Rblea97/ai-phishing-detector-portfolio
GitHub: Rblea97/ai-phishing-detector-portfolio
基于ML与LLM双层架构的蓝队钓鱼邮件检测工具,提供可解释的威胁分析、IOC提取与MITRE ATT&CK映射,帮助SOC分析师快速准确地分拣邮件告警。
Stars: 0 | Forks: 0
# AI 钓鱼检测器
[](https://github.com/Rblea97/ai-phishing-detector-portfolio/actions/workflows/backend.yml)
[](https://github.com/Rblea97/ai-phishing-detector-portfolio/actions/workflows/frontend.yml)
[](https://github.com/Rblea97/ai-phishing-detector-portfolio/actions/workflows/codeql.yml)




**[在线演示 →](https://phishing-detector-ui-s3bf.onrender.com)** | **[观看演示视频 →](https://youtu.be/wYcv8Ve5-Sw)**
## 演示
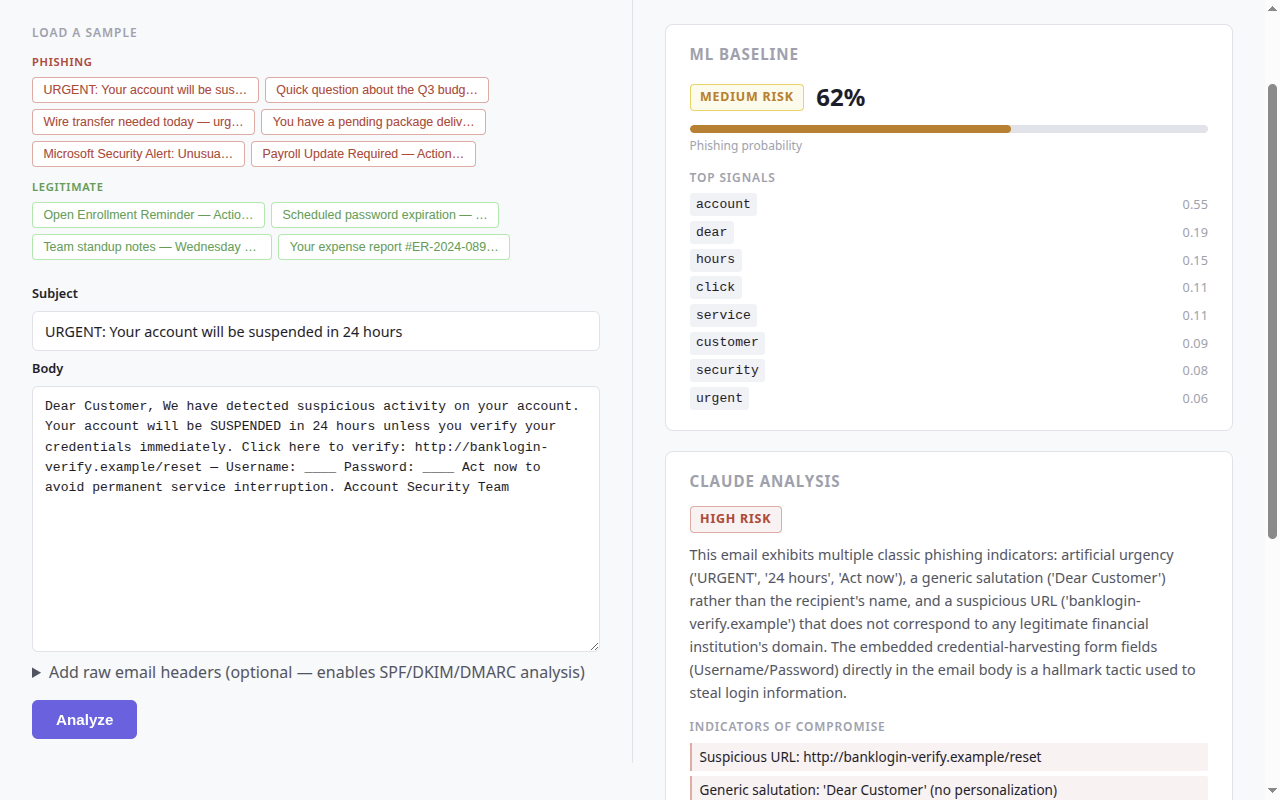
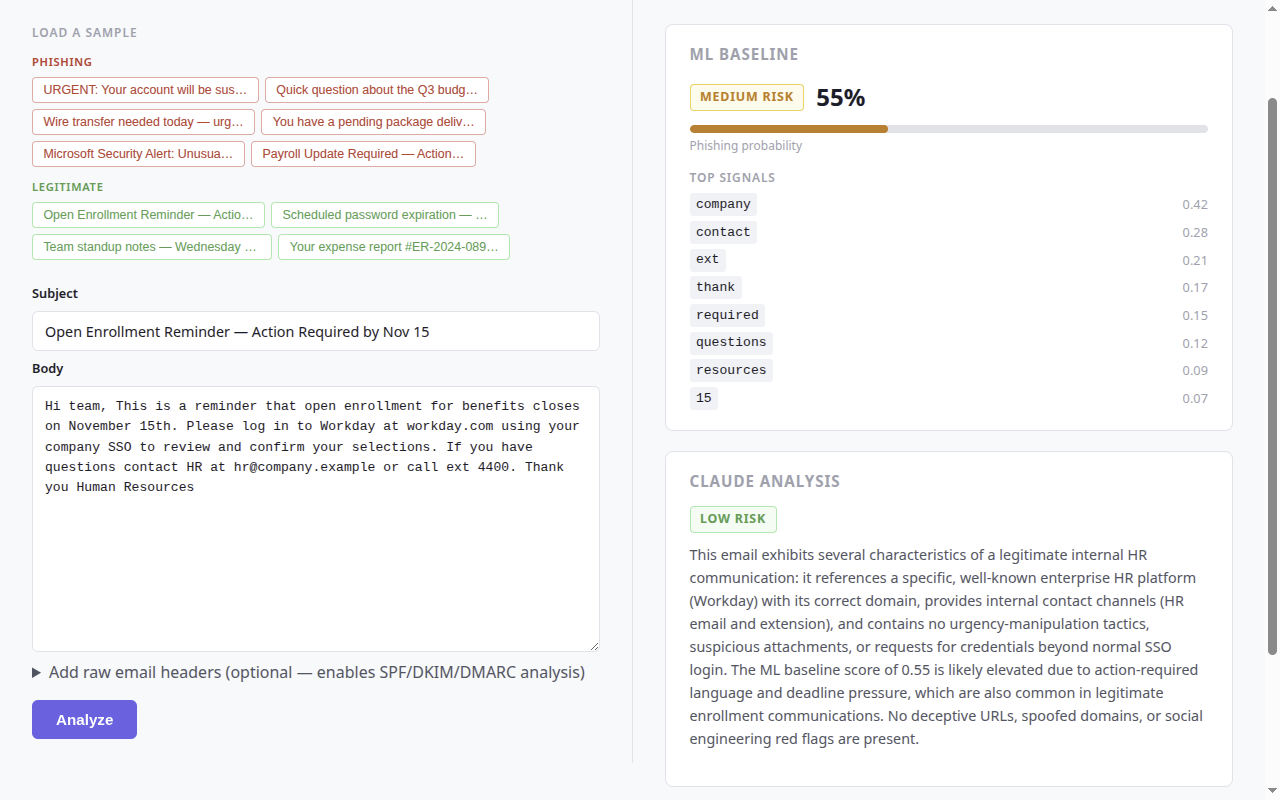
| 钓鱼邮件 | 合法邮件 |
|---|---|
|  |  |
| 头部分析 (SPF/DKIM/DMARC + 域名链) |
|---|
| 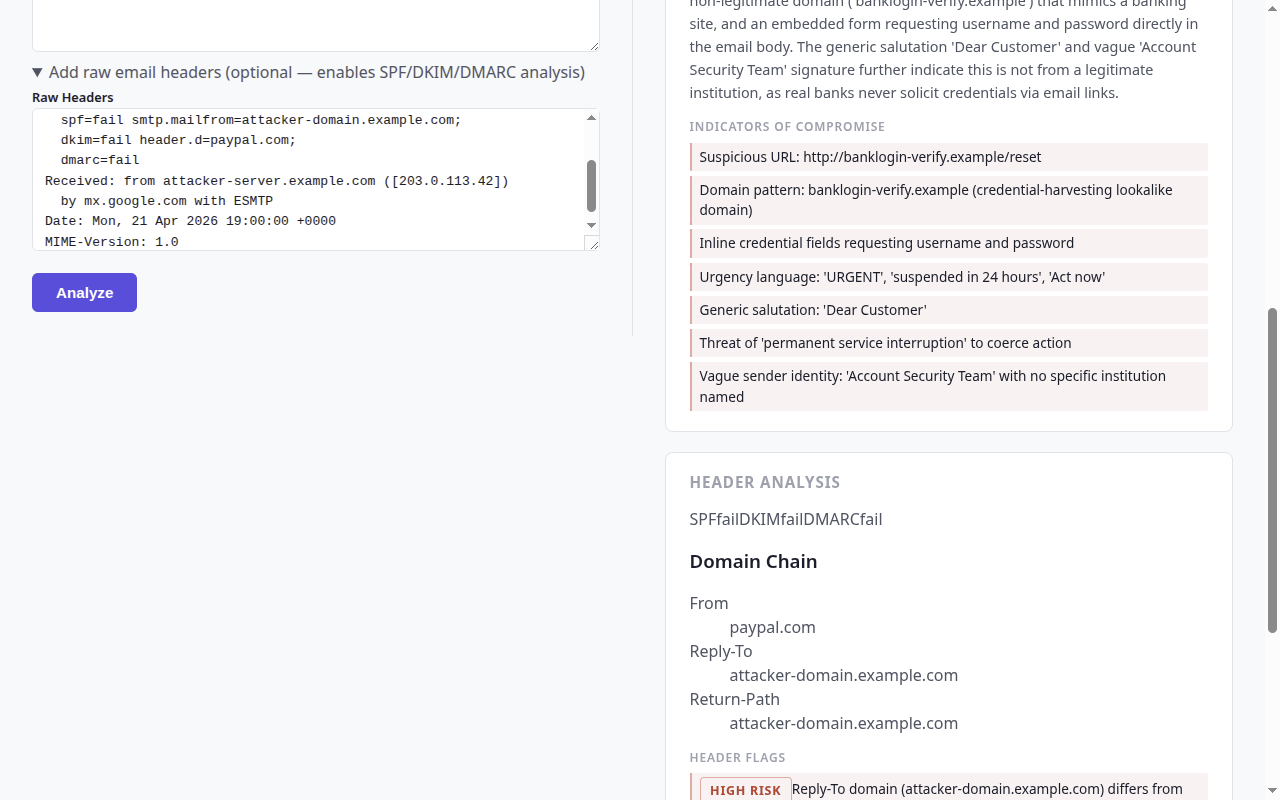 |
## 为什么会有这个项目
钓鱼攻击是所有主要威胁报告(CISA,Verizon DBIR 2025)中排名第一的**首要初始访问向量**,对应 [MITRE ATT&CK T1566](https://attack.mitre.org/techniques/T1566/)。大多数生产环境的检测器都是黑盒——SOC 分析师能看到结论,但不知道*为什么*。本项目解决了这一缺陷:每一次预测都会展示影响评分的具体 token 以及 LLM 的推理过程,让分析师能够更快地进行分拣并信任输出结果。
## 展示的蓝队概念
| 概念 | 实现 |
|---|---|
| 威胁检测 | ML 分类器在攻击类别上实现了 96.17% 的 F1 分数以标记钓鱼攻击 |
| IOC 提取 | LLM 层提取恶意 URL、催促话术和冒充模式 |
| 异常检测 | TF-IDF 特征权重揭示了统计上异常的 token 模式 |
| 告警分拣支持 | 置信度评分 + Top-N 可疑 token 支持分析师快速决策 |
| 误报管理 | 99.80% 的合法类别召回率 → ~0.20% 的 FPR,最大程度减少分析师的告警疲劳 |
