Wilsons-Navid/Wilsons_Navid_Wado_Tiwa_rl_summative
GitHub: Wilsons-Navid/Wilsons_Navid_Wado_Tiwa_rl_summative
在模拟企业网络中训练并对比四种强化学习算法(PPO、DQN、A2C、REINFORCE)用于自主威胁狩猎的效果,并提供可视化与API部署方案。
Stars: 1 | Forks: 0
# CyberShield Threat Hunter — 基于任务的强化学习

**学生姓名:** Wado Tiwa Wilsons Navid
**课程:** Machine Learning Techniques II
**作业:** 总结性作业 - 基于任务的强化学习
## 概述
一个用于在模拟企业网络中进行自主网络威胁狩猎的强化学习智能体。该智能体在由14个节点组成的网络拓扑中导航,以在累积损害超过临界阈值之前检测并清除隐藏的威胁(恶意软件、后门、加密货币挖矿程序、数据窃取)。
四种强化学习算法——PPO、DQN、A2C 和 REINFORCE——在48种超参数配置下进行了训练。表现最佳的智能体(PPO)作为 Flask REST API 部署,并提供实时 Web 仪表盘,同时在 Unity 3D 中进行了可视化。
## 目录
- [概述](#overview)
- [Unity 3D 可视化](#unity-3d-visualization)
- [问题描述](#problem-statement)
- [环境](#environment)
- [智能体](#agent)
- [动作空间](#action-space-discrete-6-actions)
- [观测空间](#observation-space)
- [奖励结构](#reward-structure)
- [终止条件](#terminal-conditions)
- [算法与训练结果](#algorithms-and-training-results)
- [训练奖励曲线](#training-reward-curves)
- [算法比较](#algorithm-comparison)
