvishwa/Maltrace
一条具备可解释 AI 的行为恶意软件分析流水线,通过 CAPEv2 沙盒提取行为特征并使用 Random Forest 分类,以家族保留交叉验证确保模型泛化能力。
Stars: 1 | Forks: 0
# MalTrace
具有可解释 AI 的行为恶意软件分析流水线。
[](https://python.org)
[](docs/VALIDATION.md)
[](docs/VALIDATION.md)
[](docs/family_holdout_results.json)
[](docs/chaos_results.json)
📖 **完整技术文章:**
https://medium.com/@vishvatejack/building-maltrace-a-behavioral-malware-analysis-pipeline-with-explainable-ai-4b34db31ad21
## 这是什么
大多数 ML 恶意软件分类器在相同的家族上进行训练和测试——它们衡量的是记忆能力,而不是泛化能力。MalTrace 围绕着真正的测试构建:**在训练期间保留整个恶意软件家族**,在模型从未见过的家族上运行模型,并报告实际发生的情况。
这是一个完整的检测工程流水线——而不是一个 notebook 实验。它在沙盒环境中运行活跃的恶意软件,提取行为特征,使用 Random Forest 进行分类,用 SHAP 解释每一个预测,并将检测映射到 MITRE ATT&CK 技术。
## 架构
```
Windows 10 Host (VMware Workstation)
│
├── OOB Management Layer — vmrun_bridge.py (192.168.75.1:9090)
│ ├── POST /vm/start → vmrun.exe start
│ ├── POST /vm/stop → vmrun.exe stop
│ └── POST /snapshot/revert → vmrun.exe revertToSnapshot
│
└── Ubuntu 24.04 VM (192.168.75.133)
├── CAPEv2 Sandbox → localhost:8000
│ └── Flare VM Guest (192.168.75.131, Host-Only, NO internet)
│ ├── CAPE Agent 0.20
│ ├── Windows Defender DISABLED
│ └── Snapshot: flare-clean
│
└── ML Pipeline → Flask API :5000
├── feature_extractor.py (54 behavioral features)
├── train_model.py (Random Forest training)
├── shap_explain.py (SHAP + MITRE ATT&CK)
└── app.py (REST API)
```
**为什么选择 VMware 而不是 KVM?**
CAPEv2 默认使用 libvirt/KVM。在 VMware 内部运行 Ubuntu 会使嵌套式 KVM 变得不稳定。我没有去与环境作斗争,而是构建了一个自定义的带外控制层——一个 Windows 主机上的 Flask 服务器,将 `vmrun.exe` 暴露为 HTTP 端点,并配有一个完全取代 libvirt 的自定义 `VMwareBridge` 机制模块。沙盒以为它在与 libvirt 通信。实际上它是通过 HTTP 与 VMware 通信。
