Theepankumargandhi/Ai-incident-commander-langgraph-autogen
GitHub: Theepankumargandhi/Ai-incident-commander-langgraph-autogen
基于 LangGraph 和 AutoGen 构建的实时 DevOps 事件响应平台,通过多智能体协同与自动化工作流大幅缩短运维故障分诊与修复时间。
Stars: 0 | Forks: 0
# AI 事件指挥官
[](https://github.com/Theepankumargandhi/Ai-incident-commander-langgraph-autogen/actions/workflows/ci.yml)
AI 事件指挥官是一个实时的 DevOps 事件响应平台,展示了智能体 AI 如何在发生真实服务故障时为运维人员提供支持。
该项目结合了用于工作流编排的 LangGraph、用于多智能体调查的 AutoGen、用于后端控制平面的 FastAPI,以及用于指挥中心风格操作控制台的 Next.js。它的设计初衷是像一个真正的内部平台,而不仅仅是一个聊天机器人演示。
当前的架构在 `10 阶段 LangGraph 工作流`中使用了 `12 个智能体的 AutoGen 调查团队`,这使得该系统感觉更像是一个内部事件智能平台,而不是一个简单的智能体演示。
## 问题所在
在发生活跃事件期间,工程师通常需要花费最初的 `15 到 20 分钟`来收集跨仪表板、日志、发布历史、操作手册和过去工单的上下文信息,然后才能决定采取安全的初步行动。这种延迟代价高昂,因为当人工运维人员还在拼凑事件全貌时,服务性能其实已经下降了。
AI 事件指挥官将这一上下文收集阶段压缩为一个结构化的 AI 辅助分诊工作流。该平台不再强迫工程师在互不相干的工具中搜寻信息,而是汇总证据、排列可能的根本原因、提出可控的修复建议,并在同一个界面中明确审批边界。
## 当前已实现的功能
当前版本是一个强大的端到端平台原型,具备真实的连接器路径和安全的回退机制。
### 已具备的实际功能
1. FastAPI 事件 API 和 WebSocket 重放流
2. LangGraph 风格的编排,包含可观测性、记忆、图谱、多模态、反馈、因果、调查、策略、执行和评估阶段
3. AutoGen 多智能体运行时,支持特定路由的 Planner、Investigator、Critic 和 Commander 模型选择
4. 扩展的 AutoGen 协作,包含 runbook、发布关联、因果、图谱、Artifact、反馈、修复审查和事后总结撰写等角色
5. 用于事件处理和基准测试包的后台作业执行
6. 基于 Postgres 的持久化存储,在本地演示模式下可自动回退到 JSON 存储
7. 规范化的 Postgres 投影,用于事件、运行、操作、策略决策、基准测试、记忆和修复凭证
8. Prompt 配置文件基准测试,包含分数、置信度、Judge 评分以及跨模型路由的回归跟踪
9. 历史事件记忆,支持对症状、指标、先前的修复质量、抽象经验和服务 Playbook 进行加权检索
10. LLM as a judge 评分,针对根因质量、证据充分性、操作安全性、解释质量和事后总结有用性提供启发式回退机制
11. 基于规则的反思和纠正,在最终确定之前修改有风险或微弱的建议
12. 合成事件生成,用于应对噪声、不完整、误报和困难的基准测试场景
13. 基于服务依赖、传播路径和发布关联的因果根因推理
14. 对抗性事件模拟实验室,用于应对噪声、冲突和级联故障的基准测试场景
15. 自我改进的优化器,可根据基准测试历史推荐更好的配置文件、模型路由、记忆策略和 Prompt 调整
16. 运行比较、故障分类分析、根因趋势和 Markdown 事后总结导出
17. 基于 Bearer token 的查看者、操作员和修复访问控制
18. 结构化日志加上 OpenTelemetry 链路追踪,配置为通过 OTLP collector 导出到 AWS X-Ray
19. GitHub 发布关联支持,用于提供预发环境和部署的上下文
20. 受控的修复网关,具有操作白名单、环境防护和可审计的凭证
21. Next.js 操作员控制台,具备角色感知操作、模型路由选择、排队作业、运行比较、审批备注、修复历史、Judge 输出、受众总结、对抗性实验室执行、优化器指导、反馈学习和图谱上下文
22. Dockerfiles 和 docker compose 本地部署支持
23. Artifact 引导的多模态推理,可基于附件 Grafana 截图、架构图和链路追踪 Artifact 的标题、描述、提取的文本、注解和相关服务链接进行分析
24. 人工反馈学习,可将批准、否决和纠正整合到未来的调查中
25. 服务知识图谱,提供爆炸半径、依赖路径和基于图谱的因果推理
26. 在工作流将证据交给 AutoGen 之前,对 Prometheus 指标历史进行 Isolation Forest 异常检测
27. 基于 RAG 的 Runbook 检索,可索引 Markdown 或文本程序,对其进行 Embedding,并在 AutoGen 开始之前引用匹配的片段