| MITRE ATT&CK 映射 | 检测结果映射到 [T1566.001](https://attack.mitre.org/techniques/T1566.001/) (鱼叉式钓鱼链接) 和 [T1566.002](https://attack.mitre.org/techniques/T1566.002/) (附件) |
| 可解释性 (XAI) | 每个结论都会展示影响评分的具体 token——没有黑盒 |
| SIEM 集成 | 每个结论都会发出一个结构化的 `SiemLogEntry` (结论、严重程度、MITRE 技术、IOC),专为导入 Splunk / Elastic SIEM / Azure Sentinel 而设计 |
## 工作原理
```
flowchart LR
A["Email\nSubject + Body"] --> B["ML Layer\nTF-IDF + Logistic Regression"]
B --> C["Risk Score\n+ Feature Weights"]
A --> D["LLM Layer\nClaude claude-sonnet-4-6"]
C --> D
C --> E["React Frontend"]
D --> E
```
**ML 层** — TF-IDF 向量化器(5,000 个特征,1-2 元语法)为基于 [SpamAssassin 公开语料库](https://spamassassin.apache.org/old/publiccorpus/)(2,972 封已标记邮件)训练的 Logistic Regression 分类器提供输入。从模型的系数中提取贡献最大的 token 及其权重,并随每次预测一同返回。这就是可解释性的基石。
**LLM 层** — 邮件文本和 ML 评分被发送给 Claude,并附带一个仅限于防御性分析的结构化系统提示词。Claude 以结构化 JSON 格式返回风险评估、推理过程和入侵指标 (IOC)。LLM 层是可选的——如果不存在 API 密钥,应用程序会优雅降级为仅使用 ML。
## 结果
在预留的测试集(SpamAssassin 语料库的 20%,595 封邮件,分层抽样)上进行了评估:
| 类别 | Precision | Recall | F1 |
|---|---|---|---|
| Legitimate (合法) | 98.81% | 99.80% | 99.30% |
| Phishing (钓鱼) | 98.88% | 93.62% | 96.17% |
| **整体准确率** | | | **98.82%** |
| **误报率 (FPR)** | | | **~0.20%** |
## 技术栈
| 层级 | 技术 | 原因 |
|---|---|---|
| Backend | Python 3.12 + FastAPI | 异步、带类型提示、通过 OpenAPI 自动生成文档 |