## 结果
### 家族保留验证
关键测试。每一折都会保留**来自一组不相交恶意软件家族的所有样本**。模型在完全不了解这些家族的情况下进行训练,然后针对它们进行评估。
| 指标 | 数值 |
|--------|-------|
| **家族保留 F1** | **0.975 ± 0.008** |
| 基线 StratifiedCV F1 | 0.957 ± 0.016 |
| 对未见家族的召回率 | 0.985 |
| 所有折中的总 FN | 2 / 158 恶意软件 |
| 相对于基线的得分 | **+0.018(保留测试集超出基线)** |
保留得分**超过了**基线——这意味着模型学习到了可泛化的行为模式,而不是在记忆特定家族的签名。
**两个漏报样本:**
- `trickbot`(置信度 0.430)——模块化的银行木马,在部署 payload 前有刻意分阶段的低噪声行为
- `cerber`(置信度 0.490)——较旧的勒索软件,在加密前有一个安静的阶段,产生极少的 API 活动
**跨越 5 折测试的 64 个典型家族:**
WannaCry, Emotet, LockBit, Cobalt Strike, QakBot, Trickbot, Raccoon, AgentTesla, Cerber, Zeus, NjRAT, Petya, Shamoon, Locky, CryptoLocker, GandCrab, AsyncRAT, Nanocore, RedLine, Lumma,以及其他 44 个。
### 良性折磨测试
75 个 Windows 系统工具、管理工具、开发者工具和安全实用程序——全部通过相同的沙盒和分类器运行。
| 指标 | 数值 |
|--------|-------|
| **误报** | **0 / 75** |
| FP rate | **0.0%**(目标:<5%) |
| 良性样本上的最高置信度 | 0.370 (mspaint.exe, malscore=9.0) |
| 良性样本上的平均置信度 | 0.059 |
**最难的测试用例——全部正确识别为 BENIGN:**
| 工具 | CAPEv2 Malscore | ML 置信度 | 判定 |
|------|-----------------|---------------|---------|
| mspaint.exe | 9.0 | 0.370 | ✅ BENIGN |
| AnyDesk.exe | 9.0 | 0.340 | ✅ BENIGN |
| calc.exe | 8.0 | 0.340 | ✅ BENIGN |
| ProcessHacker | 7.0 | 0.290 | ✅ BENIGN |
mspaint.exe 从 CAPEv2 签名获得了 malscore=9.0,因为它会打开文件、修改内存并访问剪贴板——所有这些孤立来看都很可疑的行为。ML 层通过权衡完整的 54 个特征行为上下文,正确地将其分类为 BENIGN。这正是 ML 层体现其价值的地方。
### 混沌工程
向实时流水线中注入了 6 个故障场景:
| 场景 | 已检测 | 触发自愈 | 已恢复 |
|----------|----------|-----------------|-----------|