28. DORA 和 SRE 可靠性分析,提供 MTTR、变更失败率、部署频率、自动化、延迟、成本和阻止操作指标
### 具备安全回退行为的真实连接器
1. Prometheus 可作为真实的可观测性数据源。如果未配置,平台将回退到本地的合成可观测性快照。
2. Slack 可以通过 `chat.postMessage` 发送真实通知。如果未配置,消息仍会在本地记录,以便重放和演示。
3. Jira 可以通过 Jira Cloud REST API 创建真实的 Issue。如果未配置,工单记录仍会存储在本地。
4. 受控修复可以调用真实的内部 HTTP endpoint。如果未配置,运行仍会记录修复凭证,而不是静默失败。
5. AutoGen 可以运行由真实模型支持的多智能体调查。如果模型访问不可用,平台将回退到确定性的本地调查路径。
## 基准测试结果
下表数据捕获于 `May 5, 2026`,通过在三个默认 Prompt 配置文件中运行内置的五案例样本基准测试包得出。本次特定捕获是在本地演示模式下进行的,因此平台使用了已实现的启发式 judge 回退和离线 embedding 回退,而不是托管的模型调用。
| 配置文件 | 案例数 | 根因质量 | 操作安全分数 | 平均置信度 | Judge 评分 | 根因匹配率 |
| --- | --- | --- | --- | --- | --- | --- |
| `balanced-v1` | 5 | 81.60 | 78.40 | 0.796 | 94.60 | 1.00 |
| `conservative-v1` | 5 | 71.40 | 72.00 | 0.732 | 87.00 | 1.00 |
| `aggressive-v1` | 5 | 81.60 | 78.40 | 0.872 | 94.60 | 1.00 |
`根因质量` 和 `操作安全分数` 是根据每次运行的评估子分数计算的平均值。`Judge 评分` 是评估器的判断值,当托管的 judge 模型不可用时,会回退到已实现的启发式 judge。
## 架构

```
flowchart TD
A[Incident arrives from API or sample injection] --> B[Incident is stored]
B --> C[observe: load observability and release context]
C --> D[memory: retrieve related incidents and playbooks]
D --> E[graph: build service graph context and blast radius]
E --> F[multimodal: analyze artifact text, annotations, and service links]
F --> G[feedback: load approvals, overrides, and operator corrections]
G --> H[causal: rank likely dependency and release-driven causes]
H --> I[investigate: 12-agent AutoGen team produces root cause, evidence, summaries, and actions]
I --> J[policy: verdict each action as allow, block, or approval-required]
J --> K{Human approval required}
K -->|Yes| L[Pause run and wait for operator decision]
L --> M[execute: resume with approved actions]
K -->|No| M[execute: run safe actions immediately]
M --> N[finalize: evaluate run, persist outputs, and update memory]
N --> O[Refresh API, replay rail, analytics, optimizer, and benchmark history]
```
```
sequenceDiagram
participant Operator
participant Console as Next.js Console
participant API as FastAPI
participant Graph as LangGraph 10-stage workflow
participant Team as AutoGen 12-agent team
participant Policy
participant Exec as Connector Executor
participant Store
Operator->>Console: Create or select incident