- [超参数比较](#hyperparameter-comparison)
- [损失与熵曲线](#loss-and-entropy-curves)
- [收敛图](#convergence-plots)
- [泛化测试](#generalization-test)
- [奖励与训练时间](#reward-vs-training-time)
- [Flask REST API 与 Web 仪表盘](#flask-rest-api--web-dashboard)
- [API 端点](#api-endpoints)
- [API 响应示例](#example-api-response)
- [Web 仪表盘](#web-dashboard)
- [开始使用](#getting-started)
- [设置](#setup)
- [训练](#training)
- [运行智能体](#running-the-agent)
- [Unity 3D 设置](#unity-3d-setup)
- [项目结构](#project-structure)
## Unity 3D 可视化
| | | |
|:---:|:---:|:---:|
| 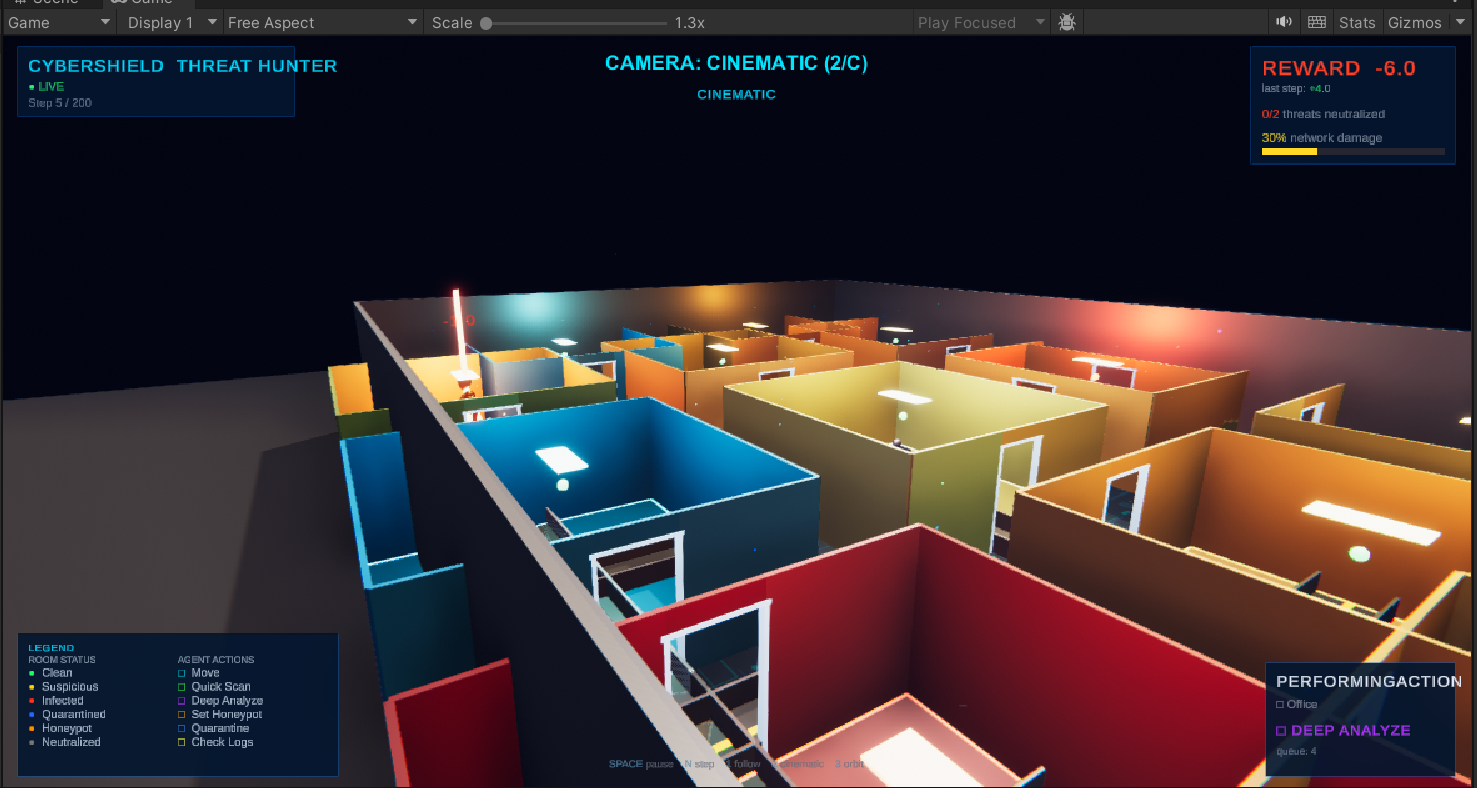 |  |  |
| *电影视角 — 完整房屋布局* | *观察者视角 — 俯视全景* | *跟随摄像头 — 走廊中的智能体* |
|  | 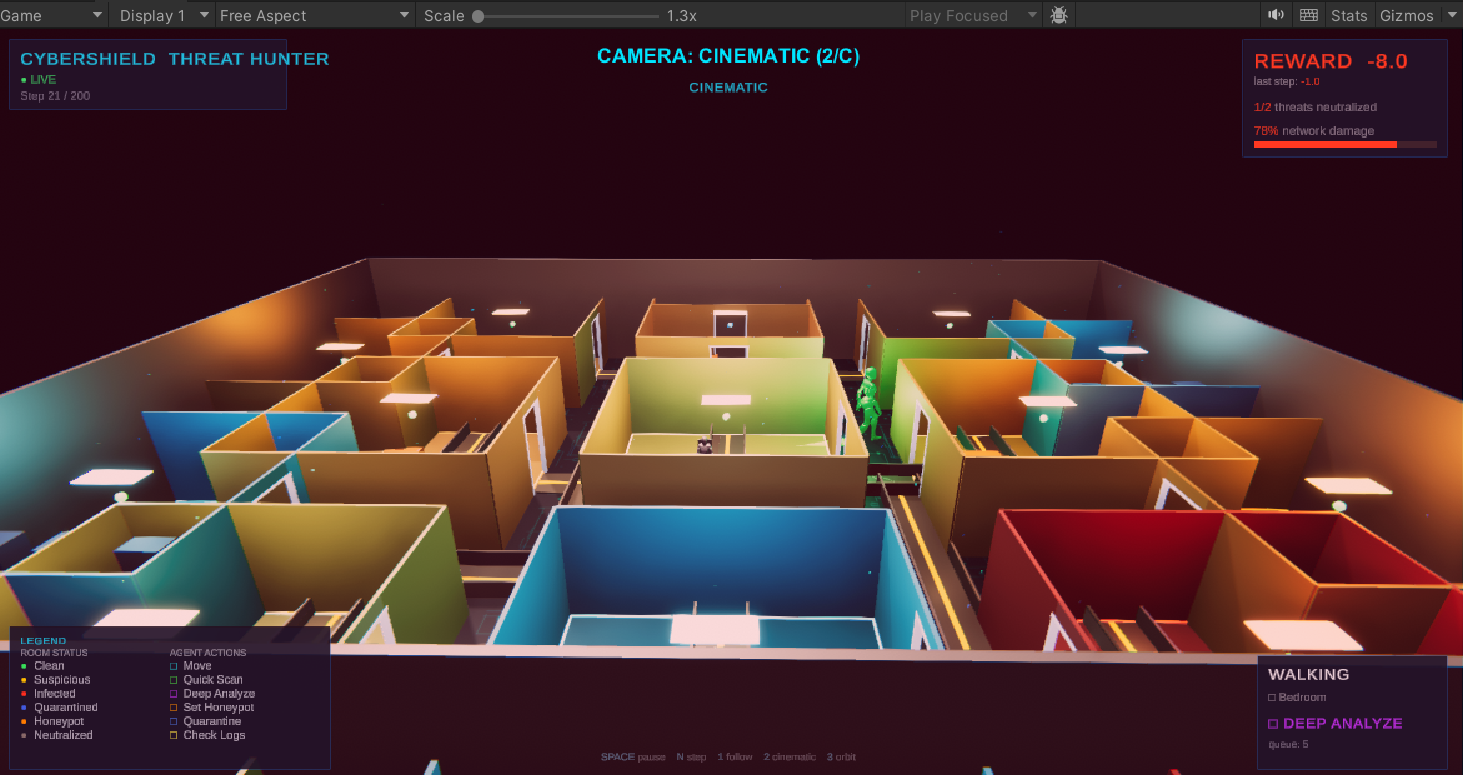 |  |
| *跟随摄像头 — 智能体穿门导航* | *电影视角 — 被感染的房间 (红色)* | *观察者视角 — 智能体获得 +2.0 奖励* |
该环境在 Unity 3D 中以程序化生成的14个房间的智能家居呈现。每个房间代表一个网络节点,根据威胁状态进行颜色编码:绿色 (干净)、黄色 (可疑)、红色 (被感染)、蓝色 (已隔离)、橙色 (蜜罐)、灰色 (已清除)。智能体使用 BFS 寻路算法在房间之间的走廊中导航。提供三种摄像头模式:跟随 (F)、电影 (C) 和观察者 (O)。