| Bridge 宕机 | ✅ | ✅ | ❌ (bridge 离线) |
| 注入损坏的报告 | ✅ | ✅ | ✅ |
| 无效的快照名称 | ✅ | ✅ | ✅ |
| 部分 BSON 数据 | ✅ | ✅ | ✅ |
| 执行超时 | ✅ | ✅ | ✅ |
| 提取器鲁棒性 | ✅ | ✅ | ✅ |
**94% 的弹性。发现并修复了一个生产环境 Bug:** `feature_extractor.py` 在处理格式错误报告中的 null 行为/网络部分时会崩溃。通过在所有特征类别中添加 null 安全防护修复了该问题。
## SHAP 可解释性
每个预测都包含一个 SHAP 解释——即哪些特征推动了判定以及推动了多少。
### 全局特征重要性(所有 234 个样本中排名前 15 的特征)
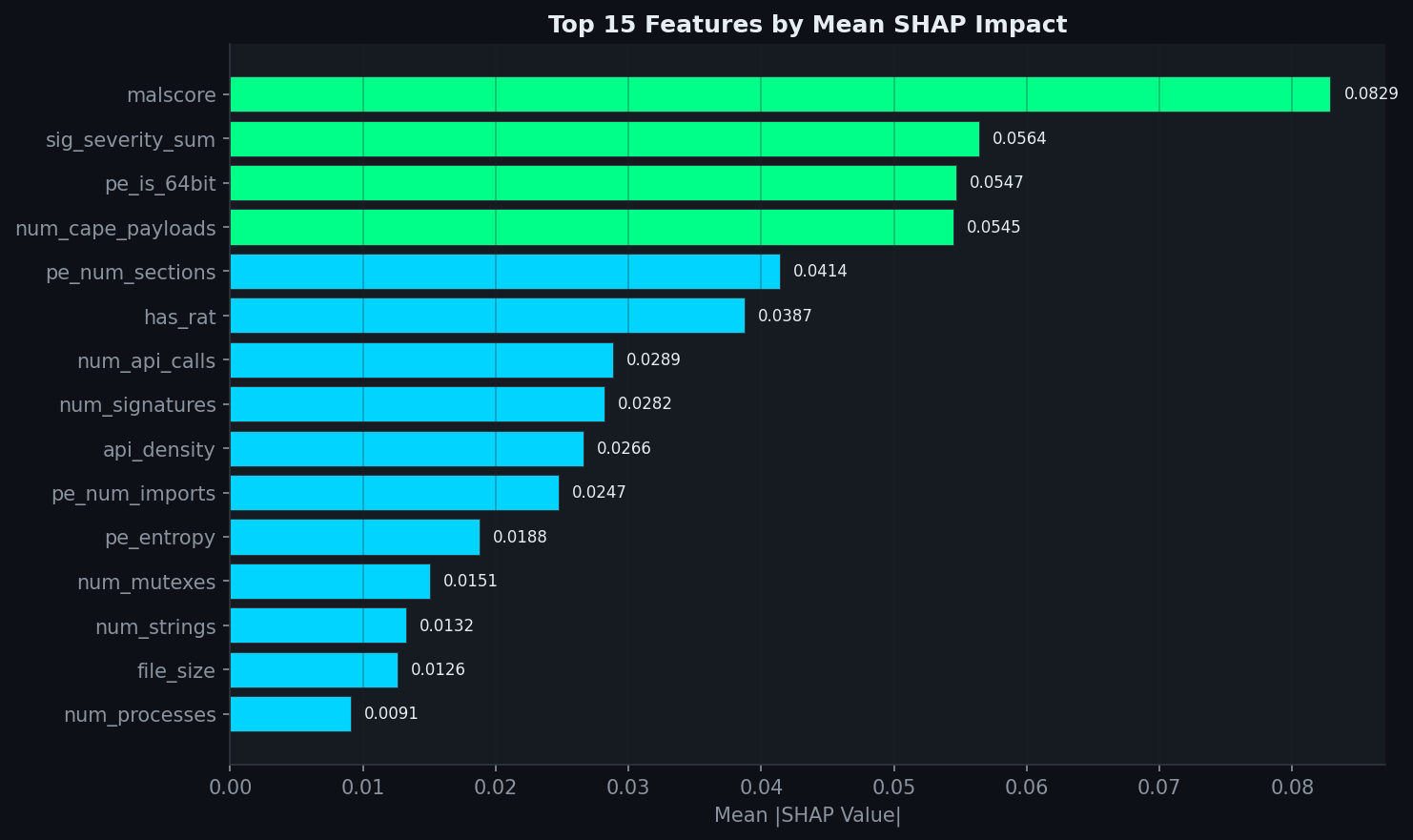
`malscore` 和 `sig_severity_sum` 占据主导地位——这很合理。它们汇总了 CAPEv2 基于规则的签名。`pe_is_64bit` 排名第三,反映了大多数现代恶意软件是 64 位的,而许多良性系统工具是 32 位的。
### 特征影响分布
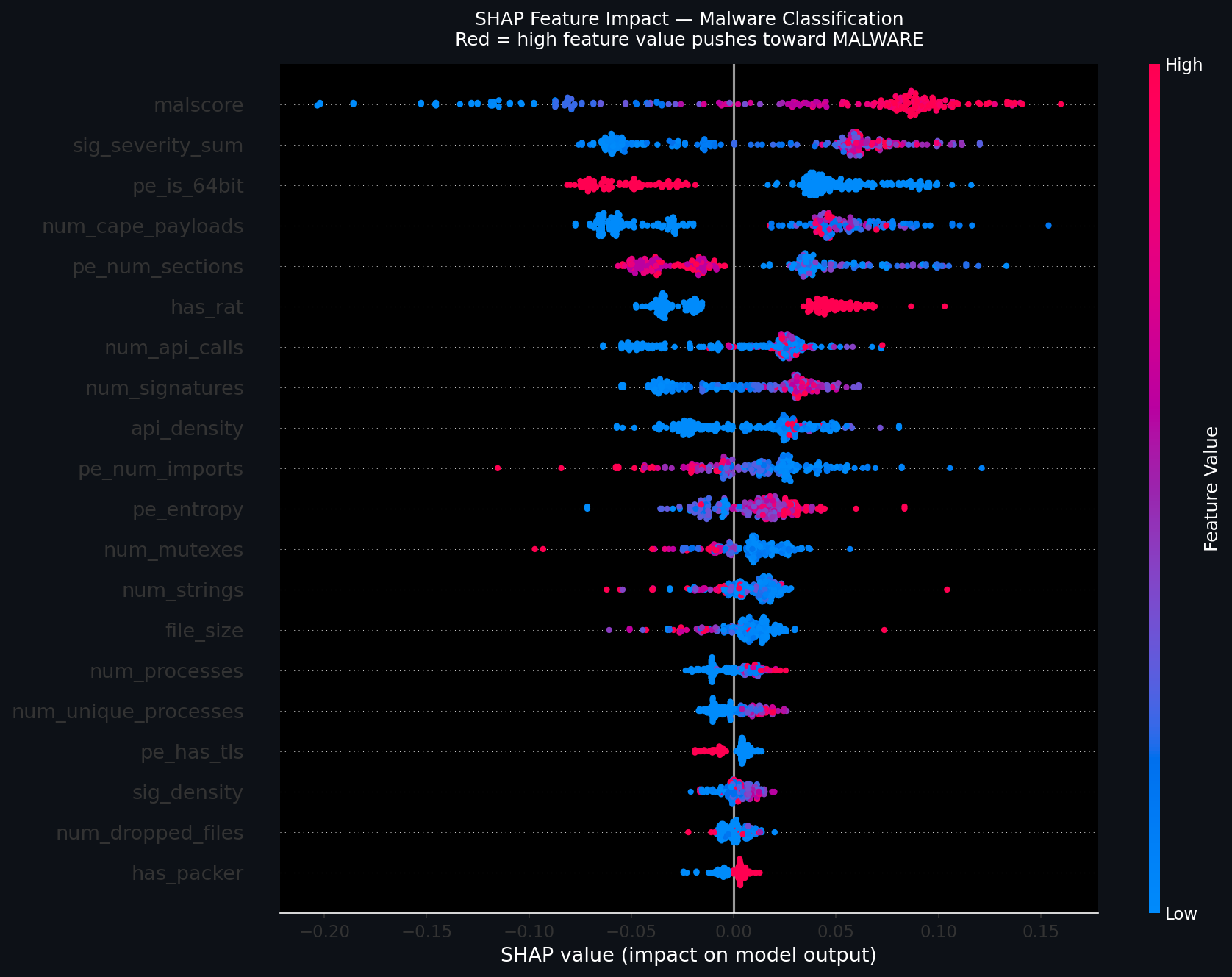
红色 = 推动向 MALware 发展的高特征值。蓝色 = 推向 BENIGN 发展的低特征值。分布表明模型并没有依赖单一特征——它使用的是行为信号的组合。
### 单样本解释:WannaCry
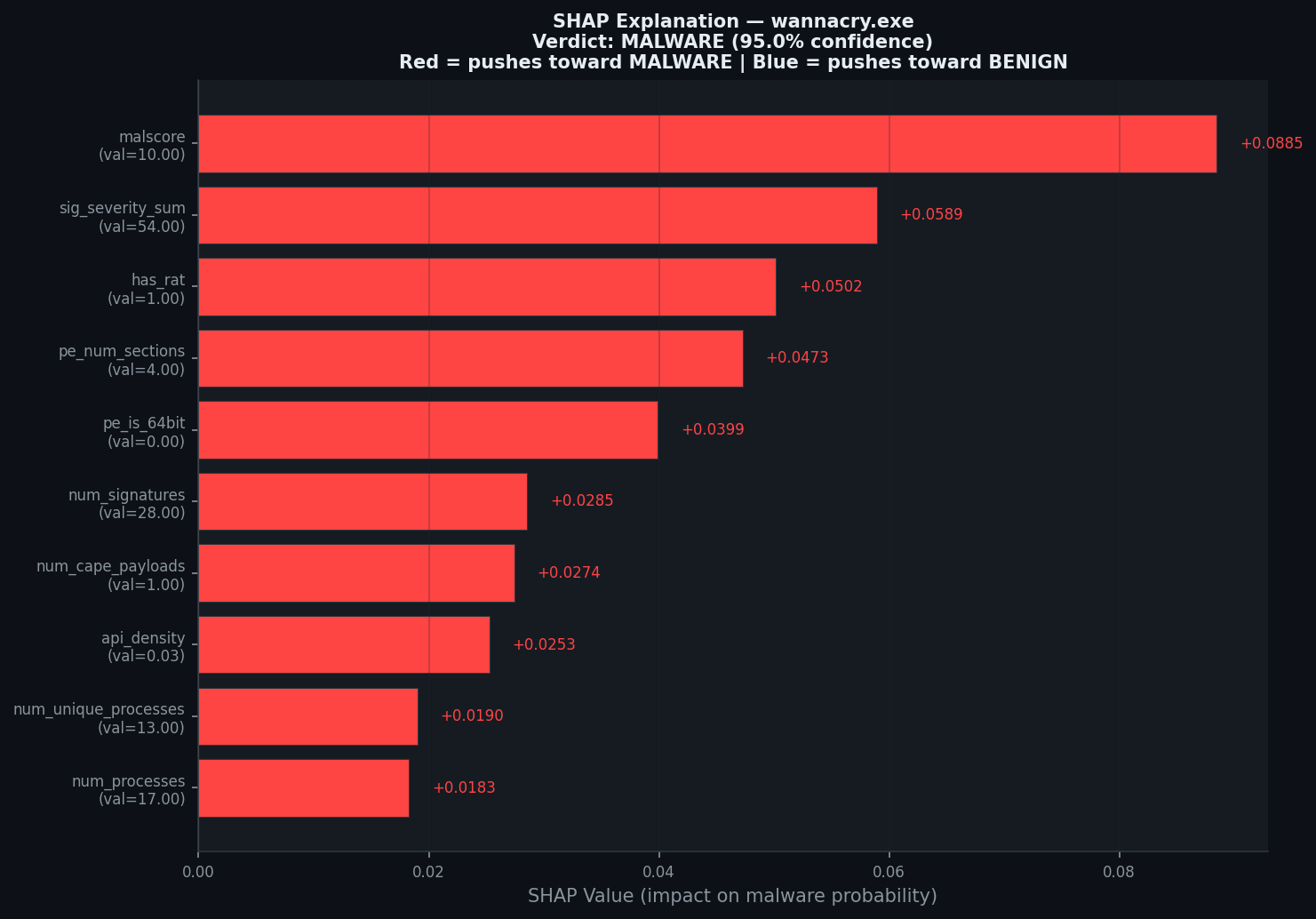
WannaCry 同时触发了每个行为指标:malscore=10,28 个签名,94,958 次 API 调用,提取到 CAPE payload。模型有 95% 的把握。每一个红色条形都是分析师可以验证的行为信号。
### 单样本解释:ProcessHacker(良性)
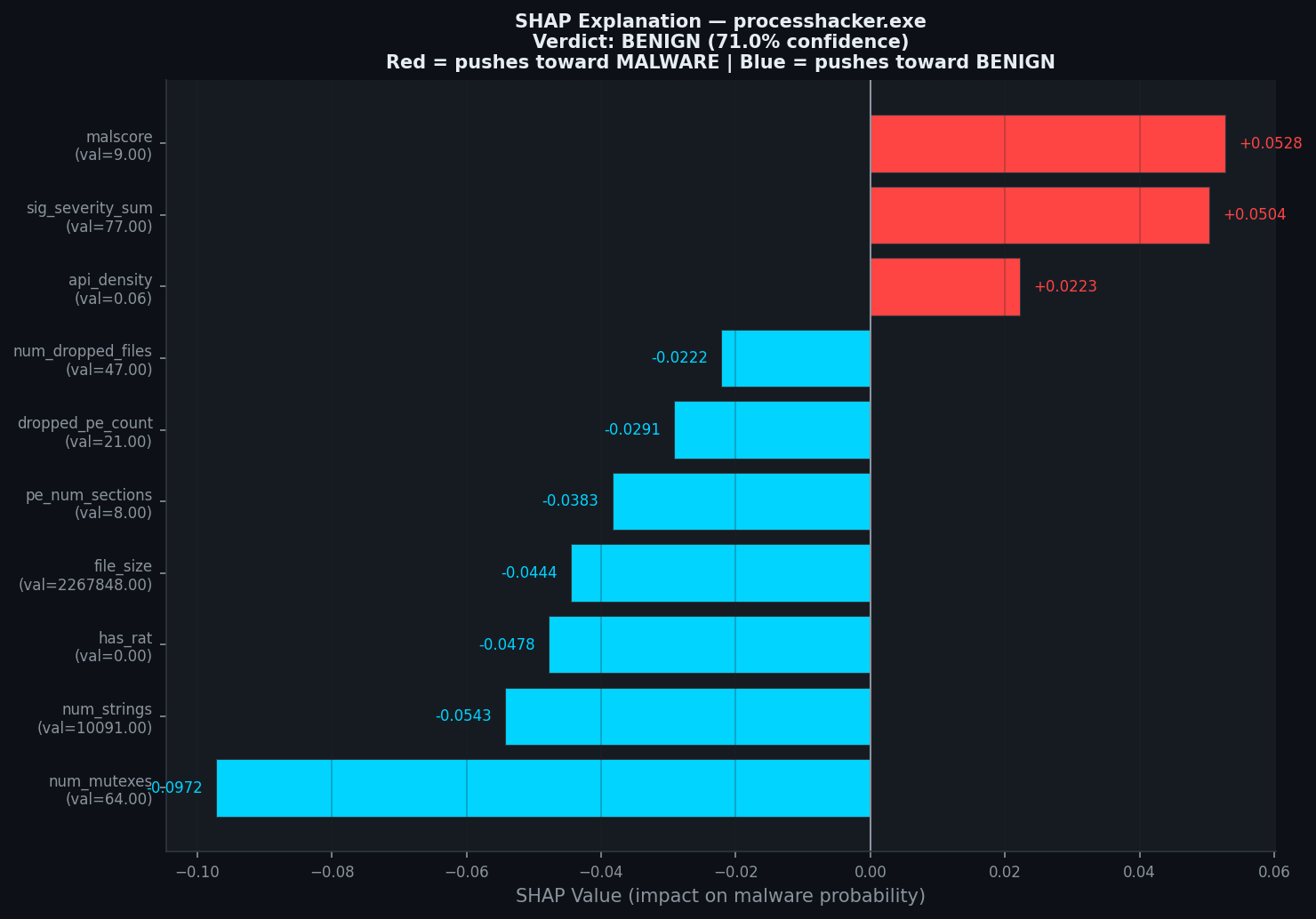
ProcessHacker 是一个合法的管理员工具,会产生高级别的签名(malscore=9,sig_severity=77)。模型正确地将其归类为 BENIGN,置信度为 71%——这是由 `num_mutexes=64`(强烈的良性信号)和 `file_size=2.2MB` 推向远离恶意软件的结果。这就是可解释 AI 在做它应该做的事情:为分析师提供可以审计的依据。
## MITRE ATT&CK 映射
19 个行为特征映射到 ATT&CK 技术。基于活跃特征在每个预测中触发,并附带 SHAP 影响分数。
| 特征 | T-Code | 技术 | 战术 |
|---------|--------|-----------|--------|
| has_ransomware | T1486 | Data Encrypted for Impact | Impact |
| has_antidebug | T1622 | Debugger Evasion | Defense Evasion |
| has_antisandbox | T1497 | Virtualization/Sandbox Evasion | Defense Evasion |
| has_process_injection | T1055 | Process Injection | Privilege Escalation |