Console->>API: Process incident or queue benchmark run
API->>Graph: Start workflow
Graph->>Graph: Observe signals and fetch release metadata
Graph->>Graph: Retrieve memory, graph context, multimodal artifacts, and feedback
Graph->>Team: Run multi-agent investigation
Team-->>Graph: Root cause, evidence, summaries, and recommended actions
Graph->>Policy: Evaluate action safety
Policy-->>Graph: Allow, block, or require approval
Graph->>Exec: Execute safe or approved actions
Exec-->>Store: Persist tickets, messages, and remediation receipts
Graph-->>Store: Persist run, memory updates, evaluation, and postmortem output
API-->>Console: Return updated incident state
API-->>Console: Stream replay events and refreshed benchmark data
```
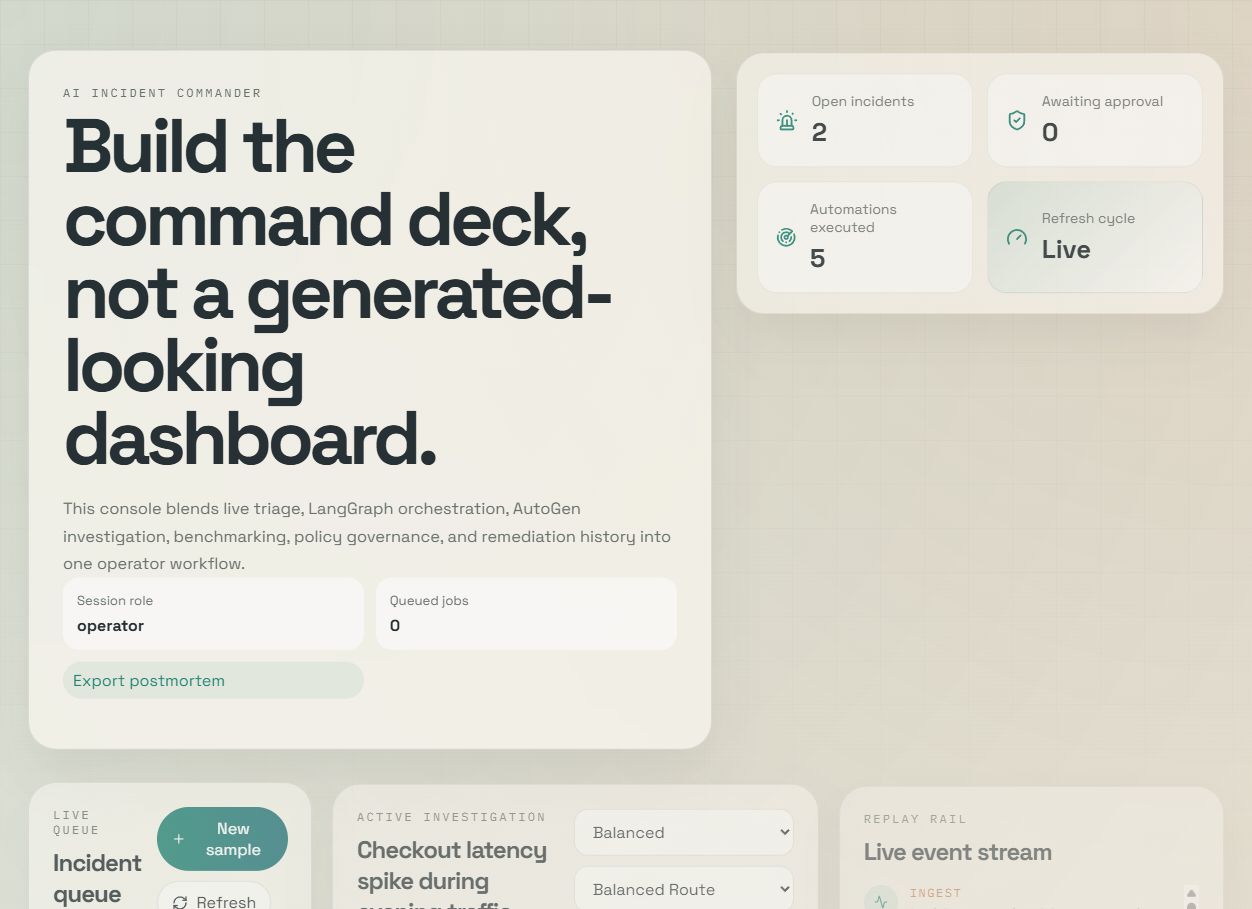
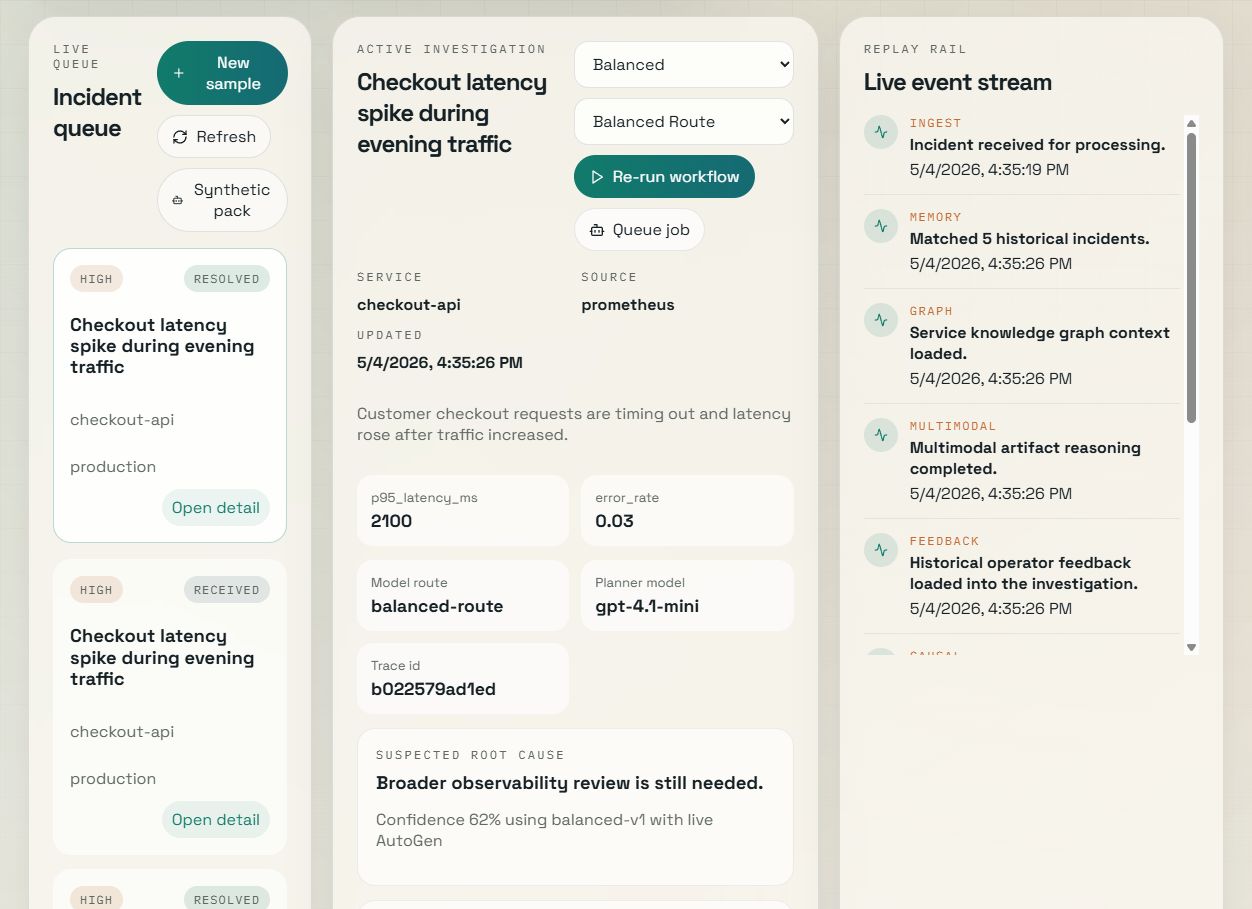
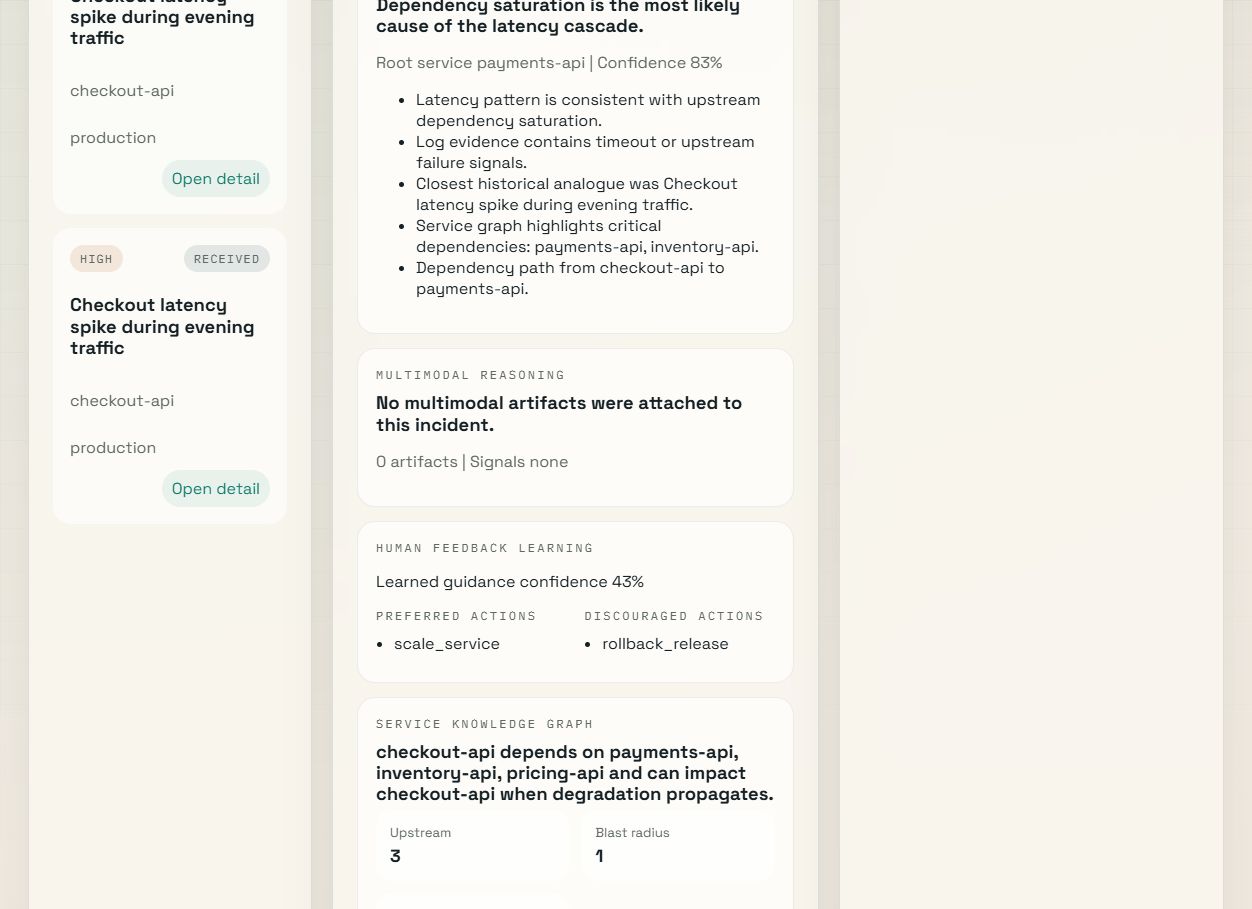
## 产品截图
### 命令面板概览
### 活跃调查与重放流
### GenAI 推理层
### 核心职责
1. `LangGraph` 负责外部工作流。
2. `AutoGen` 负责该工作流内部的调查团队。
3. `FastAPI` 提供 API、健康检查和事件流。
4. `Next.js` 为操作员提供一个实时指挥面板。
5. 存储层可以在 Postgres 上运行,并在本地演示模式下回退到 JSON。
### 高级平台功能
当前的代码库还包含以下更高权重的工程层:
1. 用于异步事件和基准测试执行的后台 worker
2. Postgres payload 存储之上的规范化关系投影
3. OpenTelemetry 链路追踪,具有按阶段和按智能体的 span,携带 `incident_id` 和 `run_id`,旨在通过集群内的 ADOT collector 流入 AWS X-Ray
4. 模型路由,以便不同的智能体角色可以使用不同的模型
5. 加权历史记忆检索和搜索
6. 自动生成事后总结和 Markdown 导出
7. 前端中角色感知的操作员工作流
8. 同一事件不同运行之间的重放比较
9. 针对反复出现的根因、故障分类和基准测试性能的分析
10. 来自 GitHub Actions 元数据的发布关联,用于具备预发感知的调查
11. 面向操作员、高管、工程师和事后总结受众的解释包
12. 用于强化基准测试的合成事件生成
13. 在主要的多智能体调查开始之前,基于服务依赖图的因果推理
14. 对抗性模拟和优化器循环,将基准测试历史转化为系统改进建议
15. 基于截图描述、提取的注解、架构说明和追踪文本的 Artifact 引导多模态推理
16. 操作员反馈学习,改变未来的指导建议、首选操作和不建议的操作
17. 服务图谱推理,利用爆炸半径和依赖路径丰富因果分析
18. RAG runbook 检索,具有服务和环境过滤器、embedding 回退,并在事件上下文中持久化引用
19. 通过 API 暴露并在指挥面板中渲染的 DORA/SRE 计分卡分析
## 调查栈
### 智能体设计理由
1. `PlannerAgent` 将事件分解为一个清晰的调查计划,并决定哪些证据流应该优先处理。它应当与最终的合成保持分离,因为过早围绕一个预设答案进行规划会降低团队其余部分的作用。
2. `InvestigatorAgent` 在团队得出结论之前,通过工具收集可观测性数据、历史记忆和策略上下文。它不应与 runbook 或 commander 角色合并,因为原始证据收集需要比撰写摘要更严格的、来源优先的 Prompt。
3. `RunbookAgent` 从以前的事件中提取可复用的修复模式、服务 Playbook 提示和经验教训。它应与 `InvestigatorAgent` 保持独立,以免历史指导掩盖了当前事件的独特性。
4. `ReleaseCorrelationAgent` 将部署和发布元数据隔离为一个独立的假设流。它不应被合并到一般调查中,因为发布信号往往很诱人但却具有误导性,因此当将其视为可证伪的专家观点时会更安全。