## 问题描述
企业网络面临着日益复杂的网络威胁,需要快速的检测和响应。本项目训练一个强化学习智能体以自主巡逻网络,通过扫描和日志分析识别受损节点,并隔离威胁——在彻底性与紧迫性之间取得平衡,因为未被发现的威胁会造成持续的破坏。
## 环境
模拟企业网络的自定义 Gymnasium 环境 (`environment/custom_env.py`):
- **14个节点**,分为5种类型:防火墙、路由器、服务器、数据库、工作站
- **4种威胁类型**,具有不同的破坏率、传播率和隐蔽级别
- 威胁在每个时间步长演进:造成破坏、向相邻节点传播,并波动异常特征
### 智能体
智能体(“威胁狩猎无人机”)在网络节点之间移动,以调查、分析和清除威胁。它必须在彻底性(深度扫描)、紧迫性(威胁会造成持续破坏)和准确性(误报会受到惩罚)之间取得平衡。
### 动作空间 (离散,6种动作)
| 动作 | 名称 | 描述 |
|--------|------|-------------|
| 0 | MOVE | 导航至相邻节点 |
| 1 | QUICK_SCAN | 快速扫描 — 检测概率 = 1 - stealth |
| 2 | DEEP_ANALYZE | 深度分析 — 检测概率 = 1 - stealth x 0.3 |
| 3 | SET_HONEYPOT | 部署蜜罐;每个步骤有20%的几率暴露威胁 |
| 4 | QUARANTINE | 隔离节点 — 如果正确则中和,如果误报则 -5 |
| 5 | CHECK_LOGS | 检查历史活动;中等检测率 |
### 观测空间
连续的 `Box(89,)` 向量:
- **节点特征** (14个节点 x 6 = 84维):CPU 使用率、内存使用率、网络异常分数、自上次扫描以来的时间、威胁指示级别、隔离状态
- **全局特征** (5维):智能体位置、剩余时间、威胁清除率、破坏级别、蜜罐数量
所有值均归一化至 [0, 1]。
### 奖励结构
| 事件 | 奖励 |
|-------|--------|
| 每个时间步长 | -1.0 |
| 快速扫描检测到威胁 | +2.0 |
| 深度分析确认威胁 | +5.0 |
| 在被感染节点设置蜜罐 | +1.0 |
| 正确隔离 | +10.0 |