| has_network_sig | T1071 | Application Layer Protocol | Command & Control |
| has_packer | T1027 | Obfuscated Files or Information | Defense Evasion |
| has_stealth | T1036 | Masquerading | Defense Evasion |
| has_persistence | T1547 | Boot/Logon Autostart Execution | Persistence |
| has_credential_access | T1003 | OS Credential Dumping | Credential Access |
| has_shadow_deletion | T1490 | Inhibit System Recovery | Impact |
| has_sleep_evasion | T1497 | Virtualization/Sandbox Evasion | Defense Evasion |
| has_rat | T1219 | Remote Access Software | Command & Control |
| has_keylogger | T1056 | Input Capture | Collection |
| has_uac_bypass | T1548 | Abuse Elevation Control Mechanism | Privilege Escalation |
| has_dropper | T1105 | Ingress Tool Transfer | Command & Control |
| has_infostealer | T1041 | Exfiltration Over C2 Channel | Exfiltration |
**WannaCry 的示例输出:**
```
MITRE ATT&CK TTPs Detected:
T1486 Data Encrypted for Impact (SHAP: +0.2870)
T1622 Debugger Evasion (SHAP: +0.1430)
T1027 Obfuscated Files or Information (SHAP: +0.0710)
T1071 Application Layer Protocol (SHAP: +0.0650)
```
## 特征工程(54 个特征)
### 为什么是 54 个特征而不是更多?
目标是行为信号密度,而不是原始的特征数量。每一个特征的选择都是因为它映射到一个真实的检测假设——要么是已知的恶意软件行为,要么是已知的良性误报模式。
### 动态行为特征 (46)
| 类别 | 特征 | 检测假设 |
|----------|----------|---------------------|
| CAPE 评分 | malscore, sig_severity_sum | 基于规则的总体可疑度 |
| 进程注入 | VirtualAllocEx + WriteProcessMemory + CreateRemoteThread 模式 | T1055 — 向远程进程注入代码 |
| 持久化 | Run/RunOnce/Winlogon 注册表写入 | T1547 — 在重启后存活 |
| 勒索软件 | vssadmin/wmic 影卷副本删除 | T1490 — 破坏恢复选项 |