| ML | scikit-learn (TF-IDF + LR) | 系数具有可解释性,无需 GPU |
| LLM | Anthropic Claude claude-sonnet-4-6 | 结构化 JSON 输出,仅限防御性提示词 |
| Frontend | React 19 + TypeScript (Vite) | 类型安全,构建速度快 |
| 测试 | pytest + Vitest | 124 个后端测试,16 个前端测试,98% 覆盖率 |
| CI | GitHub Actions | 每次推送时运行 Ruff、mypy、pytest、ESLint、tsc、Vitest |
| 安全扫描 | CodeQL + Dependabot | 针对 Python + JS 的 SAST;每周依赖更新 |
| 部署 | Render (免费套餐) | 通过 `render.yaml` 实现零配置 |
## 模型选择:可解释性胜过黑盒准确率
在 SOC 环境中,即使黑盒模型是准确的,也会引发分析师的不信任——分析师需要向利益相关者解释结论,而不仅仅是报告一个分数。在最终选择 Logistic Regression 之前,我评估了 Naive Bayes,原因有两点:性能和可审计性。NB 是文本分类的常见基线,训练速度更快,但 LR 在钓鱼类别上的表现优于它(F1 分数提升 +4.1 pp),因为这些特征并非条件独立——许多钓鱼邮件使用特定的 token 组合(如 "click here" + "verify account"),而不是 NB 视为互不相关的单个 token。更重要的是,LR 的系数提供了可直接解释的特征权重:正系数意味着该 token 推动了钓鱼的判定。这种可解释性是此工具在 SOC 使用场景中的核心价值主张,因此模型的选择是由可解释性需求驱动的,而不仅仅是准确率。
## 本地设置
### 前提条件
- Python 3.12+ 和 [uv](https://docs.astral.sh/uv/getting-started/installation/)
- Node.js 18+
### 后端
```
cd backend
uv sync
uvicorn app.main:app --reload
# API 位于 http://localhost:8000
# OpenAPI 文档位于 http://localhost:8000/docs
```
设置你的 Anthropic API 密钥以启用 LLM 层(可选——没有它应用程序也能正常工作):
```
export ANTHROPIC_API_KEY=sk-ant-...
# Windows PowerShell:
# $env:ANTHROPIC_API_KEY = "sk-ant-..."
```
或者将 `.env.example` 复制为 `.env` 并填入你的密钥。
### 前端
```
cd frontend
npm install