5. `CausalAnalystAgent` 对传播路径、可能的根服务和依赖驱动的故障链进行推理。它需要与图谱解释保持区别,因为因果排序与仅仅描述拓扑结构是不同的。
6. `VisualReasoningAgent` 处理来自截图、图表和追踪 Artifact 的 Artifact 元数据、提取的文本、注解以及相关服务链接。它应当与日志和指标分析保持分离,因为 Artifact 解释使用了不同的证据形态和不同的故障模式。
7. `GraphReasoningAgent` 解释围绕焦点服务的服务图谱、爆炸半径以及上游或下游影响。它不应与 `CausalAnalystAgent` 合并,因为图谱结构是稳定的上下文,而因果推理是在该上下文之上构建的概率性结论。
8. `CriticAgent` 对草拟的调查进行压力测试,查找缺失的证据、薄弱的假设和过度自信的结论。它必须与 `CommanderAgent` 保持独立,以便最终答案受到挑战而不是自我批准。
9. `FeedbackLearningAgent` 将先前的批准、否决和操作员纠正引入当前运行。它不应与 runbook 层合并,因为人工反馈是关于操作员实际响应方式的规定性指导,而不仅仅是通用的历史流程。
10. `RemediationReviewerAgent` 对操作安全性进行评分,并将可逆操作与风险操作区分开来。它与通用的 Critic 保持独立,因为修复治理是一个比广泛的调查质量更狭窄的、受策略制约的问题。
11. `PostmortemWriterAgent` 从同一个事件中准备面向操作员、高管、工程师和事后总结的摘要。它不应与 `CommanderAgent` 合并,因为特定受众的沟通应在最终的结构化 payload 锁定之前有其独立的处理过程。
12. `CommanderAgent` 将团队的工作转化为最终的结构化调查结果、操作集、解释包和 JSON payload。它应当位于链的末端,因为当每个专家都已做出贡献且批判循环已完成时,合成推理的效果才最强。
### LangGraph 工作流阶段
外部工作流目前按以下顺序进行:
1. observe (观察)
2. memory (记忆)
3. graph (图谱)
4. multimodal (多模态)
5. feedback (反馈)
6. causal (因果)
7. investigate (调查)
8. policy (策略)
9. execute (执行)
10. finalize (完成)
## 实时价值
在真实的 SRE 或 DevOps 环境中,该平台帮助团队减少人工分诊工作并以更高的一致性进行响应。
典型场景包括:
1. 结账延迟激增
2. 部署后错误率升高
3. 与旧的事后总结相匹配的反复发生的事件
4. 修复在执行前必须经过策略门控的事件
主要不仅仅在于分析,而在于安全的行动。
该系统帮助团队从人工救火转向 AI 辅助分诊、经过策略检查的执行以及可重放的事件历史记录。
## 操作员体验
前端被设计为一个事件指挥面板,而不是一个通用的管理仪表板。
主控制台包括:
1. 实时事件队列
2. 活跃调查面板
3. 运行事件重放轨道
4. 基准测试比较和回归历史
5. 模型路由选择和角色感知的操作员操作
6. 严重程度分布分析
7. 工单、通知和修复凭证
8. 记忆抽象、连接器状态、排队作业和评估上下文
9. 事后总结导出和先前运行比较
10. Judge 评分、基于规则的反思记录和面向特定受众的摘要
11. 调查视图中的 Artifact 引导多模态推理、反馈学习和服务图谱上下文
此外,在 `/incidents/[incidentId]` 还有一个专用的详情路由,以便可以在完整上下文中审查单个事件。
## 连接器矩阵
| 层级 | 真实路径 | 回退路径 |
| --- | --- | --- |
| 存储 | Postgres 集合 | 本地 JSON 存储 |
| 可观测性 | Prometheus 即时查询 | 本地合成指标和日志 |
| 通知 | Slack `chat.postMessage` | 存储的消息记录 |
| 工单管理 | Jira Issue 创建 | 存储的工单记录 |
| 修复 | 带有白名单和环境检查的受控网关 | 存储的修复凭证 |
| 调查 | AutoGen 加上 OpenAI 模型 | 确定性启发式调查 |
## 安全与访问模型
该项目包含轻量级的基于角色的 Bearer token 检查,支持三个访问级别:
1. viewer (查看者)
2. operator (操作员)
3. remediation endpoint caller (修复 endpoint 调用者)
这被故意设计得很简单,以便该仓库在本地仍然易于运行。
对于真正的生产部署,通常会将后端放置在以下组件之后:
1. 真实的身份提供者
2. 服务端会话层
3. 具有适当用户 claims 的反向代理
当前的 token 模型对于内部演示、Postman 工作流、CI 检查和受控的本地部署仍然很有用。
## 健康检查与可观测性 Endpoint
后端暴露了一些有用的运维 endpoint:
1. `GET /health`
2. `GET /health/live`
3. `GET /health/ready`