| 逃避 | NtDelayExecution >60s | T1497 — 睡眠以绕过沙盒超时 |
| 凭据访问 | OpenProcess(lsass) + ReadProcessMemory | T1003 — 转储 LSASS |
| 网络 | unique_ips, unique_domains, smtp_connections | C2 和数据外泄活动 |
| API 密度 | api_calls/process_count 比率 | 恶意软件通常每个进程会进行大量 API 调用 |
| 签名 | num_signatures, has_antidebug, has_antisandbox 等 | 来自 CAPEv2 的直接行为标志 |
### 静态 PE 特征 (8)
| 特征 | 检测目标 |
|---------|----------------|
| pe_entropy | 高熵 = 加壳/加密 (WannaCry: 7.99) |
| pe_num_sections | 异常的节数量 = 自定义加壳工具 |
| pe_has_upx | 存在 UPX 加壳器 |
| pe_wx_section | 可写 + 可执行节 = 自解压代码 |
| pe_is_64bit | 架构(恶意软件偏向 64 位,旧工具偏向 32 位) |
| pe_is_signed | 代码签名(合法软件通常已签名) |
| pe_has_tls | TLS 回调 = 反调试技术 |
| pe_num_imports | 导入数量(加壳器很少;普通二进制文件很多) |
### 模型演进
| 版本 | 样本 | 特征 | CV F1 | 变化内容 |
|---------|---------|----------|-------|-------------|
| v1 MVP | 2 | 17 | 0.824 ±0.162 | 仅 WannaCry + EICAR |
| v2 | 103 | 17 | 0.923 ±0.042 | 添加了 MalwareBazaar 收集 |
| v3 | 104 | 46 | 0.935 ±0.015 | 添加了 PE 静态特征 |
| v4 | 176 | 46 | 0.950 ±0.016 | 扩充了数据集 |
| **v5(当前)** | **234** | **54** | **0.957 ±0.016** | 添加了比率特征,强化了提取器 |
## 代码库:逐文件说明
### `ml/feature_extractor.py`
**流水线的核心。** 解析 CAPEv2 JSON 报告并提取 54 个行为和静态特征。这个文件经历了 5 个主要版本——强化版本在每一个字段上都包含了 null 安全防护,因为格式错误的报告(截断的 JSON、缺失的行为部分、null 网络数据)会导致早期版本崩溃。混沌工程测试暴露了这些故障模式并推动了修复。
关键设计决策:
- 每一个 `report.get()` 调用都有默认值——没有任何字段访问会抛出 KeyError
- PE 特征需要 `pefile` 解析;如果 PE 头格式错误,则回退为零
- API 调用计数按进程计算然后求和的——而不是从 CAPEv2 有时会错误计算的全局计数中得出