| 误报隔离 | -5.0 |
| 检查日志发现可疑活动 | +1.5 |
| 所有威胁被清除 (奖励) | +25.0 |
### 终止条件
1. **成功:** 所有威胁被清除 (+25 奖励)
2. **失败:** 累积损害 >= 100 (严重违规)
3. **超时:** 达到100个时间步长
## 算法与训练结果
使用四种强化学习算法进行训练,**每种算法配置12组超参数** (总共48次实验):
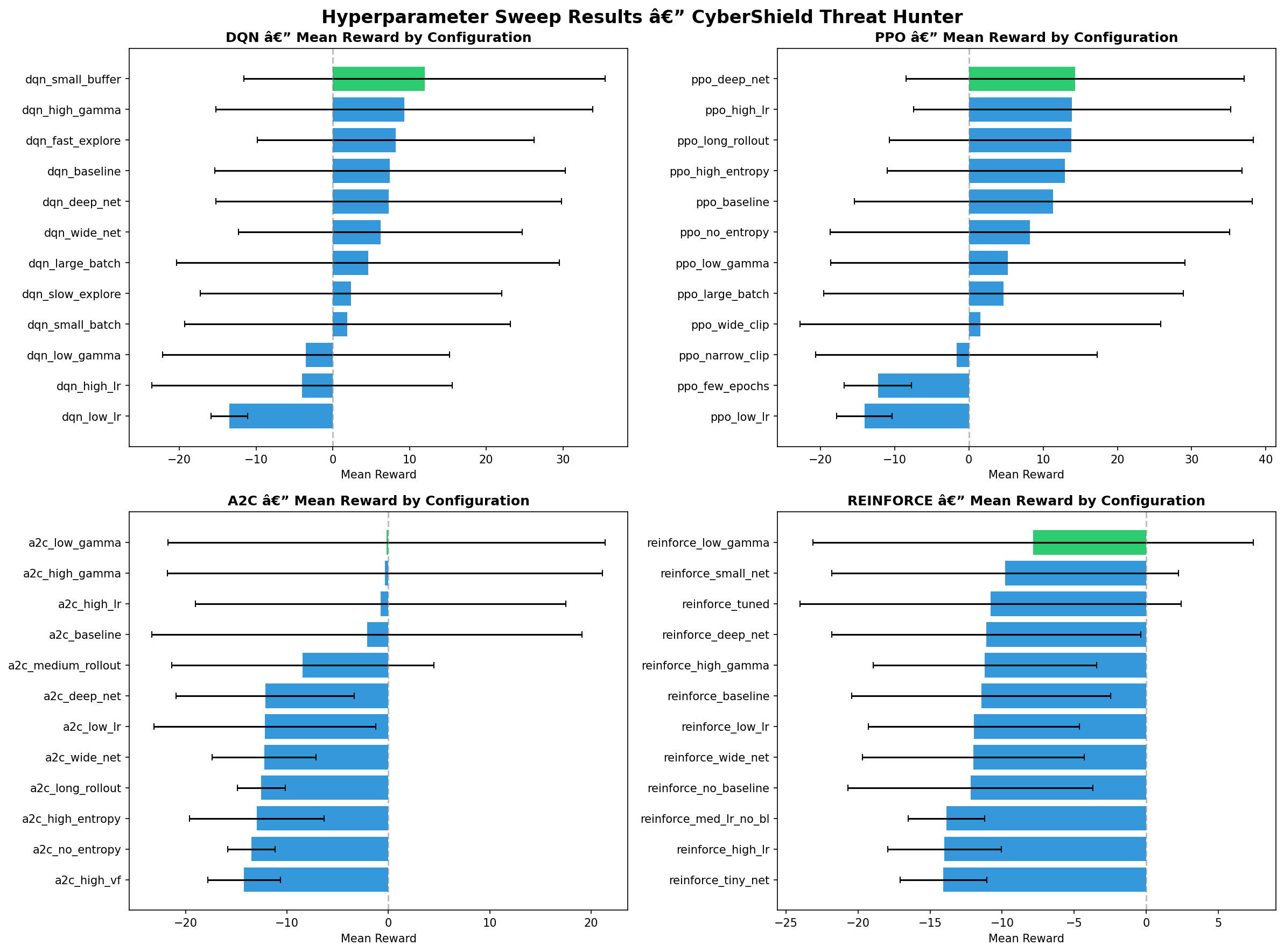
| 算法 | 库 | 最佳配置 | 平均奖励 |
|-----------|---------|-------------|-------------|
| **PPO** | Stable Baselines 3 | deep_net [256,256,128] | **+14.30** |
| **DQN** | Stable Baselines 3 | small_buffer (10K) | +11.98 |
| **A2C** | Stable Baselines 3 | low_gamma (0.9) | -0.18 |
| **REINFORCE** | Custom PyTorch | low_gamma (0.9) | -7.85 |
PPO 凭借更深的网络架构取得了最佳性能。DQN 表现同样出色,且具有更好的训练效率。
### 训练奖励曲线
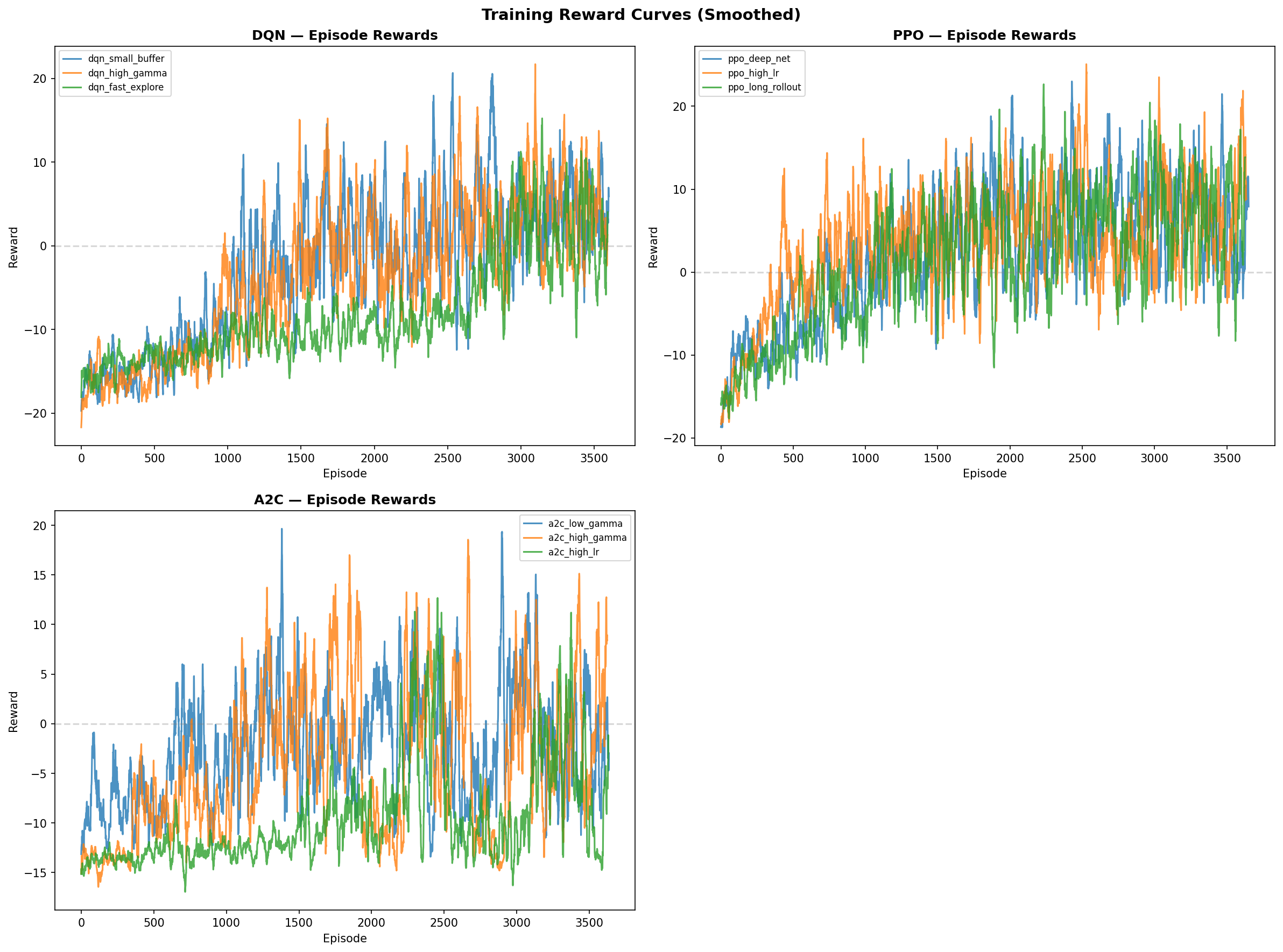
所有48组超参数实验(每种算法12组)的累积奖励曲线。PPO 和 DQN 配置持续达到正向奖励,而 A2C 和 REINFORCE 则表现出更高的方差和较慢的收敛速度。
### 算法比较
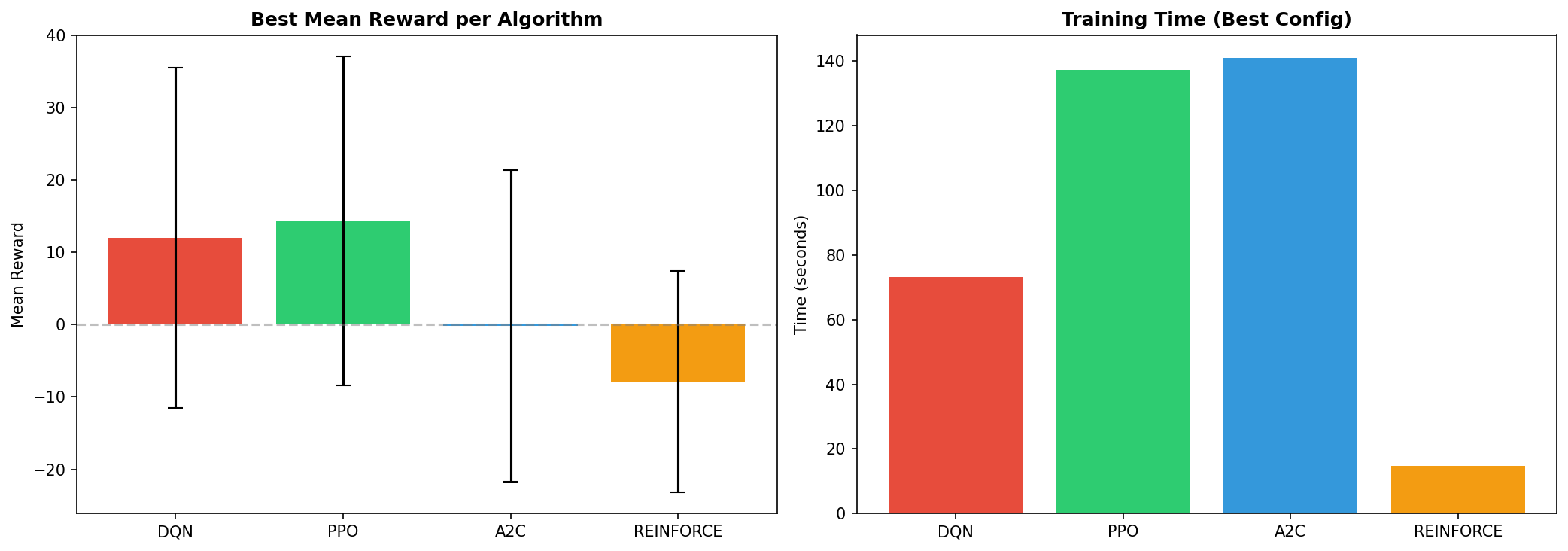
每种算法最佳配置的并列比较。PPO (deep_net) 获得了最高的平均奖励 (+14.30),其次是 DQN (small_buffer) 的 +11.98。
### 超参数比较
### 损失与熵曲线
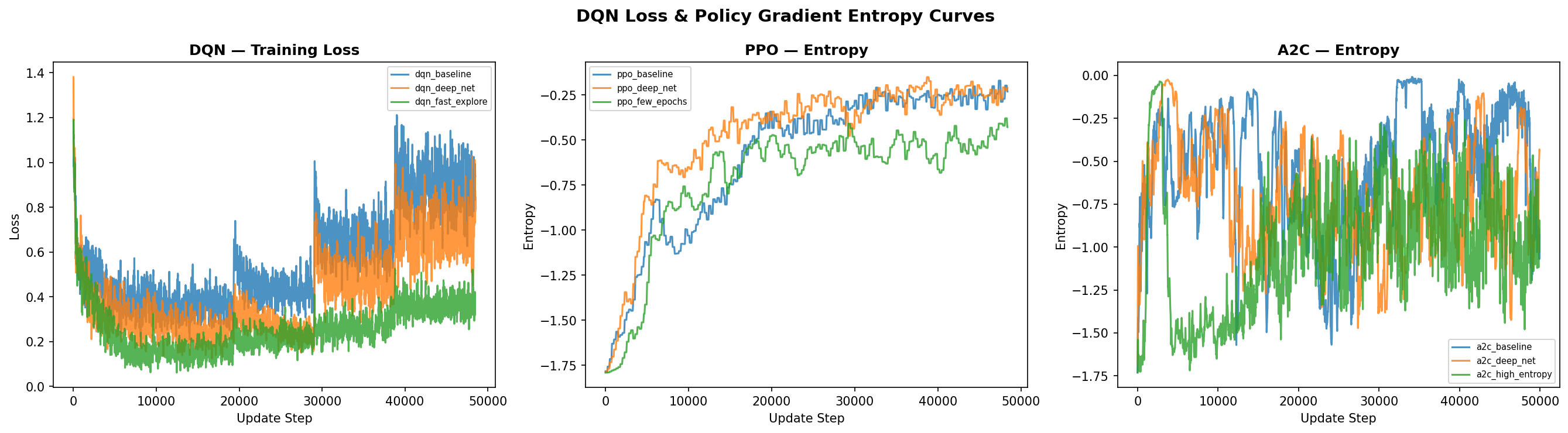