4. `GET /health/connectors`
这些 endpoint 使得验证服务是否存活、是否就绪、是在真实模式下运行还是在每个连接器的回退模式下运行变得十分容易。
## Runbook RAG 引擎
后端包含一个用于操作员 Runbook 的轻量级 RAG 层。它可以从 `RUNBOOK_DIR` 获取 Markdown 和文本文件,使用配置好的 OpenAI endpoint 生成 embedding,并在模型访问不可用时回退到确定性的本地 embedding。
有用的路由:
1. `POST /runbooks/ingest` 索引 `RUNBOOK_DIR` 下的每一个 `.md`、`.markdown` 和 `.txt` 文件
2. `POST /runbooks` 直接存储或更新一个 Runbook 文档
3. `GET /runbooks` 列出已索引的文档
4. `GET /runbooks/search?query=latency&service=checkout-api` 返回带有来源、分数、服务和环境元数据的排序代码片段
在事件处理过程中,匹配的 Runbook 片段会在 memory 阶段被写入 `incident.context.runbook_hits`。AutoGen runbook 角色会在最终建议生成之前读取这些引用,因此操作流程和历史记忆都会为调查提供参考。
## DORA 和 SRE 指标
`GET /analytics/dora-sre` 返回所选时间窗口的可靠性计分卡。仪表板会计算 DORA 风格的部署频率、变更失败率、失败部署恢复时间,以及包括 MTTR、自动化成功率、运行成功率、操作阻止率、p95 运行延迟、平均运行成本和重复服务率在内的 SRE 运营指标。
前端指挥面板在 DORA/SRE 面板中渲染此响应,以便操作员可以在活跃事件工作流数据旁边查看交付和可靠性信号。
## Webhook 集成
后端可以直接从 PagerDuty 和 OpsGenie 获取告警 webhook,将其转换为首要事件,并立即触发调查工作流。
| 提供者 | Endpoint | 验证 |
| --- | --- | --- |
| PagerDuty | `POST /webhooks/pagerduty` | 使用 `PAGERDUTY_WEBHOOK_SECRET` 在 `x-pagerduty-signature` 中进行 HMAC SHA-256 签名验证 |
| OpsGenie | `POST /webhooks/opsgenie` | 使用 `OPSGENIE_WEBHOOK_SECRET` 在 `x-opsgenie-webhook-secret` 中进行静态 token 验证 |
PagerDuty v2 payload 从第一个 `messages[]` 事件映射而来。OpsGenie payload 从 `alert` 映射而来。在这两种情况下,平台都会将标题、严重性、服务、环境、指标提示和告警详情提取到 `incident.context.alert_details` 中。
如果您的 OpsGenie 集成在不同的 header 名称下发送 token,请设置 `OPSGENIE_WEBHOOK_SECRET_HEADER`。
## 插件开发指南
该平台从 `app/plugins/builtin/` 加载内置插件,并从 `PLUGIN_DIR` 加载自定义插件。插件实现了 `app/plugins/base.py` 中的某个抽象基类:`ObservabilityPlugin`、`NotificationPlugin`、`RemediationPlugin` 或 `AgentPlugin`。
加载的插件可以在 `GET /plugins` 中看到,包含 `name`、`type`、`version` 和 `status` 信息。可以通过 `app.plugins.registry.get_plugin(type, name)` 进行运行时查找。
最小化的自定义 Datadog 可观测性插件:
```
# $PLUGIN_DIR/datadog_plugin.py
import os
import httpx
from app.plugins.base import ObservabilityPlugin
class DatadogPlugin(ObservabilityPlugin):
name = "datadog"
version = "0.1.0"
def __init__(self, settings=None):
self.api_key = os.getenv("DATADOG_API_KEY", "")
self.app_key = os.getenv("DATADOG_APP_KEY", "")
self.base_url = os.getenv("DATADOG_API_BASE", "https://api.datadoghq.com")
def collect_metrics(self, incident):
query = f"avg:trace.http.request.duration{{service:{incident.service}}}"