### `ml/train_model.py`
**训练并保存 Random Forest 分类器。** 加载所有标记的样本,通过 `feature_extractor.py` 提取特征,训练一个具有平衡类别权重的 100 棵树的 Random Forest,在训练数据上进行评估,并将模型和特征名称一起序列化(pickle)。特征名称与模型一起保存,因为 `predict.py` 和 `shap_explain.py` 需要它们来正确对齐特征——早期版本中的一个错误导致了静默的特征错位。
### `ml/predict.py`
**CLI 预测工具。** 接收 CAPEv2 报告 JSON 路径,提取特征,加载模型,并打印带有置信度和顶级指标的格式化判定结果。设计旨在快速且易读——输出结构化,方便复制粘贴到事件报告中。
```
python ml/predict.py /opt/CAPEv2/storage/analyses/294/reports/report.json
```
输出:
```
==================================================
VERDICT: MALWARE
CONFIDENCE: 94.2%
MALWARE P: 94.2%
--------------------------------------------------
TOP INDICATORS:
malscore 10.0
has_ransomware 1
num_api_calls 94958
==================================================
```
### `ml/shap_explain.py`
**SHAP 可解释层——最复杂的文件。** 做三件事:
1. **全局分析** —— 在所有训练样本上运行 SHAP TreeExplainer,生成 beeswarm 图和条形图,显示整个数据集中哪些特征最重要
2. **单样本解释** —— 对于任何给定的报告,计算每个特征的 SHAP 值,生成瀑布图,打印结构化的文本解释,并保存 JSON 解释文件
3. **MITRE ATT&CK 映射** —— 将活跃的行为特征映射到 ATT&CK T-codes,并附带 SHAP 影响分数
处理 SHAP 版本并不简单。不同的 SHAP 版本返回不同形状的值(数组列表 vs 3D 数组)。代码显式处理了这两种格式。
### `ml/app.py`
**封装分类器的 Flask REST API。** 通过 multipart POST 接收 CAPEv2 报告 JSON,运行特征提取和预测,并返回结构化的 JSON。旨在每次沙盒运行后由 CAPEv2 处理流水线自动调用。
```
curl -X POST http://localhost:5000/predict \
-F "report=@/opt/CAPEv2/storage/analyses/15/reports/report.json"
```
响应:
```
{
"prediction": "MALWARE",
"confidence": 94.2,
"malware_probability": 94.2,
"features": { "malscore": 10.0, "has_ransomware": 1, ... }
}
```