DQN 损失曲线和训练期间的策略梯度熵。熵衰减表明,随着训练的进行,智能体从探索过渡到了利用。
### 收敛图
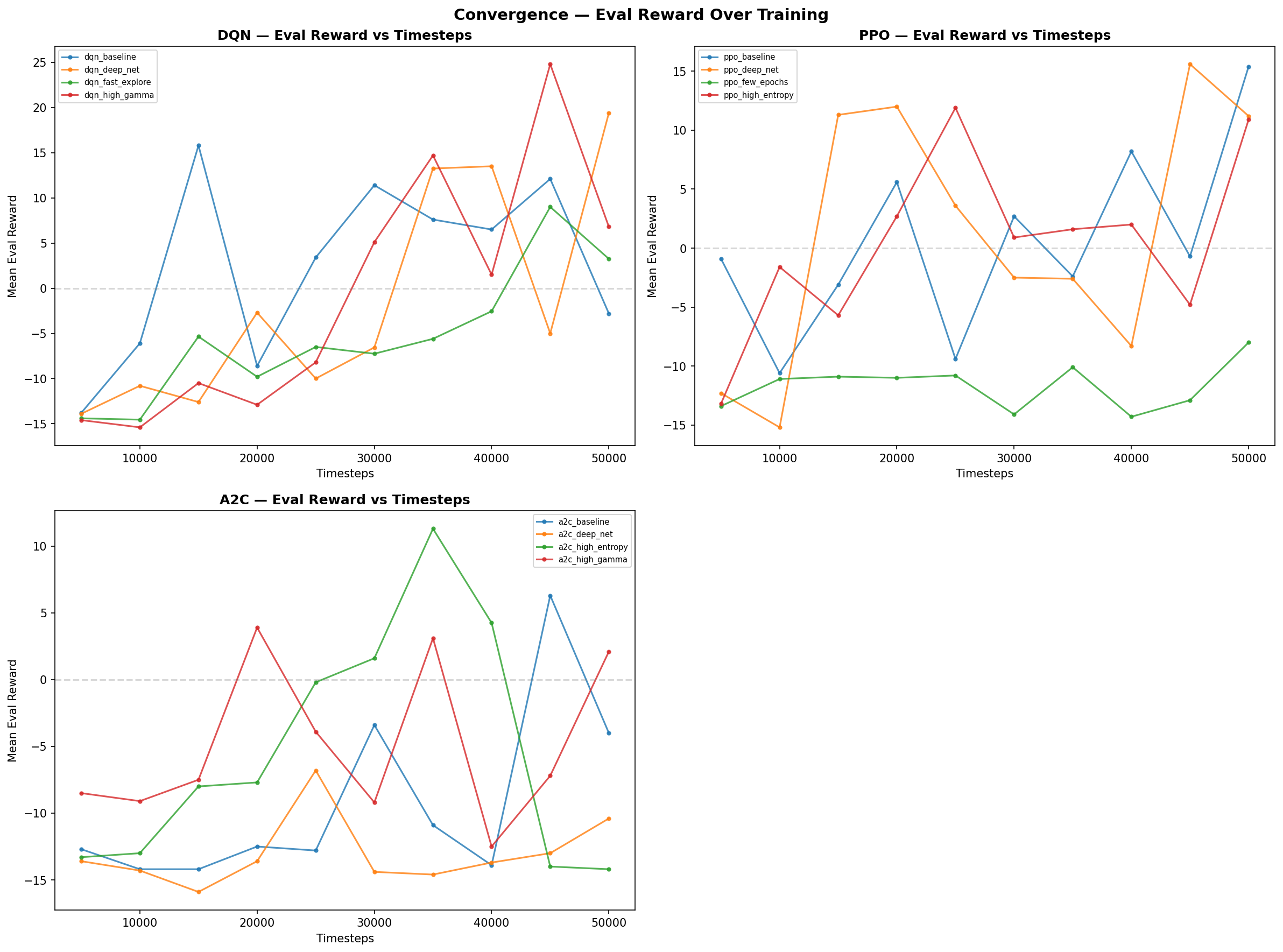
收敛分析展示了每种算法稳定的速度。PPO 在3万个时间步长内收敛;DQN 耗时略长,但能达到稳定的策略。
### 泛化测试
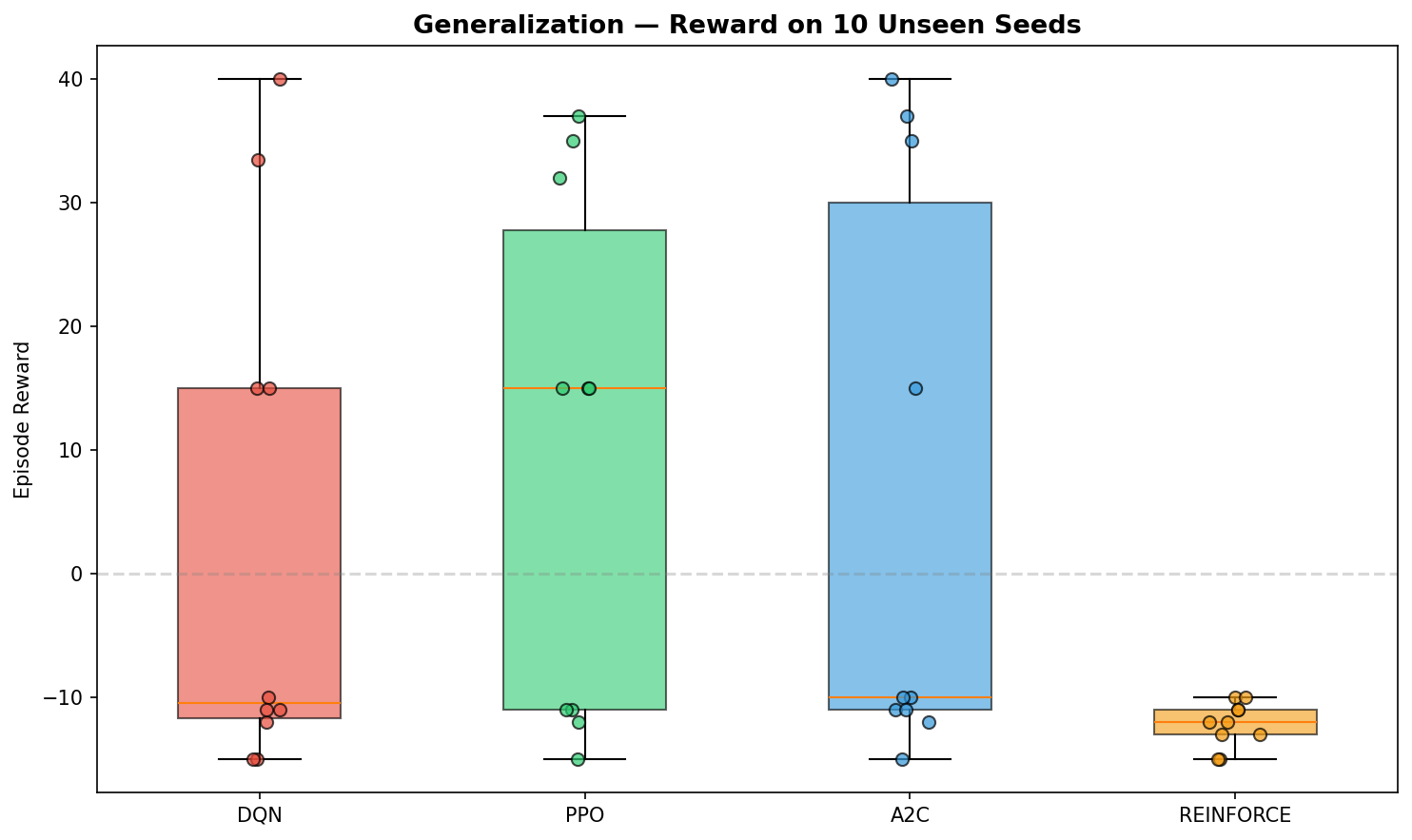
在10个未见过的随机种子上的表现。PPO 泛化能力最强,在5/10的种子上获得了正向奖励。DQN 在4/10的种子上实现了泛化。
### 奖励与训练时间
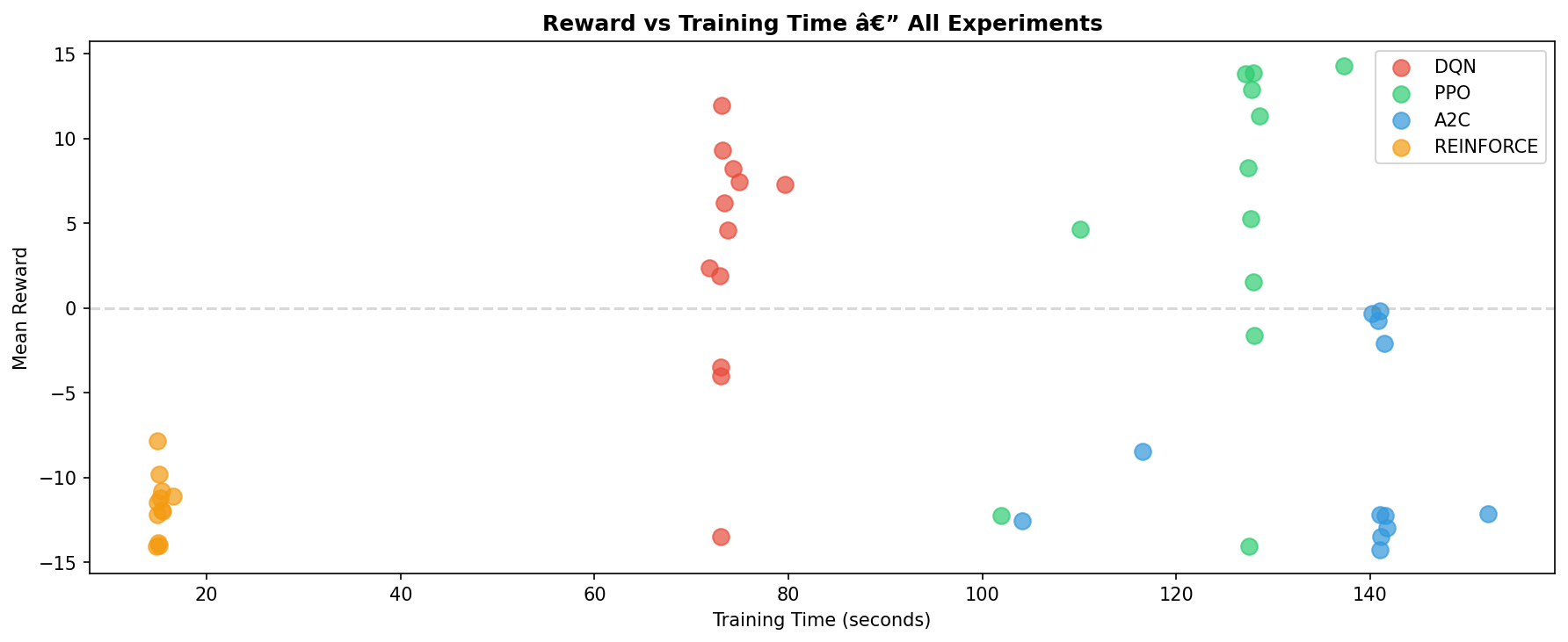
训练效率比较。DQN 提供了最佳的奖励时间比 (在73秒内达到 +11.98),而 PPO 耗时较长,但达到了更高的峰值性能。
**主要发现:**
- 学习率是所有算法中影响最大的超参数
- 较高的折扣因子有利于 DQN(长期规划);较低的折扣因子则有利于策略梯度方法(方差减少)
- PPO 泛化能力最强:在5/10的未见种子上获得了正向奖励
- DQN 提供了最佳的奖励时间比 (在73秒训练内达到 +11.98)
## Flask REST API 与 Web 仪表盘
训练好的智能体通过 Flask 作为生产就绪的 JSON API 提供服务。部署版本在线地址:
**[https://wilsons-navid-wado-tiwa-rl-summative.onrender.com](https://wilsons-navid-wado-tiwa-rl-summative.onrender.com)**
本地运行:
```
python api.py # Start on port 5000 (default: PPO model)
python api.py --algorithm dqn # Use DQN model
python api.py --port 8080 # Custom port
```
### API 端点
| 端点 | 方法 | 描述 |
|----------|--------|-------------|