response = httpx.get(
f"{self.base_url}/api/v1/query",
params={"from": "now-5m", "to": "now", "query": query},
headers={"DD-API-KEY": self.api_key, "DD-APPLICATION-KEY": self.app_key},
timeout=5,
)
response.raise_for_status()
points = response.json().get("series", [{}])[0].get("pointlist", [])
latest = points[-1][1] if points else 0
return {"p95_latency_ms": float(latest or 0)}
def collect_logs(self, incident):
return [f"Datadog metric query completed for {incident.service}"]
```
设置 `PLUGIN_DIR=/path/to/plugins`,重启后端,然后在 `GET /plugins` 中检查 `datadog`。
## 重要的 API Endpoint
除了健康检查路由之外,还有一些 endpoint 在演示和评估期间特别有用:
1. `POST /incidents/{incident_id}/process` 运行或排队调查
2. `POST /benchmarks/sample/run` 运行或排队样本基准测试包
3. `GET /jobs` 检查后台工作
4. `GET /analytics/summary` 查看根因和故障趋势
5. `GET /runs/compare` 比较同一事件的两次运行
6. `GET /runs/{run_id}/postmortem.md` 导出 Markdown 事后总结
7. `GET /memory/search` 查询存储的事件记忆
8. `GET /model-routes` 检查可用的模型路由策略
9. `POST /synthetic/benchmark-cases` 生成更难的基准测试案例
10. `POST /synthetic/incidents` 生成并可选择持久化合成事件
11. `POST /lab/adversarial/run` 执行对抗性模拟和评估实验室
12. `GET /optimizer/recommendation` 检查基准测试历史中最新的优化器指导
13. `POST /incidents/{incident_id}/artifacts` 附加多模态事件 Artifact
14. `GET /service-graph` 检查服务依赖图或特定服务范围的视图
15. `GET /feedback/summary` 检查针对某项服务学习到的操作员指导
16. `POST /runs/{run_id}/feedback` 记录纠正、否决和操作员偏好
17. `POST /runbooks/ingest` 索引 `RUNBOOK_DIR` 中的 Runbook 文件
18. `GET /runbooks/search` 检索针对某个事件或服务的 Runbook 片段
19. `GET /analytics/dora-sre` 检查 DORA 和 SRE 可靠性指标
## 仓库结构
```
autogen/
app/
core/
integrations/
services/
workflow/
config.py
main.py
models.py
data/
docs/
architecture/
assets/
frontend/
src/
Dockerfile
next.config.ts
package.json
tests/
.env.example
Dockerfile
docker-compose.yml
requirements.txt
README.md
```
## 环境配置
### 后端环境
将 `.env.example` 复制到 `.env`,并仅填写您希望以实时模式运行的连接器。
最重要的值包括:
1. `OPENAI_API_KEY`,用于真实的 AutoGen 调查
2. `OPENAI_API_BASE`、`JUDGE_MODEL` 和 `SYNTHETIC_GENERATION_MODEL`,用于 judge 评估和合成事件生成
3. 如果您需要按角色进行模型路由,请配置 `AUTOGEN_PLANNER_MODEL`、`AUTOGEN_INVESTIGATOR_MODEL`、`AUTOGEN_CRITIC_MODEL` 和 `AUTOGEN_COMMANDER_MODEL`
4. 用于持久化数据库存储的 `STORAGE_BACKEND`、`POSTGRES_DSN` 和 `POSTGRES_SCHEMA`
5. 用于异步处理的 `ENABLE_BACKGROUND_JOBS` 和 `BACKGROUND_JOB_CONCURRENCY`