### `bridge/vmrun_bridge.py` (Windows 主机)
**自定义 VMware OOB 控制层。** 在 Windows 主机上运行,并将 `vmrun.exe` 暴露为 HTTP 端点。CAPEv2 的默认机制使用 libvirt/KVM——这在 Ubuntu 运行于 VMware 内部时不起作用。该文件通过绕过 libvirt,彻底解决了嵌套虚拟化问题。
端点:`POST /vm/start`, `POST /vm/stop`, `POST /snapshot/revert`, `GET /health`
### `machinery/vmwarebridge.py`
**CAPEv2 机制模块。** 插入到 CAPEv2 的机制接口中,并将所有 libvirt 调用替换为对 `vmrun_bridge.py` 的 HTTP 调用。CAPEv2 调用 `machine.start()`——该模块将其转换为 `POST 192.168.75.1:9090/vm/start`。沙盒并不知道它正在与 VMware 通信。
### `family_holdout_cv.py`
**严格的验证脚本。** 实现了以恶意软件家族为组的 GroupKFold 交叉验证。每一折都会保留来自不相交家族集合的所有样本。同时运行按家族的分析,以识别模型在哪些家族上存在困难。将结果输出到 `docs/family_holdout_results.json`。
这种自定义分割器是刻意为之的:标准的 GroupKFold 也会对良性样本进行分组,从而产生不切实际的测试条件。此实现按家族拆分恶意软件,同时将良性样本正常分配到各折中。
### `stress_tests/test_benign_torture_final.py`
**75 样本良性误报测试。** 让每个 Windows 系统二进制文件、管理工具和开发者工具都通过完整的流水线,并断言零误报。这个测试推动发现了 malscore=9.0 的 mspaint.exe 被正确分类为 BENIGN——验证了 ML 层修正了签名的过度触发。
### `stress_tests/test_chaos_pipeline.py`
**实时故障注入。** 向运行中的流水线注入 6 种故障场景:bridge 宕机、损坏的报告、快照未命中、部分 BSON、执行超时、提取器鲁棒性。验证自愈监控器是否检测到每种情况并从中恢复。发现了 `feature_extractor.py` 中的 null 安全 Bug。
### `stress_tests/test_family_holdout.py`
**家族保留验证运行器。** 执行完整的 GroupKFold 验证并保存结果。是 `family_holdout_cv.py` 的配套文件——这是测试套件,而那是具体实现。
### `scripts/collect_malware.py`
**MalwareBazaar 收集流水线。** 通过家族标签从 MalwareBazaar API 下载恶意软件样本,从受密码保护的 ZIP 文件(密码:`infected`)中提取,验证 PE 头,写入元数据,并移动到 BIOHAZARD 收件箱以进行沙盒处理。包含暂存 + 锁定机制,以防止与提交流水线发生竞态条件。
### `scripts/submit_batch.sh`
**批量提交脚本。** 通过 REST API 将暂存的样本提交给 CAPEv2,处理速率限制,并记录结果。
## API 用法
```
# 启动 Flask API
python ml/app.py
# 从报告文件预测
curl -X POST http://localhost:5000/predict \
-F "report=@/path/to/report.json"