| `/` | GET | 实时 Web 仪表盘 |
| `/health` | GET | 健康检查及模型状态 |
| `/info` | GET | 环境和模型元数据 |
| `/reset` | POST | 重置环境,返回初始状态 |
| `/step` | POST | 根据智能体的动作执行一步操作 |
| `/predict` | POST | 根据给定的观测值获取动作 |
### API 响应示例
`GET /health`
```
{
"status": "ok",
"model_loaded": true,
"algorithm": "ppo"
}
```
`POST /step`
```
{
"action": 0,
"action_name": "MOVE",
"reward": -1.0,
"terminated": false,
"truncated": false,
"done": false,
"observation": [0.45, 0.32, "..."],
"state": { "nodes": ["..."], "agent_pos": 3 }
}
```
### Web 仪表盘
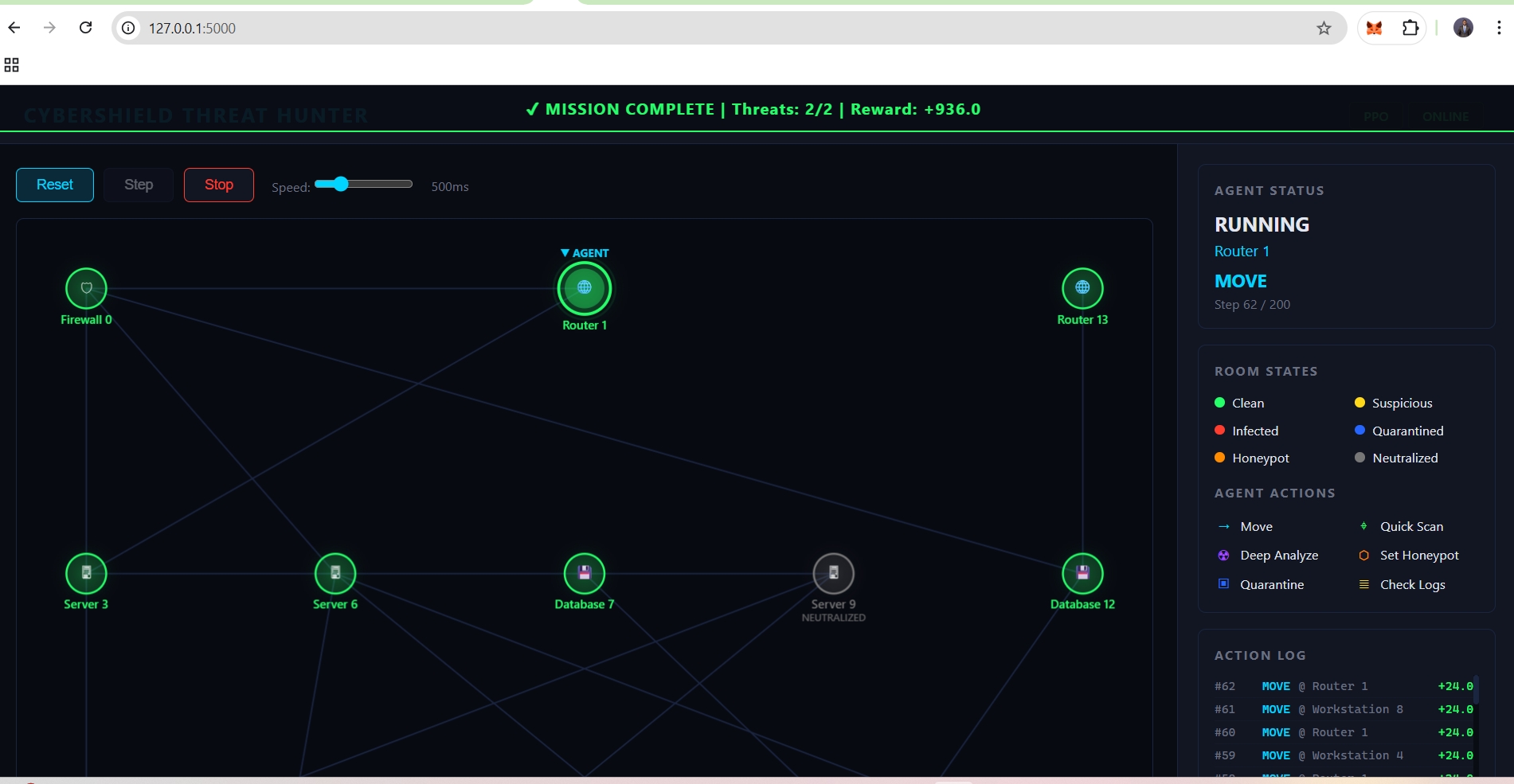
根路由 (`/`) 提供了一个包含以下功能的单页面仪表盘:
- 带有颜色编码节点状态的 Canvas 2D 网络图
- 实时控制(重置、步进、自动运行、速度滑块)
- 实时指标(奖励、已清除威胁、破坏进度条)
- 智能体状态面板和滚动操作日志
## 开始使用
### 设置
```
pip install -r requirements.txt
```
**环境要求:** Python 3.9+、PyTorch >= 2.0.0、Stable Baselines 3 >= 2.3.0、Gymnasium >= 0.29.0、Flask、NumPy、Matplotlib、Pandas、TensorBoard
### 训练
```
# 训练 DQN (12 个超参数实验)
python training/dqn_training.py --timesteps 50000