npm run dev
# App 位于 http://localhost:5173
```
## 运行测试
```
# Backend
cd backend && uv run pytest
# Frontend
cd frontend && npm test
```
## 部署
通过 `render.yaml` 部署到 [Render](https://render.com)。要部署你自己的副本:
1. Fork 本仓库
2. 访问 [render.com](https://render.com) → **New → Blueprint** → 连接你 fork 的仓库
3. 在 API 服务上将 `ANTHROPIC_API_KEY` 设置为环境变量密钥
4. Render 会自动构建并部署这两个服务
ML 模型工件 (`backend/model/pipeline.joblib`) 已提交到仓库中,因此在部署时无需执行训练步骤。
## 项目结构
```
backend/ FastAPI app, ML model, Claude API integration
frontend/ React/TypeScript UI
data/ Labeled email corpus (SpamAssassin, Apache 2.0)
scripts/ Playwright demo recording script
```
*仅供防御和安全教育使用。不包含钓鱼生成或攻击性工具。*
SIEM 日志输出示例
``` { "timestamp": "2026-04-21T20:00:00Z", "event_type": "email_threat_assessment", "verdict": "PHISHING", "severity": "HIGH", "confidence": 0.97, "mitre_technique": "T1566.001", "iocs": ["verify your account immediately", "http://banklogin-verify.example/reset"], "header_flags": ["spf_fail", "reply_to_mismatch"], "analyst_notes": "Email exhibits classic credential-harvesting pattern..." } ```标签:AI钓鱼检测, Apex, AV绕过, DKIM, DLL 劫持, DMARC, FastAPI, Python, React, Sigma 规则, SOC分析师, SPF, Syscalls, UI界面, XAI, 初始访问, 前端, 可解释性, 后端, 域名分析, 大语言模型, 失陷标示提取, 威胁情报, 安全分析与运营, 安全规则引擎, 开发者工具, 开源, 无后门, 机器学习, 电子邮件威胁检测, 管道, 网络安全, 逆向工具, 隐私保护, 黑盒解释