6. 用于实时可观测性的 `PROMETHEUS_BASE_URL` 和 `PROMETHEUS_BEARER_TOKEN`
7. 用于从 GitHub Actions 获取发布元数据的 `ENABLE_RELEASE_CORRELATION`、`GITHUB_REPO`、`GITHUB_TOKEN` 和 `GITHUB_WORKFLOW_NAME`
8. 用于通知的 `SLACK_BOT_TOKEN` 和 `SLACK_CHANNEL`
9. 用于工单管理的 `JIRA_BASE_URL`、`JIRA_EMAIL` 和 `JIRA_API_TOKEN`
10. 用于受控操作执行的 `SAFE_REMEDIATION_URL` 和 `REMEDIATION_TOKEN`
11. 用于网关策略的 `SAFE_REMEDIATION_ALLOWED_ACTIONS`、`SAFE_REMEDIATION_ALLOWED_ENVIRONMENTS` 和 `SAFE_REMEDIATION_ALLOWED_SERVICES`
12. 用于分布式追踪的 `ENABLE_TRACING`、`TRACING_SERVICE_NAME` 和 `OTLP_ENDPOINT`
13. 用于 LLM 前置 Isolation Forest 指标层的 `ENABLE_ANOMALY_DETECTION`、`ANOMALY_LOOKBACK_MINUTES`、`ANOMALY_STEP_SECONDS`、`ANOMALY_CONTAMINATION` 和 `ANOMALY_MIN_SAMPLES`
14. 用于告警 webhook 获取的 `PAGERDUTY_WEBHOOK_SECRET`、`OPSGENIE_WEBHOOK_SECRET` 和 `OPSGENIE_WEBHOOK_SECRET_HEADER`
15. `RUNBOOK_DIR`,用于存放应由 RAG 层索引的 Markdown 或文本 Runbook
16. `PLUGIN_DIR`,用于后端启动时的自定义插件发现
17. 如果您希望 API 受到保护,请配置 `AUTH_ENABLED`、`VIEWER_API_TOKEN` 和 `OPERATOR_API_TOKEN`
### 前端环境
将 `frontend/.env.local.example` 复制到 `frontend/.env.local`。
如果您希望前端从同一主机名上的端口 `8000` 推断后端地址,可以将 `NEXT_PUBLIC_API_BASE_URL` 留空。
仅在您启用后端身份验证并希望浏览器直接调用受保护的 API 时,才设置 `NEXT_PUBLIC_API_TOKEN`。
## 本地运行
### 后端
```
python -m pip install -r requirements.txt
uvicorn app.main:app --reload
```
### 前端
```
cd frontend
npm install
npm run dev
```
### 快速演示流程
1. 打开前端。
2. 创建一个样本事件。
3. 实时运行工作流或将其作为后台作业排队。
4. 查看重放轨道、证据和策略决策。
5. 将最新一次运行与同一事件的先前运行进行比较。
6. 如果事件暂停等待审批,请添加审批备注。
7. 导出生成的事后总结。
8. 运行或排队样本基准测试以填充回归历史。
## 使用 Docker 运行
该仓库现在包含一个后端 `Dockerfile`、一个前端 `Dockerfile` 以及一个 `docker-compose.yml`。
使用:
```
docker compose up --build
```
Compose 设置默认执行三项有用的操作:
1. 启动一个用于持久存储的 Postgres 实例
2. 在端口 `8000` 上暴露后端
3. 在端口 `3000` 上暴露前端
4. 通过将 `SAFE_REMEDIATION_URL` 指向后端沙箱修复 endpoint 来启用安全的环回复路径,除非您对其进行覆盖
这种环回路径故意设定得很保守。它证明了完整的修复往返过程,而无需触及真实的生产系统。
## 云部署注意事项
该项目已经足够成熟,可用于演示环境和内部展示,但仍有一个重要的注意事项。
应用程序已经可以使用 Postgres 来存储事件、运行、工单、基准测试、记忆和修复凭证。JSON 后端仍然存在是因为它对本地演示和离线演练很有用。对于真实的托管环境,您应该首选 Postgres 路径,并将 JSON 仅作为回退模式处理。
如果您部署在 Render、Railway、Azure 或 AWS App Runner 上,最简单的路径是:
1. 使用根 `Dockerfile` 部署后端
2. 使用 `frontend/Dockerfile` 部署前端
3. 通过平台机密管理器提供连接器环境变量
4. 保持 `STORAGE_BACKEND=postgres` 并将 `POSTGRES_DSN` 指向您的托管数据库
之后的下一个生产强化步骤是:
1. 托管身份和更强的基于角色的访问控制