# 训练 PPO 和 A2C (各 12 个实验)
python training/pg_training.py --timesteps 50000
# 训练 REINFORCE (12 个实验,自定义实现)
python training/reinforce_training.py --episodes 500
# 仅训练特定实验
python training/dqn_training.py --experiment dqn_baseline
```
训练结果和图表保存至 `results/`。
### 运行智能体
```
# 使用文本渲染运行最佳模型 (默认: PPO)
python main.py --render human
# 运行特定算法
python main.py --algorithm dqn --render human
# 使用 Unity 3D 可视化运行
python main.py --render unity
# 运行随机智能体 (基线对比)
python main.py --random --render human
```
### Unity 3D 设置
1. 在 Unity 2022 LTS 中打开 `unity_viz2/` 项目
2. 打开主场景并按下 Play
3. 在项目根目录运行 `python main.py --render unity`
4. Unity 通过 TCP socket(端口 9876)连接并实时渲染
## 项目结构
```
rl_summative/
├── environment/
│ ├── custom_env.py # CyberThreatHuntEnv (Gymnasium)
│ ├── network_graph.py # Network topology generation
│ └── rendering.py # Unity TCP socket bridge
├── training/
│ ├── dqn_training.py # DQN hyperparameter sweep (12 configs)
│ ├── pg_training.py # PPO & A2C hyperparameter sweep (12 each)