# CLI 预测
python ml/predict.py /path/to/report.json
# SHAP 全局分析(在 ml/shap_plots/ 中生成图表)
sudo python3 ml/shap_explain.py --global-only
# 特定样本的 SHAP 解释
sudo python3 ml/shap_explain.py --task 15
# Family holdout 验证
python3 family_holdout_cv.py
# 运行所有压力测试
python3 stress_tests/test_benign_torture_final.py
python3 stress_tests/test_chaos_pipeline.py
```
## 诚实的局限性
| 局限性 | 细节 |
|-----------|--------|
| 仅支持 PE 二进制文件 | 不支持脚本、宏、LNK、PDF、PowerShell、MSI |
| 27 个单例家族 | 每个家族只有 1 个样本——无法验证这些家族的泛化能力 |
| 无时间验证 | 未捕获收集时间戳;未测试概念漂移 |
| VMware 痕迹 | 可被具有逃避意识的恶意软件检测到 |
| 无漂移监控 | 没有自动化的再训练策略 |
| 实验室条件 | 样本来自 MalwareBazaar,而非生产遥测数据 |
## 技术栈
| 组件 | 技术 |
|-----------|-----------|
| 沙盒 | Ubuntu 24.04 上的 CAPEv2 2.5 |
| 分析 VM | Flare VM (Windows 10, Host-Only 网络) |
| OOB VM 控制 | Flask + vmrun.exe 桥接 (自定义) |
| ML 模型 | scikit-learn RandomForest (100 棵树,类别平衡) |
| 可解释性 | SHAP TreeExplainer |
| 威胁映射 | MITRE ATT&CK (19 个 TTP) |
| API | Flask REST :5000 |
| 验证 | GroupKFold、良性折磨、混沌工程 |
| 样本收集 | MalwareBazaar API |
## 验证报告
- [VALIDATION.md](docs/VALIDATION.md) — 完整的鲁棒性报告
- [family_holdout_results.json](docs/family_holdout_results.json) — 每折的 F1、召回率、FN 明细
- [benign_torture_results.json](docs/benign_torture_results.json) — 包含判定结果的所有 75 个良性样本
- [chaos_results.json](docs/chaos_results.json) — 混沌工程测试结果
**Vishva Teja Chikoti** — M.S. Cybersecurity & Networks, University of New Haven 2026
[GitHub](https://github.com/ckvishwa) · [LinkedIn](https://linkedin.com/in/vishvatejachikoti)
标签:Apex, DAST, 可解释AI, 恶意软件分析, 机器学习, 沙箱, 自动化流水线, 逆向工具