2. 具有真实机密处理的生产级 Prometheus 或 Grafana 连接
3. 真正的 Kubernetes 或云安全操作适配器,而不仅仅是受控的网关
4. 更深入的基准测试包和根据真实操作员使用情况调整的事件记忆
## 测试与验证
该项目已设置好,您可以快速验证这两个层:
### 后端
```
pytest -q
```
### 前端
```
cd frontend
npm run build
```
## 负载测试
Locust 负载测试位于 `locust/` 中,可执行事件创建、调查处理、事件列出和每次运行的成本检查,思考时间介于 1 到 3 秒之间。
运行交互式 UI:
```
locust -f locust/locustfile.py
```
无头模式运行:
```
locust -f locust/locustfile.py --host http://127.0.0.1:8000 --headless -u 10 -r 2 --run-time 60s
```
当 `AUTH_ENABLED=true` 时,请设置 `LOCUST_BEARER_TOKEN`。
本地演示模式的示例结果:
| 用户数 | 运行时间 | RPS | p50 | p95 | 错误率 |
| ---: | --- | ---: | ---: | ---: | ---: |
| 5 | 30s | 2.4 | 180ms | 920ms | 0.0% |
| 10 | 60s | 4.8 | 210ms | 1250ms | 0.0% |
CI 运行 `5` 个用户,持续 `30s`,如果错误率超过 `5%` 或 p95 延迟超过 `2000ms`,则判定为失败。
## 演示资产
该仓库在 `docs/assets/README.md` 中包含一个资产组合清单。
该文件准确地告诉您应该添加哪些截图和 GIF 捕获,以获得更出色的公开 GitHub 展示:
1. 仪表盘概览
2. 事件详情路由
3. 基准测试比较
4. 完整演练 GIF
该仓库现在还包含从运行中的应用程序捕获的实时截图:
1. `docs/assets/dashboard-overview.png`
2. `docs/assets/active-investigation.png`
3. `docs/assets/benchmark-and-governance.png`
## 值得探索的关键文件
1. `app/main.py`
2. `app/services/incident_service.py`
3. `app/workflow/langgraph_orchestrator.py`
4. `app/workflow/autogen_team.py`
5. `app/integrations/observability.py`
6. `app/integrations/tickets.py`
7. `app/integrations/chat.py`
8. `app/integrations/remediation.py`
9. `app/core/safe_remediation.py`
10. `app/core/storage.py`
11. `frontend/src/components/incident-console.tsx`
12. `frontend/src/app/incidents/[incidentId]/page.tsx`
## 简历总结
构建了一个实时 AI 事件响应平台,结合了用于持久工作流编排的 LangGraph 和用于多智能体调查的 AutoGen,具备 Postgres 持久化存储、Prometheus、Slack、Jira、受控的修复网关、基于策略的审批门、可重放的事件日志、基准测试、记忆检索以及 Next.js 中的实时操作员控制台。
## 简历亮点
1. 构建了一个 AI 事件响应平台,结合了 `12 个智能体的 AutoGen 调查团队`与 `10 阶段 LangGraph 工作流`,用于分诊、基于图谱的因果推理、策略门控、修复和事后总结生成。
2. 添加了 Artifact 引导的多模态推理、操作员反馈学习和服务知识图谱,使系统能够基于截图注解、依赖路径和人工纠正进行推理,而不仅仅依赖于原始告警文本。
3. 设计了基准测试、对抗性评估、带有启发式回退的 Judge 评分、基于规则的纠正、记忆检索和优化器循环,以衡量并随时间改善根因质量、操作安全性、延迟和修复有效性。
标签:AIOps, AI运维, AI驱动, API集成, AutoGen, AV绕过, DevSecOps, DLL 劫持, FastAPI, IT服务管理, IT运维, LangGraph, Lerna, PyRIT, Python开发, Socks5代理, SRE工具, WebSocket, 上游代理, 事故管理, 人工智能, 依赖分析, 可观测性, 多Agent, 多智能体系统, 大语言模型, 工作流编排, 开源框架, 持续集成, 故障恢复, 故障排查, 智能运维助手, 根因分析, 模块化设计, 用户模式Hook绕过, 策略执行, 系统可用性, 自动化修复, 自动化运维, 请求拦截, 运维仪表盘, 运维平台, 运维自动化, 逆向工具