│ └── reinforce_training.py # Custom REINFORCE implementation (12 configs)
├── models/
│ ├── dqn/ # Saved DQN models
│ └── pg/ # Saved PG models (PPO, A2C, REINFORCE)
├── results/ # Training plots, CSVs, and Unity/web screenshots
├── templates/
│ └── index.html # Web dashboard (served by Flask)
├── unity_viz2/ # Unity 3D visualization project
├── docs/ # Generated report (DOCX/PDF)
├── main.py # Entry point for running best model
├── api.py # Flask REST API with web dashboard
├── render.yaml # Render deployment configuration
├── requirements.txt # Python dependencies
└── README.md # This file
```
标签:3D可视化, A2C, AMSI绕过, Apex, CyberShield, DQN, Flask, IP 地址批量处理, PPO, Python, REINFORCE, REST API, RL, Unity 3D, Web 仪表盘, 人工智能, 优势演员评论家, 凭据扫描, 后门检测, 威胁检测, 强化学习, 挖矿程序检测, 损失函数, 收敛性分析, 无后门, 无线安全, 机器学习, 机器学习课程作业, 机器学习项目, 模拟企业网络, 泛化测试, 流量捕获, 深度Q网络, 熵曲线, 用户模式Hook绕过, 策略梯度, 算法对比, 网络安全, 网络安全审计, 网络拓扑, 网络模拟, 自主网络威胁狩猎, 自动化威胁响应, 超参数优化, 近端策略优化, 逆向工具, 隐私保护